一种图标排序方法、装置及移动终端与流程
本发明涉及电子技术领域,具体涉及一种图标排序方法、装置及移动终端。
背景技术:
随着电子和通信技术的快速发展,移动终端的应用功能越来越丰富。移动终端中通常安装有多个app(application,应用程序),如微信、支付宝、微博、qq等,随着移动终端上安装的app越来越多,为了便于查找和管理app,用户通常需要将app的顺序进行排列。
目前现有技术中也公开了一些关于移动终端的排序方法,例如根据功能图标被使用的顺序进行排序,该方案中根据图标被打开的次数进行排序,当用户处于不同的状态如安静或者兴奋时,用户想使用的功能图标并不同,但是该方案中无论何种情况下推送的图标顺序都是相同的。为了根据用户不同的状态推送图标,现有技术中公开了一种程序图标排序方法,包括获取用户的虹膜特征信息;根据获取到的虹膜特征信息,确定用户当前的情绪状态;获取该情绪状态对应的程序使用记录,程序使用记录包括用户在该情绪状态下对各个应用程序的使用信息;根据情绪状态对应的程序使用记录,对应用程序的显示图标进行排序并显示。此方式需要检测用户眼部的虹膜特征信息,确定用户在当前情绪状态下的使用app的使用记录进行排序,因为检测虹膜特征参数较为复杂,造成给移动终端排序更为麻烦。
技术实现要素:
有鉴于此,本发明实施例提供了一种图标排序方法及其装置及移动终端,以解决现有技术当中根据当前情绪状态对图标进行排序时算法复杂、排序麻烦的问题。
本发明第一方面提供了一种图标排序方法及其装置及移动终端,以解决根据不同的情绪状态,给移动终端的应用图标进行排序的问题。
本发明第一方面提供一种图标排序方法,用于移动终端,包括:获取用户当前的声音特征和/或面部特征;根据所述声音特征和/或面部特征获取用户当前情绪状态;根据所述用户当前情绪状态获取与其对应的图标排列顺序,按照所述图标排列顺序对所述图标进行排序。
通过实施第一方面描述的方法,可以根据用户当前的声音特征和/或面部特征获取用户的当前情绪状态,对不同情绪即兴奋或安静时,用户使用图标的习惯或频率,一一对应不同情绪时的图标使用情况,对移动终端的图标进行快速排序,给用户带来方便,增强用户体验,减少查找应用图标的时间。
结合本发明第一方面,本发明第一方面第一实施方式中,所述声音特征包括语速和/或语调。
通过上述描述,声音特征为用户说话时的语速和语调,语速即声音的快慢,语调即音调的高低,通常人们在兴奋的时候,说话都比较欢快,故语速通常较快,语调较轻。
结合本发明第一方面或第一方面第一实施方式,本发明第一方面第二实施方式中,所述面部特征包括面部肌肉的松弛程度、眼睛的形状、嘴巴的形状中的一种或几种。
通过上述描述,面部特征为面部所有器官的状态,如微笑时眼睛的形状,生气时嘴角的闭合状态等,根据在不同的情绪状态时,用户面部所有器官的特征也会发生变化,进而判断出用户的当前情绪状态。
结合本发明第一方面或第一方面第一实施方式或第一方面第二实施方式,本发明第一方面第三实施方式,所述根据所述声音特征和/或面部特征获取用户当前情绪状态的处理,包括:预设每个情绪状态对应的声音特征和/或面部特征的阈值范围;获取所述声音特征和/或面部特征所属的所述阈值范围对应的情绪状态。
通过执行上述步骤,预先设置不同情绪状态时声音特征和/或面部特征阈值范围,即如在兴奋和安静时声音特征和/或面部特征具体存在的范围,然后获取用户当前的声音特征和/或面部特征所存在的阈值范围对应出具体的情绪状态。
