多页同类文档碎片的分组方法与流程
本发明属于文本信息处理技术领域,涉及一种多页同类文档碎片的分组方法。
背景技术:
将来源于不同文档页的碎纸机碎片恢复成原始文档是一个复杂的技术问题,来源不同、数量众多的的碎片相互混杂,碎片难以辨别,这对文档的恢复带来极大的困难。碎片分组是将数量众多的碎片按照其来源加以区别,划分成若干个不同的组,以便在组内进行碎片拼接,减小碎片搜索的难度,提高文档恢复的准确率。
在现实情况中,被粉碎的文件通常包含多页文档。由于这些文档具有统一的页面格式,他们在视觉上几乎没有差异,这些碎片被称为同类碎片,同类碎片之间具有极高的相似性,现有碎片分组技术难以处理这类碎片。然而基于同类碎片在现实中存在的广泛性,同类碎片的分组,对于文档恢复,特别是大规模文档恢复具有十分重要的意义。碎纸机能够产生条状、块状等不同类型的碎片,目前在实际应用中大多数的碎片为条状碎片,因此,解决条状碎片的分组问题,对破碎文档的恢复具有重要的现实意义。
技术实现要素:
本发明的目的是提供一种多页同类文档碎片的分组方法,解决了现有技术中存在的同类文档碎片分组困难、分组准确率低的问题。
本发明所采用的技术方案是,多页同类文档碎片的分组方法,包括以下步骤:
步骤1、提取文档的最左边碎片和最右边碎片,并确定碎片的分组数量;
步骤2、将文档的最左边碎片和最右边碎片进行分组对应;
步骤3、将文档的中间部分碎片划分为密集碎片和非密集碎片;
步骤4、对非密集碎片进行分组;
步骤5、对密集碎片进行分组。
步骤1、提取文档的最左边碎片和最右边碎片,并确定碎片的分组数量的具体过程为:
将碎片按行间距水平分割成若干个文字块,将若干个文字块划分为5种抽象类型:x1类:空白,x2类:字符分布在左右两边,x3类:字符位于中间,x4类:字符位于右边,x5类:字符位于左边,设5种抽象类型的集合为c,c={x1,x2,x3,x4,x5,};
用贝叶斯分类器将每个文字块转化为5种抽象类型之一:将文字块设为y,y={α1,α2,…,αn,},其中,αn表示文字块中第n个灰度特征,根据贝叶斯定理,如公式(1)所示,分别计算文字块为x1类的概率p(x1/y)、文字块为x2类的概率p(x2/y)、文字块为x3类的概率p(x3/y)、文字块为x4类的概率p(x4/y)、文字块为x5类的概率p(x5/y),由max{p(x1/y),p(x2/y),…,p(x5/y)}判断出文字块y的抽象类型,将每个碎片分别转换成文字块的抽象类型的集合;
其中,p(xi/y)表示文字块为xi类的概率,xi∈c,p(y)表示文字块出现的概率,p(y/xi)表示不同抽象类型下文字块出现的条件概率,p(xi)表示不同抽象类型出现的概率,p(y/xi)·p(xi)的计算如下:
其中,αn表示文字块中第n个灰度特征,p(αj/xi)表示xi类下文字块的第j个灰度特征出现的条件概率;
计算每个碎片中x1类文字块和x4类文字块的数量之和占文字块的总数量的比例q14:
计算每个碎片中x1类文字块和x5类文字块的数量之和占文字块的总数量的比例q15:
式中,num表示每个碎片中文字块的总数量,num1表示x1类文字块的数量,num4表示x4类文字块的数量,num5表示x5类文字块的数量;
将文档最左边的碎片设为l,判断一个碎片是否为l:
将文档最右边的碎片设为r,判断一个碎片是否为r:
其中,qth是阈值,qth取值范围是0.8~0.9;
统计文档中l的数量nl以及r的数量nr,碎片的分组数量为n,n=nl=nr。
步骤2、将文档的最左边碎片和最右边碎片进行分组对应的具体过程为:
将l中的文字块和r中的文字块划分为四种类型:第ⅰ类:空白,第ⅱ类:汉字,第ⅲ类:含有句号,第ⅳ类:含有逗号;设r中某一行的文字块的类型为i,l中该行下一行的文字块的类型为j,统计r中某一行的文字块与l中该行下一行的文字块之间的相关度pji;
