一种基于边界消解伪逆算法的不平衡数据分类系统的制作方法
本发明涉及模式分类技术领域,尤其涉及一种对不平衡数据集进行识别处理的边界消解伪逆方法与系统。
背景技术:
模式识别是研究利用计算机来模仿或实现人类或其它动物的识别能力,以便对研究对象完成自动识别的任务。近年来,模式识别技术已被广泛应用在人工智能、机器学习、计算机工程、机器人学、神经生物学、医学、侦探学以及考古学、地质勘探、宇航科学和武器技术等许多重要领域。可是,伴随应用领域的拓展,传统的模式识别技术面临新的挑战。其中一个突出的挑战来自不平衡数据处理问题。不平衡数据是这样一种数据,在其内部的许多类别中,一些类别的样本数量远小于其余类别的样本数量。为简便,称样本数少的类为少数类,称样本数多的类为多数类。实际应用中,少数类往往比多数类错分的代价大,例如医疗诊断时,误判一个潜在病患的代价比误判一个实际健康的人要大。同样地,在错误检测、软测量、融资预测、医疗探查等领域存在大量不平衡数据。
传统的模式分类方法在处理不平衡问题时,由于多数类样本的影响,往往得到偏差较大的结果。为了解决不平衡问题,一些特定的方法被设计出来。目前,专门针对不平衡问题的方法可以分为三类:第一类是基于数据集的方法,该类方法通过采样技术,在模式预处理环节削减多余的多数类,或生成少数类,使数据集趋于平衡,再代入后续传统分类模型。该类代表算法包括单边下采样算法(onesideselection)和人造少数类上采样算法(syntheticminorityoversamplingtechnique)等;第二类是基于代价敏感的方法,该类方法通过给错分的样本赋予不同权值的代价,从而纠正传统模型由于不平衡数据造成的偏差,一般而言,错分的少数类样本获得比错分的多数类样本更高的代价。该类代表算法包括代价敏感局保投影算法(cost-sensitivelocalitypreservingprojections)、代价敏感主成分分析算法(cost-sensitiveprincipalcomponentanalysis)及代价敏感判别分析算法(cost-sensitivelineardiscriminantanalysis)等;第三类是基于继承方法,该类方法通过将不同的弱分类方法合成在一起,对数据集进行综合判断。该类代表算法包括adacost等。
目前,三类方法都存在各自不足。第一类方法实现较易,但大多需要在训练模块代入全体或至少大部分样本,对于流动性强或先验信息不足的问题无法正常处理。且第一类基于采样的方法现在主要和其他方法结合使用,已经不能独立作为一个解决问题的模型。第二类方法和第三类方法则往往结构复杂,需要调整大量参数以获取最优值。第二类方法计算代价往外赶需要遍历大多数样本,导致效率降低。第三类方法需要把同一批数据代入不同的子分类模型,同样降低了效率。若能设计出结构简洁,参数较少,且能很好矫正偏差的方法,将会进一步提高模式分类技术在不平衡问题上的处理能力。
技术实现要素:
针对现有技术结构复杂、效率低下且精度不高,无法满足大规模、实时、或缺少先验知识的不平衡问题,本发明提供了一种基于边界消解的伪逆算法的不平衡数据集分类方法,采用基于边界算法的典型线性分类方法——伪逆算法对小规模样本进行第一次训练获取候选子集,采用启发式类边界条件方法对筛选过的样本进行第二次训练获取边界,最后通过获得的模糊边界和相似度度量策略对未知样本进行测试,从而在保证不平衡数据集分类正确率的同时,在模型设计和模型运算两方面提高效率。
