一种基于PCA‑PSO‑ELM的瓦斯涌出量预测方法与流程
本发明属于瓦斯涌出量预测技术领域,具体涉及一种基于pca-pso-elm的瓦斯涌出量预测方法。
背景技术:
瓦斯是危及煤矿安全生产的主要灾害之一,准确预测瓦斯涌出量是实现瓦斯有效管理和保障煤矿安全生产的基础工作。目前对瓦斯涌出量进行预测的方法主要有基于灰色系统理论的方法、主成分分析结合多步线性回归法、emd-svm法、emd-pso-svm法、lle结合ba-elman的方法、蚁群粒子群混合算法优化ls-svm的方法等,采用上述方法对瓦斯涌出量进行预测取得了大量研究成果,但是矿井瓦斯涌出量受到煤层瓦斯含量、煤层厚度、煤层倾角、煤层埋藏深度等诸多因素的影响,影响因素之间及其与瓦斯涌出量之间呈现出复杂的非线性、相关性特征,为瓦斯涌出量的预测带来了一定的影响,因此有必要继续探索新的方法对瓦斯涌出量进行预测。
主成分分析(principalcomponentanalysis,pca)是一种常见的数据简化方法,能够消除数据之间的相关性;极限学习机(extremelearningmachine,elm)是黄广斌等人提出的一种智能优化算法,具有泛化性能好、学习速度快、设置参数少的优点,目前在很多领域得到广泛应用,如朱志洁等采用遗传算法优化极限学习机的输入权值和隐含层偏差对冲击地压进行了预测,然而极限学习机的性能主要受隐含层神经元个数及激活函数的影响较大,且当隐含层神经元个数较多时需要优化的参数较多;丁华等采用遗传算法优选最佳隐层神经元个数,使用递进方式比选确定激励函数对采煤机功率进行了预测,然而由于在对隐含层神经元数量进行寻优时已经固定了激活函数的类型,且输入层与隐含层的权值与隐含层阈值是随机产生的,因此难以保证运行结果的唯一性。此外在对极限学习机的参数进行训练时没有充分考虑模型的过拟合问题,因而无法保证模型的预测性能。粒子群算法(particleswarmoptimization,pso)是一种性能良好的全局随机搜索算法,而十折交叉验证可以较好地避免模型过拟合问题,因而可以采用粒子群算法结合十折交叉验证对极限学习机中隐含层神经元个数及激活函数的类型两个参数进行组合优化,进而建立瓦斯涌出量预测模型。
技术实现要素:
针对现有技术的不足,本发明提出一种基于pca-pso-elm的瓦斯涌出量预测方法。
一种基于pca-pso-elm的瓦斯涌出量预测方法,包括以下步骤:
步骤1:采集采煤矿井中瓦斯涌出量监测数据、已知瓦斯涌出量对应的影响因素数据z=[z1,z2,......,zp]t、待预测瓦斯涌出量的影响因素数据z′=[z′1,z′2,......,z′p]t,其中,zi为第i类已知瓦斯涌出量对应的影响因素数据,z′i为第i类待预测瓦斯涌出量的影响因素数据,i=1,2,…,p,p为瓦斯涌出量的影响因素个数;
所述瓦斯涌出量的影响因素包括地质因素、开采因素、开采层原始瓦斯含量和临近层瓦斯含量;
所述地质因素包括:煤层深度、煤层厚度、煤层倾角、煤层间距、临近层厚度、层间岩性;
所述开采因素包括:采高、工作面长度、推进速度、采出率、日产量。
