一种面向云计算应用的同态加密密文检索方法与流程
技术领域:
本发明属于云计算应用技术领域,特别涉及一种面向云计算应用的同态加密密文检索方法。
背景技术:
:
云计算是一种创新的服务模式,它能够使用户通过互联网随时获得近乎无限的计算能力和丰富多样的信息服务,是分布式计算、并行计算和网格计算的演进。云存储也属于云计算范畴,应用日渐普及。随着云计算的迅速发展,大量敏感信息被集中到云端。为了避免客户的隐私数据泄露,须将隐私数据进行加密处理后存储在云端。当保存在云服务器端的密文数据发展到了一定规模时,对密文数据的有效检索将是一个亟待解决的问题。
现有同态加密密文检索方案中,一般将文档集的预处理等大量工作放置于客户端进行。2014年有文献将tf-idf向量检索模型应用于同态加密密文检索方案中,其方案的基本思路是首先在客户端对文档集选择相应的关键词,计算关键词对文档集中各个文档的tf-idf权重,构建每一篇文档的tf-idf权重向量,得到文档集的权重向量集。之后对权重向量集中的向量分别进行加密并上传至云端进行保存。在检索的时候,首先在客户端计算检索项的权重向量,并对其加密后上传至云端,之后使用检索项的权重向量密文与文档集的权重向量集密文,计算出检索项与文档集中各个文档的相似度密文并返回给用户,用户在客户端对排序密文解密得到明文排序结果。
上述密文检索方案,增加了客户端的计算压力,且没有充分利用云端的计算能力。
本发明提出的面向云计算的同态密文检索方法,将文档集的预处理等大量工作移到云端来进行,云端对加密后的文档实施预处理,能够充分利用云端的计算能力,进而实现高效的同态密文检索。
技术实现要素:
本发明为了克服密文检索方案中,没有充分利用云端的计算能力,从而导致客户端的计算压力非常大等缺点,提出了一种充分利用云端的计算能力,即面向云计算应用的同态加密密文检索方法,该方法与已有方法相比,明显的提高了检索工作效率,减轻了客户端的计算压力。
本发明解决其技术问题所采用的技术方案是:一种面向云计算应用的同态加密密文检索方法,其特征在于,该方法包括以下步骤:
步骤1:在客户端对文档集加密并上传至云端
在客户端,用户采用整数全同态加密算法对文档集中的每篇文档进行加密,然后上传至云端保存。
(1)加密算法
keygen:选择一个随机产生的p位的安全大素数作为密钥p,其中p∈[2p-1,2p];
encrypt(m):随机选取一个q位安全大素数q,其中,q∈[2q-1,2q],p>q>明文分组长度,随机数r是在规定的时间间隔内随机选取的,对m进行分组m=m1m2m3...mt(mi的长度为l),计算密文ci=mi+2pq+pqr,即可得到密文;
decrypt(c):计算mi=cimodp,得到明文消息m=m1m2m3...mt,即得到解密后的明文;
同态性分析:设有两个明文m1,m2,其对应的密文分别为c1,c2,则
c1=m1+2pq+pqr1
c2=m2+2pq+pqr2
加法同态性分析:
c1+c2=(m1+m2)+4pq+pq(r1+r2),因为(c1+c2)modp=m1+m2,因此该算法满足加法同态;
乘法同态性分析:
c1*c2=(m1*m2)+2m1pq+m1pqr2+2m2pq+4p2q2+2p2q2r2+m2pqr1+2p2q2r1+p2q2r1r2=(m1*m2)+2pq(m1+m2)+pq(m1r2+m2r1)+2p2q2(r2+r1)+4p2q2+p2q2r1r2,
因为(c1*c2)modp=m1*m2,因此该算法满足乘法同态性。
(2)关键词mindex的查询匹配算法
a、采用上述加密算法,在客户端对关键词加密,得到对应的密文cindex=mindex+2pq+pqr,并上传到云端;
b、云端接收到密文关键词cindex后,采用密文匹配算法进行查询,其中n=pq,匹配公式retrieval=(ci-cindex)modn=((mi-mindex)+pq(r1-r2))modn;
若retrieval=0,则mi-mindex=0,即当mi=mindex的时候,pq(r1-r2)modn=0,所以retrieval=0,检索时只需向云端上传n,其中n=pq,云端无法推出用户的密钥p,但服务器能够直接对用户的密文进行查询匹配操作。
步骤2:在云端对密文文档集进行预处理操作
云端首先生成密文文档集的副本,预处理操作都是对副本进行,预处理分为三个阶段,即分词过滤,建立倒排索引,生成文档集的权重向量集。
(1)分词过滤
英文一般通过空格来分割词条,而中文汉字则不能通过这种方式,最简单的方式就是单个汉字作为一个词条。
分词后需要剔除对文档集的检索没有任何意义的关键词,即停用词。对每一个关键词,看其是否存在于停用词列表中,如果存在则将其从文档中删除过滤掉;由于原始文档集在客户端已经进行加密处理了,在加密的情况下进行查找密文停用词可以采用线性匹配的方法进行查找;进行匹配查询的方法如下:
在步骤1中,客户端已经采用公式(1)将停用词加密后上传至云端,云端保存密文停用词,采用公式(2)将文档集中的每个关键词进行加密并上传至云端保存;
假设云端文档中的密文关键词为tindex,存储在云端的密文停用词为ti,则有:
ti=mi+2pq+pqr2公式(1)
tindex=mindex+2pq+pqr1公式(2)
在云端通过公式(3)对云端每篇密文文档中的每个关键词,都进行过滤处理,其查询的匹配公式为:
此匹配操作是在云端进行的,设结果为retrieval,若retrieval=0,则ti-tindex=0,则表示在密文文档中查询到了密文停用词,在使用上述公式时,只需向云端上传n,其中n=pq,所以从n是无法得出密钥p的,所以上述公式是安全并可靠的;
最后将所有查询到的密文停用词删除过滤处理之后,生成新的文档集,其中的每一篇文档用dj表示。
(2)建立倒排索引
本发明将倒排索引的建立放在服务器端进行,在加密条件下统计出关键词ki的词频tfi以及逆文档频率idfi,最后生成密文文档集的倒排索引表;
假设在云端需要统计的密文关键词为ckindex,存储在云端的密文关键词为ci,则有
ckindex=mkindex+2pq+pqr1公式(4)
ci=mi+2pq+pqr2公式(5)
令,
此匹配操作是在云端进行的,公式(6)中,设结果为retrieval,若retrieval=0,则ci-ckindex=0,则表示在此篇密文文档中找到了需要统计的密文关键词ckindex,即匹配查询到一个,词频fij记数count增加1,出现的文档数ni表示该统计的密文关键词ckindex在文档集中出现的文档数量,最后经过统计得到该密文关键词的fij和ni;在使用上述公式时,只需向云端上传n,其中n=pq,所以从n是无法得出密钥p的,所以上述公式是安全并可靠的。
对根据统计得到的数据进行记录,如表1所示;
表1倒排索引表
如表1所示,文档名及关键词在云端仍然是加密状态,然而统计得到的文档编号、出现频率和出现的文档数在云端为明文形式。
(3)生成文件向量集
用户在进行关键词检索时,待检索的文档集其实对应的是文档集的权重向量集,在倒排索引表更新完成以后,根据统计出的关键词词频与逆文档频率,生成文档集对应的权重向量集;本发明所使用的权重计算框架是tf-idf框架,其中tf代表的是关键词的词频,idf代表的是关键词的逆文档频率;本发明采用的计算权重向量的值如公式(7)所示:
其中wij代表关键词ki对文档dj的tf-idf权重,fij表示关键词ki出现在文档dj中的频率,即出现的次数,n表示文档集中文档的总数量,ni表示文档集中包含关键词ki的文档数量,n/ni代表关键词ki的逆文档频率;
设密文文档dj有t个密文关键词ki,且它们之间相互独立,定义密文文档dj为t维空间上的向量,根据上述公式求得密文文档dj中各个密文关键词ki的权重值,进而生成密文文档的明文权重向量,其中每个密文关键词ki求得的权重值都为明文;则dj的值如公式(8)所示:
步骤3:检索过程
客户端将明文检索项加密上传至云端,在云端对密文检索项做和密文文档集一样的预处理工作,将密文检索项进行分词过滤操作,此过程如同在云端对密文文档进行分词过滤掉密文停用词,再建立密文检索项的倒排索引,最后生成密文检索项的明文权重向量,其中的每一项都是相应密文关键词在密文检索项中的明文权重值,该明文权重值的计算公式如公式(9)所示:
设密文检索项q有t个密文关键词ki,且它们之间相互独立,根据上述公式求得密文检索项q中各个密文关键词ki的明文权重值,进而生成密文检索项的明文权重向量,其中每个密文关键词ki求得的权重值都为明文;则q的值如公式(10)所示:
检索过程其实是对密文检索项的明文权重向量与密文文档集中各密文文档的明文权重向量进行相似度计算,相似度的计算公式如下:
设密文文档的明文权重向量为
其中,|dj|和|q|分别为在云端计算得到的密文文档的明文向量模和密文检索项的明文向量模,在云端利用公式(11)计算得到密文关键词与每篇密文文档的相似度计算结果,并对计算结果按相似度大小进行排序,将相似度高的,即与查询相关程度高的文档排在前面,从而有利于用户查找,最后云端将相似度排序结果返回给客户端供用户进行查看。
步骤4:文档下载
根据上一步检索到想要的文档之后,可以对选定的文档进行下载,首先在客户端输入待下载的文档名,采用公式(12)将待下载的文档名加密上传至云端保存,采用公式(13)文档集的每篇文档名进行加密并上传至云端保存;假设存储在云端的待下载文件的密文文件名为cindex,云端文档的密文文件名为ci,则有
