基于词向量和词统计信息的关键词抽取方法与流程
本发明自然语言处理领域,特别涉及基于词向量和词统计信息的关键词抽取方法。
背景技术:
随着互联网的快速发展随着大数据时代的到来,在现实生活中,大量的人类接触到信息都是以电子文档形式存在着,面对这些浩如烟海的信息,人们迫切需要机器能自动识别出最能代表文章主旨的关键词,帮助人们更快的理解文章主要内容,节省人们阅读,处理和利用这些电子文档的时间。
目前该项技术称之为关键词抽取(keywordextraction),关键词抽取指的是快速从文档中获取多个能够代表文档主题的词或者短语,作为对该文档主要内容的一种精炼概况。通过关键词人们能够快速的了解文档的主要内容、高效的把握文档主题。关键词广泛应用于新闻报道、科技论文等广泛领域,通过能够让人们高效地管理和检索文档。随着信息以指数级速度的增长,关键词成为用户在海量信息中检索感兴趣内容的重要且主要的工具,人们日常使用的搜索引擎都是依靠关键词进行工作的。对不同时间段的文档中关键词使用频度、内在含义等方面的变化也成为研究人类社会、经济、文化和政治观念演变的重要途径。
对于关键词抽取的现有技术,一种途径是使用无监督的方法,利用候选关键词的统计性质,如(tfidf)等,对他们排序,选取最高的若干个作为关键词,但是这种方式这是单纯的利用了统计性质,只是利用了文档内部信息,也就是词的聚合度来发现文档主题。该方法的不足之处在于一篇文档的信息有限,往往无法为发现文档主题提供足够的信息,在一些文档中,个别非常重要的关键词,虽然出现的频次相对较低,但是对于文章的主题的反应有着非常重要的作用,这时,只通过统计方法,是没法将这些词提取出来的。
技术实现要素:
本发明的目的在于克服现有技术中所存在的上述不足,提供基于词向量和词统计信息的关键词抽取方法,借助词性信息对文档中分词后词进行筛选,保证关键词的抽取方向,并提高了计算效率;在此基础上引入更多外部信息为文档的关键词抽取提供支持,扩充了关键词的提取考察范围,使得关键词抽取的结果更加合理。
为实现所述发明目的,本发明提供以下技术方案:
基于词向量和词统计信息的关键词抽取方法,包含以下处理步骤:
(1)选择第一语料库,对第一语料库分词后的词进行向量转化;
(2)对待提取关键词文档进行分词,对分词后文档中的词进行词性标注,保留设置词性的词作为关键词的候选词;
(3)计算候选词在待提取关键词文档中的权重值,将权重值在设置阈值以上的候选词作为该文档的关键词;或者根据权重值进行排序,保权重值较高的前设置个数的候选词作为该文档的关键词;
候选词的权重计算公式如下:
其中pr(t|d)为当前候选词t在待提取关键词文档中的权重值;pr(w|d)是文档d中词w的权重,pr(w|d)为词w在文档d中的tf-idf值;而pr(t|w)是当前候选词与文档中其他词余弦距离之和。
在计算词w在文档d中的tf-idf值时,需要引入第二语料库;所述第一语料库包含的文档数量>第二语料库所包含文档数量的10倍。
作为一种优选,所述步骤(1)中采用word2vec对分词后的第一语料库中的词进行向量转化。
进一步的,所述步骤(1)与步骤(2)可调换顺序。
与现有技术相比,本发明的有益效果:本发明提供基于词向量和词统计信息的关键词抽取方法,相比于现有的关键词抽取技术,借助词性信息对分词后的候选词进行筛选,保证关键词的抽取方向,更加具有对分析方向的针对性,并提高了计算效率;不仅如此,本发明方法通过选择一个大规模的第一语料库,通过word2vec来对大规模语料库中分词结果的向量转换,转换后的词向量带有在大规模语料中的与其他词的语义近似和共同出现频次的关系,在计算候选词的权重时,将候选词与其他词的余弦距离作为考虑因素,通过词向量为待提取关键词文档的关键词抽取引入更多外部信息,扩充了关键词提取的考察范围,克服了当待抽取文档信息量少时,现有技术抽取效果差的技术缺陷。
附图说明:
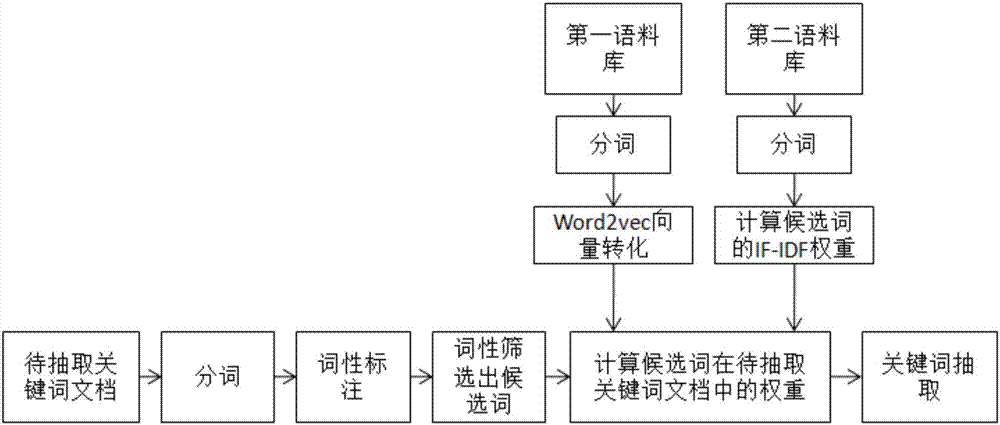
图1为本基于词向量和词统计信息的关键词抽取方法的实现步骤图。
