利用随机森林分类器实时检测安卓恶意软件的方法与流程
本发明属于通信技术领域,更进一步涉及网络安全技术领域中的一种利用随机森林分类器实时检测安卓恶意软件的方法。本发明可用于实时检测安卓软件中是否存在恶意软件,以便其他网络安全技术对安卓软件中所存在的恶意软件进行处理,从而保障安卓软件的信息安全。
背景技术:
安卓恶意软件检测技术用于发现移动设备上存在的恶意软件,以便于其他网络安全技术阻止恶意软件对移动设备的危害活动。利用随机森林分类器的安卓恶意软件检测技术在近些年受到了学者的关注,这种方法通常是对应用程序产生的特征数据进行分析,从中提取出能够区分正常软件和恶意软件的特征,作为恶意软件的检测依据。目前基于分类器分析的安卓恶意软件检测技术有:
董航在其发表的博士论文“移动应用程序检测与防护技术研究”(北京邮电大学,中国知网)中提出一种基于hmms-svm模型的移动恶意行为动态分析方法。该方法分两个阶段,首先,通过将所有应用程序按照功能分类,分别运行各个分类中的所有学习样本,对其运行时行为进行捕获,对捕获的运行时行为数据进行预处理和特征提取,作为隐马尔可夫模型的观测值输入,使用baum-welch算法进行训练建模,得到每一类应用的隐马尔可夫模型,并将hmm的输出结果组成最大似然向量;然后,将最大似然向量作为最终决策分类的依据,输入svm,学习得到训练好的svm,建立hmms-svm分类器检测模型的训练过程;最后,使用建立的分类器模型进行恶意软件的检测。该方法存在的不足之处是:该方法以支持向量机作为最后检测依据,这种处理方式使得非常多的参数需要调整,导致调整周期长,如选择最合适的核函数,正则惩罚等。
电子科技大学在其拥有的专利技术“基于随机森林分类方法的android平台恶意应用检测方法”(申请号cn201510969901.6公开号cn105550583a)中提出了一种利用随机森林分类方法来检测android平台恶意软件行为的方法。该方法针对android应用样本的多类特征,设计相应的随机森林决分类器,包括以下几种:android应用样本的静态特征、权限集和api集构建样本库。该检测方法存在的不足之处是:该方法设计的随机森林分类器所有提取的特征均来自样本的静态特征,并不能检测android应用样本在运行时数据。该方法对于所有android应用程序进行特征提取,降低了安卓恶意检测成功率,不能充分利用随机森林分类器对特征进行分类。现阶段的一些基于分类器的安卓恶意软件检测方法存在以下不足之处:第一,现有的基于分类器的安卓恶意软件检测方法通常是对不同android样本分类之后进行分析,或者是对样本逐个进行静态分析的处理方式使得恶意软件检测的实时性不能得到保障;第二,现有的基于应用程序接口数据流分析的安卓恶意软件检测方法使用的调用序列特征比较单一,没有充分利用应用程序接口数据流的各种类型的特征,使得恶意软件检测的检测准确率不能得到保障;第三,现有的基于应用程序接口数据流分析的安卓恶意软件检测方法中使用的应用程序接口数据流调用序列特征,通常现有的基于聚类算法的安卓恶意软件检测方法是对具有相同家族安卓样本进行分析,或者是对样本逐个进行静态分析的处理方式使得恶意软件检测的样本之间的内在关联性不能得到保障;第四,现有的基于随机森林分类器分析的安卓恶意软件检测方法中使用的静态特征,通常是android应用标识符、申请权限、所调用的api等特征,在面对使用安卓应用样本进行运行时数据分析之时便不能有效进行检测;第五,现有的基于分类器的安卓恶意软件检测方法使用的运行时数据特征比较单一,没有充分利用android应用样本运行时的各种类型的特征,降低了恶意软件检测的准确率。
