执行GROESTL散列的指令的制作方法
本申请是国际申请号为pct/us2011/066775,国际申请日为2011/12/22,进入国家阶段的申请号为201180076443.3,题为“执行groestl散列的指令”的发明专利申请的分案申请。
发明领域
本公开涉及加密算法,尤其涉及groestl安全散列算法。
背景技术:
密码术(cryptology)是一种依赖算法和密钥来保护信息的工具。该算法是复杂的数学算法,而密钥是位串。存在两种基本的密码术系统类型:秘密密钥系统和公开密钥系统。秘密密钥系统(也被称为对称系统)具有两方或更多方共享的单一密钥(“秘密密钥”)。该单一密钥既被用来将信息加密,也被用来将信息解密。
由国家标准和技术委员会(nist)作为联邦信息处理标准(fips)197发布的先进加密标准(aes)是一种秘密密钥系统。aes是能够将信息加密和解密的对称块密码(blockcipher)。groestl算法是一种基于aes的迭代散列函数,其具有从两个固定的大的不同的置换(p和q)构造的压缩函数。
该压缩函数(f)被经由p和q的置换来定义,使得:f(h,m)=p(hxorm)xorq(m)xorh,其中函数p和q是置换函数,而是hi-1是输入状态,mi是消息块输入,而hi是结果状态。加密(密码)使用该秘密密钥(密码密钥)执行一系列变换来将被称为“明文”的可理解数据变换为被称为“密文”的不可理解形式。密码中的变换可包括:(1)使用异或(xor)运算向该状态(二维字节数组)添加轮次常数(从p函数和q函数推出的值);(2)使用非线性字节代换表(s-box)处理该状态;(3)将该状态的最后三行循环移位不同的偏移量;以及(4)取该状态的所有的列并将这些列的数据(彼此独立地)混合以产生新的列。
解密(逆向密码)使用该密码密钥执行一系列变换来将“密文”块变换为相同大小的“明文”块。逆向密码中的变换是该密码中的变换的逆反。
groestl算法用10个或14个连续的轮次将明文变换为密码文本或将密文变换为明文,轮次的数量取决于密钥的长度。
附图简述
结合以下附图,从以下详细描述可获得对本发明更好的理解,其中:
图1是图解系统的一个实施例的框图;
图2是图解处理器的一个实施例的框图;
图3是图解紧缩数据寄存器的一个实施例的框图;
图4a和4b图解了图解由mul_byte_gf2指令和mix_byte_xor指令执行的过程的一个实施例的流程图;
图5是根据本发明的一个实施例的寄存器架构的框图;
图6a是根据本发明的多个实施例的单cpu核,连同其到管芯上互连网络的连接及其本地2级(l2)高速缓存子集,的框图;
图6b是根据本发明的多个实施例的cpu核的一部分的剖视图;
图7是图解根据本发明的多个实施例的示例性无序架构的框图;
图8是根据本发明的一个实施例的系统的框图;
图9是根据本发明的一实施例的第二系统的框图;
图10是根据本发明的一实施例的第三系统的框图;
图11是根据本发明的一实施例的片上系统(soc)的框图;
图12是根据本发明的多个实施例的带有集成存储器控制器和图形元件的单核处理器和多核处理器的框图;以及
图13是对照根据本发明的多个实施例的使用软件指令转换器来将源指令集中的二进制指令转换为目标指令集中的二进制指令的框图。
详细描述
在下面的描述中,出于解释目的阐述了众多具体细节以便提供对本发明的完全理解。然而对于本领域技术人员显然的是,没有这些具体细节中的一些细节也可实践本发明。在其他实例中,公知的结构和设备以框图形式示出以避免湮没本发明的基础概念。
说明书中对“一个实施例”或“一实施例”的引用旨在指示结合该实施例所述的特定特征、结构、或特性被包括在本发明的至少一个实施例中。在说明书各处出现的短语“在一个实施例中”不一定全部指相同实施例。
描述了一种包括用于处理groestl安全散列算法的指令的机制。如同上面讨论的,groestl算法是一种基于在aes标准中指定的rijindael算法的加密散列函数。该aes标准包括提供用于在通用处理器中执行aes加密和解密的指令集扩展的指令集(例如,aes指令集)。
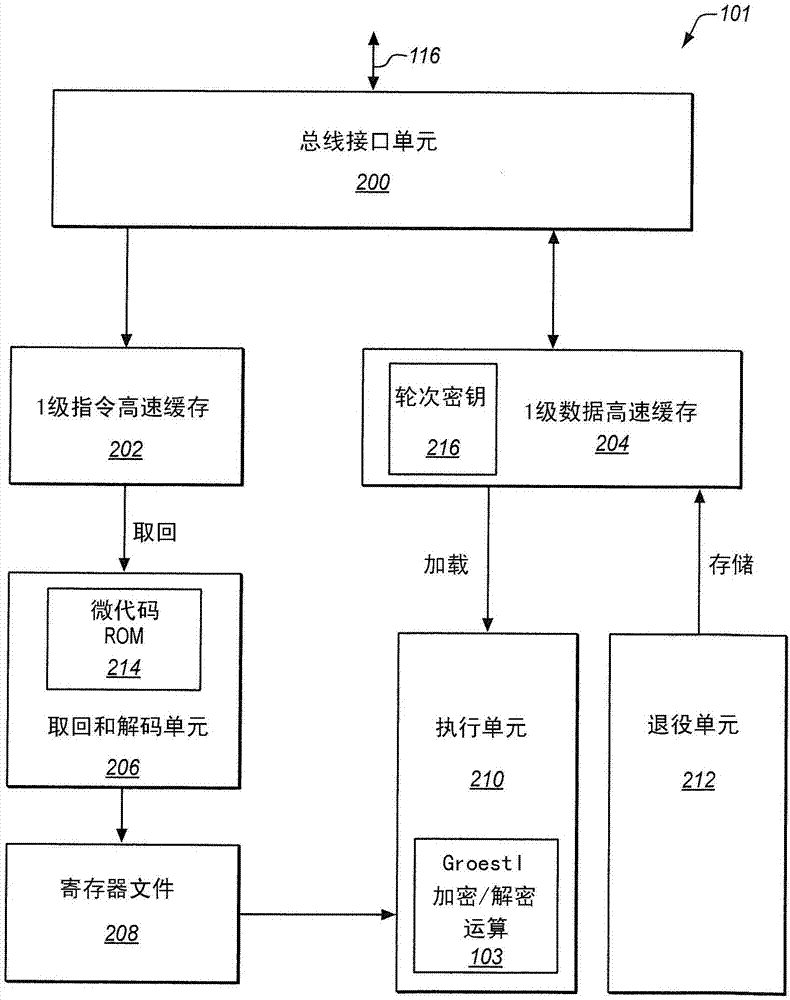
该aes指令集是对x86指令集架构(isa)的扩展,其改善了使用该aes算法的应用的速度。根据一个实施例,该aes指令集扩展被实现以执行groestl算法。图1是系统100的一个实施例的框图,该系统包括用于在通用处理器中执行groestl加密和解密的aes指令集扩展。
系统100包括处理器101、存储器控制器中枢(mch)102、以及输入/输出(i/o)控制器中枢(ich)104。mch102包括控制处理器101和存储器108之间的通信的存储器控制器106。处理器101和mch102通过系统总线116通信。
