基于深度传感器的视频识别与跟踪系统及其方法与流程
本发明涉及视频录制领域,具体地说涉及一种基于深度传感器的视频识别与跟踪系统及其方法。
背景技术:
目前国内外对课程及会议进行摄像的方法,大多数是直接请摄影师进行拍摄。或者是在教室安装固定的摄像头进行拍摄。委托摄影师在课堂及会议上录制不但耗费人力物力资源,而且会转移听众的注意力,影响效果。即当前的视频录制存在自动化程度不足的问题。
传统的单摄像头跟踪目标的方法如光流法,时间差分法,或高斯背景建模法针对人物进行跟踪具有抗噪声性能差,易混淆前景与背景,易跟踪错误的目标,难以应用于全帧视频流的实时处理等问题。且采用多目摄像头进行三维空间数据采集需要复杂的算法对数据进行合成计算,实时性不高。
技术实现要素:
本发明是为了解决上述现有技术存在的不足之处,提出一种基于深度传感器的视频识别与跟踪系统及其方法,以期能实现自动识别主讲人的运动并进行跟踪,同时,对听众区进行监视,自动识别与主讲人互动的听众并自动进行切换,从而实现全自动化的课堂和会议录制。
本发明为解决技术问题采用如下技术方案:
本发明一种基于深度传感器的视频识别与跟踪系统的特点是应用于由n+1个深度传感器、两台云台相机、一台主机以及n台从机所组成的教室环境中;所述教室环境分为主讲人区和听众区;所述主讲人区是从讲台至黑板之间的范围;所述听众区为听众所有座位的范围;在所述主讲人区的周围放置一台深度传感器,记为1号传感器;在所述主讲人区和听众区之间的上方分别放置两台云台相机,其中,一台云台相机朝向主讲人区方向,记为主讲人区的云台相机,另一台云台相机朝向听众区方向,记为听众区的云台相机;在听众区的两侧分别均匀布置剩余n个深度传感器并分别与所述n台从机相对应;
所述视频识别与跟踪系统设置在所述主机上,并包括:云台相机控制模块、跟踪模块、识别模块、录制模块;
所述1号传感器获取主讲人区的深度数据并提取相应的人物数据后发送给所述主机;
所述主机上的识别模块对所提取的人物数据利用骨骼提取方法进行处理,得到骨骼数据,并提取所述骨骼数据的头部坐标点;
所述云台相机控制模块控制所述跟踪模块利用所述主讲人区的云台相机对所述头部坐标点进行全程跟踪,并通过所述录制模块进行录制;
在t时刻令n个深度传感器各自采集听众区的深度数据,并相应发送给各自的从机进行处理,得到t时刻的n个点云数据集,任意一台从机作为监控从机获取其他从机发送的t时刻的n-1个点云数据集并进行计算,得到听众区t时刻的平面矩阵d(t);初始化μ=1;
在第μ次的δt时间间隔后,监控从机再次得到听众区的t+μ×δt时刻的平面矩阵d(t+μ×δt);根据所述t时刻的平面矩阵d(t+(μ-1)×δt)和t+μ×δt时刻的平面矩阵d(t+μ×δt),判断所述监测区域中是否有目标站起,若有目标站起,则计算目标站立者的坐标并返回给主机;并将μ+1赋值给μ,用于获得下一时刻的平面矩阵并判断目标站立者是否坐下;若没有目标站起,则直接将μ+1赋值给μ,用于获得下一时刻的平面矩阵并判断目标站立者是否站起;
若所述主机接收到所述目标站立者的坐标后,通过所述云台相机控制模块控制所述跟踪模块利用所述听众区的云台相机对所述目标站立者进行全程跟踪,并通过所述录制模块进行录制;同时,切断所述主讲人区的云台相机的录制,从而使得所述录制模块所录制的内容能互相衔接;
若所述监控从机发现目标站立者坐下,则发送切换信号给主机;
所述主机根据所述切换信号,切断所述听众区的云台相机,并恢复所述主讲人区的云台相机对主讲人区的录制,从而使得所述录制模块所录制的内容能再次互相衔接。
