一种基于田纳西伊斯曼过程的先验知识故障诊断方法与流程
本发明涉及一种故障检测与诊断技术,具体地说是一种基于田纳西伊斯曼过程的先验知识故障诊断方法。
背景技术:
基于图的半监督分类算法是先验知识学习中应用最多的一类算法。通过对数据集中所有样本(包括有标记样本和无标记样本)转化成一个定义了代表样本的结点和代表结点之间权值的边的连通加权无向图。结点与结点的边代表了两个样本间的某种关系,称之为相似性。最后在连通加权无向图中进行训练。这里指出,这类算法只对具有一定规律的样本有效,可以实现有标记样本对整个数据集的样本分布预测。如果整个数据集的样本是杂乱无章的,那么有标记样本就算再多对样本的分类也不会有什么效果。如果给的数据毫无规律,那么标记样本在总样本中的比重再大也没有用,分类没有意义效果也不会好。
已知训练样本
t={(x1,y1),...(xi,yj),...(xl,yl)}∪{xl+1,...xn}
其中:xi∈rd,i=1,...,n表示输入数据,对于二类故障问题来说,yi∈{-1,+1},i=1,...,l;对于多类故障问题来说,yi∈{1,2,...,c},i=1,...,l。其中c表示故障状态类别,然后基于这个方法识别与输入xl+1,...,xn对应的故障状态类别yl+1,...,yn。
基于图的半监督学习算法通过在加权无向图上估计出一个函数f,要求该函数需要满足以下两个条件:(1)策函数需要与有标记的样本的实际标记相近,能够在一定程度上表现有标记样本的分布;(2)策函数需要在样本分布的无向加权图上光滑。
在设计一个二分类问题决策函数的过程中,可能遇到划分曲线虽然充分考虑了训练集上的有标记样本,却未考虑决策函数的泛化能力。在训练集中可以有效的将两类有标记的样本分开,但用于对测试集进行分类是出现了错误分类。
为了解决之前考虑的问题,即在设计决策函数时单单考虑经验损失会带来过拟合的问题,需要在决策函数中加入合适的正则项使其具有一定的泛化能力。因而基于图的半监督学习算法就转化成了一个正则化问题。
基于图的半监督学习算法的正则化问题可以总结为下面的数学问题:
其中:f表示实值函数,h表示hibert空间,目标函数
基于图的半监督学习算法有很多,belkin等人首次提出一种基于全局的流行正则化方法来学习未标记样本的类标记的学习算法。朱晓进等人提出的基于图的拉普拉斯正则化方法,通过学习高斯场和谐波函数来实现半监督学习。通过聚类假设定义能量函数,之后在加权无向图上求解最优值来标记未标记样本,此方法目前是基于图的半监督学习方法中非常重要且有效的一个方法。
田纳西伊斯曼-伊斯曼过程是基于名为tenesseeeastman的化学公司的真实化学工业过程设计出来的真实化学工业过程,a、c、d、e代表四个进料气体、惰性成分b进去反应器,在相应的催化剂催化下,g、h作为生成物,f则表示副产品,整个化学反应过程是稳定的、放热的、不可逆的。冷凝器存在于反应器的内部,将反应过程中的热量传递出来,中间反应过程的生成物通过冷凝器进行冷却,并在后面的分离器中将液态和气态产物分离出来。其中气态产物以蒸汽的形式进入离心式压缩机,在其作用下循环后并最终送回反应器的进料口位置。为了避免反应的副产品以及惰性气体出现积聚现象,一部分的气态物会被排入循环流。而液态产物则会以液体的形式进入汽提塔,生成主要以a、c作为主要成分的流股,并作为气提流股,而未反应的残存物则会分离出各个组分,从汽提塔的最下面来到位于界区外的精致处理工段。此外,汽提塔最下面的生成品g、h会进行后续过程的处理,副产品和惰性气体则会在分离器中以气液分离的方法转移出系统。田纳西伊斯曼-伊斯曼过程共计有12个控制变量和41个测量变量。