处理器101可以是多种处理器中的任何一者,所述多种处理器诸如是:单核
存储器108可以是动态随机存取存储器(dram)、静态随机存取存储器(sram)、同步动态随机存取存储器(sdram)、双数据率2(ddr2)ram或rambus动态随机存取存储器(rdram)或任何其他类型的存储器。
ich104可使用高速芯片到芯片互连114(诸如直接媒体接口(dmi))耦合于mch102。dmi支持经由两个单向通道的2千兆比特/秒并发传输速率。
ich104可包括用于控制与耦合至ich104的至少一个存储设备112的通信的存储i/o控制器110。该存储设备可以例如是盘驱动器、数字视频盘(dvd)驱动器、紧致盘(cd)驱动器、独立盘冗余阵列(raid)、磁带驱动器或其他存储设备。ich104可使用诸如串行附接小型计算机系统接口(sas)或串行先进技术附接(sata)之类的串行存储协议通过存储协议互连118与存储设备112通信。
在一个实施例中,处理器101包括用于执行groestl加密和解密运算的groestl函数103。groestl函数103可被用来加密或解密存储器108中存储的和/或存储设备112中存储的信息。
图2是图解了处理器101的一个实施例的框图。处理器101包括用于解码从1级(l1)指令高速缓存202接收的处理器指令的取回和解码单元202。要用于执行该指令的数据可被存储在寄存器文件208中。在一个实施例中,寄存器文件208包括被aes指令用来存储供该aes指令使用的数据的多个寄存器。
图3是寄存器文件208中的紧缩数据寄存器的适当集合的示例实施例的框图。所示紧缩数据寄存器包括32个512位紧缩数据或矢量寄存器。这32个512位寄存器被标记为zmm0到zmm31。在所示实施例中,这些寄存器中的较低的16个寄存器(即zmm0-zmm15)的较低阶的256位被混叠或覆盖在被标记为ymm0-ymm15的相应的256位紧缩数据或矢量寄存器中,然而不要求如此。
类似地,在所示实施例中,ymm0-ymm15的较低阶128位被混叠或覆盖在被标记为xmm0-xmm1的相应的128位紧缩数据或矢量寄存器上,然而也不要求如此。512位寄存器zmm0到zmm31能够操作以保存512位紧缩数据、256位紧缩数据、或128位紧缩数据。
256位寄存器ymm0-ymm15能够操作以保存256位紧缩数据或128位紧缩数据。128位寄存器xmm0-xmm1能够操作以保存128位紧缩数据。这些寄存器中的每个寄存器可被用于存储紧缩浮点数据或紧缩整数数据。支持不同的数据元素大小,包括至少8位字节数据、16位字数据、32位双字或单精度浮点数据、以及64位四字或双精度浮点数据。紧缩数据寄存器的替代实施例可包括不同数量的寄存器、不同大小的寄存器,并且可以或可以不在较小的寄存器上混叠较大的寄存器。
参考图2,取回和解码单元202从l1指令高速缓存202取回宏指令,解码所述宏指令并且将所述宏指令分解为被称为微操作(μops)的简单操作。执行单元210调度并执行所述微操作。在所示实施例中,执行单元210中的groestl函数103包括用于aes指令的微操作。退役单元212将所执行的指令的结果写到寄存器或存储器。
函数103执行压缩函数f(h,m)=p(hxorm)xorq(m)xorh,其中置换p和q是使用多个轮次r来设计的,其包括多个轮次变换。在groestl函数103中,针对每个置换定义全部4个轮次变换。所述变换对被表示为8位字节的矩阵(例如,矩阵a)的状态操作。在一个实施例中,该矩阵具有8行和8列。然而,其他实施例可实现其他变型(例如,8行和16列)。
在一个实施例中,groestl函数103所执行的变换序列包括addroundconstant(ac)变换、subbytes变换、shiftbytes变换和mixbytes变换。
ac变换向状态矩阵a添加轮次相关常数(例如,a←axorc[i],其中c[i]是在轮次i中使用的轮次常数)。p和q具有不同的轮次常数。
subbytes变换用另一值取代该状态矩阵中的每个字节。使用非线性字节取代表(s-box)处理该状态。subbytes是通过将s-box变换应用于该16个字节中的每个字节来定义的16字节到16字节(逐字节)变换。
s-box变换可经由如下的查找表来表示:对查找表的输入是字节b[7:0],其中x和y表示低和高半字节x[3:0]=b[7:4],y[3:0]=b[3:0]。输出字节在该表中被编码为用16(h)进制表示的2数位数。在一个实施例中,aes-ni指令集提供了用于为groestl执行subbytes的精确功能。在这种实施例中,使用aes-ni指令aesenclast来计算subbytes变换。
