一种基于Hadoop的用户行为数据处理方法与流程
本发明属于通信技术领域,涉及一种基于hadoop的用户行为数据处理方法。
背景技术:
随着4g网络的商用和广泛部署,移动通信业务已经正式全面进入移动互联网时代,飞速发展的移动网络带宽直接带来繁杂的应用和用户行为,而通信网络中的数据复杂度、信息量都随之迅速增长,导致数据处理的复杂度和运算量要求都随之有了更高的要求,传统数据库体系的数据处理能力受到了极大的挑战。而面对海量数据处理需求和更低的时延性限制要求,传统数据系统投入的cpu计算能力、内存响应和吞吐、网络带宽都有着巨大的基准,且在高安全性,多中心的发展趋势下面临诸多的瓶颈。大数据时代的到来使单节点的计算模式已经不能满足数据处理的需求,分布式数据处理与存储系统逐步成为大数据平台首选的架构,大数据技术成为了众相研究的热点。而hadoop大数据平台主要基于静态数据文件的并行处理,虽然在海量数据吞吐、计算、存储方面有着极高的效率,但是实时性较差,属于高吞吐,高并发,高时延的架构,对于小文件的处理性能一直是其不可回避的问题,故针对一些实时性较高的数据处理和使用场景下无能为力。
目前还没有一种用于互联网用户实时数据和历史(离线)数据整合处理的方法,特别是能够适应运营商大数据发展的精细化运营方法。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于hadoop的用户行为数据处理方法,能够建立高效、精细化的用户行为数据业务体系。
为达到上述目的,本发明提供如下技术方案:
一种基于hadoop的用户行为数据处理方法,所述方法包括:
将用户历史数据源导入到分布式文件系统hdfs中,以通过所述hdfs提供数据访问接口;其中,所述用户历史数据源包括国际移动用户识别码imsi库、国际移动设备身份码imei库以及爬虫库中的至少一种;
基于所述用户历史数据源生成用户的历史行为数据表;
通过数据采集工具flume收集用户的实时行为数据流,所述实时行为数据流包括用户实时上网日志以及用户互联网行为实时解析数据;
分布式订阅系统kafka实时记录从所述flume收集的数据,并作为消息缓冲组件为实时计算框架提供数据;
根据实时行为数据流的不同业务类型,运用实时计算框架spark实时处理用户行为产生的实时数据,以生成用户的实时数据表;
运用所述imsi库中的imsi号关联用户的实时数据表和历史行为数据表,得到用户的行为数据宽表;
根据预设配置文件将所述用户的行为数据宽表输出并保存到hbase数据库中;
将查询系统impala与hbase数据库整合,以向外部提供用户行为数据的查询入口。
进一步地,基于所述用户历史数据源生成用户的历史行为数据表包括:
通过所述imsi库中的imsi号关联所述用户的所有历史行为数据,并将所述用户的所有历史行为数据映射至数据仓库工具hive中,以形成所述用户的历史行为数据表。
进一步地,在分布式订阅系统kafka实时记录从所述flume收集的数据之后,所述方法还包括:
判断待处理的数据是否已经缓冲到kafka配置文件中;若是,将所述待处理的数据发送至所述实时计算框架spark;若否,将所述到处理的数据反馈至所述分布式订阅系统kafka。
进一步地,所述imsi库、imei库以及爬虫库通过sqoop从关系型数据库导入到hdfs中。
进一步地,所述用户的事实行为数据流中包括用户在移动终端的访问特性、搜索信息以及流量消耗对应的实时数据。
进一步地,得到用户的行为数据宽表包括:
基于不同的业务逻辑,运用map/reduce框架获得所有输入用户的实时数据表和历史行为数据表的输出值,以形成所述行为数据宽表;其中,一个imsi号表征一个用户。
进一步地,所述hbase数据库中表的结构包括imsi号与业务编号的组合以及用于存放用户具体业务信息的列。
本发明的有益效果在于:
(1)本发明将用户的海量历史原始数据存储在hdfs上,为原始数据提供具备高容错、高吞吐、低成本的存储空间,支持以流的形式访问文件系统中的数据;通过数据采集工具flume收集用户行为的实时数据,实时数据包括用户实时上网日志、用户互联网行为实时解析数据,kafka实时记录从flume收集的数据,并作为消息缓冲组件为上层实时计算框架提供可靠数据支撑,然后运用spark内存计算框架实时处理用户行为产生的实时数据。通过imsi号关联用户的实时数据和历史数据,得到统一的用户行为数据宽表,并存储在分布式数据库hbase中,为海量用户行为数据的存储提供了一个可行的解决方案,缓解了传统方法中单机存储客户数据的压力。