结合本发明第一方面或第一方面第一实施方式或第一方面第二实施方式,本发明第一方面第四实施方式,包括:预先建立各个情绪状态对应的图标排列顺序,所述图标排列顺序根据该情绪状态下的图标的使用频率或该情绪状态下的用户习惯来生成。
通过执行上述步骤,排列顺序为行列顺序,此处指排成一列或一行,然后根据用户的不同情绪下的图标使用频率或该情绪状态下用户的使用习惯预先建立图标排列顺序。
此外,发明第二方面提供一种图标排序装置,用于移动终端,包括用于执行上述第一方面或第一方面任意一种实现所描述的图标排序方法的模块或单元。
例如,所述图标排序装置,包括第一获取模块,用于获取用户当前的声音特征和/或面部特征;第二获取模块,用于根据所述声音特征和/或面部特征获取用户当前情绪状态;排序模块,用于根据所述用户当前情绪状态获取与其对应的图标排列顺序,按照所述图标排列顺序对所述图标进行排序。
通过实施第二方面的图标排列装置,可以根据用户当前的声音特征和/或面部特征获取用户的当前情绪状态,对不同情绪即兴奋或安静时,用户使用图标的习惯或频率,一一对应不同情绪时的图标使用习惯,对移动终端的图标进行快速排序,给用户带来方便,增强用户体验,减少查找应用图标的时间。
通过结合本发明第二方面,本发明第二方面的第二实施方式,所述声音特征包括语速和/或语调。
通过实施上述图标排序装置,声音特征为用户说话时的语速和语调,语速即声音的快慢,语调即音调的高低,通常人们在兴奋的时候,说话都比较欢快,故语速通常较快,语调较轻。
通过结合本发明第二方面,本发明的第二实施方式中,所述面部特征包括面部肌肉的松弛程度、眼睛的形状、嘴巴的形状中的一种或几种。
通过上述描述,面部特征为面部所有器官的状态,如微笑时眼睛的形状,生气时嘴角的闭合状态等,根据在不同的情绪状态时用户面部所有器官的特征也会发生变化,进而判断出用户的当前情绪状态。
结合本发明第二方面或第二方面第一实施方式或第二方面第二实施方式,本发明第二方面第三实施方式,所述第二获取模块,包括:预设子模块,用于预设每个情绪状态对应的声音特征和/或面部特征的阈值范围;获取子模块,用于获取所述声音特征和/或面部特征所属的所述阈值范围对应的情绪状态。
上述图标排序装置,预先设置不同情绪状态时声音特征和/或面部特征阈值范围,即如在兴奋和安静时声音特征和/或面部特征具体存在的范围,然后获取用户当前的声音特征和/或面部特征所存在的阈值范围对应出具体的情绪状态。
结合本发明第二方面或第二方面第一实施方式或第二方面第二实施方式,本发明第二方面第四实施方式,包括:预先建立各个情绪状态对应的图标排列顺序,所述图标排列顺序根据该情绪状态下的图标的使用频率或该情绪状态下的用户习惯来生成。
通过执行上述图标排序装置,排列顺序为图标顺序,此处指排成一列或一行,然后根据用户的不同情绪下的图标使用频率或该情绪状态下用户的使用习惯预先建立图标按照由大至小的顺序。
本发明第三方面提供了一种移动终端,包括上述第二方面、第二方面第一实施方式、第二实施方式以及第三实施、第四实施方式所述的图标排序装置。
本发明第四方面还提供了另一种移动终端,包括第一检测单元,用于检测用户当前的声音特征;和/或第二检测单元,用于检测用户当前的面部特征;存储器和处理器;所述第一检测单元、第二检测单元、所述存储器和所述处理器之间通过总线互相连接,所述存储器中存储有计算机指令,所述处理器通过执行所述计算机指令,从而实现以下方法:获取用户当前的声音特征和/或面部特征;根据所述声音特征和/或面部特征获取用户当前情绪状态;根据所述用户当前情绪状态获取与其对应的图标排列顺序,按照所述图标排列顺序对所述图标进行排序。