shiftbytes变换将一行内的字节向左循环移位多个位置。在一个实施例中,shiftbytes实现aes-ni指令pshufb以对xmm寄存器中的字节快速重新排序。
当p和q矩阵是以xmm/ymm寄存器中的行组织的时,ac和shiftbytes操作不是计算密集的,而使用aes-ni指令aesenclast可以同时为高达16个字节计算subbytes操作。从而,aes指令集中的复杂度和循环的大部分是由mixbytes操作带来的。
mixbytes变换将该矩阵中的每一列独立地进行变换。mixbytes实现有限字段f256,其是经由对f2的不可化简多项式x8xorx4xorx3xorxxor1来定义的。状态矩阵a的字节可被看作f256的元素,(例如,作为系数为{0,1}的最高为7次的多项式)。每个字节的最低有效位确定x0的系数等。
mixbytes将矩阵a的每一列乘以f256中的常数8x8矩阵b。从而,整个矩阵a上的变换可被写为矩阵乘法:a←bxa。在一个实施例中,矩阵b是循环行列式(例如,每一行等于将上一行向右轮转一个位置,并被指定为:
从而,b=circ(02;02;03;04;05;03;05;07)。该状态矩阵的每一行被在f256中与循环行列式b矩阵的8个行相乘并累加以每次一行地进行mixbytes变换。此操作花费8个指令(f256中的64个乘法/累加)。针对groestl-224/256实现总共64x8个伽罗瓦域(gf)256乘法/累加(其中乘数为02,03,04,05,07)。
因为groestl状态按行组织,所以每次一行地形成经更新的状态矩阵,使得:
结果行1=a行1*02+a行2*02+a行3*03+a行4*04+a行5*05+a行6*03+a行7*05+a行8*07
结果行2=a行1*07+a行2*02+a行3*02+a行4*03+a行5*04+a行6*05+a行7*03+a行8*05
结果行3=a行1*05+a行2*07+a行3*02+a行4*02+a行5*03+a行6*04+a行7*05+a行8*03
结果行4=a行1*03+a行2*05+a行3*07+a行4*02+a行5*02+a行6*03+a行7*04+a行8*05
结果行5=a行1*05+a行2*03+a行3*05+a行4*07+a行5*02+a行6*02+a行7*03+a行8*04
结果行6=a行1*04+a行2*05+a行3*03+a行4*05+a行5*07+a行6*02+a行7*02+a行8*03
结果行7=a行1*03+a行2*04+a行3*05+a行4*03+a行5*05+a行6*07+a行7*02+a行8*02
结果行8=a行1*02+a行2*03+a行3*04+a行4*05+a行5*03+a行6*05+a行7*07+a行8*02
目前,与02,03,04,05和07的gf乘法通过以下方式实现:将每一行与2的8个gf相乘乘法和经加倍的行乘积与2的8个附加的gf相乘,再次产生每一行4倍的乘积。这导致16个gf乘法。03因子形成为行xor2*行,05因子形成为行xor4*行,而07因子形成为行xor2*行xor4*行。此外,在传统系统中执行的xor操作的总数量从48变为108。
在使用aes指令的传统系统中,与2的gf相乘是通过创建带有用作被乘数字节的16进制ff的字节的寄存器来形成,所述被乘数字节的最高有效位(msb)(例如,=1)使得超过256的每个字节乘积能够加(xor)1b。在这种系统中,pcmpgtb指令被用来创建ff字节掩码寄存器。从而,与2相乘要求4个或5个simd指令。从而,使用当前指令的mixbytes的预期性能是(16*4)+58=122个操作,需要61个周期,每个周期退役2个simd指令。
根据一个实施例,新指令mul_byte_gf2和mix_byte_xor被实现以加速mixbytes变换。在这种实施例中,mul_byte_gf2指令被执行两次以便对状态矩阵执行与2的gf相乘运算。本指令的示例是mul_byte_gf2zmm2,zmm1,其中zmm2=按8字节行的64位段组织的初始8x8矩阵;zmm1=该矩阵的每个元素的2倍;其中mul_byte_gf2zmm2,zmm1zmm2中形成2x原始矩阵,而mul_byte_gf2zmm3,zmm2乘以zmm2中的2x矩阵并且zmm3=zmm1矩阵中的每个元素的4倍。
图4a是图解mul_byte_gf2指令所执行的过程的一个实施例的流程图。在处理框410处,所有8个64位行被存储在zmm1中。在处理框420处,zmm1中所存储的行被乘以2。对于msb=1的每个字节,用1bhex(1b十六位)与该值进行xor以完成gf2乘法。
