基于ELM的网络信息热点预测系统和方法与流程
本发明涉及网络信息热点的预测方法,具体涉及一种基于elm的网络信息热点预测系统和方法。
背景技术:
当前网络信息热点的预测主要采用:传统统计模型和现代统计学模型,传统统计模型无法跟踪网络信息热点的变化态势,预测结果极不可靠。现代统计学模型以获得更高精度的网络信息热点预测结果,但无法满足大规模网络信息热点的数据预测要求。因此,为了提高网络信息热点预测的准确性,更好地描述网络信息热点的变化趋势,亟需一种预测实时性良好、且结果理想的网络信息热点预测系统和方法。
技术实现要素:
本发明克服现有技术存在的不足,所要解决的技术问题为:提供一种预测实时性良好、且结果理想的基于elm的网络信息热点预测系统和方法。
为了解决上述技术问题,本发明采用的技术方案为:基于elm的网络信息热点预测系统,包括:采集单元:用于采集待测网络信息热点的历史点击率数据,构成网络信息热点的学习样本;估计单元:用于对网络信息热点数据的延迟时间τ和嵌入维m进行估计,并对网络信息热点数据进行变换,得到训练样本和测试样本;训练单元:用于采用极限学习机器训练网络信息热点样本,训练过程中,采用cholesky分解方法对极限学习机器的权值βl进行最优求解;模型建立单元:用于利用极限学习机器的权值βl,建立网络信息热点的预测模型;预测单元:用于利用预测模型,对网络信息热点的测试样本进行预测。
优选地,所述估计单元对网络信息热点数据的延迟时间τ和嵌入维m进行估计时,具体是采用关联积分算法来确定最优的延迟时间τ和嵌入维m。
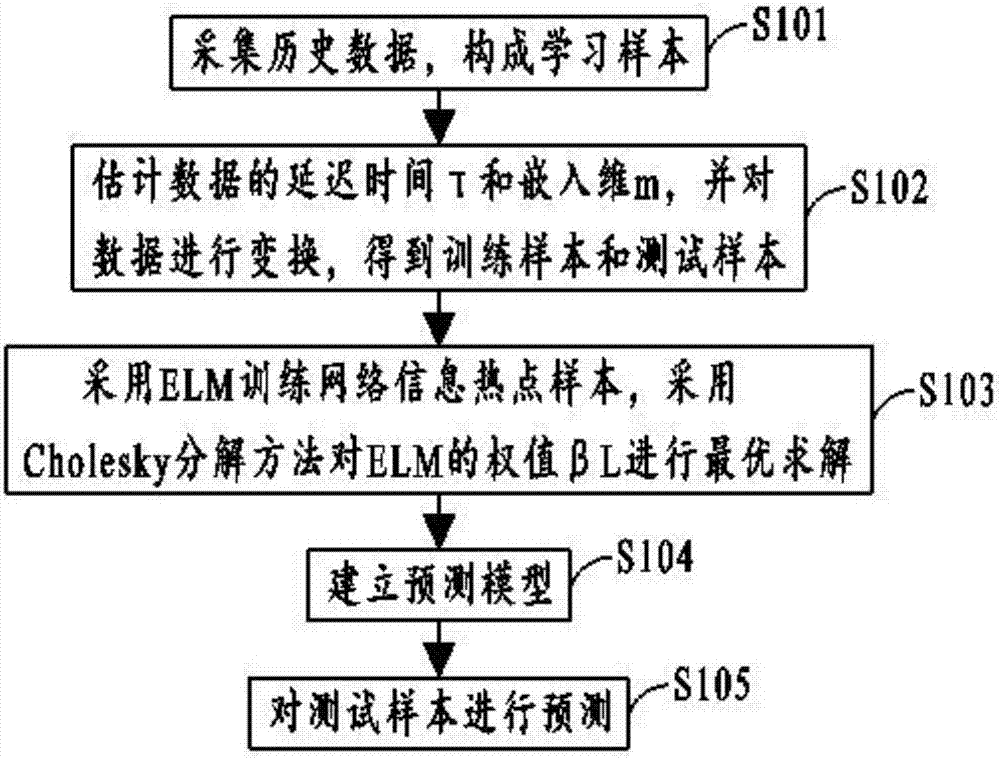
相应地,基于elm的网络信息热点预测方法,包括以下步骤:采集待测网络信息热点的历史点击率数据,构成网络信息热点的学习样本;对网络信息热点数据的延迟时间τ和嵌入维m进行估计,并对网络信息热点数据进行变换,得到训练样本和测试样本;采用极限学习机器训练网络信息热点样本,训练过程中,采用cholesky分解方法对极限学习机器的权值βl进行最优求解;利用极限学习机器的权值βl,建立网络信息热点的预测模型;利用预测模型,对网络信息热点的测试样本进行预测。
优选地,所述对网络信息热点数据的延迟时间τ和嵌入维m进行估计时,具体是采用关联积分算法来确定最优的延迟时间τ和嵌入维m。
本发明与现有技术相比具有以下有益效果:本发明在对网络信息热点进行预测时,先采集待测网络信息热点的历史点击率数据,构成网络信息热点的学习样本,然后对网络信息热点数据的延迟时间τ和嵌入维m进行估计,并对网络信息热点数据进行变换,得到训练样本和测试样本,接着采用极限学习机器训练网络信息热点样本,再利用极限学习机器的权值βl,建立网络信息热点的预测模型,最后利用预测模型,对网络信息热点的测试样本进行预测;在极限学习机器的训练过程中,关键要找到权值βl的最优值,而对于现有的极限学习机器,在βl的求解过程中,有大量的矩阵求逆运算,导致计算复杂度高,对网络信息热点预测模型的训练过程产生不利影响;因此,本发明对现有的极限学习机器进行相应的改进,引入cholesky分解方法对极限学习机器的权值βl进行最优求解,使得βl的求解仅通过四则运算就可以实现,没有矩阵求逆运算,计算更加简单,大幅度减少了求解的时间,使得对网络信息热点的预测实时性良好,结果也较理想。
附图说明
下面结合附图对本发明做进一步详细的说明;
图1为本发明提供的基于elm的网络信息热点预测系统的实施例的结构示意图;
图2为本发明提供的基于elm的网络信息热点预测方法的流程示意图;
图3为采用本发明的实施例对某一网络信息热点进行预测时采集数据的样本示意图;
图4为对图3中的网络信息热点数据的延迟时间τ进行估计后取得的最优值的示意图;
图5为对图3中的网络信息热点数据的嵌入维m进行估计后取得的最优值的示意图;
图6采用本发明对图3中的网络信息热点进行预测后的结果示意图;
