一种便于电力调度的风电功率预测系统的制作方法
本发明涉及电力技术领域,具体涉及一种便于电力调度的风电功率预测系统。
背景技术:
风电场在接入电网后对电力系统的经济调度和安全稳定带来了严峻挑战。如果能对风电场功率进行准确有效的预测,将使电力调度部门能够提前根据风电场出力变化情况及时合理的调整调度计划。从而减轻风电并网对电网造成的不利影响,减少系统的备用容量,整体上降低风电并网的运行成本。
技术实现要素:
针对上述问题,本发明提供一种便于电力调度的风电功率预测系统。
本发明的目的采用以下技术方案来实现:
提供了一种便于电力调度的风电功率预测系统,包括数据提取模块、数据预处理模块、训练模块、风电功率预测模块,所述数据提取模块用于从数值天气预报系统或者电力系统的相关数据采集与监视控制系统中进行数据提取,获得多个初步样本;所述数据预处理模块用于对初步样本的数据进行预处理,并根据预处理后的数据确定训练样本;所述训练模块用于采用改进的粒子群算法优化支持向量机的参数,采用训练样本以及优化后的支持向量机的参数对支持向量机进行训练,得到支持向量机模型;所述风电功率预测模块用于采用得到的支持向量机模型进行风电功率预测,并输出风电功率预测结果。
本发明的有益效果为:建模过程简单实用,能快速有效的进行风电功率预测,对于电力系统的安全稳定和调度运行具有重要意义,具有广泛的推广应用价值。
附图说明
利用附图对本发明作进一步说明,但附图中的实施例不构成对本发明的任何限制,对于本领域的普通技术人员,在不付出创造性劳动的前提下,还可以根据以下附图获得其它的附图。
图1本发明的结构连接框图;
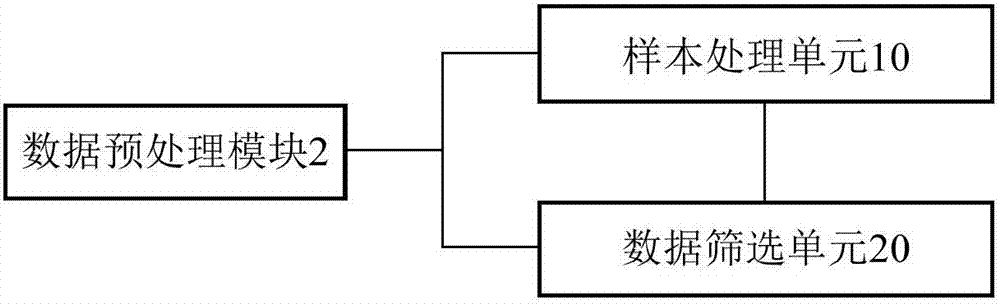
图2是本发明数据预处理模块的结构连接框图。
附图标记:
数据提取模块1、数据预处理模块2、训练模块3、风电功率预测模块4、样本处理单元10、数据筛选单元20。
具体实施方式
结合以下实施例对本发明作进一步描述。
参见图1,本实施例提供的一种便于电力调度的风电功率预测系统,包括数据提取模块1、数据预处理模块2、训练模块3、风电功率预测模块4,所述数据提取模块1用于从数值天气预报系统或者电力系统的相关数据采集与监视控制系统中进行数据提取,获得多个初步样本;所述数据预处理模块2用于对初步样本的数据进行预处理,并根据预处理后的数据确定训练样本;所述训练模块3用于采用改进的粒子群算法优化支持向量机的参数,采用训练样本以及优化后的支持向量机的参数对支持向量机进行训练,得到支持向量机模型;所述风电功率预测模块4用于采用得到的支持向量机模型进行风电功率预测,并输出风电功率预测结果。
优选地,提取的数据包括风速、温度以及风电场实测输出功率数据,所述风速、温度作为支持向量机训练样本的输入数据,所述风电场实测输出功率数据作为支持向量机训练样本的输出数据。
优选地,采用得到的支持向量机模型进行风电功率预测时,采用实时风速和实时温度作为预测的输入。
本发明上述实施例适应性强,可作为一般风电场的功率预测模型,建模过程简单实用,能快速有效的进行风电功率预测,对于电力系统的安全稳定和调度运行具有重要意义,具有广泛的推广应用价值。
优选地,如图2所示,所述数据预处理模块2包括用于对初步样本进行筛选处理的样本处理单元10以及用于对筛选出的初步样本中的数据进行筛选处理的数据筛选单元20;
其中样本处理单元10对初步样本的筛选处理,具体为:
(1)计算各初步样本间的马氏距离:
其中
式中,φ(xa,xb)表示初步样本xa与初步样本xb之间的马氏距离,
(2)若满足下列筛选公式,则删除初步样本xa:
其中ρ1、ρ2为设定的阈值调整因子,
本优选实施例对相似度较高的初步样本进行筛选,能够在保证保留有效初步样本的前提下从整体上减少支持向量机模型的训练时间,提高风电功率预测的效率。