在处理框430处,gf2结果被存储在zmm2中。在处理框440处,zmm2中存储的乘以2的结果被乘以2以创建乘以4的结果。在处理框450处,乘以4的结果被存储在zmm3中。从而,3个zmm寄存器包括被用作mix_byte_xorzmm1,zmm2,zmm3的源操作数的8x8矩阵、2xgf2中的每个字节以及4xgf2中的每个字节,其中zmm1是mixbyte操作的结果的目的地寄存器。
mix_byte_xor的数据路径包括到达用xor函数来组合状态矩阵的1、2和4因子的路由。图4b图解mix_byte_xor所执行的流程的一个实施例。mix_byte_xor使用由mul_byte_gf2生成的x1、x2和x4因子为该状态矩阵的每64(或128)个元素执行所有的xor运算并分别存储在寄存器zmm1、zmm2和zmm3中。如图4b中所示,通过从结果寄存器中取乘法因子并执行xor运算来得到结果行。
在一个实施例中,将x1、x2和x4因子相加以得到其他因子。例如,结果行1中的因子3是通过将来自相应寄存器的x1因子和x2因子相加获得的。类似地,因子7是通过将x1、x2和x4因子相加获得的。在一个实施例中,结果行被存储在zmm1中。然而,在其他实施例中,结果行可被存储在zmm2或zmm3之一中。
mul_byte_gf2和mix_byte_xor指令被实现在3周期流水线中,允许在10个周期中计算出p和q矩阵。对于两个p和q8x8groestl状态矩阵的mixbytes计算,mul_byte_gf2和mix_byte_xor指令所得到的性能改进是从60个周期减少到10个周期。
在又一个实施例中,groestl-1024使用相同的指令来对p1024和q1024状态矩阵执行mixbytes操作,对于该矩阵的左8x8侧使用2个mul_byte_gf2指令,且对于该矩阵的右8x8侧使用2个mul_byte_gf2指令。随后使用mix_byte_xor指令来确定8x16矩阵的每一半。
示例性寄存器架构-图5
图5是图解根据本发明的一个实施例的寄存器架构的框图。该架构的寄存器文件和寄存器被列在下面:
矢量寄存器文件510——在所示实施例中,存在32个512位宽的矢量寄存器,这些寄存器被作为zmm0到zmm31引用。较低的16个zmm寄存器的较低阶856位被覆盖在寄存器ymm0-16上。较低的16个zmm寄存器的较低阶128位(ymm寄存器的较低阶128位)被覆盖在寄存器xmm0-15上。
写掩码寄存器515-在所示实施例中,存在8个写掩码寄存器(k0到k7),每个写掩码寄存器的大小为64位。如前所述,在本发明的一个实施例中,矢量掩码寄存器k0不能用作写掩码;当正常情况下指示k0的编码被用于写掩码时,它选择0xffff的硬连线的写掩码,从而有效地针对该指令禁用写掩码。
多媒体扩展控制状态寄存器(mxcsr)1020——在所示实施例中,此32位寄存器提供在浮点运算中使用的状态和控制位。
通用寄存器525-在所示实施例中,存在16个64位通用寄存器,它们与现有的x86寻址模式一起被用来对存储器操作数寻址。这些寄存器用名称来rax,rbx,rcx,rdx,rbp,rsi,rdi,rsp和r8到r15指代。
扩展标志(eflags)寄存器530-在所示实施例中,此32位寄存器被用来记录许多指令的结果。
浮点控制字(fcw)寄存器535和浮点状态字(fsw)寄存器540-在所示实施例中,这些寄存器被x87指令集扩展用来在fcw的情况下设置取整模式、异常掩码和标志,而在fsw的情况下跟踪异常。
标量浮点栈寄存器文件(x87栈)545(其上混叠了mmx紧缩整数平坦寄存器文件1050)-在所示实施例中,x87栈是用来使用x87指令集扩展对32/64/80位浮点数据执行标量浮点运算的8元素栈;而mmx寄存器被用来对64位紧缩整数数据执行运算,以及为在mmx和xmm寄存器之间执行的一些运算保存操作数。
段寄存器555-在所示实施例中,存在用来存储用于分段地址生成的数据的6个16位寄存器。
rip寄存器565-在所示实施例中,此64位寄存器存储指令指针。
本发明的替代实施例可使用更宽或更窄的寄存器。此外,本发明的替代实施例可使用更多的、更少的或不同的寄存器文件和寄存器。
示例性有序(in-order)处理器架构——图6a-6b
图6a-b图解示例性有序处理器架构的框图。这些示例性实施例是围绕用宽矢量处理器(vpu)扩充的有序cpu核的多个实例设计的。取决于应用,核通过高带宽互连网络与某些固定功能逻辑、存储器i/o接口以及其他必要的i/o逻辑通信。例如,此实施例作为独立gpu的一实现通常包括pcie总线。