图中:101为采集单元,102为估计单元,103为训练单元,104为模型建立单元,105为预测单元。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例;基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1为本发明提供的基于elm的网络信息热点预测系统的实施例的结构示意图,如图1所示,基于elm的网络信息热点预测系统,包括:
采集单元101:用于采集待测网络信息热点的历史点击率数据,构成网络信息热点的学习样本。
估计单元102:用于对网络信息热点数据的延迟时间τ和嵌入维m进行估计,并对网络信息热点数据进行变换,得到训练样本和测试样本。
训练单元103:用于采用极限学习机器训练网络信息热点样本,训练过程中,采用cholesky分解方法对极限学习机器的权值βl进行最优求解。
模型建立单元104:用于利用极限学习机器的权值βl,建立网络信息热点的预测模型。
预测单元105:用于利用预测模型,对网络信息热点的测试样本进行预测。
对一个具体的预测问题,首先要采集历史数据,设历史数据组成的样本集为:
式中:l表示隐含层节点的数,ci表示第i个隐含层节点的误差,f表示隐含层节点的非线映射函数,αi和βi分别表示隐含层节点和输入节点的权值。
对式(1)进行求解,效率相当低而且难以获得全局最优解,为此引入拉格朗日乘子建立如下优化函数:
式中:hl表示节点矩阵,w表示权值,t表示输出结果。
对变量的偏导进行计算,得到如下公式:
对式(3)求解,极限学习机的权值计算公式为
利用权值βl构建相应问题的预测模型,得到输出结果的表达式为
在标准极限机器学习过程中,关键要找到βl的最优值,在βl求解过程,有大量的矩阵求逆运算,导致计算复杂度高,对网络信息热点预测模型的训练过程产生不利影响,因此本实施例对标准的极限机器进行相应的改进,引入cholesky分解方法,再加上极限学习机器的训练过程,快速找到βl的最优求解。
下面对采用cholesky分解方法对极限学习机器的权值βl进行最优求解,来进行详细的说明:
根据式(3)能够得到:
利用式(6)对βl进行求解,可以得到相应的线性方程形式为:
alβl=bl(7)
同时满足如下约束条件:
综合式(6)和式(8)可以得到
对于v、al的二次型可以描述为:
对式(10)进行详细分析可以发现,al是一个对称正定矩阵,那么采用cholesky对其进行分解,就可以得到:
式中,sl是一个三角矩阵。
sij表示三角矩阵sl中的非零元素,那么根据al的元素αij可以得到
式中,i=1,2,…,l,j=1,2,…,l。
结合式(11)和式(7),同时乘上
式中,i=1,2,…,l。
根据sl和fl可以得到βl的计算公式为:
对比标准elm和本发明中改进的elm的建模过程,本发明中改进的elm中βl的求解仅通过四则运算就可以实现,没有矩阵求逆运算,计算更加简单,大幅度减少了求解的时间。
尤其当隐含层的节点增多条件下,速度更加加快,可以得到:
那么,al+1与al之间的关系可以表示为:
式中,
根据cholesky分解过程可以知道,通过计算sl+1,1与sl+1,l中不为零的元素就可以得到sn+1,此时可以得到:
那么,根据fl可以得到
因此根据fl+1可以得到fl+1,不要重新计算f1,f2,…,fl,加快了学习效率,而且可以实现elm的在线学习。
本实施例在对网络信息热点进行预测时,先采集待测网络信息热点的历史点击率数据,构成网络信息热点的学习样本,然后对网络信息热点数据的延迟时间τ和嵌入维m进行估计,并对网络信息热点数据进行变换,得到训练样本和测试样本,接着采用极限学习机器训练网络信息热点样本,再利用极限学习机器的权值βl,建立网络信息热点的预测模型,最后利用预测模型,对网络信息热点的测试样本进行预测;在极限学习机器的训练过程中,关键要找到权值βl的最优值,而对于现有的极限学习机器,在βl的求解过程中,有大量的矩阵求逆运算,导致计算复杂度高,对网络信息热点预测模型的训练过程产生不利影响;因此,本发明对现有的极限学习机器进行相应的改进,引入cholesky分解方法对极限学习机器的权值βl进行最优求解,使得βl的求解仅通过四则运算就可以实现,没有矩阵求逆运算,计算更加简单,大幅度减少了求解的时间,使得对网络信息热点的预测实时性良好,结果也较理想。
