基于光场图像角度域像素的深度估计方法及系统与流程
本发明涉及计算机视觉与数字图像处理领域,特别涉及一种基于光场图像角度域像素的深度估计方法及系统。
背景技术:
光场可以记录环境中所有的光线信息,这一概念早在二十世纪四十年代就被提出。自此以后人们开始研究光场成像原理并不断地丰富光场的内涵。基于光场成像理论,科研人员开始研制可以记录光场的相机,光场相机可以记录来自实际场景中光线的方向及强度,近些年来发明的光场相机在工业及商业界均取得了不错的效果。
现有深度估计的策略主流算法是立体匹配算法,该算法主要思想是利用普通相机采集两个视角的图像,然后分析两个视角之间的相关性构造损失函数,通过最小化损失函数来实现深度的估计;这种方法对于光场相机深度估计存在一定的局限性,由于光场相机的基线太短,构造的损失函数不够精确,会产生一定的块效应,从而使得误差会过大,无法满足深度估计的精度要求。
另外一种方法是利用结合分析光场子孔径图像之间的散焦量以及匹配度来弥补单纯的立体匹配的误差,这种方式在一定程度上提高了深度图像的精确度,但是不能准确估计纹理稀疏处的深度。
还有一种提取方式:信息熵;这种度量手段可以有效的抑制噪声的影响以及可以很好地处理遮挡的影响,但是这种方式的计算消耗过大。
技术实现要素:
为解决上述问题,本发明提出一种基于光场图像角度域像素的深度估计方法及系统,该方法使图像纹理平滑区域的深度更加准确,深度过渡感增强,实际场景物体的边界更加清晰,从而使深度图像得到增强。
本发明提供一种基于光场图像角度域像素的深度估计方法,其特征在于,包括如下步骤:
a1.输入光场图像数据进行重聚焦,得到多个不同聚焦平面的重聚焦光场图像;根据所述多个重聚焦光场图像,提取基于颜色通道的角度域像素强度一致性的深度张量;根据该深度张量,沿着深度层次的方向进行深度估计,获得初始深度图像draw;
a2.对所述初始深度图像draw进行置信度分析:通过分析归一化的角度域像素一致性变量图像的最低点邻域内的方差,方差大于一定阈值,则判定为置信点,从而得到相应的置信区域ω;方差小于该阈值,则判定为非置信点,从而得到相应的非置信区域;
a3.根据置信区域ω,建立优化模型,对非置信区域进行优化,填充非置信点,得到增强的深度图像dopt。
优选地,所述步骤a1中的深度张量包括以强度差值为基础变量,表达为如下公式:
c(p,α)=βrmax(p,α)+(1-α)ravg(p,α),
c(p,α)表示角度域像素p在重聚焦平面α的深度张量;β表示加权系数,0≤β≤1;rmax表示r,g,b三个颜色通道强度的最大值,rmax(p,α)=max(rr(p,α),rg(p,α),rb(p,α));ravg表示r,g,b三个颜色通道强度的平方平均值,
其中,ri(p,α)=max(iq)-min(iq),i表示r,g,b,q∈a(p,α),q表示位于角度域a(p,α)内的像素。
优选地,所述步骤a1中的深度张量包括以强度信息熵为基础变量,表达为如下公式:
c(p,α)=βrmax(p,α)+(1-α)ravg(p,α),
c(p,α)表示角度域像素p在重聚焦平面α的深度张量;β表示加权系数,0≤β≤1;rmax表示r,g,b三个颜色通道强度的最大值,rmax(p,α)=max(rr(p,α),rg(p,α),rb(p,α));ravg表示r,g,b三个颜色通道强度的平方平均值,
其中,ri(p,α)=-∑jh(j)log(h(j)),i表示r,g,b,h(j)表示强度j在角度域a(p,α)中出现的概率。
优选地,所述步骤a1中的深度张量包括以强度匹配度为基础变量,表达为如下公式:
c(p,α)=βrmax(p,α)+(1-α)ravg(p,α),
c(p,α)表示角度域像素p在重聚焦平面α的深度张量;β表示加权系数,0≤β≤1;rmax表示r,g,b三个颜色通道强度的最大值,rmax(p,α)=max(rr(p,α),rg(p,α),rb(p,α));ravg表示r,g,b三个颜色通道强度的平方平均值,