技术实现要素:
本发明的目的是克服上述现有技术的不足,提出一种利用随机森林分类器实时检测安卓恶意软件的方法,在隐马尔科夫模型之上加入随机森林决策树模型,进一步加强和巩固程序的安全性评估。
实现本发明的具体思路是:本发明提出的方法包括模型建立阶段和实时检测阶段,其中模型建立阶段,对所有已经下载的android应用软件样本通过运行,提取出运行时数据特征,然后使用隐马尔可夫模型对不同类型的数据特征建立隐马尔科夫模型,将隐马尔科夫模型的各个观测单元的最大似然输出组成最大似然向量,作为随机森林分类器的观测值输入,完成hmm-rf检测模型的训练过程;实时检测阶段,是使用模型训练阶段建立的恶意软件检测模型,对待检测软件样本进行实时检测,输出检测结果。
实现本发明目的的具体步骤如下:
(1)收集网络数据:
使用数据包捕获工具,分别收集正常软件样本和恶意软件样本所产生的运行时应用程序接口调用数据流,将收集到的运行时应用程序接口调用数据流作为训练恶意软件检测模型的初始数据集;
(2)应用程序接口调用数据流分组:
根据应用程序接口数据流的分组规则,对初始应用程序接口调用数据集进行分组,得到多个不同应用程序接口数据流类型的分组;
(3)提取数据流最小单元:
根据应用程序接口数据流最小单元的分组规则,提取不同应用程序接口数据流类型的分组,从运行时trace文件生成的应用程序接口数据流调用关系树中,提取应用程序接口数据流最小单元;
(4)提取调用序列特征:
(4a)根据运行时trace文件对应的应用程序接口数据流最小单元,分别从每个应用程序接口数据流最小单元的头部字段调用信息中,提取多种网络行为特征序列;
(4b)将提取到的多种网络行为特征中每一项网络行为特征作为对应向量的每一列特征元素,组成字段网络特征向量;
(5)训练隐马尔科夫模型:
(5a)分别将每个字段网络特征向量标记为与该特征向量对应的软件样本类别,将所有标记后的字段网络特征向量组成隐马尔科夫模型的训练样本集;
(5b)利用baum-welch算法,对训练样本集进行训练,得到隐马尔科夫模型;
(5c)利用最大似然推导公式,计算在baum-welch算法下得到的隐马尔科夫模型的最大似然输出,将多个类型的最大似然输出组成最大似然向量;
(6)训练随机森林模型:
(6a)将最大似然向量作为随机森林模型的观测值训练样本集;
(6b)利用随机森林算法,对训练样本集进行训练,得到随机森林分类器检测模型;
(7)提取待检测样本的应用程序接口数据流特征:
(7a)利用网络数据包捕获工具,实时捕获待检测样本的应用程序接口数据流特征;
(7b)根据各类数据流的分组定义规则,得到待检测样本的应用程序接口数据流分组;
(7c)根据数据流最小单元的定义规则,从待检测样本的应用程序接口数据流分组中提取应用程序接口数据流最小单元;
(7d)提取到网络行为特征作为向量的元素,组成字段网络特征向量;
