一种用于手势识别的数据库建立方法与流程
本发明属于计算机视觉领域,特别涉及一种用于手势识别的数据库建立方法。
背景技术:
人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。近年来,人工智能和深度学习如雨后春笋般发展起来,2016年因为alphago战胜韩国九段李世石等众多标志性事件发生被称为ai元年。手势识别是人工智能领域中非常重要的一个领域,在人机沟通、智能驾驶、智能家居方面具有良好的应用前景,因此手势数据集的构建吸引了一些学者的兴趣。建立一个完善的手势识别数据集可以推动手势识别精度大幅提高,从而推动手势识别在生活中的广泛应用。因此,建立一个完善的手势识别数据集有非常重要的研究意义和应用价值。
研究人员尝试各种方法来使数据集包含丰富的手部信息,通常邀请志愿者到实验室中佩戴实验设备,采集数据。此类数据集存在如下缺点:1、实验室场地有限,获取的数据场景单一;2、志愿者数量有限,获取的手势种类不足;3、干扰因素少。目前人工智能仍处于数据驱动的阶段,用此类数据集训练得到的模型鲁棒性、泛化性较差,在实际应用中效果较差,不能达到令人满意的效果,以及场景复杂性,更接近现实生活。本发明处理图像数据并获得图像中手的节点信息。
技术实现要素:
本发明构建了一个完备的针对手势识别的数据集,包含了丰富的场景,不再是传统简单的实验室场景,接近现实生活,并包含了多样的手势,基本涵盖了一只手可以实现的所有手势,具有较好的适用性和鲁棒性,为手势识别提供了坚实的数据基础,旨在解决手势识别问题,推动人工智能的发展。
一种用于手势识别的数据库建立方法,包括如下步骤:
步骤1、从网络上收集关于单只手的rgb手部图片,构建数据库;
步骤2、对数据库中的图片统一尺寸;
将原始数据统一到一个标准尺寸n*m,并对每张手部图片进行命名,图片文件名称为“hand+序号”;
步骤3、获取数据库中统一尺寸后的手部图片中手的各个节点的坐标数据;
所述的坐标数据的标记通过标记模块实现,坐标数据包括手腕坐标和每个手指每个节点坐标;坐标数据的标记顺序:首先标记获取手腕部坐标,再依次获取大拇指、食指、中指、无名指和小拇指上各个关节点的坐标;每个手指的标记顺序为从手指根部开始,依次标记到手指顶部;
步骤4、将步骤2统一尺寸后手部图片和步骤3获取的坐标数据通过转换模块转换成深度学习框架能够直接使用的数据类型。
步骤3所述的标记模块包括存储单元和鼠标点击单元,其具体实现过程如下:
手部图片输入到标记模块后,先将该输入的手部图片的文件名和长宽写入存储单元;再通过鼠标点击单元左键点击输入的手部图片中的节点,以一个圆点作为节点记号,同时将该节点记号的坐标数据输入至存储单元;
在鼠标点击单元左键点击输入的手部图片中节点的过程中,若该手部图片中存在不可见节点,则将鼠标点击单元移动至手部图片的外侧区域,然后通过鼠标点击单元左键点击该外侧区域,此时自动将该不可见节点的坐标数据记为(-1,-1),同时将该节点记号的坐标数据输入至存储单元;
通过深度学习方法,同时结合数据库训练得到手势模型,将一张全新的手部图片输入该手势模型完成节点位置的判断,输出手部图片中每个节点的坐标数据,利用输出的坐标数据能够还原出手部图片中的手势,进而进行相关判断和控制。
步骤4所述的转换模块实现过程有两种,其中转换为hdf5类型数据如下:
1.为数据库中的每张手部图片分配内存空间,同时为该手部图片在存储单元中的坐标数据分配内存空间;
2.将每张手部图片中所有节点的坐标数据以矩阵形式读入,经过矩阵转置,每个矩阵行向量对应一张手部图片的手势节点的坐标数据,便于程序读取;
3.将转换模块中读入的手部图片和该手部图片对应的坐标数据进行绑定,然后转换成hdf5类型数据;转换模块能够同时对读入的多张手部图片和手部图片对应的坐标数据同时进行处理;每批转换处理的手部图片数目通过转换模块中一个参数chunksz进行设定;转换换成hdf5类型数据的过程需要调用到store2hdf5函数;