cindex=mindex+2pq+pqr1公式(12)
ci=mi+2pq+pqr2公式(13)
同样,因为同态加密技术对同一数据加密两次所得的密文是不同的,所以需将待下载的密文文档名与文档集中的各密文文档名通过公式(14)进行匹配,设匹配结果为retrieval,则
此匹配操作是在云端进行的,通过公式(14)可以在云端检索到要下载的文档,若retrieval=0,则ci-cindex=0,则表示在密文文档中查询到了该密文文档,在使用上述公式时,只需向云端上传n,其中n=pq,所以从n是无法得出密钥p的。
本发明的有益效果:
在云计算密文检索应用领域,基于tf-idf向量检索模型的同态加密密文检索方法较有优势,现有方案多是将文档集的预处理等大量工作放置于客户端进行处理,客户端处理大量的工作,云端只处理少量工作,这样做的缺点是增加了客户端的压力,并未利用云端本身强大的计算能力。
本发明将预处理阶段放到云端来进行实施,与将预处理阶段放到客户端进行处理的方案进行对比,这样处理的好处是:减轻了客户端的计算压力,能够充分利用云计算强大的计算能力及存储能力来对数据进行操作,提高检索工作效率。
本发明的创新点可总结如下:
(1)将文档集的预处理等大量工作尽量迁移到云端进行,文档的tf-idf权重向量都是在云端计算得到;
(2)云端基于同态加密后的文档,可以对密文进行同态性操作和计算,构建出每篇文档的tf-idf权重向量,并以明文方式存在;
(3)在进行密文检索时,客户端将检索项加密并上传到云端,云端对密文检索项进行操作也可得到相应的tf-idf权重向量明文,进而计算出检索项与文档集中各个文档的相似度并得到明文排序结果。
附图说明
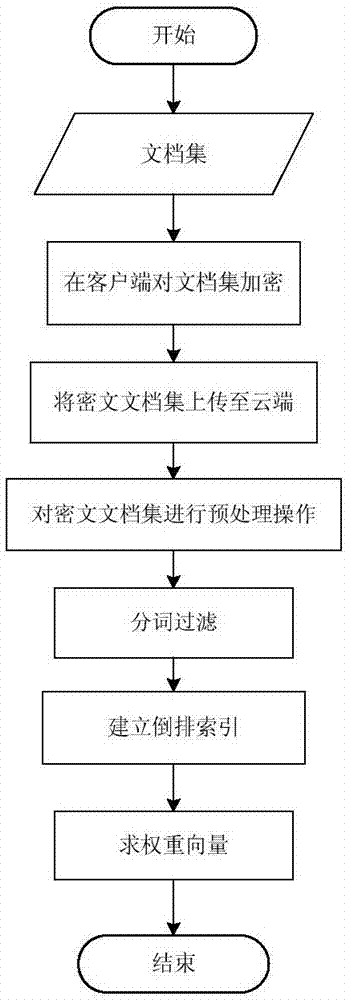
图1为本发明所提出的方法的总体步骤的流程图;
图2为本发明中步骤1、2对文档加密上传及预处理操作具体的流程图;
图3为本发明中步骤1、2、3的操作具体流程图;
图4为本发明中步骤4文档下载的具体流程图。
具体实施方式:
本发明提出一种面向云计算的同态密文检索方法,将文档集的预处理等大量工作移到云端来进行,云端对加密后的文档实施预处理,能够充分利用云端的计算能力,进而实现高效的同态密文检索。结合附图及实施例详细说明如下。
本发明提出的方法流程如图1所示,包括以下步骤:
步骤1:在客户端对文档集加密并上传至云端
(1)加密算法
随机选择一个密钥p=131;
q和随机数r是在规定的时间间隔内随机选取的。
选择四篇文档作为文档集,每篇文档中随机选取7个关键词,文档内容具体如下:
test1={ihappinessontheothersmyhands}
test2={iwasfatherwindhappinessiis}
test3={myfatherisaplayerplayerbirthday}
test4={happinessfatherotherswasofmyothers}
对这四篇文档分别进行加密,得到的密文文档具体如下:
test1={dc47e285afe8b229b2463e12cfe69f1049ea107b84f51c034c4653ca01142196c9bd11a559d61541049eb2e90112cf2bc6f11300d8a78d53e129fb50cb3f56320459fe510dec9ba2a7}
test2={56e1d11107f444633216d92f822262c9ad76c9b1444676c9bbfb50afb4fc6981447609adc10888653213df64837ddf4d9598252359fea4d95edf6214d9542b75d}
test3={4d9586fb6512cf29ba295980a7ccc6ed2fb1e59902540d3e12fb70f21049ec114217285a811d70d123a3f13327b285b7e8b2d8ba081173c7954e3af8bb70f37903e94f0211a56534c3b320756e3511d70d}
test4={f8971173af126bedb3f5e53c9a123a48d61543af8c412d2f895df6394a7bc4d95344467dc4a759fe6444764d95363abdc4a7285ba8ebc11300c7c6ff2b759f51b3c692daaa7ebd4464761959fdfa15811300d872d02}
将加密后的文档集以密文形式上传到云端进行存储。
步骤2:在云端对密文文档集进行预处理操作
(1)分词过滤
