一种社交圈子的确定方法和装置与流程
本发明涉及信息处理技术领域,尤其涉及一种社交圈子的确定方法和装置。
背景技术:
社交网络具有大规模、动态、内容与数据丰富等特性,在发现或查找社交群体时,往往涉及到社交群体的密度设定的问题,若社交群体密度设定的太小,得到的社交群用户间共性降低,反之,则可能会遗漏更多的用户。
现有方法多是人为随机指定社交群体聚类密度值,存在主观性强、效率低、且不能保证聚类得到社交用户之间的共性的问题。
技术实现要素:
本发明实施例提供了一种社交圈子的确定方法和装置,解决了现有技术中主观性强、效率低、且不能保证聚类得到社交用户之间的共性的技术问题,具有结果客观、效率高,既满足社交用户之间的共性,又能达到社交群体用户数量最大化的技术效果。
本申请实施例提供一种社交圈子的确定方法,所述方法包括:获得第一社交圈子,所述第一社交圈子具有第一密度值d1;获得第二社交圈子,所述第二社交圈子具有第二密度值d2,其中,所述第一社交圈子不同于所述第二社交圈子,所述第一密度值d1不同于所述第二密度值d2;获得所述第一社交圈子的第一文档信息;根据所述第一社交圈子和所述第一文档信息确定所述第一社交圈子的第一相似度;获得所述第二社交圈子的第二文档信息;根据所述第二社交圈子和所述第二文档信息确定所述第二社交圈子的第二相似度;判断所述第一相似度和所述第二相似度的大小;当所述第一相似度大于所述第二相似度时,确定所述第一密度值d1作为社交圈子的选择标准。
进一步地,所述方法还包括:当所述第一相似度不大于所述第二相似度时,确定所述第二密度值d2作为社交圈子的选择标准。
进一步地,所述方法还包括:根据
进一步地,所述方法还包括:根据所述第一文档信息获得第一主题信息,其中,所述第一主题信息包括第一词项信息;根据所述第一社交圈子、所述第一文档信息、所述第一主题信息和所述第一词项信息获得第一概率分布;根据所述第一社交圈子和所述第一概率分布获得所述第一相似度。
本申请实施例还一种社交圈子的确定装置,所述装置包括:第一获得单元,所述第一获得单元用于获得第一社交圈子,所述第一社交圈子具有第一密度值d1;第二获得单元,所述第二获得单元用于获得第二社交圈子,所述第二社交圈子具有第二密度值d2,其中,所述第一社交圈子不同于所述第二社交圈子,所述第一密度值d1不同于所述第二密度值d2;第三获得单元,所述第三获得单元用于获得所述第一社交圈子的第一文档信息;第一确定单元,所述第一确定单元用于根据所述第一社交圈子和所述第一文档信息确定所述第一社交圈子的第一相似度;第四获得单元,所述第四获得单元用于获得所述第二社交圈子的第二文档信息;第二确定单元,所述第二确定单元用于根据所述第二社交圈子和所述第二内容信息确定所述第二社交圈子的第二相似度;第一判断单元,所述第二判断单元用于判断所述第一相似度和所述第二相似度的大小;第三确定单元,所述第三确定单元用于当所述第一相似度大于所述第二相似度时,确定所述第一密度值d1作为社交圈子的选择标准。
进一步地,所述装置还包括:第四确定单元,所述第四确定单元用于当所述第一相似度不大于所述第二相似度时,确定所述第二密度值d2作为社交圈子的选择标准。
进一步地,所述装置还包括:第五获得单元,所述第五获得单元用于根据
进一步地,所述装置还包括:第六获得单元,所述第六获得单元用于根据所述第一文档信息获得第一主题信息,其中,所述第一主题信息包括第一词项信息;第七获得单元,所述第七获得单元用于根据所述第一社交圈子、所述第一文档信息、所述第一主题信息和所述第一词项信息获得第一概率分布;第八获得单元,所述第八获得单元用于根据所述第一社交圈子和所述第一概率分布获得所述第一相似度。
本申请实施例中的上述一个或多个技术方案,至少具有如下一种或多种技术效果:
1、本申请实施例提供一种社交圈子的确定方法和装置,所述方法包括:获得第一社交圈子,所述第一社交圈子具有第一密度值d1;获得第二社交圈子,所述第二社交圈子具有第二密度值d2,其中,所述第一社交圈子不同于所述第二社交圈子,所述第一密度值d1不同于所述第二密度值d2;获得所述第一社交圈子的第一文档信息;根据所述第一社交圈子和所述第一文档信息确定所述第一社交圈子的第一相似度;获得所述第二社交圈子的第二文档信息;根据所述第二社交圈子和所述第二文档信息确定所述第二社交圈子的第二相似度;判断所述第一相似度和所述第二相似度的大小;当所述第一相似度大于所述第二相似度时,确定所述第一密度值d1作为社交圈子的选择标准。通过上述技术方案,解决了现有技术中主观性强、效率低、且不能保证聚类得到社交用户之间的共性的技术问题,具有结果客观、效率高,既满足社交用户之间的共性,又能达到社交群体用户数量最大化的技术效果。
2、本申请实施例通过根据社交圈子及其文档信息获得用户感兴趣的主题的分布,确定所述社交圈子用户的相似度,比较不同社交圈子的相似度大小从而获得选择社交圈子的标准,具有结果客观,满足社交用户之间的共性的技术效果。
附图说明
图1为本申请实施例提供的一种社交圈子的确定方法流程图;
图2为本申请实施例提供的一种第一相似度的确定方法流程图;
图3为本申请实施例提供的一种社交圈子的确定装置示意图。
具体实施方式
本申请实施例提供了一种社交圈子的确定方法和装置,解决了现有方法中存在的主观性强、效率低、且不能保证聚类得到社交用户之间的共性的问题,具有结果客观、效率高,既满足社交用户之间的共性,又能达到社交群体用户数量最大化的技术效果。
为了解决上述技术问题,本发明提供的思路如下:
本申请实施例提供一种社交圈子的确定方法和装置,所述方法包括:获得第一社交圈子,所述第一社交圈子具有第一密度值d1;获得第二社交圈子,所述第二社交圈子具有第二密度值d2,其中,所述第一社交圈子不同于所述第二社交圈子,所述第一密度值d1不同于所述第二密度值d2;获得所述第一社交圈子的第一文档信息;根据所述第一社交圈子和所述第一文档信息确定所述第一社交圈子的第一相似度;获得所述第二社交圈子的第二文档信息;根据所述第二社交圈子和所述第二文档信息确定所述第二社交圈子的第二相似度;判断所述第一相似度和所述第二相似度的大小;当所述第一相似度大于所述第二相似度时,确定所述第一密度值d1作为社交圈子的选择标准。通过上述技术方案,解决了现有技术中主观性强、效率低、且不能保证聚类得到社交用户之间的共性的技术问题,具有结果客观、效率高,既满足社交用户之间的共性,又能达到社交群体用户数量最大化的技术效果。
下面通过附图以及具体实施例对本发明技术方案做详细的说明,应当理解本申请实施例以及实施例中的具体特征是对本申请技术方案的详细的说明,而不是对本申请技术方案的限定,在不冲突的情况下,本申请实施例以及实施例中的技术特征可以相互组合。
本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。
实施例1:
图1为本申请实施例提供的一种社交圈子的确定方法流程图,所述方法包括:
步骤101:获得第一社交圈子,所述第一社交圈子具有第一密度值d1;
在社交环境中社交用户彼此互相关注,形成关系链,进而,基于这种关注关系链形成的关系圈,称为社交圈子。其中,所述社交用户是指在社交网络平台,例如微博、微信、贴吧等平台中,具有关注其他用户或者被其他用户关注的平台账号资源;所述关注关系链是指社交用户互相关注后形成的关系链。所述第一社交圈子由具有一定关注关系链的社交用户群体构成,可在社交网络平台上选取一定量的社交用户构成所述第一社交圈子。
社交圈子的密度值用于描述社交圈子内用户的关注紧密度,用户互相关注的越多,则社交圈子的密度值越大,用户之间互相关注越少,则社交圈子密度值越小。所述第一社交圈子的所述第一密度值d1可根据
步骤102:获得第二社交圈子,所述第二社交圈子具有第二密度值d2,其中,所述第一社交圈子不同于所述第二社交圈子,所述第一密度值d1不同于所述第二密度值d2;
同理,根据上述获得第一社交圈子和第一密度值d1的方式获得所述第二社交圈子及所述第二密度值d2。其中,所述第一社交圈子和所述第二社交圈子为不同的社交圈子,所述第一密度值d1不同于所述第二密度值d2。
步骤103:获得所述第一社交圈子的第一文档信息;
具体来说,所述第一文档信息是指所述第一社交圈子中的社交用户在社交平台上的浏览历史及发表的文字、语音、视频信息等内容构成的集合,例如所述社交用户浏览及发布过的微博、帖子等。