本发明解决其技术问题所采用的技术方案(以两类不平衡问题为例):首先后台根据具体的不平衡问题描述,将采集到的样本转化成可以供后续算法处理的向量模型。其次,将以向量表示的数据集分为训练数据集与测试数据集两部分。若数据集有限,可以全部用作训练。在训练步骤中,第一次训练使用基于伪逆算法的分类策略对训练样本点划分出大致的分类决策面,并进一步生成平行于该分类决策面且过各类样本质心的两个新决策面。只有位于两个过质心决策面中间空间的样本被保留作为候选子集,其余样本被去除。第二次训练时,得到每个候选的多数类样本点距离过多数类质心决策面的距离,少数类作同样处理,两类每个样本的距离生成两个距离向量。第三,在测试阶段,得到当前测试样本点到两个过质心决策面的距离后,用这两个距离和训练模块生成的两类距离向量分别比较,通过判断测试样本点在哪一边的距离更接近质心决策面而作出最终决定。当两边距离相等时,算法采用训练模块里第一次生成的两类决策面进行判断,整个方法退化为原始的伪逆算法。最后,输出决定的类标号。
本发明解决其技术问题所采用的技术方案还可以进一步完善。所述训练模块的第一次训练步骤中,伪逆方法寻找决策面可以使用各种改进的方法,只要修正的方法保证复杂度和训练速度即可。进一步,该模型还可以使用任意适用的线性分类模型取代伪逆算法。但由于伪逆算法在所有线性分类模型里结构最简单,发明仍然以伪逆算法进行实践。另外,所述的训练模块的第一次训练步骤后,生成两个过质心的决策面时,为了提高效率,可以先判断问题的两类数据是否重叠,若无重叠,说明该数据集线性可分,则不必执行后续步骤。最后,训练第二部及测试的相似度度量步骤,采用的相似度度量方法默认为欧氏距离。但根据不同情况,可以使用任意度量方式,例如余弦距离、马氏距离等。
本发明有益的效果是:利用基于边界消解伪逆算法结构的简洁性,实现了对不平衡问题的快速反馈;通过两步训练,融合了基于边界的伪逆算法和基于非边界的启发式近邻算法,提高了分类精确度;由于伪逆方法本身的简便,使该方法只需预设一个参数,大大缩短调试时间;该方法形成的边界是模糊的,因此在训练样本数极少时仍能保证偏差不会过大。
附图说明
图1是本发明的基于边界消解伪逆算法的不平衡数据分类系统的系统框架。
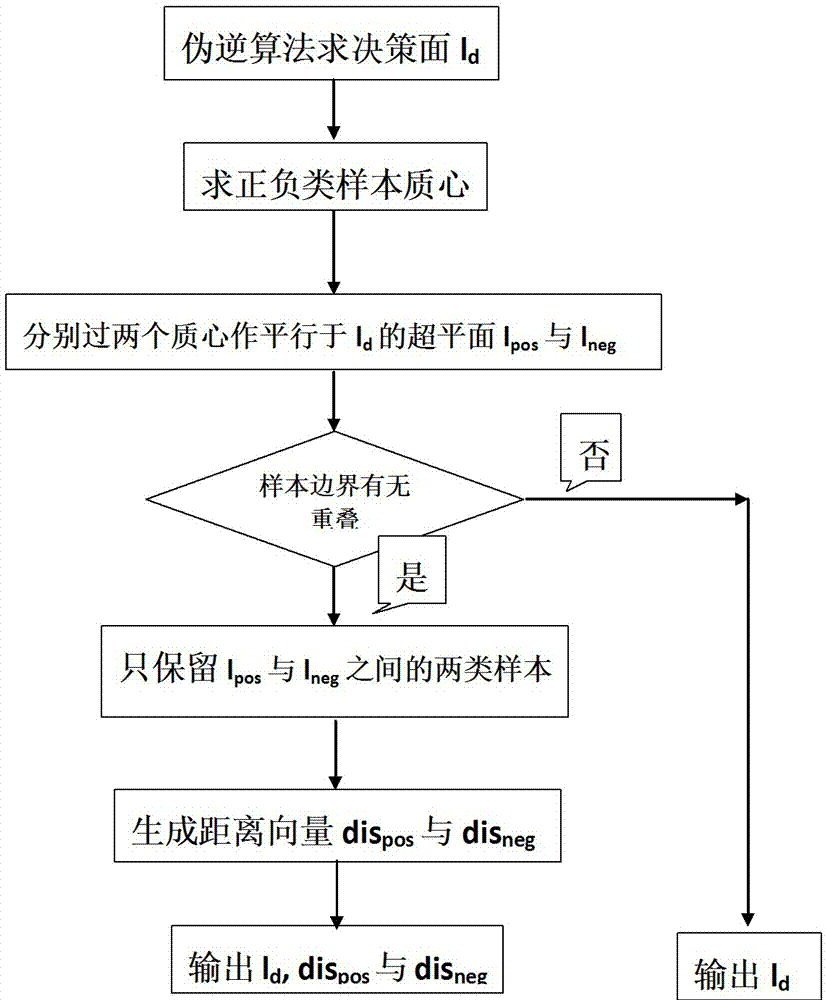
图2是本发明在训练步骤的流程图。
图3是本发明在测试步骤的流程图。
具体实施方式
下面结合附图和实施例对本发明作进一步介绍:本发明的方法共分三个模块。
第一部分:数据采集
数据采集过程是将现实中的不平衡问题数据化,生成向量表示的数据集便于后续模块进行处理。一个样本生成一个向量x,向量的每一元素对应样本的一个属性,向量的维度d即为样本的属性数,如下图所示:
在两类问题中,将少数类样本和多数类样本各合并成一个矩阵,即少数类的矩阵xpos与多数类的矩阵xneg,再将两个矩阵合并成一个大矩阵xall,这个最终的矩阵即是整个问题的数据集,如下图所示:
第二部分:训练分类模型
在这个模块中,采集到的数据集将代入发明的核心算法中进行训练。主要步骤如下。
1)利用伪逆算法生成分类决策面ld:伪逆算法是典型的线性分类算法,目的是生成一个决策面,落在决策面一边的测试样本就被判定为属于与其同一边的那一类别。决策面方程表示为:
伪逆算法首先将数据集矩阵xall的第一列增加全1向量,使其扩展为增广矩阵,如下图:
之后通过伪逆算法的公式求出最优的w与w0。公式如下:
其中,d是预先设置的理论类标号参数。
2)过两类训练样本质心,作平行于ld的两个分类面lpos与lneg:两类质心的算法如下公式所示,
3)生成候选子集:将位于lpos与lneg之间的训练样本留下作为候选子集c,其余样本去除。