(2)本发明基于hadoop平台,将建立精细化用户行为体系任务分发到由低配置的计算机组成的集群环境中,运用impala与hbase整合提供用户行为数据高效查询引擎,减少查询时间延迟,比原生的mapreduce以及hive的执行速度快很多。
(3)本发明所述的用户行为数据生成方法,相对于传统用户单一的数据而言,该方法建立了高效、精细化的用户行为数据业务体系,同时具备高扩展性,有效提升运营商精细化运营能力。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为本发明提供的一种基于hadoop的用户行为数据生成方法的流程图;
图2为本发明中用户历史行为数据表的设计示意图;
图3为本发明中用户实时行为数据的模型设计示意图;
图4为本发明中用户行为数据宽表的设计示意图;
图5为本发明中hbase存储结构图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
请参阅图1,本申请实施方式提供一种基于hadoop的用户行为数据处理方法,所述方法包括:
将用户历史数据源导入到分布式文件系统hdfs中,以通过所述hdfs提供数据访问接口;其中,所述用户历史数据源包括国际移动用户识别码imsi库、国际移动设备身份码imei库以及爬虫库中的至少一种;
基于所述用户历史数据源生成用户的历史行为数据表;
通过数据采集工具flume收集用户的实时行为数据流,所述实时行为数据流包括用户实时上网日志以及用户互联网行为实时解析数据;
分布式订阅系统kafka实时记录从所述flume收集的数据,并作为消息缓冲组件为实时计算框架提供数据;
根据实时行为数据流的不同业务类型,运用实时计算框架spark实时处理用户行为产生的实时数据,以生成用户的实时数据表;
运用所述imsi库中的imsi号关联用户的实时数据表和历史行为数据表,得到用户的行为数据宽表;
根据预设配置文件将所述用户的行为数据宽表输出并保存到hbase数据库中;
将查询系统impala与hbase数据库整合,以向外部提供用户行为数据的查询入口。
在本实施方式中,基于所述用户历史数据源生成用户的历史行为数据表包括:
通过所述imsi库中的imsi号关联所述用户的所有历史行为数据,并将所述用户的所有历史行为数据映射至数据仓库工具hive中,以形成所述用户的历史行为数据表。
在本实施方式中,在分布式订阅系统kafka实时记录从所述flume收集的数据之后,所述方法还包括:
判断待处理的数据是否已经缓冲到kafka配置文件中;若是,将所述待处理的数据发送至所述实时计算框架spark;若否,将所述到处理的数据反馈至所述分布式订阅系统kafka。
在本实施方式中,所述imsi库、imei库以及爬虫库通过sqoop从关系型数据库导入到hdfs中。
在本实施方式中,所述用户的事实行为数据流中包括用户在移动终端的访问特性、搜索信息以及流量消耗对应的实时数据。
在本实施方式中,得到用户的行为数据宽表包括:
基于不同的业务逻辑,运用map/reduce框架获得所有输入用户的实时数据表和历史行为数据表的输出值,以形成所述行为数据宽表;其中,一个imsi号表征一个用户。
在本实施方式中,所述hbase数据库中表的结构包括imsi号与业务编号的组合以及用于存放用户具体业务信息的列。
在本实施方式中,hadoop是apache组织管理的一个开源项目,目前得到了大量的应用,hadoop已经成长为包括hadoopcommon,hdfs,mapreduce,zookeeper,avro,chukwa,hbase,hive,mahout,pig在内的10个子项目,hadoop的核心是由hadoopcommon、hdfs(hadoopdistributedfilesystem)以及mapreduce三个子系统组成。其中hadoopcommon部分为hadoop整体的架构提供了基础支撑性功能,主要包括了文件系统、远程过程调用协议和数据串行化库;hdfs是分布式文件系统,具有高容错性而且使用成本比较低特点;mapreduce主要用于大规模计算机集群上编写对海量数据进行快速处理的并行化程序是一个编程模型和软件框架。
spark是一个分布式的内存计算框架,其特点是能处理大规模数据,计算速度快。spark需要集成hadoop的分布式文件系统才能运作,它延续了hadoop的mapreduce计算模型,相比之下spark的计算过程保持在内存中,减少了硬盘读写,能够将多个操作进行合并后计算,因此提升了计算速度。spark必须搭在hadoop集群上,它的数据来源是hdfs,本质上是yarn上的一个计算框架,像mapreduce一样。spark核心部分分为rdd。sparksql、sparkstreaming、mllib、graphx、sparkr等核心组件解决了很多的大数据问题,其完美的框架日受欢迎。其相应的生态环境包括zepplin等可视化方面,正日益壮大。spark读写过程不像hadoop溢出写入磁盘,都是基于内存,因此速度很快。另外dag作业调度系统的宽窄依赖让spark速度提高。