计算任意一个最右边碎片ri与其他l之间的相关度scji:
其中,m表示每个碎片中含有的文字块的总数量,pji(k+1,k)表示r中第k的行文字块和l中第k+1的行文字块之间的相关度;
最大的scji所对应的l,即为与ri同组的l,按照公式(7),逐一将所有r和l进行分组对应。
步骤3、将文档的中间部分碎片划分为密集碎片和非密集碎片的具体过程为:
对l和r以外的碎片中的文字块进行空白块识别:
其中,hei为文字块中黑色像素点的个数;
计算每个碎片中空白块的数量占文字块的总数量的比例α:
其中,m表示每个碎片中文字块的总数量,n表示每个碎片中空白块的数量;
根据α值的大小,将碎片划分为密集碎片和非密集碎片:
其中,th是阈值,th取值范围是0.1~0.2。
步骤4、对非密集碎片进行分组的具体步骤为:
步骤4.1、对文档靠左部分的非密集碎片进行分组;
步骤4.2、对文档靠右部分的非密集碎片进行分组。
步骤4.1、对文档靠左部分的非密集碎片进行分组的具体过程为:
将任意一个最左边碎片设为起始碎片kl,进行以kl为起点的右近邻匹配:
首先,计算kl与待匹配的非密集碎片之间的匹配度集合s(k):
s(k)={sk,u,1,sk,u,2,...,sk,u,j,...,sk,u,n}(11)
式中,sk,u,j表示kl与第j个待测的非密集碎片之间的匹配度,1≤j≤n,n表示待匹配的非密集碎片的数量:
式中,m为每个碎片的文字行数,即每个碎片的文字块的总数量,ci为两个碎片的第i行文字块之间的匹配度;
最大匹配度对应的非密集碎片即为与kl右近邻的非密集碎片v:
v=argmaxs(k)(13)
其次,匹配出与v右近邻的非密集碎片,进而,按照公式(11)、(12)、(13),逐一实现非密集碎片与其右近邻的碎片的匹配,当非密集碎片与一个密集碎片匹配上时,以kl为起点的右近邻匹配的过程结束,该密集碎片即为文档靠左部分的右边界碎片,设为lr;
逐一实现以其他最左边碎片为起点的右近邻匹配,完成文档靠左部分的非密集碎片的分组。
步骤4.2、对文档靠右部分的非密集碎片进行分组的具体过程为:
将任意一个最右边碎片设为起始碎片kr,在步骤4.1分组后剩下的非密集碎片中,找出所有非空白块的位置与kr完全相同的非密集碎片,即为与kr同组的非密集碎片;将kr转化为一个空白块与非空白块的集合kr',将每个与kr同组的非密集碎片分别转化为一个空白块与非空白块的集合,将与kr'同组的空白块与非空白块的集合逐个和kr'进行异或运算:
wi表示任意一个与kr'同组的空白块与非空白块的集合,yh是异或运算的结果,最大的yh值对应的碎片即为文档靠右部分的左边界碎片,设为rl:
rl=argmax(yh)(15)
按照公式(14)、(15),逐一找出与其他最右边碎片同组的非密集碎片,实现文档靠右部分的非密集碎片的分组。
步骤5、对密集碎片进行分组的具体过程为:
将文档中的一对边界碎片,即靠左部分的右边界碎片lr和靠右部分的左边界碎片rl,设为(lr,rl),文档中所有的(lr,rl)构成集合i:
i={(lr1,rl1),(lr2,rl2),...,(lri,rli),...,(lrn,rln)}(16)
其中,(lri,rli)表示第i对(lr,rl),n表示碎片的分组数量;
寻找并记录每对(lr,rl)中位置相同的空白块的具体位置和数量,将每对(lr,rl)按照空白块的数量进行排序,将包含空白块数量最多的(lr,rl)设为(lrj,rlj),从(lrj,rlj)开始分组,搜索与(lrj,rlj)具有相同位置及数量的空白块的密集碎片,即为与(lrj,rlj)同组的密集碎片,逐一实现密集碎片的分组。