图6a是根据本发明的多个实施例的单cpu核,连同到管芯上互连网络602的连接及其本地2级(l2)高速缓存子集1104,的框图。指令解码器600支持具有扩展的x86指令集。尽管在本发明的一个实施例中(为了简化设计)标量单元608和矢量单元610使用独立的寄存器集合(分别使用标量寄存器612和矢量寄存器614),并且在其间传输的数据被写到存储器并随后从1级(l1)高速缓存606读回,然而本发明的多个替代实施例可使用不同的方法(例如,使用单一寄存器集合或者包括允许数据在不被写入并读回的情况下在这两个寄存器文件之间传输的通信路径)。
l1高速缓存606允许低等待时间访问以将存储器高速缓存到标量和矢量单元中。与此矢量友好指令格式的load-op(加载运算)指令一起,这意味着l1高速缓存606能够在某种程度上像扩展寄存器文件一样被对待。这显著提高了许多算法的性能。
l2高速缓存604的本地子集是被划分成单独的本地子集(每个cpu核一个本地子集)的全局l2高速缓存的一部分。每个cpu具有对该l2高速缓存604的其自己的本地子集的直接访问路径。cpu核所读取的数据被存储在其l2高速缓存子集604中并能与其他cpu访问其自己的本地l2高速缓存子集并行地被快速访问。cpu核所写入的数据被存储在其自己的l2高速缓存子集604中并在必要时从其他子集清空。环形网络确保了共享数据的一贯性。
图6b是根据本发明的多个实施例的图6a中的cpu核的一部分的剖视图。图6b包括l1数据高速缓存606a,l1高速缓存604的一部分,以及关于矢量单元610和矢量寄存器1114的更多细节。具体而言,矢量单元610是16-宽矢量处理单元(vpu)(参见16宽alu1128),该vpu执行整数、单精度浮点数以及双精度浮点数指令。该vpu支持通过拌和单元620拌和寄存器输入、通过数值转换单元622a-b进行数值转换,以及通过复制单元624进行对存储器输入的复制。写掩码寄存器626允许断言所得的矢量写入。
可以各种方式搅和寄存器数据,如,来支持矩阵乘法。可将来自存储器的数据跨vpu通道被复制。这是图形和非图形并行数据处理中的通用操作,这显著增加了高速缓存效率。
环形网络是双向的,以允许诸如cpu核、l2高速缓存和其它逻辑块之类的代理在芯片内彼此通信。每个环形数据路径每个方向为1012位宽。
示例性无序架构—图7
图7是图解根据本发明的多个实施例的示例性无序架构的框图。具体而言,图7示出公知的示例性无序架构,已经被修改为结合了矢量友好指令格式以及其实行。在图7中,箭头指示两个或更多个单元之间的耦合,且箭头的方向指示这些单元之间的数据流的方向。图7包括耦合到执行引擎单元705和存储器单元710的前端单元715;执行引擎单元710还耦合到存储器单元715。
前端单元705包括耦合到二级(l2)分支预测单元722的一级(l1)分支预测单元720。l1和l2分支预测单元720和722耦合到l1指令高速缓存单元724。l1指令高速缓存单元724耦合至指令翻译后备缓冲器(tlb)726,该缓冲器726进一步耦合至指令取回和预解码单元728。指令取回和预解码单元728耦合至指令队列单元730,该单元730进一步耦合至解码单元732。解码单元732包括复杂解码器单元734和三个简单解码器单元736、738和740。解码单元732包括微代码rom单元742。在解码级段中,解码单元7可如上所述地操作。l1指令高速缓存单元724还耦合到存储器单元715中的l2高速缓存单元748。指令tlb单元726还耦合到存储器单元715中的二级tlb单元746。解码单元732、微代码rom单元742、和循环流检测器(lsd)单元744各自耦合到执行引擎单元710中的重命名/分配器单元756。
执行引擎单元710包括耦合到退役单元774和统一调度器单元758的重命名/分配器单元756。退役单元774还耦合到执行单元760且包括重排序器缓冲器单元778。统一调度器单元758还耦合到物理寄存器文件单元776,物理寄存器文件单元776耦合到执行单元760。物理寄存器文件单元776包括矢量寄存器单元777a、写掩码寄存器单元777b、和标量寄存器单元777c;这些寄存器单元可提供矢量寄存器510、矢量掩码寄存器515、以及通用目的寄存器525;且物理寄存器文件单元776可包括未示出的附加寄存器文件(如,混叠在mmx紧缩整数平坦寄存器文件550上的标量浮点栈寄存器文件545)。执行单元1260包括三个混合标量和矢量单元762、764和772;负载单元766;存储地址单元768;存储数据单元770。负载单元766、存储地址单元768和存储数据单元770各自进一步耦合到存储器单元715中的tlb单元752。
