基于深度学习的服务机器人物体识别算法的制作方法
本发明涉及一种基于深度学习的服务机器人物体识别方法,属于服务机器人物体识别领域。
背景技术:
物体识别是机器视觉研究中的重要问题,而室内物体识别是智能服务机器人完成服务任务的必备技能。由于物体种类繁多,特征各不相同,且室内环境因光照、遮挡、角度等问题复杂多变,室内物体识别仍然没有一个高效的通用方法,所以室内物体识别问题受到广泛关注。物体识别是通过特征匹配或模型识别的方法,确定所获取的图像中是否存在待识别物体。传统的基于特征匹配的物体识别方法一般为,首先提取物体的图像特征,然后对提取到的特征进行描述,最后对被描述的物体进行特征匹配。虽然特定的特征在特定的物体识别问题中取得了较好的效果,但这种人工的特征提取方法极大地依赖经验;而且在复杂场景下,特征匹配的复杂度高、鲁棒性差;再加上这种分步进行的方法耗时多,不具有实时性。本发明设计的方法解决了依赖人工提取特征、复杂场景下鲁棒性差以及不具有实时性的问题,建立了整个物体识别系统,对于服务机器人物体识别具有重要的借鉴意义,可以直接应用于家庭、办公室、机场、酒店等多种场合。
技术实现要素:
本发明的目的在于设计一种基于深度学习的实时性好、准确率高的服务机器人物体识别算法,实现服务机器人在复杂室内环境下的物体识别功能。
本发明的目的是这样实现的:包括如下步骤:
步骤一:采集服务机器人待识别物体的图像并制作包含训练集和验证集的图像数据集;
步骤二:设计卷积神经网络结构,在深度学习框架下进行训练得到物体识别模型;
步骤三:利用物体识别模型进行测试,实现室内复杂环境下的物体识别,服务机器人能够根据摄像头捕捉到的图像确定目标物体的类别,完成物体识别。
本发明还包括这样一些结构特征:
1.步骤一包括:
(1)通过下载和相机拍摄采集待识别物体的图像,待识别物体包含杯子、钥匙、笔和u盘四类物体,每类物体的图片共采集150张;
(2)将所采集的图片归一化为统一的尺寸、格式;
(3)将所采集的每类物体的图片按照1:4的比例分为验证集和训练集,并做好对应的标签;
(4)将验证集和训练集分别生成文件路径与标签一一对应的文本文件备用。
2.步骤二具体包括:
(1)设计一个共有八层的原始的网络结构,八层的原始的网络结构包括五个卷积模块、两个全连接层、一个输出分类层,每个卷积模块包括卷积层、激活函数层、池化层、标准化层;
(2)根据卷积核大小、参数设置和网络层数三个方面对原始网络结构进行优化,得到用于训练物体识别模型的、优化后的卷积神经网络结构;
a、卷积核大小:分析第一个卷积层的卷积核大小对识别准确率的影响,将准确率最高时采用的卷积核大小设置为优化后网络的第一层卷积层的卷积核大小;
b、参数设置:分析dropoutratio的取值对识别准确率的影响,调整dropout层的dropoutratio的取值情况,将准确率最高时采用的dropoutratio取值组合作为优化后网络的dropoutratio值;
c、网络层数:分析网络层数对识别准确率的影响,在原始网络结构基础上进行改变,设计出不同卷积层数的网络结构,将识别准确率最高的网络层数设置为优化后的网络层数;
(3)将优化后的网络结构搭建在caffe框架下;
(4)将数据集输入给卷积神经网络结构,在geforcegtx1080gpu下训练;
(5)经过20000次训练得到物体识别模型。
与现有技术相比,本发明的有益效果是:本发明通过采集服务机器人待识别的物体图像并制作数据集,设计卷积神经网络结构,在深度学习框架下进行训练得到物体识别模型,并利用物体识别模型进行测试,实现室内复杂环境下的物体识别,服务机器人能够根据摄像头捕捉到的图像确定目标物体的类别,完成物体识别的任务。