具体地,所述估计单元102对网络信息热点数据的延迟时间τ和嵌入维m进行估计时,具体是采用关联积分算法来确定最优的延迟时间τ和嵌入维m。
网络信息热点通常是一个一维的数据:{x(i),i=1,2,…n},根据其混沌性得到延迟时间(τ)和嵌入维(m),然后把它变化一个多维数据:x(t)={x(t),x(i+τ),…,x(i+(m-1)τ),从而将表面上看起来没有规律的数据变为实际有规律的数据,从而发现其中包含的变化特点。采用关联积分算法确定最优的τ和m。设两个样本点为:x(i)和x(j),它们的距离rij(m)为:
rij(m)=||x(i)-x(j)||(19)
那么可以得到关联积分为:
式中,r为距离的阈值。
全部样本划分为t个序列,cl为第l个序列的相关积分,那么可以得到:
可以得到极小值点为:
当
变换后第i个向量为:xi(m+1),最近邻为xn(i,m)(m+1),则有
设
相应地,图2为本发明提供的基于elm的网络信息热点预测方法的流程示意图,如图2所示,基于elm的网络信息热点预测方法,包括以下步骤:
采集待测网络信息热点的历史点击率数据,构成网络信息热点的学习样本。
对网络信息热点数据的延迟时间τ和嵌入维m进行估计,并对网络信息热点数据进行变换,得到训练样本和测试样本。
采用极限学习机器训练网络信息热点样本,训练过程中,采用cholesky分解方法对极限学习机器的权值βl进行最优求解。
利用极限学习机器的权值βl,建立网络信息热点的预测模型。
利用预测模型,对网络信息热点的测试样本进行预测。
具体地,所述对网络信息热点数据的延迟时间τ和嵌入维m进行估计时,具体是采用关联积分算法来确定最优的延迟时间τ和嵌入维m。
下面选择“天津化工厂爆炸”这个网络信息热点作为研究对象,图3为采用本发明的实施例对该网络信息热点进行预测时采集数据的样本示意图,图4为对图3中的网络信息热点数据的延迟时间τ进行估计后取得的最优值的示意图,图5为对图3中的网络信息热点数据的嵌入维m进行估计后取得的最优值的示意图。
对图3进行分析,可以发现该网络信息热点变化很复杂,不仅具有一定的增长趋势,同时具有强烈的波动性。采用关联积分算法估计τ和m,结果如图4和图5所示,从图4和图5可知,最优的τ和m分别为:7和8,根据τ=7和m=8得到网络信息热点的多维数据,选择前200个数据作为训练样本,其余用于测试其预测效果。
采用本发明中改进的elm对“天津化工厂爆炸”这个网络信息热点话题进行预测,结果如图6所示。对图6进行分析可以发现,本发明中改进的elm的网络信息热点测精度高,而且预测结果十分稳定,表明本发明中改进的elm可以用于网络信息热点话题预测中,而且预测结果十分理想。
选择当前经典模型:多元线性回归(mlr)、bp神经网络(bpnn)、支持向量机(svm)对2016年的10个网络信息热点进行预测,它们预测结果如表1所示。
表1预测精度(%)统计
对比表1中所有的网络信息热点的预测精度可以发现,相对于当前经典模型,本发明中改进的elm的网络信息热点预测精度有了一定的提高,而且预测结果更优,这表明,本发明中改进的elm可以很好对网络信息热点进行建模,把握其变化态趋,是一种通用性强的网络信息热点预测模型。
统计所有模型的平均建模时间,结果如表2所示。
表2平均建模时间(秒)统计
从表2中可以发现,本发明中改进的elm的平均建模时间最少,加快了网络信息热点的建模效率,可以实现网络信息热点在线预测。
网络信息热点受到人的思想、政治、经济以及其它因素的影响,变化十分复杂,不仅具有强烈的时变性,而且具有一定的混沌变化特点。本发明中改进的elm的网络信息热点预测模型的预测结果稳定、可信,建模预测效率更高,可以应用于实际网络舆情数据分析,预测结果可以帮助预控一些负面网络信息热点扩散,具有较高的实际应用价值。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!