上述移动终端可以根据用户当前的声音特征和/或面部特征获取用户的当前情绪状态,对不同情绪即兴奋或安静时,使用图标的习惯或频率,一一对应不同情绪时的图标使用情况,对移动终端的图标进行快速排序,给用户带来方便,增强用户体验,减少查找应用图标的时间。
附图说明
通过参考附图会更加清楚的理解本发明的特征和优点,附图是示意性的而不应理解为对本发明进行任何限制,在附图中:
图1示出了本发明实施例中的移动终端的图标排序方法的结构图;
图2示出了本发明实施例中的移动终端的图标排序方法的流程图;
图3示出了本发明实施例中的一种移动终端的结构示意图;
图4示出了本发明实施例中的另一种移动终端的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,是本发明的实施例的应用场景示意图。移动终端可以为手机或平板电脑等移动设备,移动终端以手机为例,手机的部分结构框图如图1所示,手机包括射频电路110、存储器120、输入单元130、显示单元140、传感器150、音频电路160、无线模块170、处理器180以及电源190等部分。本领域技术人员可以理解,图1中示出的手机结构并不构成对手机的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
其中rf电路110用于收发信息或通话过程中,信号的接收和发送。存储器120用于存储软件程序以及模块,处理器180通过运行存储在存储器120的软件程序以及模块,从而执行手机的各种功能应用以及数据处理。输入单元130用于接收输入的数字或字符信息,以及产生与手机的用户设置以及功能控制有关的键信号输入。输入单元130可包括触控面板131以及其他输入设备132。其他输入设备132可以包括但不限于物理键盘、功能键、鼠标、操作杆中的一种或几种。显示单元140用于显示由用户输入的信息或提供给用户的信息以及手机的各种菜单。显示单元140可以包括显示面板141。触控面板131可覆盖显示面板141,当触控面板131检测到在其上或附近的触摸操作后,传送给处理器180以确定触摸事件的类型,随后处理器180根据触摸事件的类型在显示面板141上提供相应的视觉输出。
手机还可包括至少一种传感器150,如光传感器、运动传感器以及其他传感器。光传感器可包括环境光传感器及接近传感器,环境传感器可根据环境光线的明暗来调节显示面板141的亮度,接近传感器可在手机移动到耳边时,关闭显示面板141和/或背光。本实施例中光传感器可以设置在手机的正面和背面的壳体上,用于检测用户持握手机时的遮挡区域。此处还可以包括压力传感器,设置在手机的正面或背面壳体上,用于通过检测压力的方式获得用户持握手机时的遮挡区域。此外,手机还可以配置陀螺仪、气压计、湿度计、温度计、红外线传感器等其他传感器,不再赘述。
音频电路160、扬声器161、传声器162可提供用户与手机之间的音频接口。无线模块170可以是wifi模块,为用户提供无线的互联网访问服务。
处理器180是手机的控制中心,利用各种接口和线路连接整个手机的各个部分,通过运行或执行存储在存储器120内的软件程序和/或模块,以及调用存储在存储器120内的数据,执行手机的各种功能和处理数据,从而对手机进行整体监控。可选的,处理器180可以包括一个或多个处理单元。此外,手机还包括各部件供电的电源190,通过电源管理系统与处理器180逻辑相连,从而通过电源管理系统实现管理充电、放电、以及功耗管理等功能。