所述的store2hdf5函数由caffe开发者提供,能直接调用;转换结束后为了确定hdf5数据转换成功;程序中设定验证部分,若成功,将在屏幕上显示“successful”,若失败,将在屏幕上显示“error”,成功后文件夹下会生成一个.h5文件和一个txt文件,其中txt文件中包含所需hdf5文件的文件名,因此可以同时调用多个hdf5文件进行训练或者测试。
步骤4所述的转换模块的另一种实现过程为转换为lmdb类型数据,具体如下:
1.为数据库中的每张手部图片分配内存空间,同时为该手部图片在存储单元中的坐标数据分配内存空间;
2.将每张手部图片中所有节点的坐标数据以矩阵形式读入,经过矩阵转置,每个矩阵行向量对应一张手部图片的手势节点的坐标数据,便于程序读取;
3.将转换模块中读入的手部图片和该手部图片对应的坐标数据通过转换模块后分别生成image文件和label文件,用于训练和测试;转换模块结合python的lmdb库和caffe的python接口caffe.io.array_to_datum,完成image和label的lmdb数据类型转换;
转换模块能够同时对读入的多张手部图片和手部图片对应的坐标数据同时进行处理;每批转换处理的手部图片数目通过转换模块中一个参数batchsz进行设定;转换换成lmdb类型数据的过程需要调用到caffe.io.arraytodatum函数;
所述的caffe.io.arraytodatum函数为caffe自带的接口函数,完成后数据得到两个lmdb文件,一个包含图片数据,一个包含坐标数据;结束后程序会输出程序中读取失败的图片数量,方便确认转换过程时候成功;lmdb的使用方法为在网络底层添加datalayer,在其中定义所用lmdb文件的的路径。
本申请的手势数据库能够达到以下有益效果:
采用本申请提供的手势识别数据库,由于坐标数据中包含了手部每个关键节点的坐标,并且手部的背景场景涵盖各种生活场景,弥补了过往的手势数据集包含数据贫瘠,场景单一的不足。同时将获得的数据和图片转换成了目前深度学习中普遍使用的数据类型,进而可以便利地应用于各种深度学习网络结构训练,例如vgg,resnet,googlenet,可以推动手势识别领域的快速发展。手势识别作为当前人工智能领域的热门课题,对未来人机交互,智能驾驶等方面都有重要意义,因而该数据库的构建完成具有重要意义。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1为本申请实施例构建手势识别数据库方法流程图;
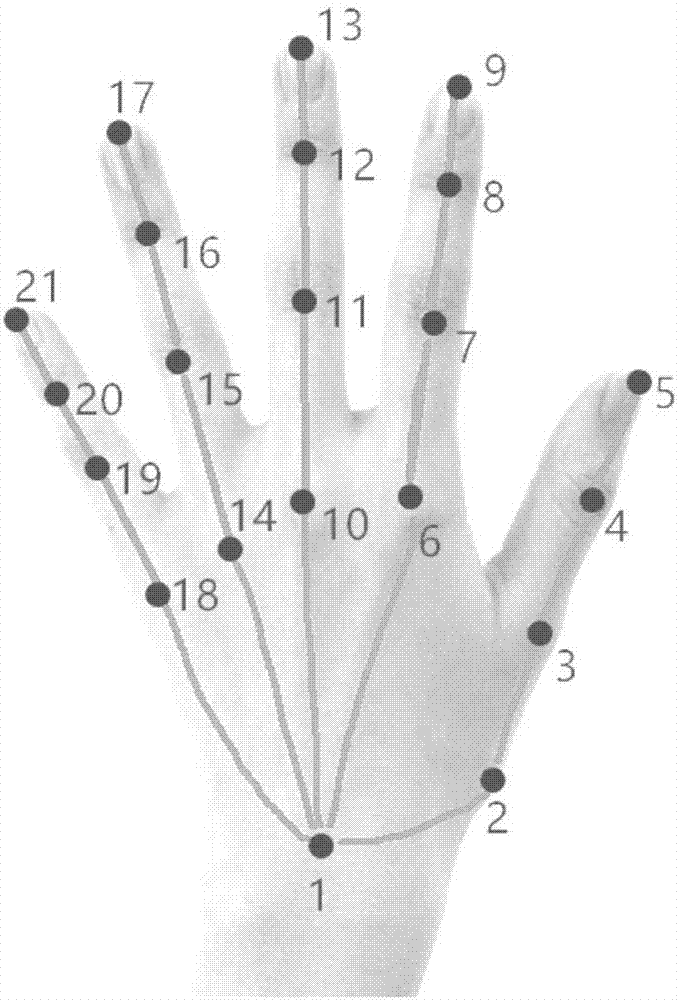
图2为本申请实施例获取手部坐标数据顺序的示意图;
图3为本申请实施例中采用的图片标记程序的流程示意图;
图4为本申请实施例中采用的数据类型转换程序的流程示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请具体实施例及相应的附图对本申请技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围下面结合具体实施方式对本发明进行详细的说明。
以下结合附图,详细说明本申请各实施例提供的技术方案。
本发明构建的用于手势识别的数据库包括原始图片和手部坐标数据,同时包括目前广泛使用的hdf5类型数据,可以但不仅限于深度学习框架caffe,根据需要可以转换生成任意需要的数据类型,用于任何进行深度学习的框架。
本申请实施例提供了一个完备的用于手势识别的数据库,弥补了现有数据库所存在的不足,该方法的具体实现流程示意图如图1所示,主要包括下述步骤:
步骤1、从网络上收集关于单只手的rgb手部图片,构建数据库;
构建数据库首先要收集大量的原始数据,通常研究人员选择通过实验收集数据,好处是保证了数据的唯一性,不足则是数据量较小,通过该方法获取较多数据时将耗费巨大成本。本发明采用从网络中获取图片的方式,以较小的成本获取较多的数据。
大数据时代已经到来,每分每秒都有海量的数据正在产生。图片网站,社交平台例如instagram、pinterest、facebook,全球用户以惊人的速度创造原始数据,促使该类网站存在海量的原始手部图片数据,且场景丰富,手势多样,是构建手势数据库的最好数据来源。同时当前google,百度该类搜索引擎功能日趋完善,有助于提高收集数据的效率。需要说明的是,本实施例中对图片不做严格的限定,只要保证在图片中包含单只手,遮挡、光线等因素不做限定,确保该数据库接近现实环境,训练得到的模型具有较强的泛化能力、较强的鲁棒性。为确保从获取的图片中筛选包含单只手的图片的准确性,该过程采用人为筛选的方式,并重复3次,直至筛选出的图片全部满足要求。
步骤2、对数据库中的图片统一尺寸;
当前深度学习框架所使用的训练数据和测试数据获取的一般过程:将原始数据统一到一个标准尺寸n*m,并对每张手部图片进行命名,图片文件名称为“hand+序号”;根据需求做相应操作,得到满足要求的数据。为了方便后期应用于人工智能训练过程中,本步骤中将所有收集到的图片将其大小统一改为长:256像素,宽:256像素。
步骤3、获取数据库中统一尺寸后的手部图片中手的各个节点的坐标数据;
所述的坐标数据的标记通过标记模块实现,坐标数据包括手腕坐标和每个手指每个节点坐标;该过程虽已利用程序提高工作效率,但仍需人工获取图片中的手部节点坐标。坐标数据的标记顺序如图2所示:首先标记获取手腕部坐标,再依次获取大拇指、食指、中指、无名指和小拇指上各个关节点的坐标;每个手指的标记顺序为从手指根部开始,依次标记到手指顶部。
标记模块包括存储单元和鼠标点击单元,其实现过程参看图3,具体如下:
手部图片输入到标记模块后,先将该输入的手部图片的文件名和长宽写入存储单元;再通过鼠标点击单元左键点击输入的手部图片中的节点,以一个圆点作为节点记号,同时将该节点记号的坐标数据输入至存储单元;
在鼠标点击单元左键点击输入的手部图片中节点的过程中,若该手部图片中存在不可见节点,则将鼠标点击单元移动至手部图片的外侧区域(该区域点坐标的横坐标大于图片长度或者纵坐标大于图片宽度),然后通过鼠标点击单元左键点击该外侧区域,此时自动将该不可见节点的坐标数据记为(-1,-1),同时将该节点记号的坐标数据输入至存储单元;
通过深度学习方法,同时结合数据库训练得到手势模型,将一张全新的手部图片输入该手势模型完成节点位置的判断,输出手部图片中每个节点的坐标数据,利用输出的坐标数据能够还原出手部图片中的手势,进而进行相关判断和控制。
所述的存储单元为txt文件
步骤4、将步骤2统一尺寸后手部图片和步骤3获取的坐标数据通过转换模块转换成深度学习框架能够直接使用的数据类型;
所述的转换模块的实现过程有两种,转换为hdf5类型数据如下:
1.为数据库中的每张手部图片分配内存空间,同时为该手部图片在存储单元中的坐标数据分配内存空间;
2.将每张手部图片中所有节点的坐标数据以矩阵形式读入,经过矩阵转置,每个矩阵行向量对应一张手部图片的手势节点的坐标数据,便于程序读取;
3.将转换模块中读入的手部图片和该手部图片对应的坐标数据进行绑定,然后转换成hdf5类型数据;转换模块能够同时对读入的多张手部图片和手部图片对应的坐标数据同时进行处理。每批转换处理的手部图片数目通过转换模块中一个参数chunksz进行设定。转换换成hdf5类型数据的过程需要调用到store2hdf5函数,