其中,
优选地,所述步骤a1中初始深度图像draw表达为如下公式:draw(p)=∑pdraw(p),其中,
优选地,所述步骤a2中的置信区域ω表达为如下公式:ω={p|var(r(r))|r∈m(p)>τreject},其中,var(*)表示方差运算,m(p)表示像素点p的邻域,m(p)=[draw(p)-δ,draw(p)+δ],δ表示半邻域宽;τreject表示阈值。
优选地,所述步骤a3的优化模型为像素点的深度值、梯度和平滑度的优化模型。
进一步地优选,所述步骤a3的优化模型为:dopt=argminj1(d)+λj2(d)+γj3(d)。
其中,
优选地,在所述步骤a3之后还包括步骤a4:使用加权中值滤波对dopt再进行优化得到dfinal。
本发明还提供一种基于光场图像角度域像素的深度估计系统,包括一种计算机可读存储介质,其存储用于电子数据交换的计算机程序,其中,所述计算机程序使得计算机执行如上所述的方法。
本发明的有益效果:通过对光场图像重聚焦,并提取基于颜色通道的角度域像素强度一致性的深度张量,根据该张量沿着深度层次的方向进行深度估计,获得初始深度估计图像;并对初始深度图像进行置信度分析,建立优化模型,对非置信区域进行优化,从而使得图像纹理平滑区域的深度准确,实际场景物体的边界清晰,进而使深度图像得到增强。
在进一步的优选方案中还能获得更多的优点:通过构造几种有效的衡量光场图像角度域像素强度一致性的基础变量,如:强度差值、强度信息熵、强度匹配度,能够很好地估计深度,深度估计更准确;通过分析cmr曲线最低点邻域内的方差能够有效地得到包含最终置信深度点的置信区域ω;依据置信区域ω,建立置信深度点扩散模型,对非置信深度区域进行优化,填充非置信深度点,二阶导数项的增加使得图像纹理平滑区域的深度更加准确,一阶梯度项使得深度过渡感增强,实际场景物体的边界更加清晰。
附图说明
图1为本发明实施例1深度估计方法的流程示意图。
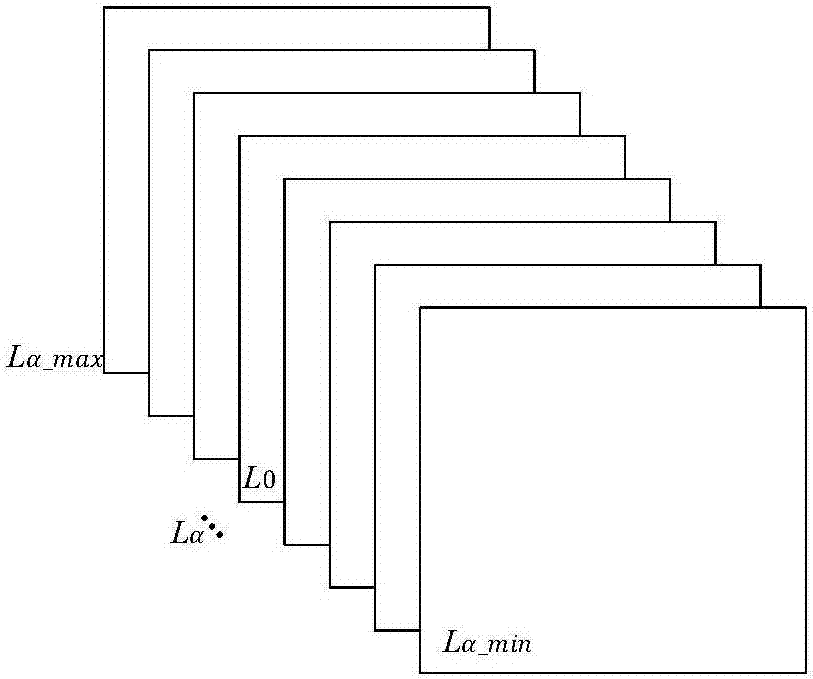
图2为本发明实施例1重聚焦光场图像示意图。
图3为本发明实施例1光场图像与角度域像素的关系示意图。
图4为本发明实施例1光场图像与中心视角图像的关系示意图。
图5a为本发明实施例1基于强度一致性深度张量的损失函数曲线及置信度分析示意图。
图5b为本发明实施例2基于强度匹配度深度张量的损失函数曲线及置信度分析示意图。
图5c为本发明实施例3基于强度信息熵深度张量的损失函数曲线及置信度分析示意图。
具体实施方式
下面结合具体实施方式并对照附图对本发明作进一步详细说明,应该强调的是,下述说明仅仅是示例性的,而不是为了限制本发明的范围及其应用。
实施例1
本实施例提供一种基于光场图像角度域像素的深度估计方法,其流程示意图如图1所示,具体步骤如下:
a1.将原始输入图像聚焦在不同的深度层次上,通过分析不同的深度层次图像角度域内像素强度的变化情况,设计并且提出一个新的深度张量来衡量这种变化,统计再得到初始深度图像draw。
根据已有的光场重聚焦技术进行光场剪切,公式如下:
其中l0表示原始图像,lα表示聚焦在深度层次α上(如图2所示);根据以上公式,可将原始输入图像聚焦在不同的深度层次上,得到一系列隶属不同焦平面的图像簇。
通过分析不同的深度层次图像角度域内像素强度的变化情况,设计并且提出一个基础变量:
ri(p,α)=max(iq)-min(iq)(2)
其中,i表示r,g,b,q∈a(p,α),q表示位于角度域a(p,α)内的像素,利用角度域内像素强度最大值与最小值之差来度量角度域像素强度的变化。
光场图像,中心视角图像ic,以及角度域像素a(p,α)的位置关系如图3和图4所示。
图像数据有三个颜色通道,分别为r、g、b,根据公式(2)的基础变量得到三通道强度的最大值和平均值,如下所示:
rmax(p,α)=max(rr(p,α),rg(p,α),rb(p,α))(3)
rmax表示得到r,g,b三通道强度的最大值,这个变量对于角度域某个像素强度很突出的情况是很有效的;ravg表示r,g,b三个通道强度的平方平均值,这个变量对于角度域内三通道强度差异不大的情况是有效的。结合这两个变量的优势形成构造深度张量,如下:
c(p,α)=βrmax(p,α)+(1-β)ravg(p,α)(5)
其中β是介于0到1之间的数,即将rmax和ravg加权求和。于是c(p,α)最终用作衡量角度域像素强度一致性的深度张量,即强度一致性度量(cmr:consistencymetricrange)。
原始深度通过沿着深度层次上最小化c(p,α),可以得到像素点p处的初始深度:
a2.根据提取的深度张量信息进行原始深度图像的置信分析。置信分析用于确定原始深度估计的准确度,统计每个c(p,α)在draw(p)的邻域内变化的趋势,提出一种新型的判定该像素p处深度是否属于置信点的策略,假设var(*)表示方差运算符,则此邻域内cmr的方差可以表示为:var(c(r))|r∈m(p),其中m(p)=[draw(p)-δ,draw(p)+δ]表示像素点p的邻域,图5a描述了此要求中各个变量的位置关系。若此方差var(·)小于一个阈值τreject时,判定该点是非置信点;相反,该点是置信点。根据以上原理,可以判定深度置信区域以及非置信区域。用ω来表示置信深度区域,相应的ω={p|var(r(r))|r∈m(p)>τreject}。
a3.根据置信区域ω,建立优化模型,对非置信区域进行优化,填充非置信点,得到增强的深度图像dopt。优化模型为基于像素点的深度值、梯度和平滑度的优化模型。优化模型为:
限制条件是d(ω)=draw(ω)。
公式(7)中,
j2(d)表示深度图像中像素r与置信深度区域的图像ic的梯度保持误差函数,gd和
j3(d)表示深度图像中非置信深度区域的平滑度,δd表示d的二阶导数;λ和γ为比例系数。
a4.使用加权中值滤波对dopt再进行优化得到dfinal。
实施例2
本实施例提供一种基于光场图像角度域像素的深度估计方法,具体步骤如下:
a1.将原始输入图像聚焦在不同的深度层次上,通过分析不同的深度层次图像角度域内像素强度的变化情况,设计并且提出一个新的变量来衡量这种变化,统计再得到初始深度图像draw。
根据已有的光场重聚焦技术进行光场剪切,公式如下:
其中l0表示原始图像,lα表示聚焦在深度层次α上;根据以上公式,可将原始输入图像聚焦在不同的深度层次上,得到一系列隶属不同焦平面的图像簇。
与实施例1的区别在于,步骤a1中的基础变量不同,本实施例利用角度域像素强度的信息熵来得到基础变量,表示为如下:
ri(p,α)=-∑jh(j)log(h(j))(10)
其中,i表示r,g,b,h(j)表示强度j在角度域a(p,α)中出现的概率。
图像数据有三个颜色通道,分别为r、g、b,根据公式(10)的基础变量得到三通道强度的最大值和平均值:
rmax(p,α)=max(rr(p,α),rg(p,α),rb(p,α))(3)
同实施例1的公式(3)和(4),再进行加权得到衡量角度域像素强度一致性的深度张量:
c(p,α)=βrmax(p,α)+(1-β)ravg(p,α)(5)
原始深度通过沿着深度层次上最小化c(p,α),可以得到像素点p处的初始深度:
a2.根据提取的深度张量信息进行原始深度图像的置信分析。置信分析用于确定原始深度估计的准确度,统计每个c(p,α)在draw(p)的邻域内变化的趋势,提出一种新型的判定该像素p处深度是否属于置信点的策略,假设var(*)表示方差运算符,则此邻域内的方差可以表示为:var(c(r))|r∈m(p),其中m(p)=[draw(p)-δ,draw(p)+δ]表示像素点p的邻域,图5b描述了此要求中各个变量的位置关系。若此方差var(·)小于一个阈值τreject时,判定该点是非置信点;相反,该点是置信点。根据以上原理,可以判定深度置信区域以及非置信区域。用ω来表示置信深度区域,相应的ω={p|var(r(r))|r∈m(p)>τreject}。
