基于SOAR模型的突发事件中网络舆情的预测与仿真方法与流程
本发明涉及突发事件中微博网络舆情的预测与仿真方法,具体涉及一种以建立在soar模型上的网民群体行为规则为基础的仿真方法。
背景技术:
随着web2.0技术及相关互联网应用的不断普及,微博等新媒体已经成为网络舆情的重要舆论场。微博具有用户基数大、传播速度快、信息上载方便等特点,已经成为我国舆情爆发的主要策源地和传播媒介,如病毒般蔓延至互联网、企业、个人生活的每个角落。如何针对微博所具有的海量非结构化文本数据、大用户数和实时性强的特点,研究有效的微博舆情预测仿真方法,成了当务之急。
honeycutt和herring通过对twitter上用户发表的内容文本分析,进而研究twitter如何支持网民之间交互以及网民为什么要在twitter上发表信息。naaman等人在honeycutt研究的基础上进行归纳,将网民分为me-formers和in-formers两类me-formers大多数的时候只发表有利于他们自己目标的或跟自己有关的博客,并且对评论或转发别的用户的博客没有兴趣。in-formers不仅仅是发表更多的博客,还评论或者转发别的用户发表的内容。
soar模型是一种可计算程序体系结构表达的通用的认知模型,试图通过提供一个基于知识的问题求解、学习、与外界交互的框架,来促进人们对人类智能的认识。soar模型源自人工智能(ai)领域,常被用来创建智能体,对行为决策过程进行模拟,它为解决人工智能在动态复杂环境下能够自动使用知识、持续学习来完成任务的问题提供了灵活的计算框架。
目前国内学者对于网络舆情中政府应急管理的研究往往集中于理论上的建议,国外学者从公共管理角度对政府在危机管理中应急措施进行研究,但缺乏对实时数据进行分析和建模,不能根据舆情发展态势以给政府采取应急措施提供明确的建议。
技术实现要素:
本发明的目的在于基于soar模型来模仿网民的心智,结合政府措施、舆情发展阶段和网民特征,提供一种符合事实情况、便于政府做决策的舆情预测方法。
实现本发明目的的技术解决方案为:一种基于soar模型的突发事件中网络舆情的预测与仿真方法,包括以下步骤:
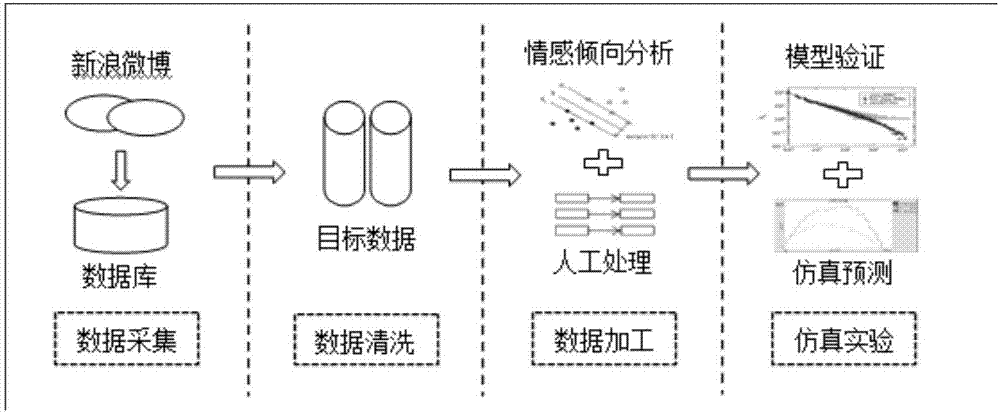
第一步,数据采集;将事件微博的评论、转发内容以及发布、评论、转发相关内容的用户信息存到本地数据库;
第二步,数据清洗;对第一步抓取来的微博数据进行清洗和整理,剔除媒体、官微发布的微博数据,得到所需普通网民发布的目标微博数据;
第三步,数据加工;通过对第二步清洗后的微博数据进行分析,对微博网民进行分类,分析微博网民情感倾向,划分网络舆情演变阶段,统计政府应急管理措施;
第四步,仿真实验;通过实验仿真再现事件中政府不同应对措施下微博用户群体行为转换过程,仿真实验包括模型设计、仿真算法设计和基于仿真平台实现仿真算法。
本发明与现有技术相比,其显著优点:1、本发明不再局限于实时的舆情反映,而是更进一步地去预测未来舆情的走向。
2、本发明将重要参数置于政府举措上,更加突出了政府的作用力,为政府的网络舆情监管起到辅助作用。
3、本发明基于soar模型,将网络舆情中网民群体行为转变过程看作相应舆情问题空间中状态随时间的连续转换过程,不再只是单纯地从时间片的角度来看待网络舆情,使得网络舆情的仿真与预测更符合实际情况。
附图说明
图1为本发明的仿真实验流程示意图。
图2为本发明的仿真算法流程示意图。
具体实施方式
