一种基于改进型主元分析模型的故障检测方法与流程
本发明涉及一种工业故障检测方法,尤其涉及一种基于改进型主元分析模型的故障检测方法。
背景技术:
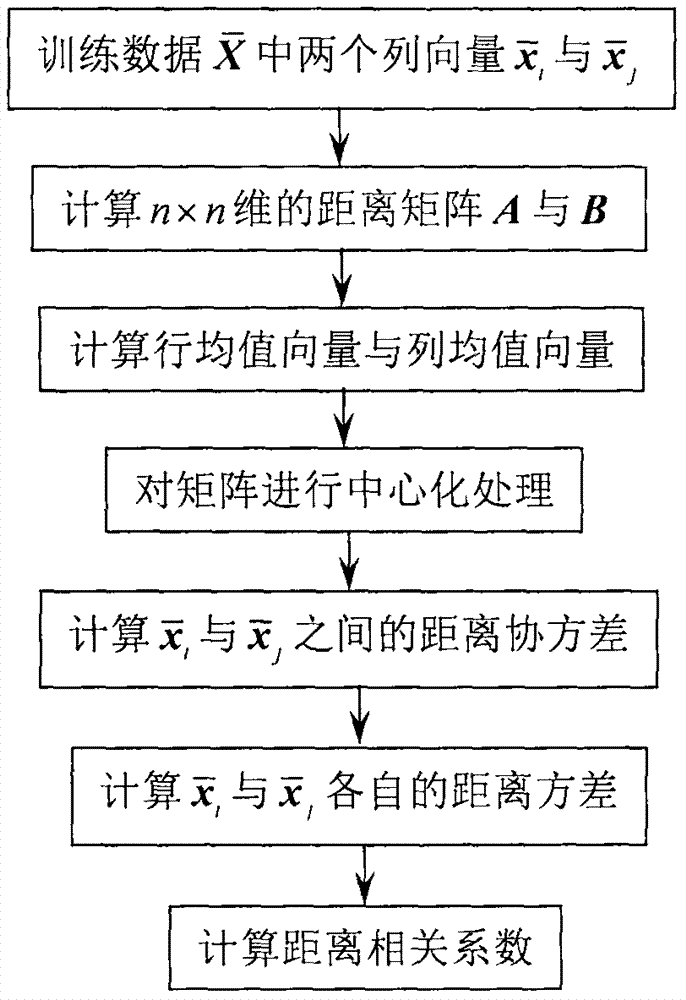
:在整个生产自动化系统中,实时监测生产过程的运行状态是非常重要的,因为它是保证生产安全和维持产品质量稳定性的最简单、最直接的技术手段。随着现代工业过程规模不断扩大,先进的仪表与计算机技术得到了广泛的应用。一方面,生产过程的机理模型越来越难以获取;另一方面,生产过程可以采集并存贮的海量的数据信息。正是在这个背景下,传统基于机理模型的故障检测方法遇到了发展的瓶颈,而数据驱动的工业过程监测方法逐步得到了工业实践者和理论研究者的青睐。数据驱动的故障检测方法一般都是对正常工况下采集到的数据进行数据特征挖掘,从而建立能描述正常数据变化特征的单分类模型。作为数据驱动的故障检测方法的核心,主元分析(principalcomponentanalysis,pca)算法在故障检测领域受到了极为广泛的研究与应用。从算法原理上讲,pca旨在挖掘训练数据间的相关性特征,从而利用少数几个潜隐变量提取原训练数据绝大部分的方差信息。近年来,基于pca的改进型故障检测方法如雨后春笋般不断涌现,解决了许多不同类型过程对象的故障检测问题。仔细研究pca算法的求解过程不难发现,pca算法首先需计算训练数据的相关系数矩阵,然后对该相关系数矩阵求解特征值及特征向量。通常来讲,相关系数矩阵中各个元素表示了训练数据各测量变量间的相关性大小,该数值的计算方式与计算两向量间角度的余弦值类似。因此,可以说传统pca算法挖掘的是训练数据的角度相关性特征。从空间分布情况来讲,表征两变量间的相关性,除了角度之外,还可以用距离。而且距离相关与角度相关可以说占有着同等重要的地位,没有孰轻孰重之分。从这点来分析,传统pca算法单独挖掘训练数据的角度相关性是一种片面的特征提取方式,缺失了对距离相关性特征的挖掘。因此,传统基于pca的故障检测方法在建模过程中需进一步考虑距离相关性,以全面的描述训练数据特征,从而提升pca算法用于故障检测的性能。技术实现要素:本发明所要解决的主要技术问题是:在pca算法用于建立故障检测模型时,如何进一步挖掘训练数据间的距离相关性特征,从而提高传统pca算法用于故障检测的效果。具体来讲,本发明方法首先计算训练数据的角度相关性矩阵与距离相关性矩阵,然后将角度相关性矩阵与距离相关性矩阵相加得到一个新的相关性矩阵,并求取相应的特征值与特征向量。最后,利用特征向量建立改进型的pca模型,并应用于在线故障检测。本发明解决上述技术问题所采用的技术方案为:一种基于改进型主元分析模型的故障检测方法,包括以下步骤:(1)采集生产过程正常运行状态下的数据样本,组成训练数据集x∈rn×m,并对每个变量进行标准化处理,得到均值为0,标准差为1的新数据矩阵其中,n为训练样本数,m为过程测量变量数,r为实数集,rn×m表示n×m维的实数矩阵,为第i个测量变量标准化后的数据,i=1,2,…,m为第i个测量变量的下标号。(2)按照公式计算训练数据的角度相关性矩阵s1∈rm×m,上标号t表示矩阵或向量的转置。(3)计算训练数据的距离相关性矩阵s2∈rm×m。(4)按照公式s=s1+s2计算得到新相关性矩阵s∈rm×m。(5)对矩阵s求取非零特征值及其对应的特征向量,并将特征值按数值大小降序排列(即:λ1≥λ2≥…≥λm),对应的特征向量为p1,p2,…,pm,其中,m为非零特征值的个数。(6)根据如下所示公式确定改进型pca模型中需要保留的主元个数d:其中,d为满足如公式(1)所示条件的最小数值。(7)计算得分矩阵并计算得分矩阵对应的协方差矩阵c=yty/(n-1),其中,矩阵p=[p1,p2,…,pd]∈rm×d。(8)确定监测指标t2与q的控制上限,记为与qc,保留模型参数集以备在线故障检测时调用。