一种快速筛选大规模过程数据中的稳态工况数据的方法与流程
本发明涉及过程数据挖掘技术领域,尤其是一种快速筛选大规模过程数据中的稳态工况数据的方法。
背景技术:
在过程数据模型辨识、系统稳定工况的参数判定等过程中,都需要应用过程数据中的稳态工况数据,对于大量的过程数据而言,人工筛选耗时费力。滑动窗口是一种通用性的数据统计处理方法,即通过一个固定长度的窗口对数据进行遍历处理。例如中国发明专利cn103679218b公开的一种手写体关键词检测方法,通过使用滑动窗口对待检测文本图像的特征点进行提取,进而与关键词特征库对比。但是现有技术中所使用的滑动窗口方法由于处理方法复杂,无法适应大数据量的快速处理。
技术实现要素:
本发明要解决的技术问题是提供一种快速筛选大规模过程数据中的稳态工况数据的方法,能够解决现有技术的不足,提高了大规模过程数据的筛选速度。
为解决上述技术问题,本发明所采取的技术方案如下。
一种快速筛选大规模过程数据中的稳态工况数据的方法,包括以下步骤:
a、稳态数据筛选的初始化处理,
对需要进行稳态工况数据筛选的数据段进行数据滤波,
选取长度为n的存储空间作为滑动窗口,所述存储空间为判断所述过程数据段稳定的最小单元,其中n表示所述滑动窗口中包含数据的个数,
根据包含n个数据的滑动窗口中的单个数据允许偏差值α,计算所述滑动窗口中n个数据的标准偏差的阈值δy;
计算数据段起始位置的n个数据的均值,作为滑动窗口均值的初值
计算数据段起始位置的n个数据的标准差,作为滑动窗口标准差的初值σ1
b、滑动窗口由数据起点向终点移动,每移动一次,会有一个新数据点进入滑动窗口,同时将原滑动窗口内数据的起始点舍弃,计算新的滑动窗口内数据的均值和标准差;
c、将所述新的滑动窗口内所含n个数据的标准差与标准差阈值δy进行比较,若其小于所述标准差阈值δy,则将新加入的数据计入稳态数据;若其大于所述标准差阈值δy,对于新的滑动窗口,则新的滑动窗口内所含第n个数据赋0;若对于初始的滑动窗口其标准差大于所述标准差阈值δy,则初始的滑动窗口内所含n个数据全部赋0;设需要进行筛选的原始数据长度为n,则直至所述滑动窗口的起点移动至n-n+1后,筛选过程结束;
d、对所选稳态数据段两端的数据进行剔除,提高数据稳态值的计算准确度。
作为优选,步骤a中,标准差的阈值δy的计算方法为,
作为优选,步骤a中,滑动窗口均值的初值
作为优选,:步骤a中,滑动窗口标准差的初值σ1的计算方法为,
其中,diff1为初始时刻的方差。
作为优选,步骤b中,新的滑动窗口内数据均值的计算方法为,
设此时滑动窗口起点所处位置为k,此时窗口内数据的均值为
作为优选,步骤b中,新的滑动窗口内数据标准差的计算方法为,
k时刻的方差diff值为,
则有对公式(6)进行展开可得如下公式,
同理,当滑动窗口移动至k+1时刻时,有如下公式,
比较公式(7)与公式(8)可得,
将公式(3)所得方差diff1的值带入公式(9),得到方差diffk+1,从而得到k+1时刻的滑动窗口内的数据标准差σk+1,
作为优选,步骤c中,稳态数据具体遵循以下原则进行数据存储:
当滑动窗口由k=1开始,逐步移动到k=n-n+1,需要进行筛选的原始数据长度为n;