步骤2:对已知瓦斯涌出量对应的影响因素数据z=[z1,z2,......,zp]t和待预测瓦斯涌出量的影响因素数据z′=[z′1,z′2,......,z′p]t同时进行标准化处理,得到标准化后的瓦斯涌出量的影响因素数据x=[x1,x2,......,xp]t;
所述对已知瓦斯涌出量的影响因素数据z=[z1,z2,......,zp]t和待预测瓦斯涌出量的影响因素数据z′=[z′1,z′2,......,z′p]t同时进行标准化处理采用的方法为zscore标准化法。
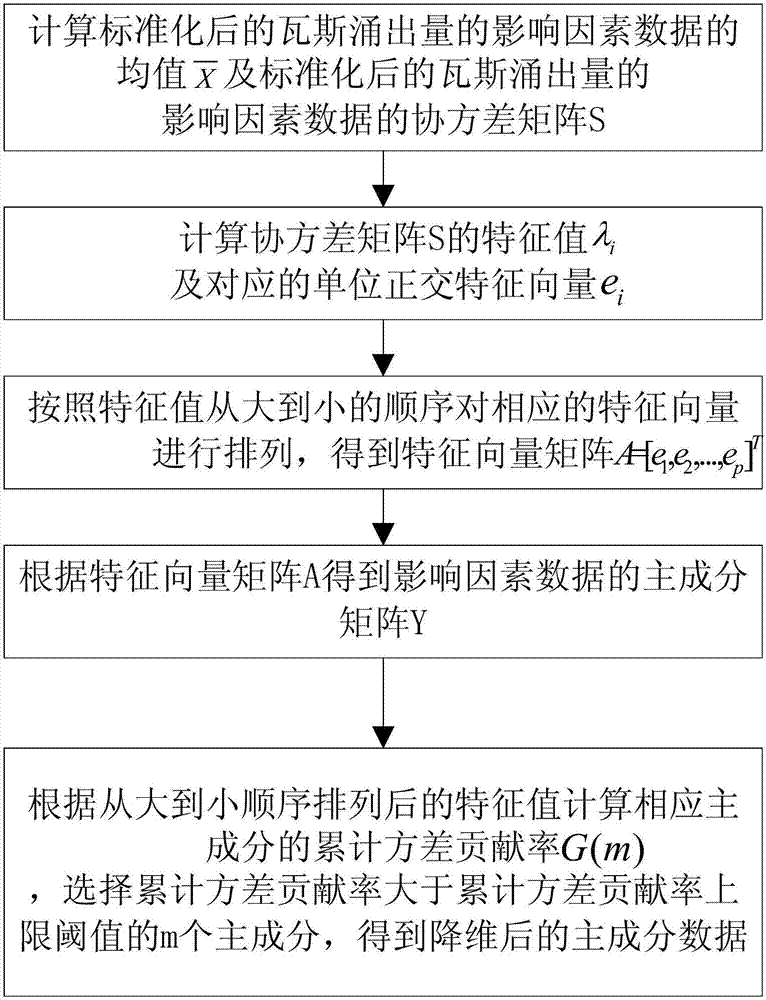
步骤3:采用主成分分析法对标准化后的瓦斯涌出量的影响因素数据进行处理,得到降维后的主成分数据,将已知瓦斯涌出量对应的影响因素数据z及其降维后的主成分数据作为训练样本集,将待预测瓦斯涌出量的影响因素数据z′降维后的主成分数据作为测试数据集,记为e;
步骤3.1:计算标准化后的瓦斯涌出量的影响因素数据的均值
步骤3.2:计算协方差矩阵s的特征值λi及对应的单位正交特征向量ei;
步骤3.3:按照特征值从大到小的顺序对相应的特征向量进行排列,得到特征向量矩阵a=[e1,e2,...,ep]t;
步骤3.4:根据特征向量矩阵a得到影响因素数据的主成分矩阵y=[y1,y2,......,yp]t=ax,其中,yi为第i个主成分数据;
步骤3.5:根据从大到小顺序排列后的特征值计算相应主成分的累计方差贡献率g(m),选择累计方差贡献率大于累计方差贡献率上限阈值的m个主成分,得到降维后的主成分数据,将已知瓦斯涌出量对应的影响因素数据z及其降维后的主成分数据作为训练样本集,将待预测瓦斯涌出量的影响因素数据z′降维后的主成分数据作为测试数据集,记为e,其中,m<p。
所述根据从大到小顺序排列后的特征值计算相应主成分的累计方差贡献率g(m)的公式如下所示:
其中,m∈{1,2,...,p}为选择的主成分个数,k=1,2,...,p。
步骤4:建立极限学习机,将训练样本集中降维后的主成分数据作为极限学习机的输入,将训练样本集中相应的瓦斯涌出量监测数据作为极限学习机的输出,采用粒子群优化算法优化极限学习机的隐含层神经元个数和激活函数的类型组合,对迭代过程中根据每个粒子建立的极限学习机模型采用十折交叉验证法计算预测结果的均方误差,根据全局最优粒子确定极限学习机的隐含层神经元个数和激活函数的类型组合,得到瓦斯涌出量预测模型;
步骤4.1:将隐含层神经元个数和激活函数的类型组合作为粒子,设定粒子群优化算法的粒子的搜索维数d、种群规模j、最大迭代次数gmax、学习因子c1和c2、惯性因子w、粒子速度区间,随机初始化粒子群优化算法的粒子位置初值hj(1)及粒子速度初值vj(1),令迭代次数t=1,其中,j=1,...,j,gmax≥t;
所述激活函数的类型为1~3的整数,分别表示为sigmoid函数、sin函数、hardlim函数。
步骤4.2:根据当前粒子建立极限学习机,将训练样本集中降维后的主成分数据作为当前极限学习机的输入,将训练样本集中相应的瓦斯涌出量监测数据作为当前极限学习机的输出,采用十折交叉验证法测试极限学习机的性能,计算十次预测结果与训练样本集相应的瓦斯涌出量监测数据的均方误差,将该均方误差值作为相应粒子的适应度值,并更新粒子的个体极值和粒子群的全局极值;