sqoop是在关系型数据库和hdfs间高效传输数据的工具,可以将一个关系型数据库中的数据导入到hadoop的hdfs中,也可以将hdfs的数据导进关系型数据库中。
flume是cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。kafka可实时记录从数据采集工具flume中收集的数据,并作为消息缓冲组件为上游实时计算框架提供可靠数据支撑。
hbase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用hbase技术可在廉价pcserver上搭建起大规模结构化存储集群。hbase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
impala是由cloudera公司主导开发的大数据实时查询分析工具,比原来基于mapreduce的hivesql查询速度提升3~90倍,且更加灵活易用。提供类sql的查询语句,能够查询存储在hadoop的hdfs和hbase中的pb级大数据。查询速度快是其最大的优势。impala作为大数据实时查询分析工具,具有查询速度快,灵活性高,易整合,可伸缩性强等特点。
以用户历史行为数据(区域属性、用户办理套餐)和用户当天当前使用的app时长为例,本发明提供的技术方案包括以下步骤:
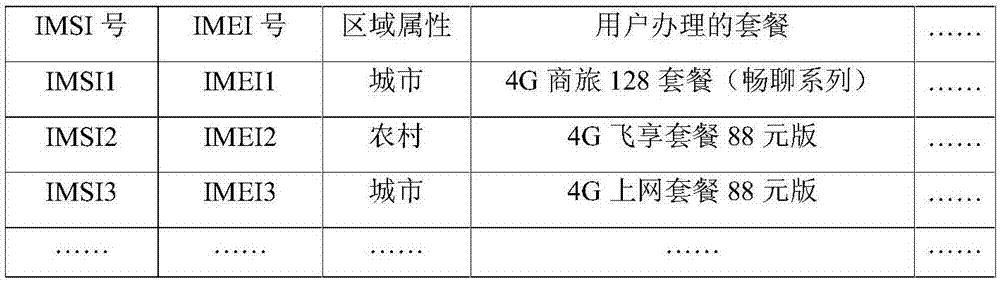
步骤1:将用户历史数据源导入到分布式文件系统hdfs,由hdfs提供高吞吐量的数据访问能力,其中数据源包括imsi库、imei库、爬虫库;imsi库、imei库、爬虫库通过sqoop从关系型数据库导入到hdfs,用户历史数据源的表格式如图2所示。
步骤2:通过数据采集工具flume收集用户行为的实时数据,实时数据以用户当天当前使用app时长为例,kafka实时记录从flume收集的数据,并作为消息缓冲组件为上层实时计算框架提供可靠数据支撑。
步骤3:根据步骤2的例子进行说明,通过spark实时数据处理工具处理用户app的使用时长,从而计算出当前用户当天使用的各个app的使用时长并实时输出,同样的,当计算满一天,一周,一月,均会将数据进行输出,实时数据结构如图3所示。
步骤4:根据不同的业务逻辑,本例中的业务逻辑为用户办理套餐和app的使用时长,运用map/reduce框架获得所有输入用户(一个imsi代表一个用户)的输出值,形成用户行为表,表格式如图4所示。
步骤5:根据配置文件,将用户行为数据保存到hbase中,整合impala与hbase提供用户行为数据的查询入口,相比原生的mapreduce以及hive的执行速度,将大幅度地提高用户行为数据宽表的统计分析速度。hbase中存储结构如图5所示,rowkey为imsi+业务编号,列簇中有一列data:label,存放着用户具体业务信息。
本发明的有益效果在于:
(1)本发明将用户的海量历史原始数据存储在hdfs上,为原始数据提供具备高容错、高吞吐、低成本的存储空间,支持以流的形式访问文件系统中的数据;通过数据采集工具flume收集用户行为的实时数据,实时数据包括用户实时上网日志、用户互联网行为实时解析数据,kafka实时记录从flume收集的数据,并作为消息缓冲组件为上层实时计算框架提供可靠数据支撑,然后运用spark内存计算框架实时处理用户行为产生的实时数据。通过imsi号关联用户的实时数据和历史数据,得到统一的用户行为数据宽表,并存储在分布式数据库hbase中,为海量用户行为数据的存储提供了一个可行的解决方案,缓解了传统方法中单机存储客户数据的压力。
(2)本发明基于hadoop平台,将建立精细化用户行为体系任务分发到由低配置的计算机组成的集群环境中,运用impala与hbase整合提供用户行为数据高效查询引擎,减少查询时间延迟,比原生的mapreduce以及hive的执行速度快很多。
(3)本发明所述的用户行为数据生成方法,相对于传统用户单一的数据而言,该方法建立了高效、精细化的用户行为数据业务体系,同时具备高扩展性,有效提升运营商精细化运营能力。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!