所述的store2hdf5函数由caffe开发者提供,能直接调用。转换结束后为了确定hdf5数据转换成功。程序中设定验证部分,若成功,将在屏幕上显示“successful”,若失败,将在屏幕上显示“error”,成功后文件夹下会生成一个.h5文件和一个txt文件,其中txt文件中包含所需hdf5文件的文件名,因此可以同时调用多个hdf5文件进行训练或者测试。
本实施例通过matlab/python程序实现两种数据类型转换,程序流程图如图4所示。
转换为lmdb类型数据如下:
1.为数据库中的每张手部图片分配内存空间,同时为该手部图片在存储单元中的坐标数据分配内存空间;
2.将每张手部图片中所有节点的坐标数据以矩阵形式读入,经过矩阵转置,每个矩阵行向量对应一张手部图片的手势节点的坐标数据,便于程序读取;
3.将转换模块中读入的手部图片和该手部图片对应的坐标数据通过转换模块后分别生成image文件和label文件,用于训练和测试;转换模块结合python的lmdb库和caffe的python接口caffe.io.array_to_datum,完成image和label的lmdb数据类型转换。
转换模块能够同时对读入的多张手部图片和手部图片对应的坐标数据同时进行处理。每批转换处理的手部图片数目通过转换模块中一个参数batchsz进行设定。转换换成lmdb类型数据的过程需要调用到caffe.io.arraytodatum函数。
所述的caffe.io.arraytodatum函数为caffe自带的接口函数,完成后数据得到两个lmdb文件,一个包含图片数据,一个包含坐标数据。结束后程序会输出程序中读取失败的图片数量,方便确认转换过程时候成功。lmdb的使用方法为在网络底层添加datalayer,在其中定义所用lmdb文件的的路径。
当前普遍使用的深度学习框架有caffe,tensorflow,keras等,每个框架各有长处,各有不足。tensorflow是一个对深度学习初学者较为友善的框架,支持python和c++,允许在cpu和gpu上的计算分布,并且支持使用grpc进行水平扩展。但是却非常低层。使用tensorflow需要编写大量的代码,多人协同工作时需要以更高的抽象水平在其上创建一些层,从而简化tensorflow的使用。keras是一个较为高层的库,可以工作在theano和tensorflow(可以配置)之上。keras强调极简主义,只需几行代码就能构建一个神经网络,并且句法相当明晰,文档条理清楚,可以直观地了解它的指令、函数和每个模块之间的链接方式,支持python。caffe不只是最老牌的框架之一,而是老牌中的老牌。caffe有非常好的特性,但也有一些小缺点。起初的时候它并不是一个通用框架,而仅仅关注计算机视觉,但它具有非常好的通用性。caffenet架构的训练时间在caffe中比在keras中(使用了theano后端)少5倍,同时可以使用python或matlab接口进行自己需要的改变。keras适合进行实验和测试,caffe则适合进行生产,因此决定将图片和手部节点坐标数据转换成caffe支持训练的数据类型。caffe支持的数据类型包括lmdb,leveldb,hdf5,不同数据类型在不同场景应用中各有优势。在单标签情况或者数据量巨大时lmdb类型数据更具优势,而在多标签情况下hdf5类型数据更为便利。本部分中针对caffe框架所使用的数据格式提供转换流程。本领域技术人员应明白,本申请的实施例可提供为方法、系统或计算机程序产品。
因此,本申请可采用完全软件实施例的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
以上所述仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!