a3.根据置信区域ω,建立优化模型,对非置信区域进行优化,填充非置信点,得到增强的深度图像dopt。优化模型为基于像素点的深度值、梯度和平滑度的优化模型。优化模型为:
限制条件是d(ω)=draw(ω)。
公式(7)中,
j2(d)表示深度图像中像素r与置信深度区域的图像ic的梯度保持误差函数,gd和
j3(d)表示深度图像中非置信深度区域的平滑度,δd表示d的二阶导数;λ和γ为比例系数。
a4.使用加权中值滤波对dopt再进行优化得到dfinal。
实施例3
本实施例提供一种基于光场图像角度域像素的深度估计方法,具体步骤如下:
a1.将原始输入图像聚焦在不同的深度层次上,通过分析不同的深度层次图像角度域内像素强度的变化情况,设计并且提出一个新的变量来衡量这种变化,统计再得到初始深度图像draw。
根据已有的光场重聚焦技术进行光场剪切,公式如下:
其中l0表示原始图像,lα表示聚焦在深度层次α上;根据以上公式,可将原始输入图像聚焦在不同的深度层次上,得到一系列隶属不同焦平面的图像簇。
与实施例1的区别在于,步骤a1中的基础变量不同,本实施例利用角度域像素强度的匹配度来得到基础变量。
匹配度量分析了子孔径与中心孔径的匹配值,该值越小表示匹配度越好。首先求得角度域内的像素强度的均值:
然后利用拉式算子δp对其在该角度域像素邻域窗口内进行运算得到基础变量,表示为如下:
其中,i表示r,g,b,|wd|表示当前像素的领域窗口大小。
图像数据有三个颜色通道,分别为r、g、b,根据公式(11)的基础变量得到三通道强度的最大值和平均值:
rmax(p,α)=max(rr(p,α),rg(p,α),rb(p,α))(3)
同实施例1的公式(3)和(4),再进行加权得到衡量角度域像素强度一致性的深度张量:
c(p,α)=βrmax(p,α)+(1-β)ravg(p,α)(5)
原始深度通过沿着深度层次上最小化c(p,α),可以得到像素点p处的初始深度:
a2.根据提取的深度张量信息进行原始深度图像的置信分析。置信分析用于确定原始深度估计的准确度,统计每个c(p,α)在draw(p)的邻域内变化的趋势,提出一种新型的判定该像素p处深度是否属于置信点的策略,假设var(*)表示方差运算符,则此邻域内的方差可以表示为:var(c(r))|r∈m(p),其中m(p)=[draw(p)-δ,draw(p)+δ]表示像素点p的邻域,图5c描述了此要求中各个变量的位置关系。若此方差var(·)小于一个阈值τreject时,判定该点是非置信点;相反,该点是置信点。根据以上原理,可以判定深度置信区域以及非置信区域。用ω来表示置信深度区域,相应的ω={p|var(r(r))|r∈m(p)>τreject}。
a3.根据置信区域ω,建立优化模型,对非置信区域进行优化,填充非置信点,得到增强的深度图像dopt。优化模型为基于像素点的深度值、梯度和平滑度的优化模型。优化模型为:
限制条件是d(ω)=draw(ω)。
公式(7)中,
j2(d)表示深度图像中像素r与置信深度区域的图像ic的梯度保持误差函数,gd和
j3(d)表示深度图像中非置信深度区域的平滑度,δd表示d的二阶导数;λ和γ为比例系数。
a4.使用加权中值滤波对dopt再进行优化得到dfinal。
以上内容是结合具体/优选的实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,其还可以对这些已描述的实施方式做出若干替代或变型,而这些替代或变型方式都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!