图2为本发明方法实现过程示意图。
具体实施方式
下面结合试验例及具体实施方式对本发明作进一步的详细描述。但不应将此理解为本发明上述主题的范围仅限于以下的实施例,凡基于本发明内容所实现的技术均属于本发明的范围。
提供基于词向量和词统计信息的关键词抽取方法,相比于现有的关键词抽取技术,引入更多的考虑因素,借助词性信息对分词后的候选词进行筛选,保证关键词的抽取方向,并提高了计算效率;在此基础上引入更多外部信息为文档的关键词提取提供支持,扩充了关键词的提取考察范围,使得关键词收取的结果更加合理。
为实现所述发明目的,本发明提供以下技术方案:
基于词向量和词统计信息的关键词抽取方法,包含如图1所示的以下处理步骤:
(1)选择第一语料库,对第一语料库分词后的词进行向量转化;
(2)对待提取关键词文档进行分词,对分词后文档中的词进行词性标注,保留设置词性的词作为关键词的候选词;
(3)计算候选词在待提取关键词文档中的权重,将权重值在设置阈值以上的候选词作为该文档的关键词;或者根据权重值进行排序,保留权重值较高的前设置个数的候选词作为该文档的关键词。
本发明方法的具体实施步骤如图2所示,所述步骤(1)包含以下实现步骤:
(1-1)选择第一语料库;所述第一语料库作为外部信息的来源,可以选择语料收录比较全的语料库,现阶段开放的语料库比较多,比如说维基百科语料库,维基百科语料库收录的语料比较全面,能够提供较多的信息来源。
(1-2)使用分词工具对第一语料库进行分词,目标可以使用的分词工具也很多,比如斯坦福分词工具、哈工大ltp、中科院计算所nlpir、清华大学thulac和jieba,很多企也有内部研发的分词工具;
(1-3)将分词后的第一语料库中的词进行向量转化,可使用目前应用很广泛的word2vec来实现语料库分词后词的向量转化,word2vec实现的词的向量转化能够体现词与词之间语义的近似关系以及共现频次关系,可以将文档中意义比较接近的词,或者在文档中共现频次较高的词,转换成在空间位置较靠近的向量;
所述步骤(2)包含以下实现步骤:
(2-1)对待提取关键词文档进行分词,采用与第一语料库分词相同的分词工具来对待提取关键词文档进行分词,相同的分词工具保持分词方向的一致性,保证计算结果准确可靠。
(2-2)对分词后待提取关键词文档的词进行词性标注,目前词性标注的工具很多,使用词性标注工具来对分词后的词汇进行标注,为基于词性的候选词筛选准备了前提。
(2-3)根据词性标注的结果对待提取关键词文档中的词进行筛选,仅保留设定词性的词汇作为关键词的候选词。以不同分析方向来理解一篇文档需要获取的关键词也可能不同,现有的关键词抽取工具所抽取的关键词缺乏对分析方向的针对性;本发明方法可以根据分析的方向来设置待抽取关键词的词性;进而抽取出对应词性的关键词,对分析方向的针对性更强;并且因为本发明方法通过设置的词性来对候选词进行筛选,这样在后期的计算过程中,仅仅对保留词汇进行;减少了计算量,提高了计算的效率。
所述步骤(3)包含以下实现步骤:
(3-1)计算候选词在待提取关键词文档的权重,将权重值在设置阈值以上的候选词作为该文档的关键词;或者根据权重值进行排序,保留设置权重值较高的设置个数的候选词作为该文档的关键词;
所述候选词的权重计算公式如下:
其中pr(t|d)为当前候选词t在待提取关键词文档中的权重值,于每个词t,pr(w|d)是文档d中词w(词w为待提取关键词文档分词后经过去高频词、去停用词等预处理过程后的剩下的所有词,不仅仅关键词候选词)的权重,可使用归一化的tf-idf值,在计算每个词的tf-idf值时,需要选择第二语料库;此时语料库中文档的选择根据待提取关键词文档的情况来进行,一般选择与待提取关键词文档类型相近的文档,比如说待提取关键词文档为新闻类,那么第二语料库也对应选择新闻类的文档,选择类型相近似的文档,根据tf-idf的原理来说更能体现出候选词的区分性;
具体的,tf为词w在文档d中出现次数除以文档d中的所有词出现次数之和;idf为逆向文件频率:
在计算词w在文档d中的tf-idf值时,需要引入第二语料库d,|d|为第二语料库中包含的文档总数,|{d∈d:w∈d}|为第二语料库d中包含词w的文档数量。tf-idf为自然语言处理中计算文档中词语权重的成熟技术,对其技术细节在此不再赘述。
而pr(t|w)是当前候选词与其他词(为待提取关键词文档分词后经过去高频词、去停用词等预处理过程后剩下的,除当前词之外的其他词)余弦距离之和(余弦距离也称为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量)。经过对第一语料库分词结果的word2vec向量转换,经过word2vec训练出来的词向量具有在第一领域词典上的全局性,每个词对应一个唯一的向量,向量中体现出该词与其他词的词义远近、共同出现频次的信息,比如说词a在第一领域词典中与词b共同出现频次很高,那么词a转化成的词向量a与词b转化成的词向量b在空间上更加接近,其余弦距离就愈大,这为通过余弦距离来计算候选词的权重提供了基础。将当前词与其他词的余弦距离作为候选词权重计算的考量因素,巧妙的引入的更多外部信息的参考因素;这样当某些词在待抽取关键词文档中出现频次很低,通过现有技术不能将其作为关键词抽取出来,本发明方法引入第一语料库,如果该词汇在第一语料库中与其他词汇具有很高的共现频次,那么与其他词的余弦距离也较大,补充了单纯依靠tf-idf来计算关键词权重的不足,使得关键词抽取的权重计算公式更加合理。
具体的,所述第一语料库包含的文档数量>第二语料库所包含文档数量的10倍;即第一语料库的规模远大于第二语料库的规模,比如说第一语料库中包含100000篇文档,第二语料库中包含1000篇文档。第一语料库作为外部信息引入用来训练词向量,因而第一语料库所收录的文档越丰富全面,对于外部信息的考察范围就越大。
实施例1
对如下文本的关键词进行抽取:“欧股低开欧洲主要国家圣诞休市安排一览。中国证券网讯欧股今日低开,斯托克600指数跌0.1%至366.12点;法国cac指数跌0.1%至4669.76点;英国富时100指数跌0.2%至6253.29点;德国股市今日休市。欧洲主要国家的圣诞休市安排不尽相同,据某财经消息,英国股市因圣诞假期休市三天半,24日提前半天收盘,25日(圣诞节)全天休市,26日(节礼日)落在周六,需在28日补休,英股至29日(周二)才会再度交易;法国股市因圣诞假期休市一天,为12月25日休市;德国股市于12月24日-25日休市两天”。
经过分词和词性标注后,仅保留:nr人名、nrf音译人名、nw新词、nt机构团体名、a形容词、nz其他专用名词、v动词、n名词、ns地名词性对应的词;经过本发明方法抽取出的关键词为:{低开||欧股||圣诞休市||欧洲||国家},相比于textrank抽取的关键词:{休市||圣诞||股市||今日||法国},本发明方法抽取出的关键词更能体现主体“欧股”、“低开”等词的,“欧股”在文档中出现的频次仅为一次,出现频率较低,但是全文围绕欧股低开来展开,对反应文档的主题有很重要的作用,对于这类关键词,现有的技术一般抽取不出来,而采用本发明方法实现这类关键词的较好提取;关键词的抽取结果更加合理。
实施例2
对如下文档抽取关键词:“某某股份涉嫌违反证券法,遭证监会调查某某股份(600***)25日晚间公告,25日,公司收到证监会《调查通知书》。因公司涉嫌违反证券法律法规,据证券法的有关规定,证监会决定对公司立案调查。”的关键词抽取结果如下:{某某股份||证券法||调查||证监会||公司||},而通过现有的textrank技术抽取的关键词结果为:{证监会||公司||调查||证券法||违反||}。本发明方法更好的抽取出了某某股份这样的主题词,相对于textrank方法抽取的结果更加能够反映文档的主题;值得注意的是一旦需保留的词性和其他需要设置的参数被确定,本发明方法就是属于无监督学习过程,抽取效率较高;但是抽取结果也相比于有监督学习和人工抽取有一定的差距;但这不影响本发明方法相比于现有无监督学习的关键词技术的技术进步性。
- 还没有人留言评论。精彩留言会获得点赞!