存储器单元715包括耦合到数据tlb单元752的二级tlb单元746。数据tlb单元752耦合到l1数据高速缓存单元754。l1数据高速缓存单元754还耦合到l2高速缓存单元748。在一些实施例中,l2高速缓存单元748还耦合到存储器单元715内部和/或外部的l3和更高级高速缓存单元750。
以示例的方式,示例性无序体系结构可如下实现过程流水线:1)指令取回和预解码单元728执行取回和长度解码级;2)解码单元732执行解码级;3)重命名/分配器单元756执行分配级和重命名级;4)统一调度器758执行调度级;5)物理寄存器组单元776、重排序缓冲器单元778、和存储器单元715执行寄存器读取/存储器读取;执行单元760执行(perform)执行(execute)/数据变换级;6)存储器单元715和重排序缓冲器单元778执行写回/存储器写入级1960;7)退役单元774执行rob读取级;8)各单元可牵涉到异常处理级;以及9)退役单元1274和物理寄存器组单元776执行提交级。
示例性计算机系统和处理器-图8-10
图8-10示出适于包括处理器101的示例性系统。本领域已知的对膝上型设备、台式机、手持pc、个人数字助理、工程工作站、服务器、网络设备、网络中枢、交换机、嵌入式处理器、数字信号处理器(dsp)、图形设备、视频游戏设备、机顶盒、微控制器、蜂窝电话、便携式媒体播放器、手持设备以及各种其他电子设备的其他系统设计和配置也是合适的。一般来说,能够含有本文中所公开的处理器和/或其它执行逻辑的大量系统和电子设备一般都是合适的。
现在参考图8,所示出的是根据本发明的一个实施例的系统800的框图。系统800可包括耦合至图形存储器控制器中枢(gmch)810的一个或多个处理器815、820。附加处理器815的可选性质用虚线表示在图8中。
每一处理器810、815可以是处理器1700的某种版本。然而,应该注意,集成图形逻辑和集成存储器控制单元未必存在于处理器810和815中。
图8示出gmch820可耦合至存储器840,该存储器840可以是例如动态随机存取存储器(dram)。对于至少一个实施例,dram可以与非易失性缓存相关联。
gmch820可以是芯片组或芯片组的一部分。gmch820可以与(各)处理器810、815进行通信,并控制处理器810、815与存储器840之间的交互。gmch820还可充当(各)处理器810、815和系统800的其它元件之间的加速总线接口。对于至少一个实施例,gmch820经由诸如前端总线(fsb)895之类的多站总线与(诸)处理器810、815进行通信。
此外,gmch820耦合至显示器845(诸如平板显示器)。gmch820可包括集成图形加速器。gmch820还耦合至输入/输出(i/o)控制器中枢(ich)850,该输入/输出(i/o)控制器中枢(ich)850可用于将各种外围设备耦合至系统800。在图8的实施例中作为示例示出了外部图形设备860以及另一外围设备870,该外部图形设备860可以是耦合至ich850的分立图形设备。
可选地,系统800中还可存在附加或不同的处理器。例如,附加处理器(多个)815可包括与处理器810相同的附加处理器(多个)、与处理器810异类或不对称的附加处理器(多个)、加速器(诸如图形加速器或数字信号处理(dsp)单元)、现场可编程门阵列或任何其它处理器。按照包括体系结构、微体系结构、热、功耗特征等等优点的度量谱,(多个)物理资源810、815之间存在各种差别。这些差别会有效显示为处理元件810、815之间的不对称性和异类性。对于至少一个实施例,各种处理元件810、815可驻留在同一管芯封装中。
现在参照图9,所示出的是根据本发明一实施例的第二系统900的框图。如图9所示,多处理器系统900是点对点互连系统,且包括经由点对点互连950耦合的第一处理器970和第二处理器980。如图9所示,处理器970和980中的每个可以是处理器101的某一版本。
可选地,处理器970、980中的一个或多个可以是除处理器之外的元件,诸如加速器或现场可编程门阵列。
虽然仅以两个处理器970、980来示出,但应理解本发明的范围不限于此。在其它实施例中,在给定处理器中可存在一个或多个附加处理元件。
处理器970还可包括集成存储器控制器中枢(imc)972和点对点(p-p)接口976和978。类似地,第二处理器980包括imc982和p-p接口986和988。处理器970、980可以经由使用点对点(ptp)接口电路978、988的点对点(ptp)接口950来交换数据。如图9所示,imc972和982将处理器耦合到相应的存储器,即存储器942和存储器944,这些存储器可以是本地附连到相应处理器的主存储器部分。