本发明设计了一种基于深度学习算的实时性好、准确率高的服务机器人物体识别算法,包括数据集的设计、卷积神经网络的结构设计以及识别测试方法。传统的基于特征匹配的识别方法首先要提取图像特征,然后进行特征描述,最后进行特征匹配确定该物体的类别。针对传统识别方法提取特征时极大得依赖人工经验的问题,提出了基于深度学习算法的识别方法,不需要人工提取特征完全由深度学习网络模型从底层到高层、自动地提取特征;针对传统识别方法,由于选取的特征具有特定性导致的在复杂场景下鲁棒性差的问题,本发明提出的算法提取到的特征不只是特定的某一种,而是诸如颜色、形状等特征的组合,因此在复杂环境下更具有鲁棒性;针对传统识别方法实时性差的问题,本发明提出的算法,自动提取特征并进行分类,这种端对端的方式可以节省分步处理产生的时间消耗,极大地提高实时性。本发明实现了服务机器人的物体识别功能,适用于复杂室内环境下的目标识别任务,可广泛应用于家庭、办公室等多种复杂环境下的目标识别中,算法的实时性、鲁棒性和高准确率可保证机器人在复杂环境下完成多种目标的识别任务。
附图说明
图1是本发明设计的卷积神经网络结构图;
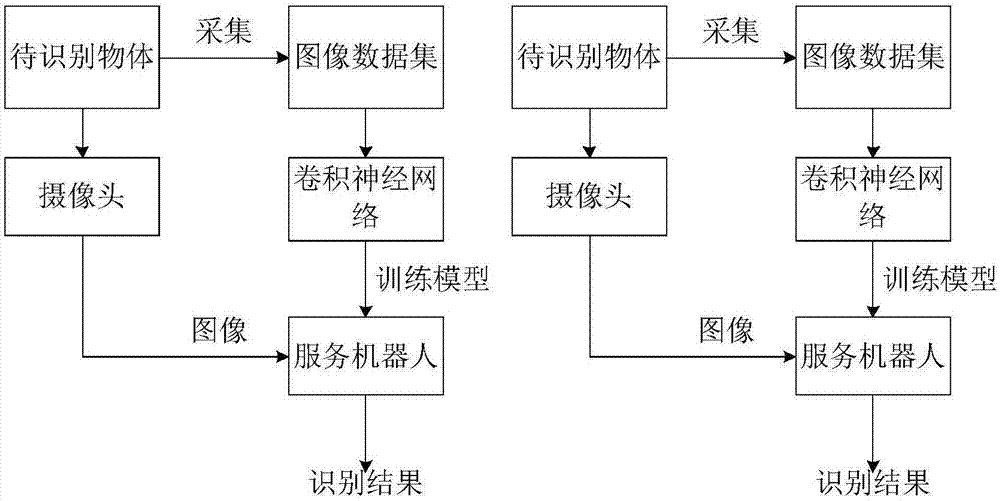
图2是本发明中基于深度学习的物体识别算法流程图。
具体实施方式
下面结合附图与具体实施方式对本发明作进一步详细描述。
本发明提出了一种基于深度学习的服务机器人物体识别方法,旨在实现服务机器人在复杂环境下高效准确地进行物体识别。首先采集服务机器人待识别物体的图像并制作包含训练集和验证集的图像数据集。然后设计原始卷积神经网络结构,包括卷积层、降采样层、全连接层等,用于训练分类模型。接下来从第一层卷积层的卷积核大小、参数设置和网络层数确定三个方面对所设计的卷积神经网络结构进行优化,根据不同设置下的识别准确率选择表现最好的三种设置的组合作为最终的改进方案。采用改进后的网络结构,在深度学习框架下进行训练得到模型,编写脚本程序调用物体识别模型进行测试,对于每个输入图片,输出其对应的类别以及准确率。最后实现室内复杂环境下服务机器人的物体识别,服务机器人能够根据摄像头捕捉到的图像确定目标物体的类别,完成物体识别的任务。
在一些实施方式中,数据集的建立具体为:
(1)通过各种网站上相关图片下载和相机拍摄,采集每类物体的图像,包括彩色的和黑白的,不同角度和光照条件下的,背景复杂程度不同的,图片中物体个数以及物体在图片中所占比例不同的图片,包含笔、钥匙、杯子和u盘四类物体的图片各150张。
(2)为了保持网络输入大小的一致性,将原始图像归一化为统一的尺寸、格式,如500*500*3,jpg格式。
(3)将每类物体的图片按照1:4的比例分为验证集和训练集,并做好对应的标签,如图片0001.jpg中的物体是杯子,那么图片0001.jpg的标签为0。
(4)将处理好的数据集生成文件路径与标签一一对应的文本文件备用。
在一些实施方式中,卷积神经网络结构的设计具体为:
(1)首先设计一个原始的网络结构,该网络共有8层,包括5个卷积模块(卷积层加上其后的激活函数层、池化层、标准化层组成一个卷积模块),2个全连接层,1个输出分类层。
(2)分析第一个卷积层的卷积核大小对识别准确率的影响,将准确率最高时采用的卷积核大小设置为优化后网络的第一层卷积层的卷积核大小。
(3)分析dropoutratio的取值对识别准确率的影响,调整dropout层的dropoutratio的取值情况,将准确率最高时采用的dropoutratio取值组合作为优化后网络的dropoutratio值。
(4)分析网络层数对识别准确率的影响,在原始网络结构基础上进行改变,设计出不同卷积层数的网络结构,将识别准确率最高的网络结构层数设置为优化后的网络的层数。
(5)根据上述三个方面的优化措施对原始网络结果进行优化,设计出最终网络结构用于训练物体识别模型。
在一些实施方式中,识别测试方法具体为:
(1)将所设计的网络结构搭建在caffe框架下。
(2)将所设计的数据集输入给卷积神经网络,在geforcegtx1080gpu下训练。
(3)经过20000次训练得到物体识别模型。
(4)调用得到的物体识别模型,编写测试脚本程序,对于输入的图片,实现实时输出其类别及准确率的功能。
下面结合附图对本发明进行分步描述:
(1)建立数据集