针对微博舆情的预测与仿真,发明提供了一种微博舆情的仿真方法,模拟网民顺着舆情发展走向,对政府的措施做出反应,发布正面帖子或者负面帖子,从而影响网络舆情。
本发明通过soaragent模型总体框架设计和soaragent模块设计,结合网民分类、政府举措、网络舆情发展阶,为网民群体行为进行建模,得出网民群体行为转换规则。
下面结合附图对本发明作进一步说明。
本发明给出了舆情预测的具体流程,见图1:
从新浪微博上采集事件数据保存到数据库;
对数据进行清洗和整理,剔除媒体、官微发布的微博数据,得到所需普通网民发布的目标微博数据;
对数据进行加工:(1)使用svm模型分析微博情感倾向性;(2)按日统计微博数量构建事件发展曲线图,以此划分事件发展阶段;(3)统计不同阶段政府采取的应急管理措施,并分别统计政府采取措施前后不同类别网民发布的负面微博及非负面微博所占比例;
在模型设计与仿真算法设计的基础上,基于仿真平台实现仿真算法,首先分析模型有效性,其次通过仿真预测不同阶段政府采取不同措施对网民行为的影响。
本发明另一方面进一步详细地提供了食品安全类事件和公共安全类事件中的网民长期记忆规则库,即在不同网络舆情发展阶段、不同政府应急管理措施、不同网民总体情感倾向下,网民的行为偏好,如下表所示。
表11me-formers类网民长期记忆初始规则
表12in-formers类网民长期记忆初始规则
*注:
op表示为网络舆情发展阶段(networkpublicopiniondevelopmentphase);
gr表示政府应急管理措施(governmentresponse);
et表示网民总体情感倾向(emotiontendency);
ac表示网民群体行为(action)。
下面结合实施例对本发明作进一步说明。
从新浪微博上采集相关事件数据保存到数据库;
对数据进行清洗和整理,剔除媒体、官微发布的微博数据,得到所需普通网民发布的目标微博数据;
对网民进行分类:根据网民是否发表微博、是否评论其他网民发表的微博、是否转发其他网民发表的微博划分为me-formers与in-formers两种类型。me-formers只发表不评论不转发,in-formers既发表也评论和转发;
分析网民情感倾向:使用svm模型分析微博情感倾向性的方法,借助空间向量模型来进行每条微博的特征表示,通过微博的内容特征、外部特征来确定微博情感倾向性特征,从而确定每条微博的情感倾向。统计各阶段网民负面情感比例与非负面情感比例中较大者作为该阶段网民总体情感倾向;
划分网络舆情演变阶段:通过统计每日微博数据,构建事件发展曲线图,选取拐点作为事件发展阶段划分依据;
归纳政府应急管理措施:根据事件案例描述与事件发展阶段划分,分别找出各个阶段政府在微博或其他平台发布的信息及采取的活动,对政府应急管理措施进行归类;
基于soar模型对网民群体行为进行建模:
网络环境中网民情感倾向表明了网民对网络舆情事件的态度,网民负面情感所占的比例影响政府决定是否调整应急策略,因此,网民对政府的影响函数为式:
其中,et_n(t)表示t阶段发布的负面信息数,nmax表示t阶段发布的信息总数,f(e,t)表示t阶段负面信息所占比例,若f(e,t)∈[0,μ]则政府不调整应急措施;若f(e,t)∈[μ,1],则政府调整应急措施。μ为[0,1]区间内的常数,其值在实际数据统计中得到;