处理器970、980可各自经由使用点对点接口电路976、994、986、998的各个p-p接口952、954与芯片组990交换数据。芯片组990还可经由高性能图形接口939与高性能图形电路938交换数据。
共享高速缓存(未示出)可以被包括在任一处理器之内或被包括两个处理器外部但仍经由p-p互连与这些处理器连接,从而如果将某处理器置于低功率模式时,可将任一处理器或两个处理器的本地高速缓存信息存储在该共享高速缓存中。芯片组990可经由接口996耦合至第一总线916。在一个实施例中,第一总线916可以是外围部件互连(pci)总线,或诸如pciexpress总线或其它第三代i/o互连总线之类的总线,但本发明的范围并不受此限制。
如图9所示,各种i/o设备99可连同总线桥918一起耦合到第一总线916,总线桥918将第一总线916耦合到第二总线920。在一个实施例中,第二总线920可以是低引脚数(lpc)总线。在一个实施例中,各设备可耦合到第二总线920,包括例如键盘和/或鼠标922、通信设备926、以及可包括代码930的诸如盘驱动器或其它海量存储设备的数据存储单元928。进一步地,音频i/o924可以耦合到第二总线920。注意,其它架构是可能的。例如,代替图9的点对点架构,系统可实现多点总线或者其他此类架构。
现在参照图10,所示出的是根据本发明实施例的第三系统1500的框图。图9和10中的类似元件使用类似附图标记,且在图10中省略了图9的某些方面以避免混淆图10的其它方面。
图10示出处理元件970、980可分别包括集成存储器和i/o控制逻辑(“cl”)972和982。对于至少一个实施例,cl972、982可包括存储器控制器中枢逻辑(imc)。此外,cl972、982还可包括i/o控制逻辑。图10示出:不仅存储器942、944耦合至cl972、982,i/o设备914也耦合至控制逻辑972、982。传统i/o设备915被耦合至芯片组990。
现在参考图11,所示为根据本发明的一实施例的soc1100的框图。图12中的类似元件具有相似的附图标记。另外,虚线框是更先进的soc的可选特征。在图11中,互连单元1102耦合至:应用处理器1110,包括一组一个或多个核心1102a-n以及共享高速缓存单元1106;系统代理单元1110;总线控制器单元1111;集成存储器控制器单元1114;一组或一个或多个媒体处理器1120,可包括集成图形逻辑1108、用于提供静态和/或视频照相功能的图像处理器1124、提供硬件音频加速的音频处理器1126、提供视频编码/解码加速的视频处理器1128、静态随机存取存储器(sram)单元1130;直接存储器存取(dma)单元1132;以及显示单元1140,用于耦合至一个或多个外部显示器。
本文公开的机制的各实施例可以被实现在硬件、软件、固件或这些实现方法的组合中。本发明的实施例可实现为在可编程系统上执行的计算机程序或程序代码,该可编程系统包括至少一个处理器、存储系统(包括易失性和非易失性存储器和/或存储元件)、至少一个输入设备以及至少一个输出设备。
可将程序代码应用至输入数据以执行本文描述的功能并产生输出信息。输出信息可以按已知方式被应用于一个或多个输出设备。为了本申请的目的,处理系统包括具有诸如例如数字信号处理器(dsp)、微控制器、专用集成电路(asic)或微处理器之类的处理器的任何系统。
程序代码可以用高级过程语言或面向对象的编程语言来实现,以便与处理系统通信。程序代码也可以在需要的情况下用汇编语言或机器语言来实现。事实上,本文中描述的机制不限于任何特定编程语言的范围。在任一情形下,语言可以是编译语言或解译语言。
至少一个实施例的一个或多个方面可以由存储在机器可读介质上的代表性指令来实现,该指令表示处理器中的各种逻辑,该指令在被机器读取时使得该机器制作用于执行本文所述的技术的逻辑。被称为“ip核”的这些表示可以被存储在有形的机器可读介质上,并被提供给各种客户或生产设施以加载到实际制造该逻辑或处理器的制造机器中。
此类机器可读存储介质可包括但不限于通过机器或设备制造或形成的非易失性的粒子有形排列,包括存储介质,诸如:硬盘;包括软盘、光盘、压缩盘只读存储器(cd-rom)、可重写压缩盘(cd-rw)以及磁光盘的任何其它类型的盘;诸如只读存储器(rom)之类的半导体器件;诸如动态随机存取存储器(dram)、静态随机存取存储器(sram)之类的随机存取存储器(ram);可擦除可编程只读存储器(eprom);闪存;电可擦除可编程只读存储器(eeprom);磁卡或光卡;或适于存储电子指令的任何其它类型的介质。