(8)将待检测样本的特征向量输入随机森林检测模型,判断特征检测模型的输出是否为恶意软件类别,若是,则执行步骤(9),否则,执行步骤(10);
(9)将待检测样本标记为恶意软件,输出待检测样本对应的恶意软件类别;
(10)将待检测样本标记为正常软件,输出待检测样本对应的正常软件类别。
本发明与现有技术相比具有如下优点:
第一,由于本发明在数据流分组中,根据应用程序接口数据流的分组规则,对初始应用程序接口调用数据集进行分组,得到多个不同应用程序接口数据流类型的分组;在提取数据流最小单元中,根据应用程序接口数据流最小单元的分组规则,提取不同应用程序接口数据流类型的分组,克服了现有技术通常对相似数据流进行分析,或者是对数据流逐个进行分析的处理方式使得恶意软件检测的实时性不能得到保障的缺点,使得本发明的方法具有能够实时检测恶意软件的优点。
第二,由于本发明通过对应用程序接口数据流进行分析,提取调用序列特征,克服了现有的基于应用程序接口数据流分析的安卓恶意软件检测方法使用的调用序列特征比较单一,没有充分利用应用程序接口数据流的各种类型的特征的缺点,使得本发明的方法具有良好的检测准确率。
第三,由于本发明通过训练隐马尔科夫检测模型,克服了现有的基于应用程序接口数据流分析的安卓恶意软件检测方法中使用的应用程序接口数据流调用序列特征,通常现有的基于聚类算法的安卓恶意软件检测方法是对具有相同家族安卓样本进行分析,或者是对样本逐个进行静态分析的处理方式使得恶意软件检测的样本之间的内在关联性不能得到保障的缺点,使得本发明具有更好的内在关联性。
第四,由于本发明通过训练随机森林检测模型,克服了现有的基于随机森林分类器分析的安卓恶意软件检测方法中使用的静态特征,通常是android应用标识符、申请权限、所调用的api等特征,在面对使用安卓应用样本进行运行时数据分析之时便不能有效进行检测的缺点,使得本发明具有更好的实时检测性。
第五,由于本发明实现了隐马尔科夫与随机森林决策树的双重恶意软件检测,克服了现有的基于分类器的安卓恶意软件检测方法使用的运行时数据特征比较单一,没有充分利用安卓应用样本运行时的各种类型的特征,使得恶意软件检测的准确率降低的缺点,使得本发明进一步增大了恶意软件检测准确率。
附图说明
图1为本发明方法的流程图;
图2为使用隐马尔可夫检测模型步骤的流程图;
图3为使用随机森林分类器检测模型步骤的流程图。
具体实施方式
本发明提出了一种利用随机森林分类器实时检测安卓恶意软件的方法,该方法基于隐马尔科夫模型,可以通过内在的相似性来判断应用程序与各个类别的相似度;在此基础之上引入更适合处理分类问题的随机森林模型,在一定程度上反映出不同类别、相似行为的差异,即利用随机森林分类器模型对相似的行为序列进行识别。
参照图1,本发明的双重安全认证过程如下:
步骤1,收集网络数据。
使用数据包捕获工具,分别收集正常软件样本和恶意软件样本所产生的运行时应用程序接口调用数据流,将收集到的运行时应用程序接口调用数据流作为训练恶意软件检测模型的初始数据集;
步骤2,应用程序接口调用数据流分组。
根据应用程序接口数据流的分组规则,对初始应用程序接口调用数据集进行分组,得到多个不同应用程序接口数据流类型的分组。