最初的初始行为规则是在对多个舆情事件实际数据统计分析基础上得到的,由此形成长期记忆。首先根据网民特征属性将网民分为me-formers与in-formers类,通过真实数据对每类网民工作记忆中的输入属性和输出属性进行描述,输入属性包括网络舆情发展阶段、政府应急管理措施、网民总体情感倾向,输出属性即网民群体行为,输入属性与输出属性的组合被归纳出来形成规则,相应的偏好值,即网民有多大意愿选择这种行为,作为规则的偏好;
网络舆情演变阶段根据按日统计微博数据构建的事件发展曲线划分得到;
政府应急管理措施通过人工对舆情事件每个阶段总结得到;
网民总体情感倾向用该阶段负面微博数比上微博总数的比值来衡量,大于0.5即为负面,小于0.5为非负面;
网民群体行为用微博表达的情感来表示,一条表达负面的微博即为一个发布负面信息行为,一条表达非负面情感的微博即为一个发布非负面信息的行为;
规则偏好值通过舆情事件片断进行统计得到,计算公式如式
设计仿真算法:定义变量和函数,见下表
仿真算法变量与函数
其中
仿真开始条件:加入agt-0个持负面情感的me-formers类和in-formers类网民,加入agt+0个持非负面情感的me-formers类和in-formers类网民。
仿真结束条件:网民agent遍历完毕。
仿真算法流程,如图2所示:
步骤1:仿真开始,针对不同阶段加入agt-个带负面情感与agt+个带非负面情感的不同类别的网民,总数为agt,计算当前状态下网民总体负面情感比例nep,在政府当前应急管理措施gr下,进入循环遍历网民,获取网民agent工作记忆各个输入属性值e={op=op,gr=gr,et=et},进入步骤2;
步骤2:获取该网民类别at及对应的长期记忆规则库ruleset(at),将工作记忆元素与规则条件进行匹配,获得候选算子集合operatorset,进入步骤3;
步骤3:判断候选算子集合operatorset是否为空,如果不为空,则根据决策过程设计的算子选择机制,根据偏好对候选算子集合进行排序orderoperatorset(),选择一个算子应用,判断该算子对应的规则是否为新规则newrule,若是则加入初始规则库ruleset(at),若不是则直接进入步骤5,若是则先将该新规则添加到长期记忆规则库中再进入步骤5,如果候选算子集为空,则说明产生僵局,进入步4;
步骤4:使用降低匹配精度的算法,产生新规则,形成临时规则库newruleset(at),重新与新状态下工作记忆元素进行匹配,获得候选算子集合,进入步骤5;
步骤5:应用算子applyoperator(),输出网民行为,引起网民负面情感比例nep改变,计算当前状态下网民负面情感比例,与阈值threshold进行比较,如果小于阈值则进入步骤1,继续遍历网民,如果大于阈值则改变政府应急措施set(gr),进入步骤1,重新遍历网民,继续下一轮循环,直到遍历完网民后退出;
本发明将网民群体行为分为发负面信息与发非负面信息两种行为,如果仅选择偏好最大的算子进行应用将导致仿真结束时网民情感全部为负面或者全部为正面,因此本发明在应用算子时加入一个机制,即网民以偏好为概率选择这个行为。
最后基于仿真平台进行网络舆情的预测与仿真,选用netlogo或者anylogic仿真平台,随后选取事件发生后的微博数据为样本,首先通过实验仿真再现事件中政府不同应对措施下微博用户群体行为转换过程,根据仿真结果对模型的有效性进行分析;然后,通过在网络舆情发展的不同阶段,设置政府不同的应对措施,对实验结果进行分析,来评估政府应急措施对不同网民群体引导能力,得出在网络舆情事件不同发展阶段,对于不同类别网民,政府采用何种措施,能使网民负面情感比例下降至最低。
- 还没有人留言评论。精彩留言会获得点赞!