步骤104:根据所述第一社交圈子和所述第一文档信息确定所述第一社交圈子的第一相似度;
具体来说,所述第一相似度用于衡量所述第一社交圈子的用户之间的相似度,即用户的共性,所述第一相似度越大,则所述第一社交圈子的用户的共性越大。其中,所述用户的共性指所述用户在兴趣爱好,关注的主题等方面的共性。也就是说,第一相似度越大,则所述第一社交圈子内的用户在兴趣爱好,关注的主题方面相似的程度越大。
步骤105:获得所述第二社交圈子的第二文档信息;
具体来说,所述第二文档信息是指所述第二社交圈子中的社交用户的浏览历史及发表的文字、语音、视频信息等内容构成的集合。
步骤106:根据所述第二社交圈子和所述第二文档信息确定所述第二社交圈子的第二相似度;
具体来说,所述第二相似度用于衡量所述第二社交圈子的用户之间的相似度,即用户的共性,所述第二相似度越大,则所述第二社交圈子的用户的共性越大。也就是说,第二相似度越大,则所述第二社交圈子内的用户在兴趣爱好,关注的主题方面相似的程度越大。
步骤107:判断所述第一相似度和所述第二相似度的大小;
具体来说,相似度用于衡量用户之间的共性,相似度越大,则用户共性越大,也就是说,相似度越大,则社交圈子内的不同用户在兴趣爱好,关注的主题方面相似的程度越大。本步骤比较所述第一相似度与所述第二相似度的大小,则是为了比较所述第一社交圈子和所述第二社交圈子的用户的共性的大小,以选取用户共性大的社交圈子作为选择社交圈子的标准。
步骤108:当所述第一相似度大于所述第二相似度时,确定所述第一密度值d1作为社交圈子的选择标准。
当所述第一相似度大于所述第二相似度,则说明所述第一社交圈子的用户共性大于所述第二社交圈子的的用户的共性,则选择所述第一密度值d1作为社交圈子的选择标准。步骤101至步骤108所述方法根据社交圈子及其文档信息获得用户感兴趣的主题的分布,确定所述社交圈子用户的相似度,比较不同社交圈子的相似度大小,所述方法能够客观的得到用户共性较大,且用户数量满足需求的社交圈子,进而能够客观高效的获得社交圈子的选择标准。
进一步地,当所述第一相似度不大于所述第二相似度时,确定所述第二密度值d2作为社交圈子的选择标准。
具体来说,当所述第一相似度小于或者等于所述第二相似度时,则说明所述第一社交圈子的用户的共性小于或者等于所述第二社交圈子的共性,因此,选择所述第二密度值d2作为社交圈子的选择标准。
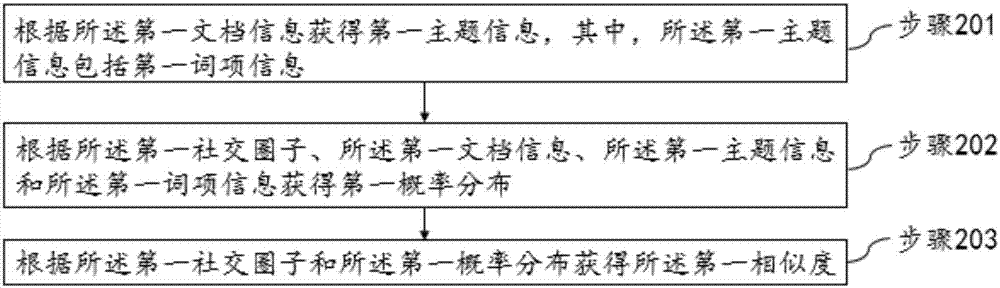
进一步地,本申请实施例提供一种第一相似度的确定的确定方法,如图2所示流程图,所述方法包括:
步骤201:根据所述第一文档信息获得第一主题信息,其中所述第一主题信息包括第一词项信息;
具体来说,所述第一主题信息用来表示所述第一社交圈子的用户的兴趣偏好,所述第一词项信息是用于描述所述第一主题信息所使用的词语。通过建立文档-主题-词项模型,对用户的浏览过及发布过的文档、语音、视频等信息进行分析,可以从大规模文档中获得用户感兴趣的主题信息。其中,所述文档-主题-词项模型是一种文档主题的生成模型,包含词项、主题、文档三层结构,一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词项”这样一个过程得到,文档到主题服从多项式分布,主题到词项服从多项式分布,所述文档-主题-词项模型可用来识别大规模文档集或语料库中潜藏的主题信息。
步骤202:根据所述第一社交圈子、所述第一文档信息、所述第一主题信息和所述第一词项信息获得第一概率分布;
所述第一概率分布是指所述第一社交圈的用户所感兴趣的主题的概率分布。具体来说,通过所述文档-主题-词项模型对用户浏览过及发布过的文档、语音、视频等信息分析后得到用户感兴趣的主题后,可计算出所述第一社交圈子中文档对主题的概率分布p=[p1,p2,p3…pt],其中,t为主题数量。所述概率分布是一种能够描述用户对不同主题的感兴趣的程度的分布。
步骤203:根据所述第一社交圈子和所述第一概率分布获得所述第一相似度。