本发明的有益效果是,多页同类文档碎片的分组方法,与常见的丢弃文档的最左边与最右边碎片估计文档页数量的方法不同,基于文档最左边碎片和最右边碎片中文字的布局特性,能够准确获得分组的数量;同时,根据段落文字的相关性,将最左边碎片和最右边碎片进行对应,并根据文字在文档不同区域的特点,将碎片按照所处区域进行分组,与已有的不分区的分组方法不同,极大提高了多页同类文档碎片分组的准确率,有利于减小多页文档碎片恢复的复杂度,提高单页文档碎片恢复的准确率,并为大规模文档碎片恢复的实现提供保障。
附图说明
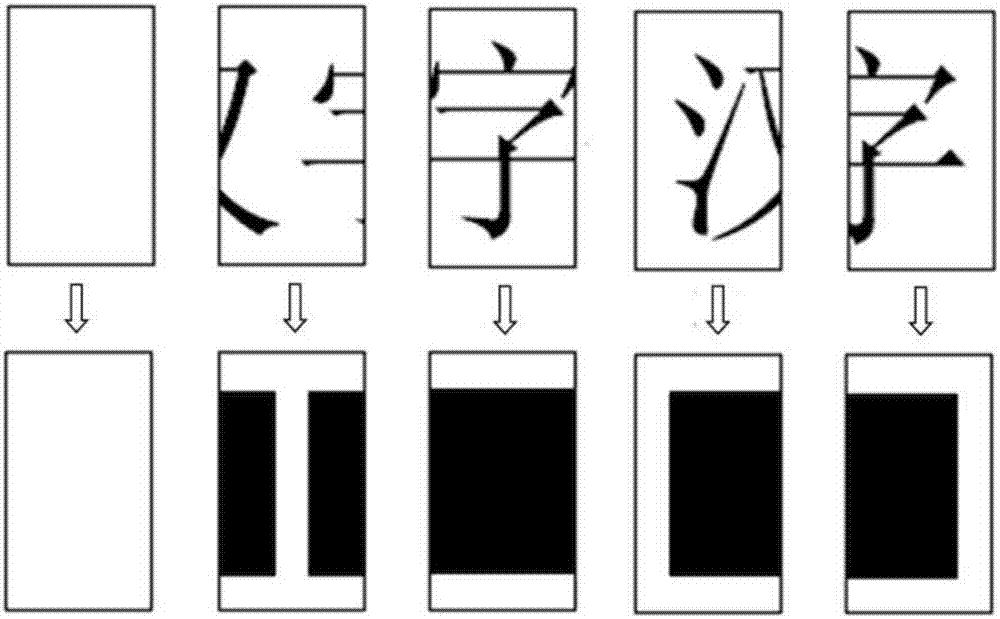
图1是部分多页同类文档的碎片的示意图;
图2是文字块对应的5种抽象类型的示意图;
图3是文档最左边碎片中的文字块和最右边碎片中的文字块对应的4种类型的示意图;
图4是文档最左边碎片中的文字块和最右边碎片中的文字块之间的相关度的分布表;
图5是密集碎片和非密集碎片的示意图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明所处理的碎片,是指来源于同一份文件的不同文档页的碎片,而非常见的特征差异明显的碎片,它们大多呈条状,在视觉特征(纸张类型、纸张颜色、文字尺寸,文本行间距,文本行数量等)上没有差异,如图1所示,其中,(a)和(b)是第一页的碎片,(c)和(d)是第二页的碎片,(e)和(f)是第三页的碎片,这类碎片广泛存在于实际的碎纸机碎片中,其分组的准确与否对于碎纸机碎片的有效恢复十分关键。
以sunwoodst9290型碎纸机对普通规格的文档(纸张大小为a4,字号为小四,行间距为1.5倍)进行破碎,并对产生的碎片加以分组为例。
多页同类文档碎片的分组方法,包括以下步骤:
步骤1、提取文档的最左边碎片和最右边碎片,并确定碎片的分组数量;
步骤2、将文档的最左边碎片和最右边碎片进行分组对应;
步骤3、将文档的中间部分碎片划分为密集碎片和非密集碎片;
步骤4、对非密集碎片进行分组;
步骤5、对密集碎片进行分组。
步骤1、提取文档的最左边碎片和最右边碎片,并确定碎片的分组数量的具体过程为:
将碎片按行间距水平分割成若干个文字块,如图2所示,若干个文字块能够被划分为5种抽象类型:x1类:空白,x2类:字符分布在左右两边,x3类:字符位于中间,x4类:字符位于右边,x5类:字符位于左边,设5种抽象类型的集合为c,c={x1,x2,x3,x4,x5,},普通规格的文档每页大约产生47个条状碎片(排除空白碎片),每个碎片的宽度为3mm,同时,每个碎片能分割成30个文字块。
用贝叶斯分类器将每个文字块转化为5种抽象类型之一:
将文字块设为y,y={α1,α2,…,αn,},其中,αn表示文字块中第n个灰度特征,由于文字块中各个灰度特征是条件独立的,根据贝叶斯定理,如公式(1)所示,分母p(y)对于5种抽象类别而言都是常数,将分子最大化,即可分别计算文字块为x1类的概率p(x1/y)、文字块为x2类的概率p(x2/y)、文字块为x3类的概率p(x3/y)、文字块为x4类的概率p(x4/y)、文字块为x5类的概率p(x5/y),找出p(x1/y)、p(x2/y)、p(x3/y)、p(x4/y)、p(x5/y)中最大的那一项,其所对应的类别就是判断出的文字块y的抽象类型,将每个碎片分别转换成文字块的抽象类型的集合;
其中,p(xi/y)表示文字块为xi类的概率,xi∈c,p(y)表示文字块出现的概率,p(y/xi)表示由训练集得到的不同抽象类型下文字块出现的条件概率,p(xi)表示由训练集得到的不同抽象类型出现的概率,p(y/xi)·p(xi)的计算如下:
统计在每种抽象类型下不同灰度特征的条件概率:
x1类文字块1-n灰度特征的条件概率:p(α1/x1),p(α2/x1),…,p(αn/x1);