1)当k=1时,对应滑动窗口的数据为y(1)到y(n),对n个数据按如下方法进行处理:
当σ1<δy时,
当σ1>δy时,
其中,ste表示用于稳态数据存储的稳态数据段,ste(n)表示稳态数据段ste中的第n个;
2)当k>1时,对应滑动窗口数据为y(k)到y(k+n-1),对n个数据按如下方法进行处理:
当σk<δy且ste(k-1)=0时,
当σk<δv且ste(k-1)≠0时,ste(k+n-1)=y(k+n-1)(14)
当σk>δy时,ste(k+n-1)=0(15);
所述滑动窗口每次移动经过以上两步判断后,最终将所有满足要求的稳态数据存储到稳态数据段ste中。
作为优选,步骤d中,设稳态数据段的起始位置为p,结束位置为q,采用滑动窗口移动的方法,具体剔除过程为,
1)计算起点在p点和q-n+1点处滑动窗口内n个数据的均值为:
其中,
2)设滑动窗口移动过程中,相邻滑动窗口间允许的滑动窗口内数据均值的最大变化量为
对公式(21)计算得到的数据均值进行比较判断:
当
当
3)滑动窗口由q点反向移动,计算滑动窗口内的数据均值的方法为,
对公式(19)计算得到的数据均值进行比较判断:
当
当
采用上述技术方案所带来的有益效果在于:本方法针对数据处理量很大时,由于计算量很大,筛选过程会变慢的问题进行设计,改进了大量数据串行处理过程的计算方法,降低了数据处理的计算量,从而使得该筛选方法在处理大量过程数据时同样具有很快的筛选速度。
附图说明
图1为稳态数据筛选过程示意图。
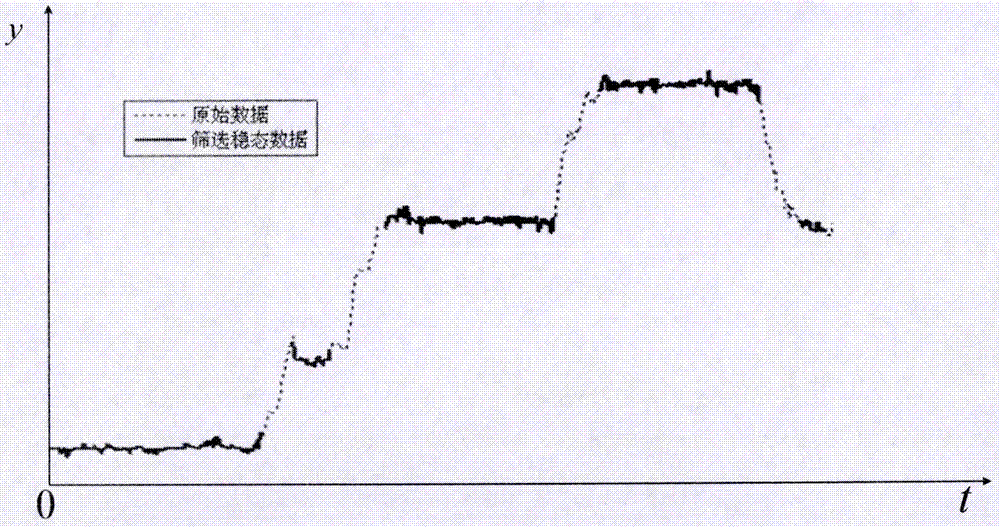
图2为稳态数据筛选结果。
图3为剔除稳态数据段两端部分数据后的筛选结果。
其中,矩形框表示滑动窗口。
具体实施方式
实施例1
一种快速筛选大规模过程数据中的稳态工况数据的方法,包括以下步骤:
a、稳态数据筛选的初始化处理,
对需要进行稳态工况数据筛选的数据段进行数据滤波,
根据选取数据的用途选取长度为n的存储空间作为滑动窗口,所述存储空间为判断所述过程数据段稳定的最小单元,其中n表示所述滑动窗口中包含数据的个数,
根据包含n个数据的滑动窗口中的单个数据允许偏差值α,计算所述滑动窗口中n个数据的标准偏差的阈值δy;
计算数据段起始位置的n个数据的均值,作为滑动窗口均值的初值
计算数据段起始位置的n个数据的标准差,作为滑动窗口标准差的初值σ1
b、滑动窗口由数据起点向终点移动,每移动一次,会有一个新数据点进入滑动窗口,同时将原滑动窗口内数据的起始点舍弃,计算新的滑动窗口内数据的均值和标准差;
c、将所述新的滑动窗口内所含n个数据的标准差与标准差阈值δy进行比较,若其小于所述标准差阈值δy,则将新加入的数据计入稳态数据;若其大于所述标准差阈值δy,对于新的滑动窗口,则新的滑动窗口内所含第n个数据赋0;若对于初始的滑动窗口其标准差大于所述标准差阈值δv,则初始的滑动窗口内所含n个数据全部赋0;设需要进行筛选的原始数据长度为n,则直至所述滑动窗口的起点移动至n-n+1后,筛选过程结束;
d、对所选稳态数据段两端的数据进行剔除,提高数据稳态值的计算准确度。