所述第一相似度用来描述所述第一社交圈的用户的相似度。所述用户的相似度是指在一个社交圈内的用户对不同主题感兴趣程度的相似程度。概率分布能够描述用户对不同主题的感兴趣的程度的分布。因此,通过概率分布的相似度,可以度量用户的相似度,概率分布的相似度越大,则说明用户对不同主题的感兴趣程度越相似,说明用户的相似度越大。本申请实施例通过kl距离公式作为文本相似度的度量标准,所述kl距离表示为:
其中pi、qi为不同文本的概率分布,dkl(p,q)为计算两个不同文本的概率分布相似度。
若所述第一社交圈中有n个社交用户,将每个社交用户的相似度分别表示为fi,其中,i=1,2,3…n,则所述第一社交圈的平均相似度为
步骤201至步骤203根据社交圈子及其文档信息获得用户感兴趣的主题的分布,确定所述社交圈子用户的相似度,相似度能够描述用户的对不同主题的感兴趣程度,进而能够客观、高效的获得满足社交用户之间的共性,用户数量又能符合需求的社交圈。
本申请实施例还提供一种社交圈子的确定装置,如图3所示装置示意图,所述装置包括:
第一获得单元11,所述第一获得单元用于获得第一社交圈子,所述第一社交圈子具有第一密度值d1;
第二获得单元12,所述第二获得单元用于获得第二社交圈子,所述第二社交圈子具有第二密度值d2,其中,所述第一社交圈子不同于所述第二社交圈子,所述第一密度值d1不同于所述第二密度值d2;
第三获得单元13,所述第三获得单元用于获得所述第一社交圈子的第一文档信息;
第一确定单元14,所述第一确定单元用于根据所述第一社交圈子和所述第一文档信息确定所述第一社交圈子的第一相似度;
第四获得单元15,所述第四获得单元用于获得所述第二社交圈子的第二文档信息;
第二确定单元16,所述第二确定单元用于根据所述第二社交圈子和所述第二文档信息确定所述第二社交圈子的第二相似度;
第一判断单元17,所述第二判断单元用于判断所述第一相似度和所述第二相似度的大小;
第三确定单元18,所述第三确定单元用于当所述第一相似度大于所述第二相似度时,确定所述第一密度值d1作为社交圈子的选择标准。
进一步地,所述装置还包括:第四确定单元,所述第四确定单元用于当所述第一相似度不大于所述第二相似度时,确定所述第二密度值d2作为社交圈子的选择标准。
进一步地,所述装置还包括:第五获得单元,所述第五获得单元用于根据
进一步地,所述装置还包括:第六获得单元,所述第六获得单元用于根据所述第一文档信息获得第一主题信息,其中,所述第一主题信息包括第一词项信息;第七获得单元,所述第七获得单元用于根据所述第一社交圈子、所述第一文档信息、所述第一主题信息和所述第一词项信息获得第一概率分布;第八获得单元,所述第八获得单元用于根据所述第一社交圈子和所述第一概率分布获得所述第一相似度。
本申请实施例提供的一种社交圈子的确定方法和装置至少具有如下技术效果:
1、本申请实施例提供一种社交圈子的确定方法和装置,所述方法包括:获得第一社交圈子,所述第一社交圈子具有第一密度值d1;获得第二社交圈子,所述第二社交圈子具有第二密度值d2,其中,所述第一社交圈子不同于所述第二社交圈子,所述第一密度值d1不同于所述第二密度值d2;获得所述第一社交圈子的第一文档信息;根据所述第一社交圈子和所述第一文档信息确定所述第一社交圈子的第一相似度;获得所述第二社交圈子的第二文档信息;根据所述第二社交圈子和所述第二文档信息确定所述第二社交圈子的第二相似度;判断所述第一相似度和所述第二相似度的大小;当所述第一相似度大于所述第二相似度时,确定所述第一密度值d1作为社交圈子的选择标准。通过上述技术方案,解决了现有技术中主观性强、效率低、且不能保证聚类得到社交用户之间的共性的技术问题,具有结果客观、效率高,既满足社交用户之间的共性,又能达到社交群体用户数量最大化的技术效果。
2、本申请实施例通过根据社交圈子及其文档信息获得用户感兴趣的主题的分布,确定所述社交圈子用户的相似度,比较不同社交圈子的相似度大小从而获得选择社交圈子的标准,具有结果客观,满足社交用户之间的共性的技术效果。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!