x2类文字块1-n灰度特征的条件概率:p(α1/x2),p(α2/x2),…,p(αn/x2);
x3类文字块1-n灰度特征的条件概率:p(α1/x3),p(α2/x3),…,p(αn/x3);
x4类文字块1-n灰度特征的条件概率:p(α1/x4),p(α2/x4),…,p(αn/x4);
x5类文字块1-n灰度特征的条件概率:p(α1/x5),p(α2/x5),…,p(αn/x5);
其中,αn表示文字块中第n个灰度特征,p(αj/xi)表示xi类下文字块的第j个灰度特征出现的条件概率;
计算每个碎片中x1类文字块和x4类文字块的数量之和占文字块的总数量的比例q14:
计算每个碎片中x1类文字块和x5类文字块的数量之和占文字块的总数量的比例q15:
式中,num表示每个碎片中文字块的总数量,num1表示x1类文字块的数量,num4表示x4类文字块的数量,num5表示x5类文字块的数量;
将文档最左边的碎片设为l,判断一个碎片是否为l:
将文档最右边的碎片设为r,判断一个碎片是否为r:
其中,qth是阈值,qth取值范围是0.8~0.9;
统计文档中l的数量nl以及r的数量nr,碎片的分组数量为n,由于一页文档只有一个l和一个r,因此n=nl=nr。
步骤2、将文档的最左边碎片和最右边碎片进行分组对应的具体过程为:
经过步骤1处理后,文档的l和r之间没有建立相互对应的关系,这将阻碍碎片的分组,因此,需要对它们进行分组对应,文档某一行最右边的字符与下一行最左边的字符直接相关,即:若文档某一行最右边为空白,则下一行最左边也应为空白;若文档某一行最右边为文字,则下一行最左边也应为文字;若文档某一行最右边为逗号,则下一行最左边应为文字;若文档某一行最右边为句号,则下一行最左边既可能为文字也可能为空白。
如图3所示,根据属性,将l中的文字块和r中的文字块被划分为四种类型:第ⅰ类:空白,参见图3(a),第ⅱ类:汉字,参见图3(b),第ⅲ类:含有句号,参见图3(c)、(d),第ⅳ类:含有逗号,参见图3(c)、(d);由于文档每一行的第一个字符一定不会是逗号或句号,文档每一行的末尾可能出现逗号或句号,因而,l中会出现第ⅰ,ⅱ类文字块,r中会出现第ⅰ,ⅱ,ⅲ,ⅳ类文字块;
考虑到文档最左边的字符和最右边的字符之间存在相关性,根据不同文字块在上下行之间的逻辑关系,得到l中的文字块和r中的文字块之间的相关度,如图4所示,设r中某一行的文字块的类型为i,l中该行下一行的文字块的类型为j,统计r中某一行的文字块与l中该行下一行的文字块之间的相关度pji;
计算任意一个最右边碎片ri与其他l之间的相关度scji:
其中,m表示每个碎片中含有的文字块的数量,pji(k+1,k)表示r中第k的行文字块和l中第k+1的行文字块之间的相关度;
最大的scji所对应的l,即为与ri同组的l,按照公式(7),逐一将所有r和l进行分组对应。
步骤3、将文档的中间部分碎片划分为密集碎片和非密集碎片的具体过程为:
对l和r以外的碎片中的文字块进行空白块识别:
其中,hei为文字块中黑色像素点的个数;
计算每个碎片中空白块的数量占文字块的总数量的比例α:
其中,m表示每个碎片中文字块的总数量,n表示每个碎片中空白块的数量;
根据α值的大小,将碎片划分为密集碎片和非密集碎片:
其中,th是阈值,th取值范围是0.1~0.2;
如图5所示,(a)代表密集碎片,(b)代表非密集碎片。
由于段落首行缩进处的空白,使得文档靠左部分会有相对较多的空白块;由于段落结尾处的空白,使得文档靠右部分会有相对较多的空白块,因此,非密集碎片位于文档的靠左部分和靠右部分,密集碎片位于文档的中间部分。
步骤4、对非密集碎片进行分组的具体步骤为:
步骤4.1、对文档靠左部分的非密集碎片进行分组;
步骤4.2、对文档靠右部分的非密集碎片进行分组。