(9)采集新时刻的数据样本x,对其进行与训练数据x相同的标准化处理,得到新数据样本向量(10)按照如下所示公式分别计算监测指标t2与q的具体数值:上式(3)中,矩阵符号||||表示计算向量的长度。(11)将t2与q的具体数值与控制上限与qc对比,若有任何一个数值超限,则当前采样数据为故障样本,否则,采集下一时刻的新数据,继续实施在线故障检测。与传统方法相比,本发明方法的优势在于:本发明方法在离线建模阶段同时将训练数据的角度相关性与距离相关性考虑进来,较全面地挖掘了数据相关性特征。因此,本发明方法所建立的改进型pca模型能更全面的描述正常数据的潜在特征,理应取得更好的故障检测效果。此外,虽然本发明方法改进的是传统基于pca的故障检测模型,但相应的改进思想其实是可以应用于其他基于pca各种衍生形式(如动态性,非线性等)的故障检测模型。附图说明图1为本发明方法的实施流程图。图2为计算距离相关性矩阵的实施流程图。图3为故障检测效果的对比图。具体实施方式下面结合附图对本发明方法进行详细的说明。如图1所示,本发明方法公开一种基于改进型主元分析模型的故障检测方法,具体的实施步骤如下所示:步骤1:采集生产过程正常运行状态下的数据样本,组成训练数据集x∈rn×m,并对每个变量进行标准化处理,得到均值为0,标准差为1的新数据矩阵其中,n为训练样本数,m为过程测量变量数,r为实数集,rn×m表示n×m维的实数矩阵,为第i个测量变量标准化后的数据,i=1,2,…,m为第i个测量变量的下标号。步骤2:按照公式计算训练数据的角度相关性矩阵s1∈rm×m,上标号t表示矩阵或向量的转置。步骤3:计算训练数据的距离相关性矩阵s2∈rm×m,相应的实施流程如图2所示,详细的操作过程如下所示:①针对训练数据中任意的两个列向量与计算对应的n×n维的距离矩阵a与b,距离矩阵中各元素的计算方法如下所示:上两式中,符号||||表示计算向量的长度,下标号k=1,2,…,n,l=1,2,…,n,ak,l与bk,l分别表示矩阵a与b中第k行、第l列的元素,表示向量中的第k个元素;②计算矩阵a中所有n个行向量的平均值记为行向量a1,所有n个列向量的平均值记为列向量a2;③计算矩阵b中所有n个行向量的平均值记为行向量b1,所有n个列向量的平均值记为列向量b2;④按照如下所示公式分别对矩阵a与b中各个元素进行中心化处理,对应得到中心化后的距离矩阵与上式中,a表示矩阵a中所有元素的平均值,b表示矩阵b中所有元素的平均值,与分别表示矩阵与中第k、第l列的元素,b1,k为向量b1中的第k个元素,a2,l为向量a2中的第l个元素;⑤根据如下所示公式计算向量与之间的距离协方差cij:⑥根据如下所示公式分别计算向量与各自的距离方差vi与vj:⑦根据如下所示公式计算向量与之间的距离相关系数sij:该距离相关系数sij就是距离相关性矩阵s2中第i行、第j列的元素;⑧重复①~⑦得到距离相关性矩阵s2中所有元素。步骤4:按照公式s=s1+s2计算得到新相关性矩阵s∈rm×m。步骤5:对矩阵s求取非零特征值及其对应的特征向量,并将特征值按大小降序排列(即:λ1≥λ2≥…≥λm),对应的特征向量为p1,p2,…,pm,其中,m为非零特征值的个数。步骤6:根据如下所示公式确定改进型pca模型中需要保留的主元个数d:其中,d为满足如公式(12)所示条件的最小数值。步骤7:计算得分矩阵并计算得分矩阵对应的协方差矩阵c=yty/(n-1),其中,矩阵p=[p1,p2,…,pd]∈rm×d。步骤8:按照如下所示公式确定监测指标t2与q的控制上限与qc:其中,fd,n-d,β表示置信度为β、自由度分别为d与n-d的f分布所对应的值,表示自由度为h、置信度为β为卡方分布所对应的值,μ和v分别为训练数据对应的q统计量的估计均值和估计方差,然后保留模型参数集以备在线故障检测时调用。