本发明一种基于深度传感器的视频识别与跟踪方法的特点是应用于由n+1个深度传感器、两台云台相机、一台主机以及n台从机所组成的教室环境中;所述主讲人环境分为主讲人区和听众区;所述主讲人区是从讲台至黑板之间的范围;所述听众区为听众所有座位的范围;在所述主讲人区的周围放置一台深度传感器,记为1号传感器;在所述主讲人区和听众区之间的上方分别放置两台云台相机,其中,一台云台相机朝向主讲人区方向,记为主讲人区的云台相机,另一台云台相机朝向听众区方向,记为听众区的云台相机;在听众区的两侧分别均匀布置剩余n个深度传感器并分别与所述n台从机相对应;所述视频识别与跟踪方法是按如下步骤进行:
步骤1、所述1号传感器获取主讲人区的深度数据并提取相应的人物数据后发送给所述主机;
步骤2、所述主机对所提取的人物数据利用骨骼提取方法进行处理,得到骨骼数据后,再提取所述骨骼数据的头部坐标点;
步骤3、所述主机利用所述主讲人区的云台相机对所述头部坐标点进行全程跟踪和录制;
步骤4、将所述教室环境抽象为一个矩形空间,以所述矩形空间的任意一个顶点作为原点o,与所原点o相连的三条边分别作为x轴,y轴和z轴,所述z轴垂直于地面,从而建立世界坐标系o-xyz;在所述教室环境的听众区的空间中划分一个监控区域;
步骤5、在t时刻令n个深度传感器在各自坐标系下采集听众区的深度数据并相应发送给各自的从机进行处理,得到t时刻的n个点云数据集,记为{k1(t),k2(t),…,ki(t),…,kn(t)};ki(t)表示t时刻第i个深度传感器所获得的点云数据;并有ki(t)={ki1(t),ki2(t),…,kij(t),…,kim(t)},kij(t)表示t时刻第i个点云数据的第j个数据点;
步骤6、将在t时刻第i个点云数据的第j个数据点kij转换到世界坐标系下,得到t时刻世界坐标系下的第i个点云数据的第j个数据点wij(t),从而得到t时刻世界坐标系下的第i个点云数据wi(t)={wi1(t),wi2(t),…,wij(t),…,wim(t)};
步骤7、在t时刻所述世界坐标系下的第i个点云数据wi(t)中删除处于所述监控区域外的点云数据,并保留在所述监控区域内的点云数据,从而得到t时刻在所述监控区域内的第i个点云数据wi′(t);
步骤8、任意一台从机作为监控从机获取其他从机发送的t时刻n-1个监控区域内的点云数据集并进行合并,得到t时刻总的点云数据集p(t)={w1′(t),w2′(t),…,wi′(t),…,wn′(t)};
步骤9、将所述t时刻总的点云数据集p(t)中的所有数据点投影到世界坐标系中的xoy平面上,得到t时刻二维点集p2d(t);
步骤10、将监控区域向世界坐标系中的xoy平面进行投影,得到的平面记为pw;将所述平面pw中与世界坐标系的原点o距离最近的点的坐标记为(x0,y0,0);
步骤11、将所述平面pw划分为r×s个网格,每个网格的长度记为len,宽度记为wid,并统计每个网格中的t时刻二维点的数量,将t时刻第a行第b列网格中的二维点数量记为dab(t)并作为分布矩阵中第a行第b列的元素值,从而得到分布矩阵d(t);
步骤12、定义时间间隔为δt,定义变量为μ和η,并初始化μ=1;η=1;
步骤13、在第μ次的δt时间间隔后,按照步骤5-步骤11获得第μ次的δt时间间隔后的分布矩阵d(t+μ×δt);
计算差值矩阵δd(t+μ×δt)=|d(t+μ×δt)-d(t+(μ-1)×δt)|;将所述差值矩阵δd(t+μ×δt)中的第a行第b列的元素记为δdab(t+μ×δt);
步骤14、建立一个与分布矩阵d(t+μ×δt)大小相同的矩阵temp(η),将所述矩阵temp(η)中的第a行第b列的元素记为tempab(η),并利用式(1)获得第a行第b列的元素tempab(η),从而得到矩阵temp(η):
式(1)中,const表示阈值;
步骤15、对所述矩阵temp(η)进行膨胀运算,得到膨胀处理后的矩阵temp′(η),所述矩阵temp′(η)中第a行第b列的元素记为temp′ab(η);