尽管未示出,手机还可以包括摄像头、蓝牙模块等,在此不再赘述。
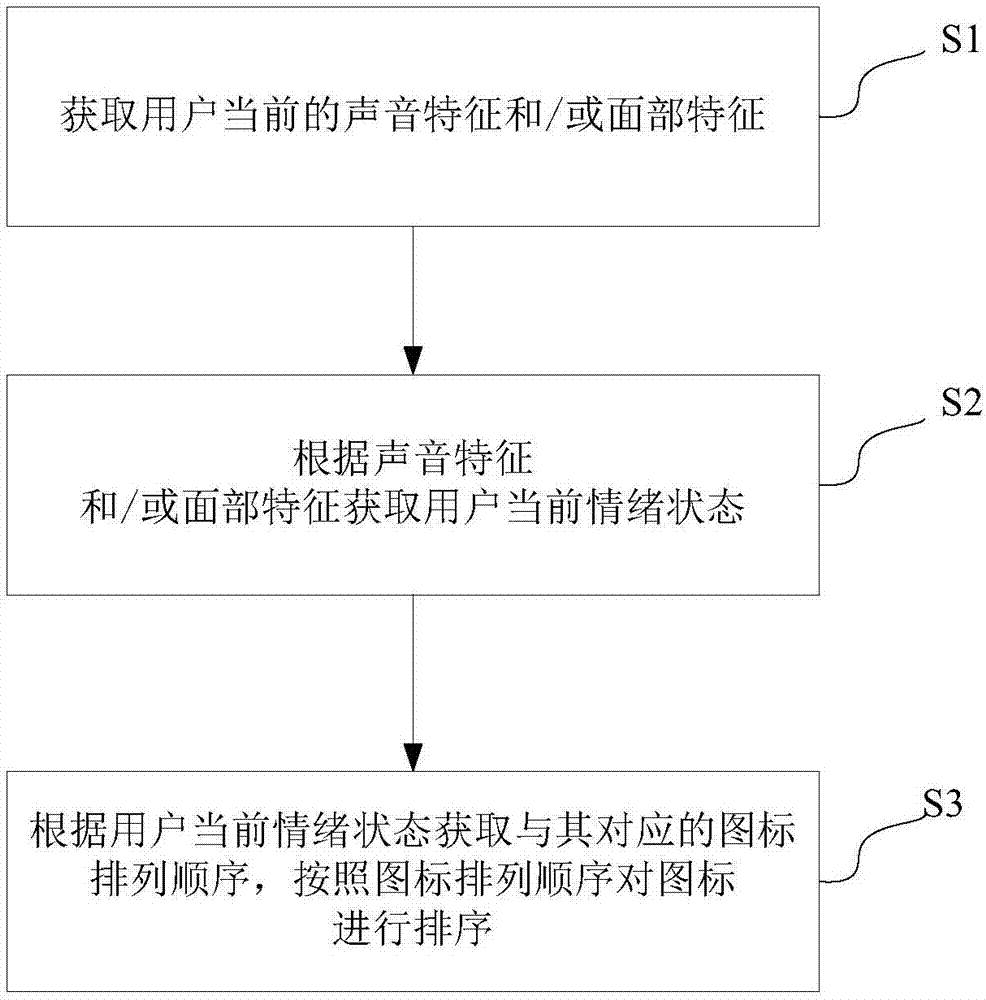
请参阅图2,本发明实施例提供的图标排序方法,可用于上述的移动终端,如手机、平板电脑等,该方法包括:
s1、获取用户当前的声音特征和/或面部特征。
此处的声音特征为用户当前说话时的语速和/或语调,语速即为用户说话时的快慢,语调为用户音调的高低;如在麦克风或话筒拾取用户说话时声音,然后通过显示声音的振动图象,查看声音的振动频率获取用户说话时的快慢和用户说话时的语调,因为音调与频率相关,频率越大,音调越高,当然声音振动地越快,语速也较快。此处也可以通过检测声音的响度特征,通过检测声音的振幅获取用户当前声音的大小,声音的振幅越大说明用户此刻说话声音的响度大,分贝高,声音较强。
此处的面部特征包括面部肌肉的松弛程度、眼睛的形状、嘴巴的形状中的一种或几种的人脸特征,包括用户当前脸部所有五官的特征,如微笑时,用户脸上所有的器官都会有一定的变化,嘴角上扬,眼睛会随之变小,面部肌肉会变松等,生气或大怒时,目瞪口呆,不同的情绪变化,脸部表情也会随之发生改变,一般通过设置在用户移动终端上的前置摄像头可以检测出用户当前面部所有器官的状态,也可以通过一些人脸识别装置进行检测。
s2、根据声音特征和/或面部特征获取用户当前情绪状态。
在上述步骤s1中获取用户当前的声音特征和/或面部特征后,可以了解用户当前情绪所处的状态。如用户遇到兴奋的事情,此时的心情当然处于高兴的状态,他此刻说话的声音一般是欢快的,声音的语速一般较快,语调会高,而此刻脸上扬起快乐的笑容,嘴角的形状和眼睛的大小会有一定的改变。当用户在勃然大怒的时候,心情有些忧伤,嘴角下垂,声音低沉,故面部肌肉较紧,语速和语调较低。所以反之,在获取用户当前声音特征和/或面部特征后,可以了解到用户当前所处的情绪状态。
作为一种可选的实现方式,本实施例中的图标排序方法,上述步骤s2根据声音特征和/或面部特征获取用户当前情绪状态的处理,包括:
首先,预设每个情绪状态对应的声音特征和/或面部特征的阈值范围。
例如,情绪状态一为兴奋状态,情绪状态二为安静状态、情绪状态三为愤怒状态。预设情绪状态一、情绪状态二和情绪状态三对应声音特征的阈值范围和面部特征的阈值范围,因语速和语调都和声音振动频率有关,因面部特征与用户面部的器官状态有关,根据面部器官的不同大小或形状,对应的面部特征不同。当用户处于兴奋状态时:声音振动频率为[60hz,150hz),对应的声音特征的阈值范围为[0.06,0.15),面部特征的阈值范围为[6,15];当用户处于安静状态时:声音振动频率为[0hz,60hz),对应的声音特征的阈值范围为[0,0.06),面部特征的阈值范围为[0,6);当用户处于愤怒状态时,声音振动频率为[150hz,250hz]对应的声音特征的阈值范围为[0.15,0.25],面部特征的阈值范围为[15,25]。故情绪状态一对应的声音特征的阈值范围为[0.06,0.15),情绪状态一对应的面部特征的阈值范围为[6,15];情绪状态二对应的声音特征的阈值范围为[0,0.06),情绪状态二对应的面部特征的阈值范围为[0,6)。情绪状态三对应的声音特征的阈值范围为[0.15,0.25],情绪状态三对应的面部特征的阈值范围为[15,25];上述参数的阈值范围可预先设置,因为用户的情绪状态多种多样,可以根据需要,预先设置多种情绪对应的声音特征和/或面部特征的阈值范围,即为预先设置出情绪状态与声音和/或面部的特征的对应关系。