4)判断当前数据集是否线性可分:判断c中的两类样本是否存在重叠,若不存在即当前数据集是线性可分,则普通线性分类模型就可以完成识别,后续使用伪逆算法生成的决策面ld进行测试即可;若存在,则进入下一步。判断重叠方法为c中两类样本离lpos与lneg最远点xpmax'与xnmax'是否满足不等式:
满足即为线性不可分。
5)生成两个距离向量dispos与disneg:令d(x,l)表示一个样本点x到一个分类面l的欧式距离。则依次计算所有c中的多数类点到lneg的距离存入disneg中,同理所有c中的少数类点到lpos的距离存入dispos中。
第三部分:测试未知数据
该模块中,需要检测其类标号的未知数据代入已经训练好的模型,并由模型做出决定。设未知样本为z。测试环节包括以下步骤。
1)计算测试样本点z到两个过质心分类平面的欧氏距离,即获取d(z,lpos)与d(z,lneg)。
2)代d(z,lpos)入dispos进行比较,获取z被分类到少数类的概率,计算公式如下:
其中,分子是dispos中数值大于d(z,lpos)的元素个数,即c子集中到lpos距离比测试样本z到lpos距离远的少数类样本个数。分母是c子集中少数类样本总数。
3)同理,比较d(z,lneg)与disneg,计算公式如下:
4)比较p(ypos~z)与p(yneg~z),z的类标号最后被决定为概率较大的一边。
5)若p(ypos~z)与p(yneg~z)相等,z由ld构成的决策方程决定。这时,算法退化到原始的伪逆方法。
实验结果
1)实验数据集选取:该实验选择了开源网站extractionbasedonevolutionarylearning(keel)datasetrepository的六个不平衡数据集。选取数据集的类数目、样本维度、规模(样本总数)及不平衡率ir列在下表中。其中ir大于9的为中度以上不平衡数据集,
其中,令nneg为多数类样本数,npos为少数类样本数,不平衡率ir的计算公式为:
所有使用的数据集均采用五折交叉方式处理,即将数据集分为大致均匀的五份,每一次选择其中一份作为测试数据,另外四份为训练数据。不重复选取测试数据五次。
2)对比算法:发明所使用的核心算法,即边界消解伪逆算法,简称为bepild。另外,我们选择knn、svm(linear)、svm(poly)、svm(rbf)为基准算法。每个算法的参数描述及值域设置如下表。
3)性能度量方法:实验统一使用受试者工作特征曲线线下面积(theareaunderthereceiveroperatingcharacteristiccurve,auc)来记录不同方法对各数据集的分类结果。结果均为对应算法在该数据集上使用最优参数配置时获得的结果,即最优结果。auc的计算公式为:
其中tp为真正类率,fp为假正类率,tn为真负类率,fn为假负类率。四个指标的关系如下表。
首先是bepild与基准算法进行对比,在实验中,因为近邻算法(knn)在近邻数k取1时平均auc值高于取其它数值,为了突出显示,表格中只列出了1nn的结果。每个数据集的最好结果标记为粗体。结果如下表。
如表可知,bepild在所有数据集上取得最高auc值,即最优结果。
接着,将提出的bepild与经典knn算法在六个数据集上的平均用时(训练时间与测试时间的和)记录在下表中,每个数据集的最好结果标记为粗体:
由表中结果可知,虽然bepild有训练与测试两个过程,而knn作为懒惰学习只有测试过程,但从时间上看,bepild效率更高。
- 还没有人留言评论。精彩留言会获得点赞!