步骤9:采集新时刻的数据样本x,对其进行与训练数据x相同的标准化处理,得到新数据样本向量步骤10:按照如下所示公式分别计算监测指标t2与q的具体数值:上式(16)中,矩阵符号||||表示计算向量的长度。步骤11:将t2与q的具体数值与控制上限与qc对比,若有任何一个数值超限,则当前采样数据为故障样本,否则,采集下一时刻的新数据,继续实施在线故障检测。下面结合一个具体的工业过程的例子来说明本发明相对于现有方法的优越性与可靠性。该过程数据来自于美国田纳西-伊斯曼(te)化工过程实验,原型是伊斯曼化工生产车间的一个实际工艺流程。目前,te过程因其流程的复杂性,已作为一个标准实验平台被广泛用于故障检测研究。整个te过程包括22个测量变量、12个操作变量、和19个成分测量变量。所采集的数据分为22组,其中包括1组正常工况下的数据集与21组故障数据。而在这些故障数据中,有16个是已知故障类型,如冷却水入口温度或进料成分的变化、阀门粘滞、反应动力学漂移等,还有5个故障类型是未知的。为了对该过程进行监测,选取如表1所示的33个过程变量,接下来结合该te过程对本发明具体实施步骤进行详细的阐述。表1:te过程监测变量。序号变量描述序号变量描述序号变量描述1物料a流量12分离器液位23d进料阀门位置2物料d流量13分离器压力24e进料阀门位置3物料e流量14分离器塔底流量25a进料阀门位置4总进料流量15汽提塔等级26a和c进料阀门位置5循环流量16汽提塔压力27压缩机循环阀门位置6反应器进料17汽提塔底部流量28排空阀门位置7反应器压力18汽提塔温度29分离器液相阀门位置8反应器等级19汽提塔上部蒸汽30汽提塔液相阀门位置9反应器温度20压缩机功率31汽提塔蒸汽阀门位置10排空速率21反应器冷却水出口温度32反应器冷凝水流量11分离器温度22分离器冷却水出口温度33冷凝器冷却水流量(1).采集te过程对象正常工况下的过程数据,并选取960个正常数据组成矩阵x∈r960×33,对其进行标准化处理得到(2)按照公式计算训练数据的角度相关性矩阵s1∈r33×33,上标号t表示矩阵或向量的转置。(3)计算训练数据的距离相关性矩阵s2∈r33×33。(4)按照公式s=s1+s2计算得到新相关性矩阵s∈r33×33。(5)对矩阵s求取非零特征值及其对应的特征向量,并将特征值按数值大小降序排列(即:λ1≥λ2≥…≥λm),对应的特征向量为p1,p2,…,pm,其中,非零特征值的个数m=33。(6)确定改进型pca模型中需要保留的主元个数d=16:(7)计算得分矩阵并计算得分矩阵对应的协方差矩阵c=yty/(n-1),其中,矩阵p=[p1,p2,…,pd]∈r33×16。(8)确定监测指标t2与q的控制上限,记为与qc,保留模型参数集以备在线故障检测时调用。为测试本发明方法的在故障检测上的优越性,以监测te过程物料进口温度发生随机变化这种故障为例,对比本发明方法与传统基于pca方法的故障检测效果。(9).采集新的数据样本,并对其进行标准化处理得到(10).计算监测指标t2与q的具体数值,实施在线故障检测。由于在故障条件下的测试数据样本数为960个,且前160个数据样本为正常工况下的采样数据,从161个采样时刻起一直持续到底960个样本,te过程物料的进口温度发生随机跳变。相应的故障检测结果显示在图3中,可以很明显的发现,本发明方法的故障漏报率明显低于传统基于pca的故障检测方法。因为从161个样本起,监测指标t2的数值绝大多数大于相应的控制上限相比之下,传统基于pca的故障检测方法的两个监测指标数值大部分小于相应的控制限,错误的将故障工况下的采样数据判别为正常数据。上述实施案例只用来解释说明本发明的具体实施过程,而不是对本发明进行限制。在本发明的精神和权利要求的保护范围内,对本发明做出的任何修改,都落入本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1