然后,获取声音特征和/或面部特征所属的阈值范围对应的情绪状态。
此处的声音特征为用户当前的声音特征,面部特征为用户当前的面部特征。通过检测用户当前说话声音的阈值范围对应上述的步骤中提到的预设每个情绪状态对应的声音特征和/或面部特征的阈值范围,确认当前用户的声音特征和面部特征。如当用户的声音特征为0.03,因0.03属于[0,0.06)声音特征的阈值范围,说明用户此刻处于情绪状态二,即安静的状态;当用户的面部特征为8,因8属于[6,15]面部特征的阈值范围,说明用户此刻处于情绪状态一,即兴奋的状态。
具体地,因为用户的情绪通常为悲伤、开心、愤怒等几种情绪。当用户悲伤的时候,情绪一般较为低落,表现出较为安静的状态、故声音低沉,面部表情僵持,这时用户移动终端的前置摄像头,检测出用户脸部肌肉较紧、嘴角紧闭,当前用户面部所有状态的面部特征参数为5,对应上述步骤中面部特征阈值范围[0,6),5属于[0,6),故确定当前面部特征是情绪状态二;或通过移动终端上的话筒拾取用户的声音,通过观察用户声音的振动图像,获取振动频率,根据当前声音振动频率获取用户此时的语速或语调,从而获取声音特征参数为0.04,对应上述步骤中声音特征的阈值范围[0,0.06),0.04属于上述步骤[0,0.06),此时用户的情绪属于情绪二。
具体地,当用户开心的时候,声音较为轻快,满脸微笑。一般也通过移动终端的前置摄像头进行检测用户的脸部或声音特征,跟上述的检测过程一样,通过面部特征参数或声音特征参数分别对应面部特征的阈值范围和声音的特征阈值范围,确定用户的当前情绪。移动终端的前置摄像头检测用户当前的面部是满脸笑容,眼睛的形状变小,嘴角上扬,前置摄像头检测出当前的面部特征总能参数为8,对应上述步骤中面部特征的阈值范围[6,15],8属于面部特征的阈值范围[6,15],故确定当前面部特征属于情绪状态一;或通过移动终端上的话筒拾取用户的声音,通过观察用户声音的振动图像,获取振动频率,根据当前声音振动频率获取用户此时的语速或语调,从而获取声音特征参数为0.07,对应上述步骤中声音特征的阈值范围[0.06,0.15),0.07属于上述步骤[0.06,0.15),此时用户的情绪属于情绪一。
具体地,当用户愤怒的时候,此时用户一般表现声音很大、面红耳赤,目瞪口呆。同样,通过移动终端的前置摄像头进行检测用户脸部或声音特征,跟上述检测过程一样。前置摄像头检测出当前的面部特征参数为17,对应上述步骤中的面部特征阈值范围[15,25],17属于面部特征的阈值范围[15,25],故确定当前面部特征属于情绪状态三;或通过移动终端上的话筒拾取用户的声音,通过观察用户声音的振动图像,获取振动频率,根据当前声音振动频率获取用户此时的语速或语调,从而获取声音特征参数为0.21,对应上述步骤中声音特征的阈值范围[0.15,0.25],0.21属于上述步骤[0.15,0.25],此时用户的情绪属于情绪三。
当然用户的情绪是多样化,如用户有时候会在悲伤的时候声音很大,不太安静,但语调和语速特征参数属于判断安静情绪的状态,声音的大小与响度有关,不是本实施例中采取的实施方式,本实施例主要通过检测声音特征的语速和/或语调。具体通过移动终端的麦克风或话筒拾取声音后,查看声音振动图像查看振动频率,频率越大,语调和语速都会较高,频率越小,语速和语调较低,进而获取声音特征参数。当然,当用户处于歇斯底里的悲伤状态,可以通过检测用户的面部特征参数对应情绪状态的面部特征的阈值范围,确定当前情绪状态。