所述的应用程序接口数据流的分组规则是指,对于初始数据集中的应用程序接口数据流,按照数据流的时间顺序,将两个数据流时间间隔小于4.5秒的相邻应用程序接口数据流,划分为一个数据流分组。
步骤3,提取数据流最小单元。
根据应用程序接口数据流最小单元的分组规则,提取不同应用程序接口数据流类型的分组,从运行时trace文件生成的应用程序接口数据流调用关系树中,提取应用程序接口数据流最小单元;
所述的应用程序接口数据流最小单元的分组规则是指,对于每一个应用程序接口数据流分组内的数据包,按照数据包的时间顺序,将具有相同的应用程序接口数据包,划分成一个应用程序数据流最小单元,7<count<256,其中,count为应用程序数据流最小单元中数据包的总数。
步骤4,提取调用序列特征。
根据运行时trace文件对应的应用程序接口数据流最小单元,分别从每个应用程序接口数据流最小单元的头部字段调用信息中,提取多种网络行为特征序列;
将提取到的多种网络行为特征中每一项网络行为特征作为对应向量的每一列特征元素,组成字段网络特征向量;
所述的网络特征向量包括,硬件访问、隐私信息获取、网络请求、网络数据传输、频繁文件读写、系统资源高负载、空闲状态字段。
步骤5,训练隐马尔科夫模型。
分别将每个字段网络特征向量标记为与该特征向量对应的软件样本类别,将所有标记后的字段网络特征向量组成隐马尔科夫模型的训练样本集;
利用baum-welch算法,对训练样本集进行训练,得到隐马尔科夫模型;
利用最大似然推导公式,计算在baum-welch算法下得到的隐马尔科夫模型的最大似然输出,将多个类型的最大似然输出组成最大似然向量;
所述的软件样本类别包括,正常软件样本和恶意软件样本两种类别。
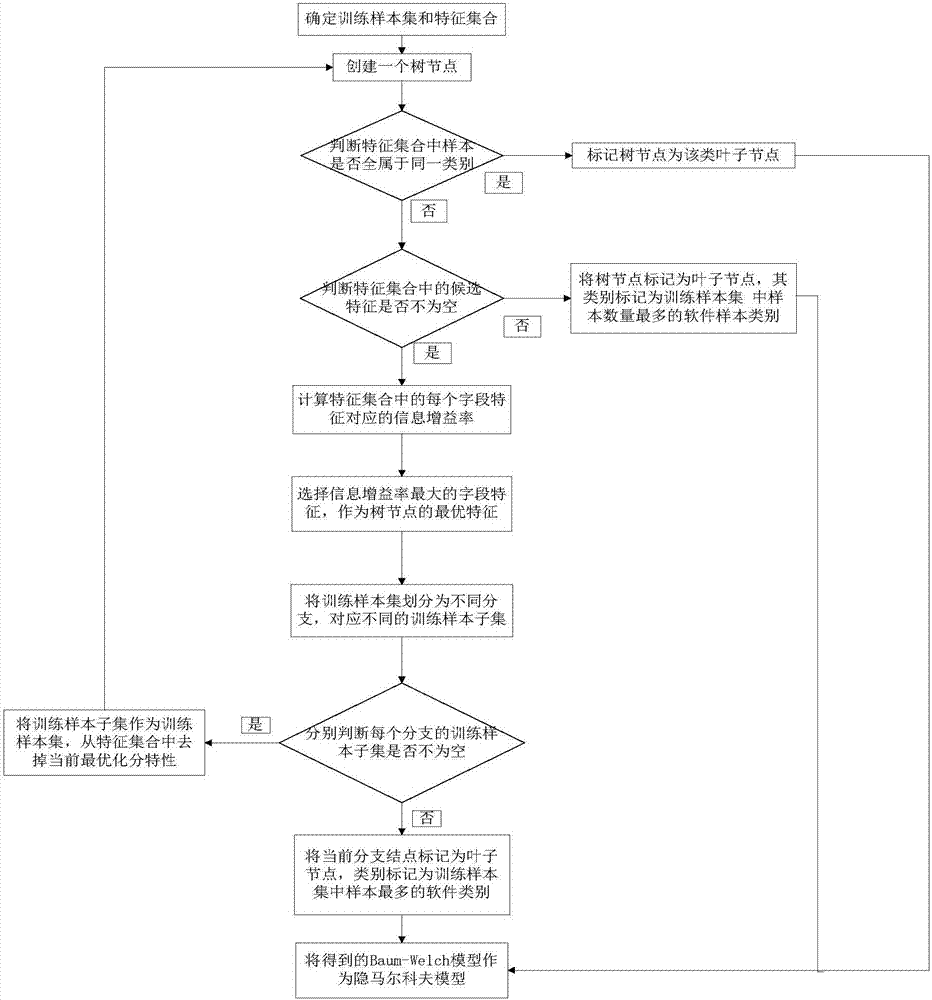
参照附图2,对使用baum-welch算法训练隐马尔科夫模型模型的步骤做进一步的描述。
所述的baum-welch算法的具体步骤如下。
第1步,将字段特征向量作为训练样本集,其中每个字段特征向量的所有字段特征组成特征集合;
第2步,创建一个树节点;
第3步,判断训练样本集中的样本是否全属于同一类别,若是,则执行第4步,否则,执行第5步;
第4步,将树节点标记为该类叶子结点,执行第13步;
第5步,判断特征集合中的候选特征是否不为空,若是,则执行第7步,否则,执行第6步;
第6步,将树节点标记为训练样本集中样本数最多的软件样本类别,执行第13步;
第7步,按照下式,计算训练样本集的信息熵:
其中,h(d)表示训练样本集d的信息熵,σ表示求和操作,v表示当前字段特征向量中向量元素的总数,pj表示到达第j个字段特征的概率的总和,*表示相乘操作,log2表示以2为底的自然对数操作;
第8步,按照下式,计算特征集合中每个字段特征的信息增益率:
其中,ii表示特征集合中第i个字段特征的信息增益率,|·|表示取绝对值操作,dj表示所有训练样本中特征值均相等为数值j的训练样本集;
第9步,从特征集合所有字段特征的信息增益率中,选择信息增益率最大的字段特征,作为树节点的最优特征;
第10步,将训练样本集代入树节点的最优特征的信息增益率公式中,得到训练样本集的不同取值,将训练样本集以取值相同为依据划分为不同的训练样本子集;
