基于认知信息粒子的半监督主动识别方法与流程
本发明属于认知知识在深度学习领域应用于半监督主动识别的一种实现,具体涉及一种基于认知信息粒子的半监督主动识别方法。
背景技术:
深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本等;深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
传统的深度学习是一种单向开环过程,不能满足人类的学习方式,如反复的权衡和比较来达到从粗糙到精细,从复杂到简单识别新的对象。如果深度学习模型用更多的数据训练,是可以表现出像人类学习一样的特性;但是,在大多数实际应用中,特别是工业或医疗领域,待识别目标通常是复杂或非均匀分布的,目标模式改变也很大,一次性收集大量的标记样本也很困难,而深度学习则需要大量的训练样本来对模型进行训练才能达到理想的识别效果。
目前主动学习主要基于对待识别样本的不确定信息的大小来选择样本进行标记,然后利用标记样本对模型进行训练,该类技术没有充分考虑模型的认知知识和认知行为,也不适用于深度学习的实际应用;半监督分类是解决深度学习在实际中应用的最佳解决方法,主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题,这样如何选择最有效的样本作为训练数据来提高深度模型的性能以适应新的应用变化是深度机器学习过程中的核心问题,由于这项工作非常具有挑战性,目前尚未有相关的文献公开基于深度模型的高维数据主动识别或分类的问题。
技术实现要素:
本发明所要解决的技术问题在于针对现有技术存在的上述缺陷,提供一种基于认知信息粒子(cips)的半监督主动识别方法,综合考虑模型的随机预测输出和专家的指导来选择有效样本来训练深度学习模型,可以有效避免其他样本对模型认知属性的干扰并能选择最有效的样本训练深度模型。
本发明是采用以下的技术方案实现的:基于认知信息粒子的半监督主动识别方法,包括以下步骤:
步骤s1、输入原始图像,训练初始深度模型:
步骤s11、使用训练数据集训练初始深度模型,所述训练数据集为样本较少的小数据集,模型可在工作过程中形成确定识别结果和不确定样本集;
步骤s12、根据深度模型的自信心指数判断对识别结果是否确信,若是,则输出确定识别结果;否则,对于不确定样本集执行步骤s13;
步骤s13、深度模型请求专家分析数据和模型的不确定性并给出不确定样本的指导信息,将添加指导信息的样本添加到专家指导样本集;
步骤s2、选择有效的训练样本:对专家指导样本集中的不确定样本计算深度模型的认知误差信息,并综合考虑各认知误差信息计算样本的认知信息粒子(cognitiveinformationparcels,简称cips)信息,选择目标敏感样本(target-sensitivesamples,简称tsss),所述目标敏感样本是根据模型的当前状态拥有对识别或分类贡献最大的样本;结合深度模型的状态和专家指导样本集的大小确定欲选择的目标敏感样本的数量;
步骤s3、将目标敏感样本(tsss)添加到训练数据集以微调深度模型,该过程循环执行,逐步提高模型的识别精确度,以使深度模型逐步适应复杂目标和环境变化所造成的模式变化。
进一步的,所述步骤s2中,计算样本的认知信息粒子(cips)信息的具体包括以下步骤:
步骤s21、计算预测认知误差xpe:针对专家给出的指导信息和分类类别标签信息和模型在该类上的预测结果计算深度模型的预测认知误差:
步骤s22、计算预测认知误差变化信息hvp:让深度模型对专家指导样本集中的该样本进行多次随机预测,得到模型针对该类的多个不同预测结果,计算出多个预测认知误差及其在不同次预测的变化率,并利用信息熵来表达该变化信息的大小:
步骤s23、计算不同类别间预测认知误差变化信息hvc:让深度模型对专家指导样本集中的样本进行预测时可以得到模型对多个类别的预测误差,进行多次随机预测,得到针对不同类别的多个不同预测结果,计算其针对不同类别不同预测的认知误差,并计算其相应信息熵的均值来表征模型针对该样本在不同类别间的认知误差信息;该信息体现了模型在不同类别间飘忽不定的不自信程度;
步骤s24、计算样本的认知信息粒子(cips)βx:将专家对该样本的重要性指导作为约束参数,综合考虑上述计算的预测认知误差xpe,预测认知误差变化信息hvp,不同类别间预测认知误差变化信息hvc,得到最终的样本认知信息粒子