步骤16、建立一个与分布矩阵d(t+μ×δt)大小相同的矩阵γ(t+μ×δt),将所述矩阵γ(t+μ×δt)中的第a行第b列的元素记为τab(t+μ×δt),并利用式(2)获得第a行第b列的元素τab(t+μ×δt),从而得到矩阵γ(t+μ×δt):
步骤17、利用式(3)获得矩阵γ(t+μ×δt)中所有元素进行求和,得到求和结果sum(t+μ×δt):
步骤18、判断sum(t+μ×δt)>th是否成立,若成立,则表示在所述监控区域内有人站起,并执行步骤19;否则,表示在所述监控区域内无人站起;并将μ+1赋值给μ后,返回步骤13;th为阈值;
步骤19、利用式(4)和式(5)获得在所述监控区域内在第μ次的δt时间间隔的站立者位置的初步坐标
步骤20、利用式(6)和式(7)获得在所述监控区域内第μ次的δt时间间隔的站立者位置的实际坐标
步骤21、所述主机接收到所述目标点后,利用所述听众区的云台相机对所述目标点进行全程跟踪和录制;同时,切断所述主讲人区的云台相机的录制,从而使得所述录制的内容能互相衔接;
步骤22、将μ+1赋值给μ后,按照步骤5-步骤11获得第μ次的δt时间间隔后的分布矩阵d(t+μ×δt);
步骤23、建立一个与分布矩阵d(t+μ×δt)大小相同的矩阵γ(t+μ×δt),将所述矩阵γ(t+μ×δt)中的第a行第b列的元素记为τab(t+μ×δt),并利用式(8)获得第a行第b列的元素τab(t+μ×δt),从而得到矩阵γ(t+μ×δt):
步骤24、利用式(9)对矩阵γ(t+μ×δt)中所有元素进行求和,得到求和结果sum(t+μ×δt):
步骤25、若sum(t+μ×δt)<th'成立,则表示目标站立者已坐下,并发送切换信号给所述主机;其中th'为所测阈值;否则,返回步骤22;
步骤26、所述主机根据所述切换信号,切断所述听众区的云台相机,并恢复所述主讲人区的云台相机对主讲人区的录制,从而使得所述录制模块所录制的内容再次能互相衔接;
步骤27、将μ+1赋值给μ,将η+1赋值给η后,返回步骤13。
与现有技术相比,本发明的有益效果在于:
1.本法明基于深度传感器提出的一种结合三维重构技术和计算机视觉技术的跟踪算法和目标识别算法,可以实现对主讲人的自动识别与跟踪并同时对听众区进行监视,实现了自动识别站起与主讲人互动的听众,并自动将画面切换到该听众的位置,解决了当前课堂和会议录制过程中自动化程度不足的缺陷。
2、本发明使用深度传感器进采集数据,克服了传统跟踪的使用单摄像机采集二维数据并利用数字图像处理技术跟踪目标的方法中抗噪声性能差,易混淆前景与背景,易跟踪错误的目标,难以应用于全帧视频流的实时处理等问题,可以极大提高了系统的鲁棒性;同时可以获取目标任务的姿态信息,有利于用于进一步的开发扩展新的功能。
3、本发明提出使用深度传感器恢复出听众区三维信息从而监测听众活动的方法;该方法相比传统的使用双目或多目相机结合计算机视觉技术计算三维信息的方法,极大地提高了程序的运行速度,减少了计算量,同时利用深度传感器相比于相机的价格优势节省了成本。
附图说明
图1是本发明对主讲人所在区域进行跟踪录制的方法的流程图;
图2是本发明对听众所在区域的判断和录制的方法的流程图;
图3是本发明传感器与云台布局的图片。
具体实施方式