英文一般是通过空格来分割词条,分词后需要剔除对文档集的检索没有任何意义的关键词,我们称为停用词。这里使用standardanalyzer分析器,而且使用了不带参数的构造器standardanalyzer(),在standardanalyzer类的这个不带参数的构造器中,指定了一个过滤字符数组stop_words,首先需要将这个stop_words进行同态加密算法进行加密上传至云端保存以备用。
本实施例中存在的停用词为{on,the,was,is,a},由于原始文档集在客户端已经进行加密处理了,在加密的情况下进行查找密文停用词需要采用线性匹配的方法进行查找,进行匹配查询的方法如下:
假设云端文档中的密文关键词为tindex,存储在云端的密文停用词为ti,根据公式(3)可以对密文档集的每篇文档的密文关键词进行密文停用词匹配查询,若retrieval=0,则ti-tindex=0,那么ti=tindex,则证明此关键词tindex为查询到的停用词,并将其删除过滤掉。
最后将所有查询到的密文停用词删除过滤处理之后,生成新的文档集,其中的每一篇文档用dj表示;
(2)建立倒排索引
假设在云端需要统计的密文关键词为cwind={107b965d18369814bd43b},存储在云端密文文档test1={dc47e285afe8b229b2463e12cfe69f1049ea107b84f51c034c4653ca01142196c9bd11a559d61541049eb2e90112cf2bc6f11300d8a78d53e129fb50cb3f56320459fe510dec9ba2a7}中的每个密文关键词标记为ci。
则根据公式(6)计算,若retrieval=0,则ci-cwind=0,那么ci=cwind,则表示在密文文档test1中找到了需要统计的密文关键词cwind,即匹配查询到一个,词频fij记数count记为1,出现的文档数ni表示该统计的密文关键词cwind在文档集中出现的文档数量,经过与四篇密文文档的匹配,最后统计得到该密文关键词cwind的ni=1;
统计得到的数据如表2所示;
表2倒排索引表
如表2所示,文档名及关键词在云端仍然是加密状态,然而统计得到的文档编号、出现频率和出现的文档数在云端为明文形式。
(3)生成文件向量集
根据公式(7)得到:
d1={i=1,happiness=0,others=1,my=0,hands=2,father=0,wind=0,player=0,birthday=0}
d2={i=2,happiness=0,others=0,my=0,hands=0,father=0.6,wind=2,player=0,birthday=0}
d3={i=0,happiness=0,others=0,my=0,hands=0,father=0.3,wind=0,player=4,birthday=2}
d4={i=0,happiness=0,others=2,my=0,hands=0,father=0.3,wind=0,player=0,birthday=0}
根据公式(8)最终得到文档集的权重向量集为:
步骤3:检索过程
例如,查询“father”检索项,可以根据步骤1,2得到其权重向量为
步骤4:文档下载
根据上一步检索可知,文档2和检索项的相似度最高,如选择文档2下载,具体实现流程如下:
待下载文档中输入“test2”,并将其检索文档名在客户端进行同态加密上传至云端,此匹配操作是在云端进行的。
保存在云端的密文文档名集合为{d2fc02540950b013217a7893ebcd83e12110184cc700e27ad4d95f25409d2fbf60331130099c9ad7d2fb1aaa784d95f11a525},待下载的文档名密文为{18d8c3e121129d93222756fb1e},再通过公式(14)可以在云端检索到要下载的文档,若retrieval=0,则ci-cindex=0,则表示在密文文档中查询到了该密文文档,继而用户可确认进行下载到客户端。
步骤4:下载后的文档解密
客户端接收到下载的密文文档test2={56e1d11107f444633216d92f822262c9ad76c9b1444676c9bb#fb50afb4fc6981447609adc10888653213df64837ddf4d9598252359fea4d95edf6214d9542b75d},然后对其进行解密,解密算法为:
decrypt(c):计算mi=cimodp,得到明文消息m=m1m2m3...mt,即得到解密后的明文文档test2={iwasfatherwindhappinessiis},即正确下载并解密密文文档。
- 还没有人留言评论。精彩留言会获得点赞!