其中41个测量变量是由对各类浓度进行测量得到的19个成分测量值和连续测量的22个连续测量值构成的。详细的变量名称以及过程chiang.等人给出了十分详尽的介绍,这里指出全部的过程都有高斯噪声成分。田纳西伊斯曼-伊斯曼过程仿真系统中用来作为故障诊断的数据都是来自http://brahms.scs.uiuc.edu,整个仿真数据包中的测量值是由11个控制变量值以及41个数据测量值组成的(这里未涉及反应器的搅拌速率),共计有52个变量观测值。在每一类数据包内都存在600个一组的采样训练数据和600个一组共计三组的采样含故障测试数据,各自的故障训练数据对应各自的故障测试数据,不能相互代替,否则离线建模等一系列操作的准确度都将受到影响,甚至会出现故障检测无效或者故障检测不出的问题。
传统在线故障监测流程图如图1所示,局部学习思想就是每一个样本点xi都可以由其局部邻域ni内的样本点估计,与传统的基于解析模型的方法有别,基于知识点的方法并没有准确的解析模型要求,它是通过故障诊断领域内的专家学者在不断分析归纳基础上总结出可以作为故障诊断方法的经验来进行故障处理的方法。它能够从大方向上定性的分析实际工业过程的数据,用经验方法实现对工业故障有效迅速的检测和诊断。基于半监督学习的方法显然在实际工业过程中具有更强的适应性,如何设计更好的分类器或者提高分类器的性能成为半监督学习领域的热点问题。在过去基于知识的模型中,往往知识在构造算法模型时对其施加一个约束,比如一个拉普拉斯正则项,在过去的仿真当中往往很难获得切实有效的决策函数。
技术实现要素:
针对现有技术中采用先验知识故障检测方法很难获得切实有效的决策函数等不足,本发明要解决的问题是提供一种具有更好的故障检测效果的基于田纳西伊斯曼过程的先验知识故障诊断方法。
为解决上述技术问题,本发明采用的技术方案是:
本发明一种基于田纳西伊斯曼过程的先验知识故障诊断方法,包括以下步骤:
1)采集田纳西伊斯曼过程的离线历史数据x=[x1,x2,...,xl,xl+1,...,xn]∈rm×n,其中xi(i=1,2,...,l)为已经通过专家先验知识标记的数据,xi(i=l+1,l+2,...,n)是未标记数据,l为已标记故障状态类别的数目,n为历史数据故障状态类别的总数目;初始化矩阵y∈rn×c,其中c表示故障状态类别,rm×n、rn×c均代表数据规模大小;
2)选择调节参数矩阵u∈rn×n和knn算法中的k;其中,u∈rn×n表示对角阵,k为近邻样本个数;
3)在已有的加权无向图上构建邻接矩阵w,在此基础上算出矩阵d,定义拉普拉斯矩阵l=d-w,根据拉普拉斯正则化算法,计算拉普拉斯正则项
4)根据局部正则化算法,计算局部正则项(i-a)t(i-a),其中,i为n×n的单位矩阵,a为参数矩阵;
5)根据
6)根据
步骤4)中,计算局部正则项(i-a)t(i-a)为:
在局部区域中,对于输入的各个xi都对应有一个fi值,同时,在其邻域样本集上学习得到的决策函数g(x)也有一个输出值g(xi),将二者之间的差
距转化为最优化问题的正则项||f-g||2,其矩阵形式为:
其中输出函数g(x)借助线性形式表达为:
其中:wi∈rn,bi∈r,ni为xi的邻域,i=1,2,...,n,它的解通过计算以下最优化问题获得:
其中:λ为调节系数,λ>0,权重向量wi∈rn,bi为r偏差项,bi∈r,线性形式中对于每个输入xi,要有训练数据(xj、fj),xj、fj分别为训练数据的输入和输出;
对输入xi,i=1,2,...,n,ni为xi的邻域,ni代表ni中样本个数,记作
由公式可知αi仅和xi有关,而与fi无关,将αi扩展成矩阵a=(aij)∈rn×n,当xj∈ni时,aij=αij;当