本实施例中,一种基于深度传感器的视频识别与跟踪系统,是应用于由n+1个深度传感器、两台云台相机、一台主机以及n台从机所组成的教室环境中;如图3所示,教室环境分为主讲人区和听众区;将教室拆分为两个区域有利于程序的编写,可以分别对主讲人区和听众区同时进行不同的程序操作。主讲人区是从讲台至黑板之间的范围;听众区为听众所有座位的范围;在主讲人区的周围放置一台深度传感器,记为1号传感器,该传感器可以将主讲人的活动范围完全覆盖;在主讲人区和听众区之间的上方分别放置两台云台相机,其中,一台云台相机朝向主讲人区方向,记为主讲人区的云台相机,该云台进行主讲人区域的跟踪与视频录制;另一台云台相机朝向听众区方向,记为听众区的云台相机,该云台进行听众区的跟踪与视频录制;在听众区的两侧分别均匀布置剩余n个深度传感器并分别与n台从机相对应,n台深度传感器进行全听众区域的覆盖,而n台从机则进行n台深度传感器的数据处理以及进一步的运算。比如说,最简单的布置就是一台深度传感器,采集听众区的数据,一台从机进行运算,另一台深度传感器采集主讲人区,两台云台分别朝向主讲人和听众,完成场景搭建;
视频识别与跟踪系统设置在主机上,并包括:云台相机控制模块、跟踪模块、识别模块、录制模块;
如图1所示,1号传感器获取主讲人区的深度数据并提取相应的人物数据后发送给主机,主机上的识别模块对所提取的人物数据利用骨骼提取方法进行处理,得到骨骼数据,并提取骨骼数据的头部坐标点;
云台相机控制模块控制跟踪模块利用主讲人区的云台相机对头部坐标点进行全程跟踪,并通过录制模块进行录制;
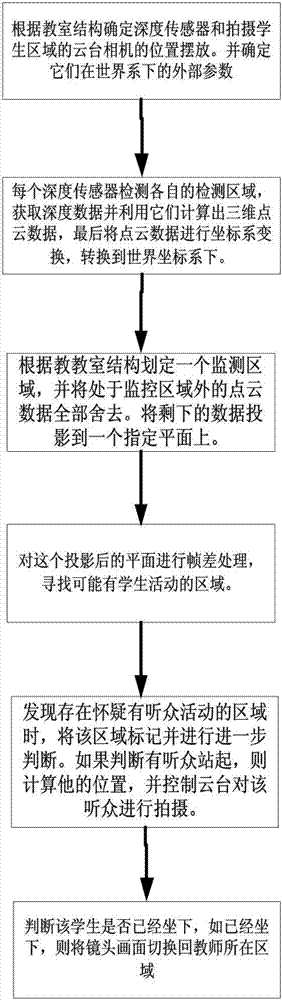
如图2所示,在t时刻令n个深度传感器各自采集听众区的深度数据,并相应发送给各自的从机进行处理,得到t时刻的n个点云数据集,任意一台从机作为监控从机获取其他从机发送的t时刻的n-1个点云数据集并进行计算,得到听众区t时刻的平面矩阵d(t);初始化μ=1;
在第μ次的δt时间间隔后,监控从机再次得到听众区的t+μ×δt时刻的平面矩阵d(t+μ×δt);根据t时刻的平面矩阵d(t+(μ-1)×δt)和t+μ×δt时刻的平面矩阵d(t+μ×δt),判断监测区域中是否有目标站起,若有目标站起,则计算目标站立者的坐标并返回给主机;并将μ+1赋值给μ,用于获得下一时刻的平面矩阵并判断目标站立者是否坐下;若没有目标站起,则直接将μ+1赋值给μ,用于获得下一时刻的平面矩阵并判断目标站立者是否站起;
若主机接收到目标站立者的坐标后,通过云台相机控制模块控制跟踪模块利用听众区的云台相机对目标站立者进行全程跟踪,并通过录制模块进行录制;同时,切断主讲人区的云台相机的录制,从而使得录制模块所录制的内容能互相衔接;
若监控从机发现目标站立者坐下,则发送切换信号给主机;
主机根据切换信号,切断听众区的云台相机,并恢复主讲人区的云台相机对主讲人区的录制,从而使得录制模块所录制的内容能再次互相衔接。
本实施例中,一种基于深度传感器的视频识别与跟踪系统,是应用于由n+1个深度传感器、两台云台相机、一台主机以及n台从机所组成的教室环境中;如图3所示,教室环境分为主讲人区和听众区;将教室拆分为两个区域有利于程序的编写,可以分别对主讲人区和听众区同时进行不同的程序操作。主讲人区是从讲台至黑板之间的范围;听众区为听众所有座位的范围;在主讲人区的周围放置一台深度传感器,记为1号传感器,该传感器可以将主讲人的活动范围完全覆盖;在主讲人区和听众区之间的上方分别放置两台云台相机,其中,一台云台相机朝向主讲人区方向,记为主讲人区的云台相机,该云台进行主讲人区域的跟踪与视频录制;另一台云台相机朝向听众区方向,记为听众区的云台相机,该云台进行听众区的跟踪与视频录制;在听众区的两侧分别均匀布置剩余n个深度传感器并分别与n台从机相对应,n台深度传感器进行全听众区域的覆盖,而n台从机则进行n台深度传感器的数据处理以及进一步的运算。比如说,最简单的布置就是一台深度传感器,采集听众区的数据,一台从机进行运算,另一台深度传感器采集主讲人区,两台云台分别朝向主讲人和听众,完成场景搭建;该视频识别与跟踪方法是按如下步骤进行:
步骤1、1号传感器获取主讲人区的深度数据并提取相应的人物数据后发送给主机;