步骤a中,标准差的阈值δy的计算方法为,
步骤a中,滑动窗口均值的初值y1的计算方法为,
步骤a中,滑动窗口标准差的初值σ1的计算方法为,
其中,diff1为初始时刻的方差。
步骤b中,新的滑动窗口内数据均值的计算方法为,
设此时滑动窗口起点所处位置为k,此时窗口内数据的均值为
步骤b中,新的滑动窗口内数据标准差的计算方法为,
k时刻的方差diff值为,
则有对公式(6)进行展开可得如下公式,
同理,当滑动窗口移动至k+1时刻时,有如下公式,
比较公式(7)与公式(8)可得,
将公式(3)所得方差diff1的值带入公式(9),得到方差diffk+1,从而得到k+1时刻的滑动窗口内的数据标准差σk+1,
步骤c中,稳态数据具体遵循以下原则进行数据存储:
当滑动窗口由k=1开始,逐步移动到k=n-n+1,需要进行筛选的原始数据长度为n;
1)当k=1时,对应滑动窗口的数据为y(1)到y(n),对n个数据按如下方法进行处理:
当σ1<δv时,
当σ1>δy时,
其中,ste表示用于稳态数据存储的稳态数据段,ste(n)表示稳态数据段ste中的第n个;
2)当k>1时,对应滑动窗口数据为y(k)到y(k+n-1),对n个数据按如下方法进行处理:
当σk<δy且ste(k-1)=0时,
当σk<δy且ste(k-1)≠0时,ste(k+n-1)=y(k+n-1)(14)
当σk>δy时,ste(k+n-1)=0(15);
所述滑动窗口每次移动经过以上两步判断后,最终将所有满足要求的稳态数据存储到稳态数据段ste中。
步骤d中,设稳态数据段的起始位置为p,结束位置为q,采用滑动窗口移动的方法,具体剔除过程为,
1)计算起点在p点和q-n+1点处滑动窗口内n个数据的均值为:
其中,
2)设滑动窗口移动过程中,相邻滑动窗口间允许的滑动窗口内数据均值的最大变化量为
对公式(21)计算得到的数据均值进行比较判断:
当
当
3)滑动窗口由q点反向移动,计算滑动窗口内的数据均值的方法为,
对公式(19)计算得到的数据均值进行比较判断:
当
当
实施例2
本实施例是在实施例1的基础上改进而来的。
在步骤b中,求取k+1时刻的滑动窗口内的数据标准差σk+1时,对方差diffk+1进行修正。使用diffk至diffk-n+1这n个方差数据进行拟合(k/2<n<k),然后求取拟合曲线的斜率变化率,根据diffk处的斜率变化率得出diffk+1的预测值diff′k+1,使用diffk+1与diff′k+1的加权平均值求取σk+1。其中diff′k+1的加权率与拟合曲线的线性度成反比。通过对diffk+1进行修正,可以有效降低干扰信号对于数据筛选过程的干扰。
实施例3
本实施例是在实施例2的基础上改进而来的。
系统对筛选出的稳态数据段ste进行遍历,将遍历的数据根据密度进行聚类,通过聚类后的局部异常因子确定异常数据。根据检测到的异常数据的比例,对使用diffk至diffk-n+1这n个方差数据进行拟合的拟合曲线进行反馈修正。通过反馈修正,可以提高实施例2中对diffk+1进行修正的准确度。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!