||f-g||2=ft(i-a)t(i-a)f
i为n×n的单位矩阵,(i-a)t(i-a)即为局部正则项的正则项因子。
步骤5)中,根据
本发明具有以下有益效果及优点:
1.本发明方法在决策函数中加入拉普拉斯正则项的同时加入局部正则项,尽可能的利用两类约束条件的优点,使得的算法具有更好的故障检测效果,充分挖掘和利用标记样本和未标记样本特征信息建立故障诊断模型,同时用田纳西伊斯曼过程数据进行验证,其中在最后分类阶段,对分类器进行了改进,提高了分类的精度,同时对样本的错分率及样本分离度等验证标准都有所改进。
附图说明
图1为现有技术中基于先验知识的在线故障监测流程图;
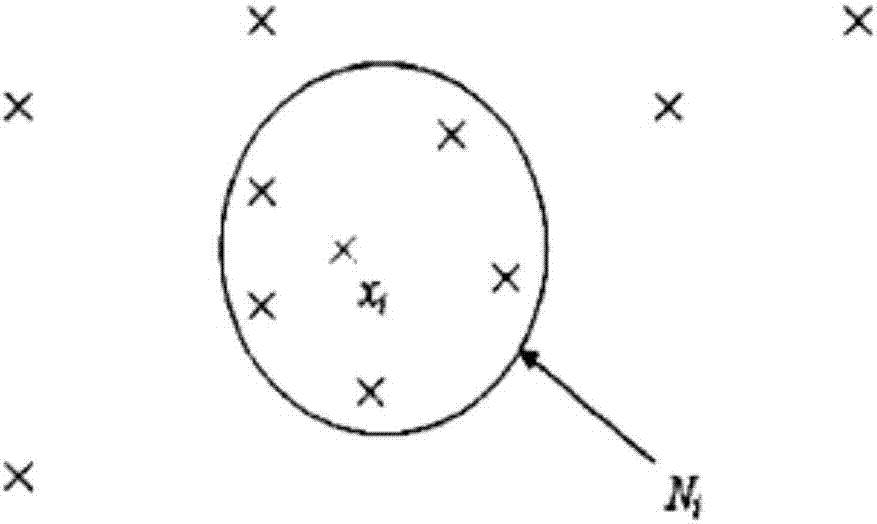
图2为本发明中半监督学习局部信息示意图;
图3(a)为本发明具体实施方式中单一故障样本标记训练、单一故障测试样本标记百分比为5%时仿真效果图;
图3(b)为本发明具体实施方式中单一故障样本标记训练、单一故障测试样本标记百分比为10%时仿真效果图;
图3(c)为本发明具体实施方式中单一故障样本标记训练、单一故障测试样本标记百分比为15%时仿真效果图;
图4(a)为本发明具体实施方式中两种故障样本标记训练、第一种故障测试样本标记百分比为5%时仿真效果图;
图4(b)为本发明具体实施方式中两种故障样本标记训练、第一种故障测试样本标记百分比为10%时仿真效果图;
图4(c)为本发明具体实施方式中两种故障样本标记训练、第一种故障测试样本标记百分比为15%时仿真效果图;
图5(a)为本发明具体实施方式中两种故障样本标记训练、第二种故障测试样本标记百分比为5%时仿真效果图;
图5(b)为本发明具体实施方式中两种故障样本标记训练、第二种故障测试样本标记百分比为10%时仿真效果图;
图5(c)为本发明具体实施方式中两种故障样本标记训练、第二种故障测试样本标记百分比为15%时仿真效果图。
具体实施方式
下面结合说明书附图对本发明作进一步阐述。
本发明基于田纳西伊斯曼过程的先验知识故障诊断方法包括以下步骤:
1)采集田纳西伊斯曼过程的离线历史数据x=[x1,x2,...,xl,xl+1,...,xn]∈rm×n,其中xi(i=1,2,...,l)为已经通过专家先验知识标记的数据,xi(i=l+1,l+2,...,n)是未标记数据,l为已标记故障状态类别的数目,n为历史数据故障状态类别的总数目;初始化矩阵y∈rn×c,其中c表示故障状态类别,rm×n、rn×c均代表数据规模大小;
2)选择调节参数矩阵u∈rn×n和knn算法中的k;其中,u∈rn×n表示对角阵,k为近邻样本个数;(knn,即k近邻算法。是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。k通常是不大于20的整数。knn算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。是自己取值的,取3或5,一般小于20;
3)在已有的加权无向图上构建邻接矩阵w,在此基础上算出矩阵d,定义拉普拉斯矩阵l=d-w,根据拉普拉斯正则化算法,计算拉普拉斯正则项
4)根据局部正则化算法,计算局部正则项(i-a)t(i-a),其中,i为n×n的单位矩阵,a为参数矩阵;
在定理1的推导中,推出决策函数的输出值g=af,进一步可得||f-g||2=ft(i-a)t(i-a)f
5)根据
6)根据
步骤1)中,初始化矩阵y∈rn×c,y示标签数据的标记信息,为n×c阶矩阵。初始化矩阵y的元素定义为:
步骤2)中,选择调节参数矩阵u∈rn×n和knn算法中的k是基于半监督学习算法的故障检测方案:
并定义
将上式改写为矩阵形式
其中u∈rn×n表示对角阵,它们的对角元素ui表示一个正的调节参数,本步骤选择适当的调节参数矩阵u∈rn×n和knn算法中的k。j(f)函数里面的参数ui组成的矩阵,是定义在里面的调节系数。
步骤3)中,在已有的加权无向图上构建邻接矩阵w,w=(wij)∈rn×n表示一个对称半正定矩阵,wij表示样本xi与xj的相似度,计算公式是
其中:σ2表示一个调节参数,ni表示xi的k个最近邻居集合,nj表示xj的k个最近邻居集合;在此基础上算出矩阵d,d表示度矩阵,是对角矩阵,对角元素
最终定义拉普拉斯矩阵l=d-w,并对拉普拉斯矩阵正则化,得到拉普拉斯正则项
其中,i为n×n的单位矩阵。
步骤4)中,如图2所示,半监督学习问题中,在局部区域,对于输入的各个xi都对应有一个fi值,同时,在其邻域样本集上学习得到的决策函数g(x)也有一个输出值g(xi),这两个值理论上应该相近或相同。基于这一点,为了让二者之间的差距足够小,即
其中决策函数g(x)借助线性形式来表达
其中:wi∈rn,bi∈r,ni为xi的邻域,i=1,2,...,n。它的解可以通过计算以下的最优化问题获得
其中:λ为线性模型的系数,λ>0。
定理1对输入xi,i=1,2,...,n,ni为xi的邻域,ni代表ni中样本个数,记作
证明:已知最优化问题
令
l与wi和bi有关,分别令
于是
同理
于是
于是
所以
对
于是
因而有
进一步对公式进行简化有
其证明如下:
证明:已知
于是
由公式可知αi仅和xi有关,而与fi无关,将αi扩展成矩阵a=(aij)∈rn×n,当xj∈ni时,aij=αij;当
通过上述一系列证明,得到||f-g||2=ft(i-a)t(i-a)f,i为n×n的单位矩阵,因此,(i-a)t(i-a)即为局部正则项的正则项因子。
步骤5)中,根据
步骤6:根据
来标记未标记样本,归一化后得出xi的每个故障分类情况。
经过田纳西伊斯曼过程过程数据的仿真实验,可以看出本发明在处理情况一,即单一故障样本标记训练、单一故障测试。训练样本为标记了一部分故障1的训练数据,观察测试故障1的效果。
故障一为田纳西伊斯曼过程中的进料b成分改变,a/c比值保持不变(管道4),属于阶跃故障)时,采样数据的训练样本的故障信息标记应保证在百分之十及其以上(经过分别观察附图3(a)~3(c)发现,已标识故障类型的样本占总体训练样本大于百分之十时,分类效果十分明显),如图3(a)~3(c)所示;
在处理情况二(两种故障样本标记训练、第一种故障测试)。
故障二为田纳西伊斯曼过程中的冷凝器冷却水入口温度发生变化(管道13),属于阶跃故障,采样数据的训练样本的故障信息标记应保证在百分之十及其以上(经过分别观察附图4(a)~4c)发现,已标识故障类型的样本占总体训练样本大于百分之十时,分类效果十分明显),如图4(a)~4(c)所示;
在处理情况三(两种故障样本标记训练、第二种故障测试),训练样本为部分标记出故障1和故障2的数据,只观察测试故障2的效果。故障一为田纳西伊斯曼过程中的进料b成分改变,a/c比值保持不变(管道4),属于阶跃故障;故障二为田纳西伊斯曼过程中的冷凝器冷却水入口温度发生变化(管道13),属于阶跃故障),采样数据的训练样本的故障信息标记应保证在百分之十以上,经过分别观察附图5(a)~5(c)发现,已标识故障类型的样本占总体训练样本大于百分之十时,分类效果十分明显,如图5(a)~5(c)所示。
经上这比较,可以得出经本方案实施的故障识别效果更显著的结论。
- 还没有人留言评论。精彩留言会获得点赞!