步骤2、主机对所提取的人物数据利用骨骼提取方法进行处理,得到骨骼数据后,再提取骨骼数据的头部坐标点;
步骤3、主机利用主讲人区的云台相机对头部坐标点进行全程跟踪和录制。前三步如图1所示。
步骤4、将教室环境抽象为一个矩形空间,以矩形空间的任意一个顶点作为原点o,与所原点o相连的三条边分别作为x轴,y轴和z轴,z轴垂直于地面,从而建立世界坐标系o-xyz,这样做可以保证数据转换后每一个点的数据都为正值,便于程序的编写;在教室环境的听众区的空间中划分一个监控区域,划分此监控区域有利于减少数据的数量,加快程序的运行;
步骤5、在t时刻令n个深度传感器在各自坐标系下采集听众区的深度数据并相应发送给各自的从机进行处理,得到t时刻的n个点云数据集,记为{k1(t),k2(t),…,ki(t),…,kn(t)};ki(t)表示t时刻第i个深度传感器所获得的点云数据;并有ki(t)={ki1(t),ki2(t),…,kij(t),…,kim(t)},kij(t)表示t时刻第i个点云数据的第j个数据点;
步骤6、将在t时刻第i个点云数据的第j个数据点kij转换到世界坐标系下,得到t时刻世界坐标系下的第i个点云数据的第j个数据点wij(t),从而得到t时刻世界坐标系下的第i个点云数据wi(t)={wi1(t),wi2(t),…,wij(t),…,wim(t)};
步骤7、在t时刻世界坐标系下的第i个点云数据wi(t)中删除处于监控区域外的点云数据,并保留在监控区域内的点云数据,从而得到t时刻在监控区域内的第i个点云数据wi′(t)。这个监控区域须根据教室的具体形状确定,可以用以下形式的约束方程组进行描述
其中(x,y,z)为空间中点在世界坐标系下的坐标,n为约束方程的数量。凡是坐标满足以上方程组的点都是所划定的监控区域中的点。
例如当想在教室里划出一个矩形的空间,该空间的下底面距离地面为1米,上底面距地面2米,则我们可以写出方程
或者当想划出一个球形空间,该空间的球心坐标在世界坐标系下为(1,2,3),且半径为1.5米时,我们可以写出约束方程{(x-1)2+(y-2)2+(z-3)2<1.52,此时约束方程数量为1即n=1;
步骤8、任意一台从机作为监控从机获取其他从机发送的t时刻n-1个监控区域内的点云数据集并进行合并,得到t时刻总的点云数据集p(t)={w1′(t),w2′(t),…,wi′(t),…,wn′(t)};
步骤9、将t时刻总的点云数据集p(t)中的所有数据点投影到世界坐标系中的xoy平面上,得到t时刻二维点集p2d(t),该过程可以该公式描述
例如
步骤10、将监控区域向世界坐标系中的xoy平面进行投影,得到的平面记为pw;将平面pw中与世界坐标系的原点o距离最近的点的坐标记为(x0,y0,0),这里的x0,y0应当是由使用者对实际场地测量得到的。
步骤11、将平面pw划分为r×s个网格,每个网格的长度记为len,宽度记为wid,并统计每个网格中的t时刻二维点的数量,将t时刻第a行第b列网格中的二维点数量记为dab(t)并作为分布矩阵中第a行第b列的元素值,从而得到分布矩阵d(t),例如投影后的平面是一个长3米宽2米的矩形,我们令len为1米,wid为1米,则这个区域会被划分为3×2的网格,即r=3,s=2。如果在投影平面上坐标为(2.6,1.3)的位置发现了2个点而其他地方没有点。这个位置是在第2行3列的网格中的,所以生成的分布矩阵
步骤12、定义时间间隔为δt,定义变量为μ和η,并初始化μ=1;η=1。这里,μ+1代表当前采集的次数。η是检测到有目标站起的次数。
步骤13、在第μ次的δt时间间隔后,按照步骤5-步骤11获得第μ次的δt时间间隔后的分布矩阵d(t+μ×δt);