第11步,判断每个训练样本子集是否不为空,若是,则执行第12步,否则,生成一个子节点,执行第13步;
第12步,将训练样本子集作为训练样本集,从特征集合中去掉当前最优特征,继续递归执行第2步;
第13步,将当前分支结点标记为叶子结点,类别标记为训练样本集中样本最多的类别,循环结束,将每一个子节点依次串联生成baum-welch模型,执行第14步;
第14步,将baum-welch模型作为隐马尔科夫模型。
所述的最大似然推导公式如下:
第1步,按照下式,计算特征集合的转移概率:
其中,aij表示状态特征qi转移到状态特征qj的转移概率,t表示当前字段特征向量中向量元素的总数,δ(qi,qj)表示状态特征qi与状态特征qj的克罗奈可值,当状态特征qi与状态特征qj相等时,δ(qi,qj)等于1,当状态特征qi与状态特征qj不相等时,δ(qi,qj)等于0,qt表示特征集合中第t个字段特征,qi表示特征集合中第i个字段特征,qt+1表示特征集合中第t+1个字段特征,qj表示特征集合中第j个字段特征;
第2步,按照下式,计算特征集合的发散概率:
其中,bj(k)表示从特征集合中的状态特征qj至下一个状态特征qk的发散概率;
第3步,将状态特征qi与状态特征qj的转移概率和发散概率作为特征集合的最大似然输出。
步骤6,训练随机森林模型。
将最大似然向量作为随机森林模型的观测值训练样本集;
利用随机森林算法,对训练样本集进行训练,得到随机森林分类器检测模型;
利用随机森林算法,对训练样本集进行训练,得到统计特征检测模型。
参照附图2,对使用随机森林算法训练统计特征检测模型的步骤做进一步的描述。
所述的随机森林算法的具体步骤如下。
第1步,在[100,200]的范围内任意选取一个数,将其设定为随机森林中的基分类器的总数;
第2步,使用自助采样法,对应用程序数据流特征向量组成的训练样本集进行采样,得到基分类器的训练样本集;
第3步,从基分类器的训练样本集的统计特征集合中,随机选取m个特征,组成特征子集,m=log2m,其中m表示统计特征集合中的特征总数;
第4步,使用基分类器的训练样本集和特征子集对一棵决策树模型进行训练,将训练后的决策树模型存入到基分类器集合中;
第5步,判断基分类器集合中的决策树模型总数是否等于设定的基分类器的总数,若是,则执行第6步,否则,执行第2步;
第6步,将基分类器集合中的所有决策树模型组成随机森林,作为统计特征检测模型。
步骤7,提取待检测样本的应用程序接口数据流特征。
利用网络数据包捕获工具,实时捕获待检测样本的应用程序接口数据流特征;
根据各类数据流的分组定义规则,得到待检测样本的应用程序接口数据流分组;
根据数据流最小单元的定义规则,从待检测样本的应用程序接口数据流分组中提取应用程序接口数据流最小单元;
提取到网络行为特征作为向量的元素,组成字段网络特征向量;
步骤8,将待检测样本的特征向量输入随机森林检测模型,判断字段网络特征检测模型的输出是否为恶意软件类别,若是,则执行步骤(9),否则,执行步骤(10);
步骤9,将待检测样本标记为恶意软件,输出待检测样本对应的恶意软件类别。
步骤10,将待检测样本标记为正常软件,输出待检测样本对应的正常软件类别。
- 还没有人留言评论。精彩留言会获得点赞!