为一种可选的实现方式,本实施例中的图标排序方法,上述步骤s2根据用户当前情绪状态获取与其对应的图标排列顺序的处理,包括:
预先建立各个情绪状态对应的图标排列顺序,图标排列顺序根据该情绪状态下的图标的使用频率或该情绪状态下的用户习惯来生成。
此处的排列顺序为图标顺序,此处指排成一列或一行的图标顺序,预先建立图标排列顺序,根据情景需要,如将用户的情绪状态一(兴奋)对应的图标排在第一行,然后进行由大至小的顺序进行排序,或将情绪状态二(安静)对应的图标排列在第一行,然后进行编码排序。使用频率即为用户使用app图标的使用次数,用户习惯为该用户的使用app的时长。这种第一行的图标顺序根据用户的使用频率或该情绪状态下的使用习惯预先建立。
s3、根据用户当前情绪状态获取与其对应的图标排列顺序,按照图标排列顺序对图标进行排序。
例如用户使用的移动终端上,设置有这些app图标:qq、微信、微博、视频播放器、wps、有道词典、阅读软件、浏览器,根据用户的使用频率对图标进行排序,如当用户在情绪状态一(兴奋)时,qq使用次数为20、微信使用次数为15、微博使用次数为13、视频播放器使用次数为12、wps使用次数为5、有道词典使用次数为4、阅读软件使用次数为3、浏览器使用次数为2,此时将上述应用app图标排成一行按照使用频率从大到小顺序为qq、微信、微博、视频播放器、wps、有道词典、阅读软件、浏览器,用户的移动终端的尺寸有限,也许一行只能放入qq、微信、微博、视频播放器,剩余的app可以不放入移动终端的屏幕上或放在移动终端屏幕的第二行。如当用户在情绪状态二(安静)时,qq使用次数为3、微信使用次数为2、微博使用次数为1、视频播放器使用次数为0、wps使用次数为21、有道词典使用次数为22、阅读软件使用次数为13、浏览器使用次数为10,此时将上述应用app图标排成一行按照使用频率从大到小的顺序为有道词典、wps、阅读软件、浏览器、qq、微信、微博、视频播放器,同理用户的移动终端的尺寸有限,也许一行只能放入有道词典、wps、阅读软件、浏览器、,剩余的app可以不放入屏幕或放在屏幕第二行。
根据用户的使用习惯对图标进行排序,如当用户在情绪状态一(兴奋)时,qq使用时长为30min、微信使用时长为40min、微博使用时长为20min、视频播放器使用时长为60min、wps使用时长为15min、有道词典使用时长为13min、阅读软件使用时长为5min、浏览器使用时长为2min,此时将上述应用app图标排成一行按照使用频率从大到小顺序为视频播放器、微信、qq、微博、wps、有道词典、阅读软件、浏览器,用户的移动终端的尺寸有限,也许一行只能放入视频播放器、微信、qq、微博,剩余的app可以不放入屏幕或放在屏幕的第二行。情绪状态二(安静)与之同理,按照用户的使用习惯,一般根据使用时长进行由大至小的顺序进行排序。
具体地,该用户使用移动终端的频率或使用习惯,通常可以在一天或半天之内进行检测,如一天内用户使用qq的使用次数,和使用时长。
获取声音特征和/或面部特征所属的阈值范围对应的情绪状态,即检测用户声音特征和/或面部特征的检测时间可以自由设置,如根据在半天内用户使用多个app图标的使用次数或使用时长,从而对移动终端上的图标进行由大至小的顺序进行排序。
参见图3,是本发明实施例提供的一种图标排序装置的示意图,用于移动终端中,其包括:
第一获取模块31,用于获取用户当前的声音特征和/或面部特征;
第二获取模块32,用于根据声音特征和/或面部特征获取用户当前情绪状态;
排序模块33,用于根据用户当前情绪状态获取与其对应的图标排列顺序,按照图标排列顺序对图标进行排序。
通过实施上述图标排序装置,可以根据用户当前的声音特征和/或面部特征获取用户的当前情绪状态,对不同情绪即兴奋或安静时,使用图标的习惯或频率,一一对应不同情绪时的图标使用习惯,对移动终端的图标进行快速排序,给用户带来方便,增强用户体验,减少查找应用图标的时间。
本实施例中的图标排序装置是以功能单元的形式来呈现,这里的单元是指asic电路,执行一个或多个软件或固定程序的处理器和存储器,和/或其他可以提供上述功能的器件。
可选地,图标排序装置,声音特征包括语速和/或语调。
通过实施上述图标排序装置,声音特征为用户说话时的语速和语调,语速即声音的快慢,语调即音调的高低,通常人们在兴奋的时候,说话都比较欢快,故语速通常较快,语调较轻。
可选地,图标排序装置,面部特征包括面部肌肉的松弛程度、眼睛的形状、嘴巴的形状中的一种或几种。
通过上述描述,面部特征为面部所有器官的状态,如微笑时眼睛的形状,生气时嘴角的闭合状态等,根据在不同的情绪状态时用户面部所有器官的特征也会发生变化,进而判断出用户的当前情绪状态。
可选地,图标排序装置,第二获取模块31,包括:预设子模块,用于预设每个情绪状态对应的声音特征和/或面部特征的阈值范围;获取子模块,用于获取声音特征和/或面部特征所属的阈值范围对应的情绪状态。
上述图标排序装置,预先设置不同情绪状态时声音特征和/或面部特征阈值范围,即如在兴奋和安静时声音特征和/或面部特征具体存在的范围,然后获取用户当前的声音特征和/或面部特征所存在的阈值范围对应出具体的情绪状态。
可选地,图标排序装置,第二获取模块31,包括:建立子模块,用于预先建立各个情绪状态对应的图标排列顺序,图标排列顺序根据该情绪状态下的图标的使用频率或该情绪状态下的用户习惯来生成。
通过执行上述图标排序装置,排列顺序为图标顺序,此处指排成一列或一行,然后根据用户的不同情绪下的图标使用频率或该情绪状态下用户的使用习惯预先建立图标按照由大至小的顺序。
上述图标排序装置可以根据用户当前的声音特征和/或面部特征获取用户的当前情绪状态,对不同情绪即兴奋或安静时,使用图标的习惯或频率,一一对应不同情绪时的图标使用情况,对移动终端的图标进行快速排序,给用户带来方便,增强用户体验,减少查找应用图标的时间。
本发明实施例还提供一种移动终端,具有上述图3所示的移动终端的图标排序装置,用于根据所述声音特征和/或面部特征对图标进行排序。
此外,本发明实施例中还提供另外一种移动终端,如图4所示,是本发明实施例提供的移动终端的硬件结构示意图,该设备包括一个或多个处理器41、存储器42、以及用于检测用户当前的声音特征的第一检测单元43,用于检测用户当前的面部特征的第二检测单元44;
图4中以一个处理器41为例。第一检测单元43、第二检测单元44连接处理器41,处理器41连接存储器42,可以通过总线或者其他方式连接,图4中以通过总线连接为例。