进一步的,所述步骤s22中,深度模型对专家指导样本集中的样本进行多次随机预测采用随机正则化技术(srt),从而得到多次随机输出,在深度模型每层后采用丢弃法(dropout)来获得模型的预测输出概率p(y|x)。
进一步的,所述步骤s23中,针对不同类别间预测认知误差变化信息hvc,使用平均信息熵的方法来获得:
进一步的,所述步骤s2中,选择目标敏感样本通过计算每个样本的认知信息粒子(cips)获得认知特征域cm,其通过计算认知信息误差和认知知识体现了样本的分类能力的贡献,该特征可以有效减少来自其他冗余样本的干扰,从而可以有效选择出更有效的样本来作为训练样本来微调模型。
进一步的,考虑到不确定性样本集的大小和实际应用情况,选择认知信息粒子(cips)值较大的样本作为目标敏感样本(tsss)。
进一步的,所述步骤s1中,训练初始深度模型时,采用丢弃法(dropout)进行训练,dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃,对于一个有n个节点的神经网络,有了dropout后,就可以看做是2n个模型的集合,但此时要训练的参数数目却是不变的,这就解决了费时的问题,可有效避免过拟合。
与现有技术相比,本发明的优点和积极效果在于:
本发明根据人类学习新知识这一认知过程的启发,通过综合考虑模型的认知误差和不确定性信息,提出一种半监督主动识别方法,通过提出新的训练样本选择方法,即认知信息粒子(cips),综合考虑模型的认知预测误差和专家的指导信息来选择有效样本来逐步训练深度学习模型提高识别精度,从而使其逐步适应复杂目标和环境变化所造成的模式变化;并且定义了一种新的认知信息的变换方式,从而获得不确定样本的相应特征用来表征模型的认知错误信息以及与之对应的认知知识的表达形式,可以有效避免其他冗余样本对模型认知属性的干扰并能有助于选择最有效的样本用来逐步训练深度模型,有效提高深度模型的识别精度及识别效率,以适应新的应用变化,该发明将认知知识和深度学习网络相结合具有深刻的意义。
附图说明
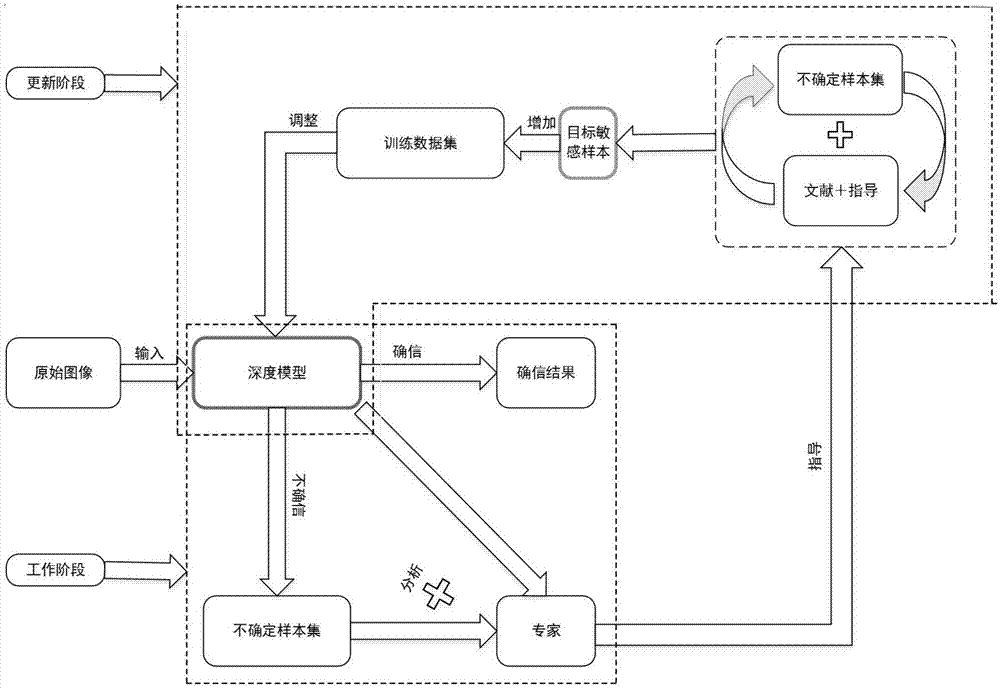
图1是本发明实施例所述半监督主动识别原理图;
图2是本发明实施例使用小数据集训练初始深度模型的流程图;
图3为本发明实施例目标敏感样本选择过程示意图;
图4为本发明实施例在mnist数据库下四种方法的精确度实验结果对比图;
图5为本发明实施例在cifar-10数据库下四种方法的精确度实验结果对比图;
图6为本发明实施例在cifar-100数据库下四种方法的精确度实验结果对比图;
图7为本发明实施例在mnist数据库下四种方法的损失比较实验结果图;
图8为本发明实施例在cifar-10数据库下四种方法的损失比较实验结果图;
图9为本发明实施例在cifar-100数据库下四种方法的损失比较实验结果图。
具体实施方式
为了能够更加清楚地理解本发明的上述目的、特征和优点,下面结合附图及实施例对本发明做进一步说明。
本实施例中,以在实际应用领域使用dnn模型的主动识别方法为例进行介绍,训练智能深度模型,该模型使用少量样本逐步训练智能识别系统来识别或检查工作领域中的对象,例如医疗系统中的病态症状识别或工业现场中的产品缺陷检查;由于对象是复杂的而且工作环境频繁变化,所以样本是非均匀分布的,模式多变的。模型的确信或不确定性是重要的。也就是说,模型可以给出最终认可的确信结果,否则,对于不确信的样本,现场质量控制人员也就是专家将给出相关指导并帮助模型给出最终结果。在模型更新期间(即工作间隙或指定时间),模型可以根据质量控制人员的指导信息来计算关于不确定样本的认知误差,并选择最有效的样本作为训练数据来微调自身。
图1为本实施例所述半监督主动识别原理图,通过训练智能深度模型,使用少量目标敏感样本来逐步提高深度模型的性能来对目标进行识别,图中文献+指导是指对不确定样本的指导信息的文档和类别分类指导,用于计算模型的认知错误信息,以帮助深度模型有效提高识别精度及识别效率。
具体的,基于认知信息粒子的半监督主动识别方法,具体实现过程如下:
1、输入原始图像,使用小数据集训练初始深度模型,在训练过程中采用丢弃法(dropout)避免过拟合,在工作过程中,对深度模型计算自信心指数从而确定模型对样本的确信度(这里的自信心指数就是模型的uncertainty,相关文献可以参阅yaringal.2016.uncertaintyindeeplearning.ph.d.dissertation.universityofcambridge.)对确定样本,模型可以产生确定的分类结果;否则,模型将要求专家帮助分析不确定性样本,专家给出不确定性样本的指导信息,将添加指导信息的样本添加到专家指导样本集(所述专家是指本领域技术专家或现场的工作人员,当智能模型不能给出确定结果时,现场专家就对样本进行分析,并给出相应的指导信息);具体流程图如图2所示。
2、在模型更新升级阶段,对专家指导样本集中的样本计算模型的认知误差信息,并综合考虑各认知误差计算样本的认知信息粒子(cips)信息,选择cips值较大的样本作为目标敏感样本(tsss),结合模型的状态和样本集的大小确定欲选择的敏感样本的数量,进而选择有效的训练样本。
下面给出认知信息粒子(cips)的相关计算描述,在进行新目标学习过程中,人类针对新目标的不确定性主要反映在三个方面:预测误差,不同次预测时预测误差的变化,以及预测在不同类别之间的变化;受此启发,为了有效地将认知知识和深度主动学习模型相结合,综合考虑以上人类所体现的不确定性认知信息,提出此方法:
(1)计算预测认知误差:针对专家的分类结果和模型在该类上的预测结果,计算深度模型的预测认知误差,该误差反映了模型对该类别的不确定程度;对于具有三个或更多类别标签的问题,预测认知误差可以表示为:
(2)计算预测认知误差变化信息:让深度模型对该样本进行多次随机预测,得到模型针对该类的多个不同预测结果,计算出多个预测认知误差及其在不同次预测的变化率,并利用信息熵来表达该变化率的大小,该信息体现了模型对该类别的不自信程度;
不同次预测后预测误差的变化可以表示为,
(3)不同类别间预测认知误差变化信息:让深度模型对该样本进行预测时可以得到模型对多个类别的预测误差,进行多次随机预测,得到针对不同类别的多个不同预测结果,计算其针对不同类别不同预测的认知误差,并计算其相应信息熵的均值来表征模型针对该样本在不同类别间的认知误差信息.该信息体现了模型在不同类别间飘忽不定不自信程度;
针对预测在不同类别之间的变化信息,也通过使用平均信息熵的方法来获得,
(4)样本的认知信息粒子(cips):将专家对该样本的重要性指导作为约束参数,综合考虑(1)、(2)、(3)中计算的预测认知误差xpe,预测认知误差变化信息hvp,不同类别间预测认知误差变化信息hvc,得到最终的样本认知信息粒子
参考图3,在本实施例中,考虑到不确定性样本集的大小和实际应用情况,可以选择前m个最大cips的样本{β1,β2,...,βm}来作为目标敏感样本,并将它们添加到训练数据集中来微调模型,得到认知信息粒子βm后,通过计算每个样本的认知信息粒子(cips)获得认知特征域cm,选择目标敏感样本,其通过计算认知信息误差和认知知识体现了样本的分类能力的贡献,该特征可以有效减少来自其他冗余样本的干扰,从而可以有效选择出更有效的样本来作为训练样本来微调模型。
3、将目标敏感样本(tsss)添加到训练数据集以微调深度模型,该过程循环执行,逐步提高模型的识别精确度,通过逐步地微调dnn深度模型,最终给出样本识别确定结果。
本实施例结合mnist、cifar-10、cifar-100三个数据库,对贝叶斯分歧主动学习、认知信息粒子、预测熵、变化率四种方法的测试精度及验证损失进行比较;如图4-图6所示,三个数据库的四种不同方法的测试精度比较,结果表明,认知信息粒子(cips)方法在准确性,稳定性和达到稳定所需的迭代次数等方面均优于其他方法,随着待识别目标对象复杂性的增加,即从数据库mnist到cifar-10,然后到cifar-100,结果精度有所降低,但随着学习时间的提高,表现有所改善,也明显优于其他方法。图7-图9为不同的方法验证损失比较,结果表明,cips的收敛性比三个数据库上的其他方法都好,针对复杂的数据,如cifar-10和cifar-100,则需要更多次数的训练循环才可收敛,损失值也会变大。由此可见,本发明所提出的方法可以有效提高深度模型的识别精度、降低损失值,将认知知识和深度学习网络相结合具有深刻的意义。
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可以利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例应用于其它领域,但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!