计算差值矩阵δd(t+μ×δt)=|d(t+μ×δt)-d(t+(μ-1)×δt)|;将差值矩阵δd(t+μ×δt)中的第a行第b列的元素记为δdab(t+μ×δt);
步骤14、建立一个与分布矩阵d(t+μ×δt)大小相同的矩阵temp(η),将矩阵temp(η)中的第a行第b列的元素记为tempab(η),并利用式(1)获得第a行第b列的元素tempab(η),从而得到矩阵temp(η):
式(1)中,const表示阈值;
步骤15、对矩阵temp(η)进行膨胀运算,得到膨胀处理后的矩阵temp′(η),矩阵temp′(η)中第a行第b列的元素记为temp′ab(η)。步骤14到步骤15的目的是标记一个怀疑有目标活动的区域,temp′ab(η)中为1的位置代表该区域是怀疑有人活动的,我们将其称为可疑区域,为0的位置代表我们不感兴趣,称为不感兴趣区域。后续的检查将对temp′ab(η)标记的区域进行,以减小程序的负担和排除一些干扰。
步骤16、建立一个与分布矩阵d(t+μ×δt)大小相同的矩阵γ(t+μ×δt),将矩阵γ(t+μ×δt)中的第a行第b列的元素记为τab(t+μ×δt),并利用式(2)获得第a行第b列的元素τab(t+μ×δt),从而得到矩阵γ(t+μ×δt):
该步骤的作用是利用矩阵temp′(η)(即我们标记的怀疑有人活动的区域)对分布矩阵d(t)进行过滤。将不感兴趣区域中,即和temp′(η)中为0的元素位置相同的数据全部舍弃掉。矩阵γ(t+μ×δt)为过滤后的分布矩阵。
步骤17、利用式(3)获得矩阵γ(t+μ×δt)中所有元素进行求和,得到求和结果sum(t+μ×δt):
步骤18、判断sum(t+μ×δt)>th是否成立,若成立,则表示在监控区域内有人站起,并执行步骤19;否则,表示在监控区域内无人站起;并将μ+1赋值给μ后,返回步骤13;th为阈值。此步骤的作用是统计可疑区域中点的总数,并将该数值与一个预先设定的阈值进行比较。如果高于该阈值则认为有人站起,反之认为没有人。
步骤19、利用式(4)和式(5)获得在监控区域内在第μ次的δt时间间隔的站立者位置的初步坐标
步骤20、利用式(6)和式(7)获得在监控区域内第μ次的δt时间间隔的站立者位置的实际坐标
步骤21、主机接收到目标点后,利用听众区的云台相机对目标点进行全程跟踪和录制;同时,切断主讲人区的云台相机的录制,从而使得录制的内容能互相衔接;
步骤22、将μ+1赋值给μ后,按照步骤5-步骤11获得第μ次的δt时间间隔后的分布矩阵d(t+μ×δt);
步骤23、建立一个与分布矩阵d(t+μ×δt)大小相同的矩阵γ(t+μ×δt),将矩阵γ(t+μ×δt)中的第a行第b列的元素记为τab(t+μ×δt),并利用式(8)获得第a行第b列的元素τab(t+μ×δt),从而得到矩阵γ(t+μ×δt):
步骤24、利用式(9)对矩阵γ(t+μ×δt)中所有元素进行求和,得到求和结果sum(t+μ×δt):
步骤25、若sum(t+μ×δt)<th'成立,则表示目标站立者已坐下,并发送切换信号给主机;其中th'为所测阈值;否则,返回步骤22;步骤23到25表示在确认已经有人站起的情况下我们无需再对分布矩阵进行差分处理,只需要实时监控可疑区域内的点是否已经低于阈值,当低于已经预先设定的阈值之后,我们便认为目标已经坐下,可以将画面切换回主讲人区域。
步骤26、主机根据切换信号,切断听众区的云台相机,并恢复主讲人区的云台相机对主讲人区的录制,从而使得录制模块所录制的内容再次能互相衔接;
步骤27、将μ+1赋值给μ,将η+1赋值给η后,返回步骤13。
综上所述,本发明系统和方法提升了录制系统的自动化程度,录制的准确性,有较好的应用前景。可以作为公司会议录制以及学校公开课视频录制的选择方案。
- 还没有人留言评论。精彩留言会获得点赞!