步骤4.3:判断当前迭代次数t是否达到最大迭代次数gmax,若是,执行步骤4.5,否则,令迭代次数t=t+1,执行步骤4.4;
步骤4.4:根据t时刻粒子的个体极值pj(t)和t时刻粒子群的全局极值g(t),更新t+1时刻粒子的位置信息hj(t+1)和t+1时刻粒子的速度信息vj(t+1),返回步骤4.2;
所述根据t时刻粒子的个体极值pj(t)和t时刻粒子群的全局极值g(t),更新t+1时刻粒子的位置信息hj(t+1)和t+1时刻粒子的速度信息为vj(t+1)的计算公式如下所示:
其中,vj(t)为t时刻第j个粒子的速度信息,hj(t)为t时刻第j个粒子的位置信息,r1和r2为[0,1]范围内的随机数。
步骤4.5:根据全局极值确定极限学习机的隐含层神经元个数和激活函数的类型;
步骤4.6:根据步骤4.5确定的隐含层神经元个数和激活函数的类型建立极限学习机,即得到瓦斯涌出量预测模型;
步骤5:对瓦斯涌出量进行预测,将测试数据集e输入作为瓦斯涌出量预测模型,得到瓦斯涌出量的预测值。
本发明的有益效果:
本发明提出一种基于pca-pso-elm的瓦斯涌出量预测方法,由于瓦斯涌出量的影响因素较多,且具有非线性、相关性特征,采用主成分分析消除了各影响因素数据间的相关性,同时减少了指标个数;极限学习机的性能受隐含层神经元个数及激活函数类型的影响较大,采用粒子群算法结合十折交叉验证对极限学习机中隐含层神经元个数及激活函数类型进行了组合优化,该方法减少了优化的参数,同时保证了模型具有良好的泛化性能。
附图说明
图1为本发明具体实施方式中基于pca-pso-elm的瓦斯涌出量预测方法的流程图;
图2为本发明具体实施方式中采用主成分分析法对标准化后的瓦斯涌出量的影响因素数据进行处理的流程图;
图3为本发明具体实施方式中适应度函数进化图。
具体实施方式
下面结合附图对本发明具体实施方式加以详细的说明。
一种基于pca-pso-elm的瓦斯涌出量预测方法,如图1所示,包括以下步骤:
步骤1:采集采煤矿井中瓦斯涌出量监测数据、已知瓦斯涌出量对应的影响因素数据z=[z1,z2,......,zp]t、待预测瓦斯涌出量的影响因素数据z′=[z′1,z′2,......,z′p]t,其中,zi为第i类已知瓦斯涌出量对应的影响因素数据,z′i为第i类待预测瓦斯涌出量的影响因素数据,i=1,2,...,p,p为瓦斯涌出量的影响因素个数。
本实施方式中,瓦斯涌出量的影响因素包括地质因素、开采因素、开采层原始瓦斯含量和临近层瓦斯含量。
地质因素包括:煤层深度、煤层厚度、煤层倾角、煤层间距、临近层厚度、层间岩性。
开采因素包括:采高、工作面长度、推进速度、采出率、日产量。
本实施方式中,瓦斯涌出量的影响因素个数p=13。
本实施方式中,选取某煤矿30组瓦斯涌出量监测数据及对应的瓦斯涌出量的影响因素数据,其中前25组数据用来表示已知瓦斯涌出量监测数据及对应的影响因素数据z,用于生成训练样本集,剩余5组数据用于生成测试样本集,其中的瓦斯涌出量影响因素数据表示为z′用于预测瓦斯涌出量,将预测结果与真实监测数据进行比较来验证所提方法的有效性,采集的数据如表1所示:
表1瓦斯涌出量监测数据及对应的影响因素数据
表1中,n1为煤层深度、n2为煤层厚度、n3为煤层倾角、n4为开采层原始瓦斯含量、n5为煤层间距、n6为采高、n7为临近层瓦斯含量、n8为临近层厚度、n9为层间岩性、n10为工作面长度、n11为推进速度、n12为采出率、n13为日产量。
步骤2:对已知瓦斯涌出量对应的影响因素数据z=[z1,z2,......,zp]t和待预测瓦斯涌出量的影响因素数据z′=[z′1,z′2,......,z′p]t同时进行标准化处理,得到标准化后的瓦斯涌出量的影响因素数据x=[x1,x2,......,xp]t。
本实施方式中,所述对已知瓦斯涌出量的影响因素数据z=[z1,z2,......,zp]t和待预测瓦斯涌出量的影响因素数据z′=[z′1,z′2,......,z′p]t同时进行标准化处理采用的方法为zscore标准化法,公式如式(1)所示:
其中,xin为标准化后的第i类已知瓦斯涌出量的影响因素数据的第n个值,μi为第i类瓦斯涌出量的影响因素数据的均值,σi为第i类瓦斯涌出量的影响因素数据的标准差,zin为第i类瓦斯涌出量的影响因素数据的第n个值。
本实施方式中,对各瓦斯涌出量的影响因素数据进行相关性分析,得到的相关系数如表2所示:
表2瓦斯涌出量的影响因素数据的相关系数
从2表中可见各指标之间存在较强的相关性,如煤层深度x1与开采层原始瓦斯含量x4的相关系数达到0.972,煤层厚度x2与采高x6的相关系数达到0.991,直接使用上述指标对瓦斯涌出量进行预测必然会对预测结果的精度产生影响,因此采用主成分分析消除指标间的相关性,并降低数据的维度。
步骤3:采用主成分分析法对标准化后的瓦斯涌出量的影响因素数据进行处理,得到降维后的主成分数据,将已知瓦斯涌出量对应的影响因素数据z及其降维后的主成分数据作为训练样本集,将待预测瓦斯涌出量的影响因素数据z′降维后的主成分数据作为测试数据集,记为e。
步骤3.1:计算标准化后的瓦斯涌出量的影响因素数据的均值
步骤3.2:计算协方差矩阵s的特征值λi及对应的单位正交特征向量ei。
步骤3.3:按照特征值从大到小的顺序对相应的特征向量进行排列,得到特征向量矩阵a=[e1,e2,...,ep]t;
步骤3.4:根据特征向量矩阵a得到影响因素数据的主成分矩阵y=[y1,y2,......,yp]t=ax,其中,yi为第i个主成分数据。
步骤3.5:根据从大到小顺序排列后的特征值计算相应主成分的累计方差贡献率g(m),选择累计方差贡献率大于累计方差贡献率上限阈值的m个主成分,得到降维后的主成分数据,将已知瓦斯涌出量对应的影响因素数据z及其降维后的主成分数据作为训练样本集,将待预测瓦斯涌出量的影响因素数据z′降维后的主成分数据作为测试数据集,记为e,其中,m<p。
本实施方式中,累计方差贡献率上限阈值为85%。
本实施方式中,根据从大到小顺序排列后的特征值计算相应主成分的累计方差贡献率g(m)的公式如式(2)所示:
其中,m∈{1,2,...,p}为选择的主成分个数,k=1,2,...,p。
经过主成分分析后得到前四个主成分的方差贡献率分别为0.570143162、0.162605184、0.094412701及0.058019067,累计方差贡献率达到88.5%,大于85%的累计方差贡献率,因此选取前四个主成分进行后继分析,各主成分的系数如表3所示:
表3各主成分的系数
本实施方式中,四个主成分的计算公式如式(3)~(6)所示:
由表3可知,第一个主成分主要受煤层深度x1、煤层厚度x2、开采层原始瓦斯含量x4、采高x6、临近层瓦斯含量x7的影响较大,可以将其命名为开采条件因子;第二个主成分主要受煤层倾角x3、工作面长度x10、采出率x12,其中受煤层倾角x3的影响最大,可以将该主成分命名为工作面信息因子;第三个主成分主要受煤层间距x5、临近层厚度x8的影响较大,可以将该主成分命名为临近层因子;第四个主成分主要受层间岩性x9、日产量x13影响较大,其中层间岩性的系数最大,可以将其命名为层间构造因子。
步骤4:建立极限学习机,将训练样本集中降维后的主成分数据作为极限学习机的输入,将训练样本集中相应的瓦斯涌出量监测数据作为极限学习机的输出,采用粒子群优化算法优化极限学习机的隐含层神经元个数和激活函数的类型组合,对迭代过程中根据每个粒子建立的极限学习机模型采用十折交叉验证法计算预测结果的均方误差,根据全局最优粒子确定极限学习机的隐含层神经元个数和激活函数的类型组合,得到瓦斯涌出量预测模型。
步骤4.1:将隐含层神经元个数和激活函数的类型组合作为粒子,设定粒子群优化算法的粒子的搜索维数d、种群规模j、最大迭代次数gmax、学习因子c1和c2、惯性因子w、粒子速度区间,随机初始化粒子群优化算法的粒子位置初值hj(1)及粒子速度初值vj(1),令迭代次数t=1,其中,j=1,...,j,gmax≥t。
本实施方式中,搜索维数为d=2,种群规模为t=20,最大迭代次数gmax=50,学习因子c1=1.4995,c2=1.4995,惯性因子w=0.3,粒子速度区间为[-10,10],粒子的位置区间取值设置为[1,30],粒子位置的第一维初始值设为1~30之间的随机数,对该随机数进行四舍五入取整以表示隐含层神经元个数,第二维初始值设为随机生成的1~3之间的整数,对应不同的激活函数,激活函数的类型分别为sigmoid函数、sin函数、hardlim函数,其中sigmoid函数取值为1、sin函数取值为2、hardlim函数取值为3。
步骤4.2:根据当前粒子建立极限学习机,将训练样本集中降维后的主成分数据作为当前极限学习机的输入,将训练样本集中相应的瓦斯涌出量监测数据作为当前极限学习机的输出,采用十折交叉验证法测试极限学习机的性能,计算十次预测结果与训练样本集相应的瓦斯涌出量监测数据的均方误差,将该均方误差值作为相应粒子的适应度值,并更新粒子的个体极值和粒子群的全局极值。
本实施方式中,采用十折交叉验证法计算十次预测结果与训练样本集相应的瓦斯涌出量监测数据的均方误差具体为:
根据当前粒子对应的隐含层神经元个数及激活函数类型建立极限学习机,将训练样本集中降维后的主成分数据分成十份,轮流将其中九份作为训练数据,一份作为测试数据,输入当前极限学习机,预测测试数据对应的瓦斯涌出量,经过十次运算,计算十次预测结果与瓦斯涌出量监测数据真实值的均方误差,将该均方误差作为相应粒子的适应度值。步骤4.3:判断当前迭代次数t是否达到最大迭代次数gmax,若是,执行步骤4.5,否则,令迭代次数t=t+1,执行步骤4.4。
步骤4.4:根据t时刻粒子的个体极值pj(t)和t时刻粒子群的全局极值g(t),更新t+1时刻粒子的位置信息hj(t+1)和t+1时刻粒子的速度信息vj(t+1),返回步骤4.2。
根据t时刻粒子的个体极值pj(t)和t时刻粒子群的全局极值g(t),更新t+1时刻粒子的位置信息hj(t+1)和t+1时刻粒子的速度信息为vj(t+1)的计算公式如式(7)所示:
其中,vj(t)为t时刻第j个粒子的速度信息,hj(t)为t时刻第j个粒子的位置信息,r1和r2为[0,1]范围内的随机数。
步骤4.5:根据全局极值确定极限学习机的隐含层神经元个数和激活函数的类型。
本实施方式中,最优隐含层神经元个数为11,激活函数的类型为sigmoid函数,最优均方误差为0.08089,得到的适应度函数进化图如图3所示。
步骤4.6:根据步骤4.5确定的隐含层神经元个数和激活函数的类型建立极限学习机,即得到瓦斯涌出量预测模型。
本实施方式中,瓦斯涌出量预测模型为三层结构,公式如(8)所示:
其中,m为有粒子群算法优化得到的隐含层神经元个数,xn为第n个输入数据,n=1,2,...,n,n为样本数量,ωv为输入层与隐含层的连接权值,βv为隐含层与输出层的连接权值,bv为隐含层神经元的阈值,g(*)为优化得到的极限学习机的激活函数,on为模型输出,输出层有一个节点对应相应的输出结果,该结果即为瓦斯浓度涌出量预测值。
本实施方式中,输入层与隐含层之间的权值与隐含层神经元的阈值b如表4所示:
表4输入层与隐含层之间的权值与隐含层神经元的阈值b
为了对所提方法进行比较,直接采用极限学习机根据原始数据中前25条数据建立预测模型,其中极限学习机中激活函数选择常用的sigmoid函数,经过不断尝试,当隐含层节点数设为14时,十折交叉验证结果较优,此时模型的均方误差为3.1769,明显大于pca-pso-elm方法所得结果的均方误差0.08089。
步骤5:对瓦斯涌出量进行预测,将测试数据集e输入作为瓦斯涌出量预测模型,得到瓦斯涌出量的预测值。
本实施方式中,表1中瓦斯涌出量的影响因素数据经过标准化、主成分分析降维后所得数据的后5条数据输入步骤4建立的瓦斯涌出量预测模型,预测相应的瓦斯涌出量,为了进行比较,使用上文直接采用极限学习机建立的预测模型根据表1中后5条瓦斯涌出量影响因素数据对瓦斯涌出量进行预测,预测结果如表5所示:
表5瓦斯涌出量的预测值
其中,本发明方法所得预测结果的均方误差为0.1083,为了进行比较,使用上文直接采用极限学习机建立的预测模型对5条测试数据进行预测,预测结果的均方误差为3.9701,说明本发明方法具有更好的预测能力。
- 还没有人留言评论。精彩留言会获得点赞!