步骤4.1、对文档靠左部分的非密集碎片进行分组的具体过程为:
将任意一个最左边碎片设为起始碎片kl,进行kl的右近邻匹配:
将任意一个最左边碎片设为起始碎片kl,进行以kl为起点的右近邻匹配:
首先,计算kl与待匹配的非密集碎片之间的匹配度集合s(k):
s(k)={sk,u,1,sk,u,2,...,sk,u,j,...,sk,u,n}(11)
式中,sk,u,j表示kl与第j个待测的非密集碎片之间的匹配度,1≤j≤n,n表示待匹配的非密集碎片的数量:
式中,m为每个碎片的文字行数,即每个碎片的文字块的总数量,ci为两个碎片的第i行文字块之间的匹配度;
最大匹配度对应的非密集碎片即为与kl右近邻的非密集碎片v:
v=argmaxs(k)(13)
其次,匹配出与v右近邻的非密集碎片,进而,按照公式(11)、(12)、(13)逐一实现非密集碎片与其右近邻的碎片的匹配,当非密集碎片与一个密集碎片匹配上时,以kl为起点的右近邻匹配的过程结束,该密集碎片即为文档靠左部分的右边界碎片,设为lr;
由于首行缩进的存在,使得每页文档靠左部分大约为4个碎片,因此逐一实现以其他最左边碎片为起点的右近邻匹配,完成文档靠左部分的非密集碎片的分组。
步骤4.2、对文档靠右部分的非密集碎片进行分组的具体过程为:
由于文档具体内容不同,段落字数存在差异,因此段落结尾的位置是不确定的,即文档靠右部分的碎片数量是不确定的,但是,通常每页文档靠右部分的非密集碎片比靠左部分的非密集碎片的数量要多;
将任意一个最右边碎片设为起始碎片kr,在步骤4.1分组后剩下的非密集碎片中,找出所有非空白块的位置与kr完全相同的非密集碎片,即为与kr同组的非密集碎片;将kr转化为一个空白块与非空白块的集合kr',将每个与kr同组的非密集碎片分别转化为一个空白块与非空白块的集合,将与kr'同组的空白块与非空白块的集合逐个和kr'进行异或运算:
wi表示任意一个与kr'同组的空白块与非空白块的集合,yh是异或运算的结果,最大的yh值对应的碎片即为文档靠右部分的左边界碎片,设为rl:
rl=argmax(yh)(15)
按照公式(14)、(15),逐一找出与其他最右边碎片同组的非密集碎片,实现文档靠右部分的非密集碎片的分组。
步骤5、对密集碎片进行分组的具体过程为:
将文档中的一对边界碎片,即靠左部分的右边界碎片lr和靠右部分的左边界碎片rl,设为(lr,rl),文档中所有的(lr,rl)构成集合i:
i={(lr1,rl1),(lr2,rl2),...,(lri,rli),...,(lrn,rln)}(16)
其中,(lri,rli)表示第i对(lr,rl),n表示碎片的分组数量;
寻找并记录每对(lr,rl)中位置相同的空白块的具体位置和数量,将每对(lr,rl)按照空白块的数量进行排序,将包含空白块数量最多的(lr,rl)设为(lrj,rlj),从(lrj,rlj)开始分组,搜索与(lrj,rlj)具有相同位置及数量的空白块的密集碎片,即为与(lrj,rlj)同组的密集碎片,从而,逐一实现密集碎片的分组。
综上,完成了文档靠左部分碎片、靠右部分碎片、中间部分碎片的分组对应,整个多页同类文档的分组也就完成了。
通过所述方式,多页同类文档碎片的分组方法,与常见的丢弃文档的最左边与最右边碎片估计文档页数量的方法不同,基于文档最左边碎片和最右边碎片中文字的布局特性,能够准确获得分组的数量;同时,根据段落文字的相关性,将最左边碎片和最右边碎片进行对应,并根据文字在文档不同区域的特点,将碎片按照所处区域进行分组,与已有的不分区的分组方法不同,极大提高了多页同类文档碎片分组的准确率,有利于减小多页文档碎片恢复的复杂度,提高单页文档碎片恢复的准确率,并为大规模文档碎片恢复的实现提供保障。
- 还没有人留言评论。精彩留言会获得点赞!