本发明针对服务机器人对室内复杂环境下的物体识别建立了一个图像数据集,首先通过网络下载和摄像头采集包括黑白的和彩色的、不同角度和光照情况下的、背景复杂程度不同的、图像中物体个数以及物体在图像中所占比例也各不相同(也即图片一部分来源于网络,另一部分是通过摄像头采集的物体图像。这些图像既有彩色的也有黑白的,在不同的角度和光照情况拍摄,背景复杂程度、图像中物体的个数以及物体在图像中所占比例也各不相同)。为了保持网络输入大小的一致性,将原始图像归一化为统一的尺寸。将处理好的数据集生成文件路径与标签一一对应的文本文件备用。建立的数据集中包括杯子、钥匙、笔、u盘共四类,每类物体的图片有150张,按照1:4的比例分为验证集和训练集。
(2)设计卷积神经网络结构
本发明设计的原始卷积神经网络结构如图1所示,该网络共有8层,包括5个卷积模块(卷积层加上其后的激活函数层、池化层、标准化层组成一个卷积模块),2个全连接层,1个输出分类层。第一个、第二个和第五个卷积层后分别紧跟了一个最大池化层(max-pooling,即降采样层),其中第一个和第二个最大池化层后又紧跟着一个norm(normalization,标准化)层,两层全连接层在五个卷积模块之后,最后一层是有4个输出的类别判定层,针对待分类的杯子、笔、钥匙和u盘共四类图片。除输出分类层外,各层都采用relu激活函数,相比传统的sigmoid函数计算简化、训练时间短,而且可以避免梯度消失的问题。最大池化层采用重叠池化(overlappingpooling),在一定程度上解决了容易发生过拟合现象(overfitting)的问题。为了防止在全连接层出现过拟合现象,本文采用一种正则化方法dropout,在训练时随机地忽略网络中某些节点的权重,保留这些权重但不更新,暂时认为忽略的节点不是网络结构的一部分,但不删除这些节点。
由于第一层卷积层距离原始图像最近,参数也最敏感,后续的操作依赖于该层输出,卷积核越小提取到的细节特征越多,而较大的卷积核可以得到更多的结构信息。为分析第一层卷积层的卷积核大小对识别准确率的影响,做一组对比试验,在原始数据集上将test模型中的第一层卷积层conv1选用3*3、5*5、7*7、11*11以及15*15大小的五种卷积核,为减少其他因素对结果的影响,除卷积核大小不同外,其他网络结构均相同。得到的结果为5*5的卷积核表现出更高的识别准确率。
为分析dropout层的参数dropoutratio对识别准确率的影响,做一组对比试验,调整dropout层的dropoutratio的取值情况,共进行五组实验,drop6和drop7层的参数在0.5~0.7范围内以0.05为最小变化间隔变化,得到的结果为drop6层的dropoutratio=0.55,drop7层的dropoutratio=0.5时识别准确率最高。
为分析网络结构的层数对识别准确率的影响,在原始网络结构基础上变化出4种只有卷积层数不同的网络结构,包含的卷积层数分别为3、4、6、7,对于增加网络层的结构,为了不改变特征图的大小对图片添加大小为1的边距,增加的卷积层均使用大小为3的卷积核,因为3是能保证获取上下、左右和中间像素特征的最小尺寸。得到的结果为在原始网络结构基础上增加一层卷积层conv6时识别准确率最高。
根据上述三方面的分析结果,对原始网络结构进行改进,改进后的网络配置为在卷积层5后加一层卷积层6,增加的卷积层的卷积核大小为3*3;将第一层卷积层的卷积核大小改为5*5;将drop6层的dropoutratio改为0.55;其他部分与原始网络完全相同。
(3)识别算法流程
参见图2,首先采集待识别物体的图像,制作成图像数据集;然后将所设计的网络结构搭建在caffe框架下,将数据集输入卷积神经网络,在geforcegtx1080gpu下进行训练,经过20000次训练得到物体识别模型;编写脚本程序调用该物体识别模型,实现对于服务机器人自带的摄像头捕捉到的图像信息,实时输出图像中物体的类别以及准确率的功能。
- 还没有人留言评论。精彩留言会获得点赞!