因此,本发明的各实施例还包括非瞬态、有形机器可读介质,该介质包含矢量友好指令格式的指令或包含设计数据,诸如硬件描述语言(hdl),它定义本文中描述的结构、电路、装置、处理器和/或系统特性。这些实施例也被称为程序产品。
在某些情况下,指令转换器可用来将指令从源指令集转换至目标指令集。例如,指令转换器可以变换(例如使用静态二进制变换、包括动态编译的动态二进制变换)、变形(morph)、仿真或以其它方式将指令转换成将由核来处理的一个或多个其它指令。指令转换器可以用软件、硬件、固件、或其组合实现。指令转换器可以在处理器上、在处理器外、或者部分在处理器上部分在处理器外。
图13是根据本发明的各实施例的对照使用软件指令转换器将源指令集中的二进制指令转换成目标指令集中的二进制指令的框图。在所示的实施例中,指令转换器是软件指令转换器,但作为替代该指令转换器可以用软件、固件、硬件或其各种组合来实现。
图13示出可以使用x86编译器1304来编译高级语言1302的程序,以便生成可以由具有至少一个x86指令集核的处理器1316本地执行的x86二进制代码1306(假设指令中的一些是以矢量友好指令格式编译)。具有至少一个x86指令集核1816的处理器表示任何处理器,该处理器能够通过兼容地执行或以其它方式处理(1)英特尔x86指令集核的指令集的大部分或(2)旨在具有至少一个x86指令集核的英特尔处理器上运行的应用或其它软件的目标代码版本来执行与具有至少一个x86指令集核的英特尔处理器基本相同的功能,以实现与具有至少一个x86指令集核的英特尔处理器基本相同的结果。x86编译器1804表示用于生成x86二进制代码1306(例如,目标代码)的编译器,该二进制代码1306可通过或不通过附加的链接处理在具有至少一个x86指令集核的处理器1316上执行。类似地,图90示出高级语言1302的程序可使用替换指令集编译器1308来编译以生成替换指令集二级制代码1310,替换指令集二级制代码1310可由不具有至少一个x86指令集核的处理器1314(诸如,具有执行加利福尼亚州桑尼威尔的mips技术公司的mips指令集的处理器和/或执行加利福尼亚州桑尼威尔的arm控股公司的arm指令集的处理器)来本地执行。指令转换器1312被用来将x86二进制代码1306转换成可以由不具有x86指令集核的处理器1314原生执行的代码。该转换后的代码不大可能与替代性指令集二进制代码1310相同,因为能够这样做的指令转换器难以制造;然而,转换后的代码将完成一般操作并由来自替代指令集的指令构成。因此,指令转换器1312表示:通过仿真、模拟或任何其它过程来允许不具有x86指令集处理器或核的处理器或其它电子设备得以执行x86二进制代码1306的软件、固件、硬件或其组合。
指令(多个)的某些操作可由硬件组件执行,且可体现在机器可执行指令中,该指令用于导致或至少致使电路或其它硬件组件以执行该操作的指令编程。电路可包括通用或专用处理器、或逻辑电路,这里仅给出几个示例。这些操作还可任选地由硬件和软件的组合执行。执行逻辑和/或处理器可包括响应于从机器指令导出的机器指令或一个或多个控制信号以存储指令指定的结果操作数的专用或特定电路或其它逻辑。例如,本文公开的指令的实施例可在图13-16的一个或多个系统中执行,且矢量友好指令格式的指令的实施例可存储在将在系统中执行的程序代码中。另外这些附图的处理元件可利用本文详细描述的详细描述的流水线和/或架构(例如有序和无序架构)之一。例如,有序架构的解码单元可解码指令、将经解码的指令传送到矢量或标量单元等。
上述描述旨在说明本发明的优选实施例。根据上述讨论,还应当显而易见的是,在发展迅速且进一步的进展难以预见的此技术领域中,本领域技术人员可在安排和细节上对本发明进行修改,而不背离落在所附权利要求及其等价方案的范围内的本发明的原理。例如,方法的一个或多个操作可组合或进一步分开。
替换实施例
尽管已经描述了将本地执行矢量友好指令格式的实施例,但本发明的可选实施例可通过运行在执行不同指令集的处理器(例如,执行美国加利福亚州桑尼维尔的mips技术公司的mips指令集的处理器、执行加利福亚州桑尼维尔的arm控股公司的arm指令集的处理器)上的仿真层来执行矢量友好指令格式。同样,尽管附图中的流程图示出本发明的某些实施例的特定操作顺序,按应理解该顺序是示例性的(例如,可选实施例可按不同顺序执行操作、组合某些操作、使某些操作重叠等)。
在以上描述中,为解释起见,阐明了众多具体细节以提供对本发明的实施例的透彻理解。然而,将对本领域技术人员明显的是,没有这些具体细节中的一些也可实践一个或多个其他实施例。提供所描述的具体实施例不是为了限制本发明而是为了说明本发明的实施例。本发明的范围不是由所提供的具体示例确定,而是仅由所附权利要求确定。
- 还没有人留言评论。精彩留言会获得点赞!