优选地,数据筛选单元20按照下列筛选函数对筛选出的初步样本中的数据进行筛选处理:
kα={kα(β),kα(β)=1,β=1,…,wα}
其中
式中,kα表示对应第α个初步样本的训练样本,kα(β)表示第α个初步样本中第β个数据,wα为第α个初步样本具有的数据的数目;μα为第α个初步样本的数据的期望值,vα为第α个初步样本的数据的标准差,η1、η2为设定的调整因子;f[x]为判定函数,当x≥0时,f[x]=1,当x<0时,f[x]=0。
本优选实施例能够优化初步样本中的数据,从而采用优化的初步样本对支持向量机进行训练,一方面减少了支持向量机模型的训练时间,另一方面能够获得更精确的训练效果,从而能够提高风电场功率的预测精度,获得精度较高的风电场功率的预测结果。
优选地,所述采用改进的粒子群算法优化支持向量机的参数,具体包括:
(1)定义支持向量机的核函数为:
γ=ε2xtxα+(1-ε2)exp(g‖x-xα‖2)
式中,ε为权重系数,xtxα为线性核函数,exp(g‖x-xα‖2)为高斯核函数,其中g为高斯核函数宽度。
(2)将支持向量回归惩罚系数c、核函数宽度g、权重系数δ三个参数作为需优化参数,将该需优化参数设定为粒子群中的粒子;
(3)采用改进的粒子群算法对该需优化参数进行优化。
本优选实施例将线性核函数与高斯核函数进行相应的组合后作为最终的核函数,并对其中的支持向量回归惩罚系数c、核函数宽度g、权重系数δ三个参数进行优化,能够在高维特征空间中更好地表达初步样本;
另外,本优选实施例中优化的参数不多,相对于其他多核函数,支持向量机训练过程较为简单,训练的支持向量机具有较好的回归精度和泛化能力,从而能够提高支持向量机模型的预测精度,获得更优异的风电功率预测效果。
优选地,所述采用改进的粒子群算法对该需优化参数进行优化,具体为:
1)初始化粒子群算法,设定粒子数目、迭代次数、学习因子、模拟退火系数,选定正交试验设计表,正交试验设计表列数大于粒子的维度,设定支持向量回归惩罚系数c、核函数宽度g、权重系数δ三个参数的搜索范围以及移动速度的上下限;
2)计算各粒子的速度,判断各粒子的速度是否越界,如果越界,则将该粒子的速度取为临界值;
3)更新各粒子的位置,以下列适应度函数计算出的适应度评价各粒子:
式中,wt为训练样本总个数,yk为训练样本实际值,yk′为训练样本预测值;
4)根据正交试验表从最优粒子和次优粒子中选取相应维,进行正交试验,评价各试验粒子;
5)根据判断各维中的因素水平的优劣,设计最终粒子并评价该粒子;
6)从最终粒子和试验粒子中选取适应度最高的粒子,并和群历史最优粒子作比较,如果优于群历史最优粒子,则替代群历史最优粒子,并以一定概率进行模拟退火搜索;
7)若达到最大迭代次数,结束搜索,输出最优粒子和最优粒子的供电电路函数值。
本优选实施例采用正交试验和模拟退火搜索相结合的方式进行参数优化,解决了传统粒子群算法存在的早熟问题和收敛震荡问题,加强了群最优粒子跳出局部最优点的能力;
另外,本优选实施例采用正交试验从群最优粒子和次优粒子中有效提取了有价值的信息,能够提升粒子群算法在捜索结果的平均值、标准偏差、评价次数、成功率和成功表现等方面的性能,并且本优选实施例的正交试验相对于传统的正交粒子群算法,大大减少了信息抽取的运算量。
最后应当说明的是,以上实施例仅用以说明本发明的技术方案,而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细地说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。
- 还没有人留言评论。精彩留言会获得点赞!