处理器41可以为中央处理器(centralprocessingunit,cpu)。处理器41还可以为其他通用处理器、数字信号处理器(digitalsignalprocessor,dsp)、专用集成电路(applicationspecificintegratedcircuit,asic)、现场可编程门阵列(field-programmablegatearray,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等芯片,或者上述各类芯片的组合。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
存储器42作为一种非暂态计算机可读存储介质,可用于存储非暂态软件程序、非暂态计算机可执行程序以及模块,如本申请实施例中的列表项操作的处理方法对应的程序指令/模块。处理器41通过运行存储在存储器42中的非暂态软件程序、指令以及模块,从而执行服务器的各种功能应用以及数据处理,即实现上述方法实施例列表项操作的处理方法。
存储器42可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储根据列表项操作的处理装置的使用所创建的数据等。此外,存储器42可以包括高速随机存取存储器,还可以包括非暂态存储器,例如至少一个磁盘存储器件、闪存器件、或其他非暂态固态存储器件。在一些实施例中,存储器41可选包括相对于处理器42远程设置的存储器,这些远程存储器可以通过网络连接至列表项操作的处理装置。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
第一检测单元43可以是设置在壳体上的声音传感器,也可以是话筒,用于检测移动终端声音特征,第二检测单元44可以是设置在壳体上前置摄像头,用于检测用户当前的面部特征,通过获取用户的声音特特征和/或面部特征根据与其对应的不同情绪状态对移动终端的图标进行排序。
上述移动过终端可执行本发明实施例所提供的方法,具备执行方法相应的功能模块和有益效果。所述处理器41通过执行所述计算机指令,从而实现以下方法:
首先,获取用户当前的声音特征和/或面部特征;
其中,声音特征包括语速和/或语调。面部特征包括面部肌肉的松弛程度、眼睛的形状、嘴巴的形状中的一种或几种。
然后,根据声音特征和/或面部特征获取用户当前情绪状态;
作为一种可选的实现方式,根据声音特征和/或面部特征获取用户当前情绪状态的处理,包括:
第一步,预设每个情绪状态对应的声音特征和/或面部特征的阈值范围;
第二步,获取声音特征和/或面部特征所属的阈值范围对应的情绪状态。
作为另一种可选的实现方式,根据用户当前情绪状态获取与其对应的图标排列顺序的处理,包括:
预先建立各个情绪状态对应的图标排列顺序,图标排列顺序根据该情绪状态下的图标的使用频率或该情绪状态下的用户习惯来生成。
最后,根据用户当前情绪状态获取与其对应的图标排列顺序,按照图标排列顺序对图标进行排序。
上述移动终端可以根据用户当前的声音特征和/或面部特征获取用户的当前情绪状态,对不同情绪即兴奋或安静时,使用图标的习惯或频率,一一对应不同情绪时的图标使用情况,对移动终端的图标进行快速排序,给用户带来方便,增强用户体验,减少查找应用图标的时间。
本领域技术人员可以理解,实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(rom)或随机存储记忆体(ram)等。
虽然结合附图描述了本发明的实施例,但是本领域技术人员可以在不脱离本发明的精神和范围的情况下作出各种修改和变型,这样的修改和变型均落入由所附权利要求所限定的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!