一种基于竞争学习的深度聚类方法与流程
本发明涉及大规模数据分析与聚类领域,更具体地,涉及一种基于竞争学习的深度聚类方法。
背景技术:
聚类算法在学术界和工业界都有着广泛的用途,常被用于一些有监督算法的初始化过程、探索大规模无标签数据的内在规律等领域。在数据量不断增加的今天,尤其是无标签数据的大量产生,聚类算法往往要面对超大体量的数据,传统的聚类算法在这类数据上表现难以令人满意。深度学习是目前解决大体量数据最有效的方法,强表达能力的深度特征在图像,视觉,语音等各种应用中表现出了很好的效果。为了有效改善大数据条件下聚类算法的性能,使用深度特征进行聚类取得较好的结果。
然而,尽管使用深度特征进行聚类在一些较小的数据库上得到了不错的结果,但在较大的数据库它仍然面临聚类效果不佳、结果不稳定等问题。中国科学院自动化研究所的宋纯锋等人提出了基于自编码机的聚类方法,这个方法利用类内约束更新网络,能够部分解决了原始空间重叠条件下的聚类问题。
技术实现要素:
为了克服上述现有技术的不足,本发明提出一种基于竞争学习的深度聚类方法。该方法能够有效的解决复杂的大数据背景下的聚类问题,在数据在原始空间有重叠的条件下,该方法学习到的特征空间在类内是紧凑的同时保证了类间的稀疏性,能有效的解决复杂大数据背景下的聚类问题。
为了实现上述目的,本发明的技术方案为:
一种基于竞争学习的深度聚类方法,引入竞争性聚类损失和有效聚类集,包括以下步骤:
s1.输入数据和网络参数,并进入网络循环体;
其中输入的数据和网络参数包括:样本集d={x1,x2,…,xn}、聚类中心数k、最大迭代次数t、聚类可信阈值γ和最小间隔α;其中样本集d={x1,x2,…,xn}是一组不含类别属性或标签的数据;
s2.使用网络本身的自编码机的最小重构损失加上额外的竞争聚类损失更新网络参数,使用更新网络参数后的网络提取深度特征,用于s3中的聚类;
s3.将s2中提取的深度特征输入已有的聚类模型进行聚类,更新聚类结果,利用更新的聚类结果,计算可信聚类集以筛选出聚类可信度高的样例,其中聚类可信度高是指其聚类可信值大于聚类可信阈值γ;
s4.在交替进行s2和s3更新轮数达到最大迭代次数t之前,将s3中的可信聚类集输入到s2进行新一轮的更新;当达到最大迭代次数t时,输出s3得到的更新后的聚类结果。
优选的,步骤s2中更新网络参数包括两种损失:网络本身自编码机的最小重构损失和额外的竞争聚类损失;
网络本身自编码机的最小重构损失ere为:
其中xi是样本集d中的第i个样例,h=f(·)是编码函数,x′=g(h)是解码函数;
额外的竞争聚类损失es为:
其中,ci*为样例xi所属的聚类中心,xj为任意一个与xi不属于同一个聚类中心的样例,d(·)表示任意一种距离度量;
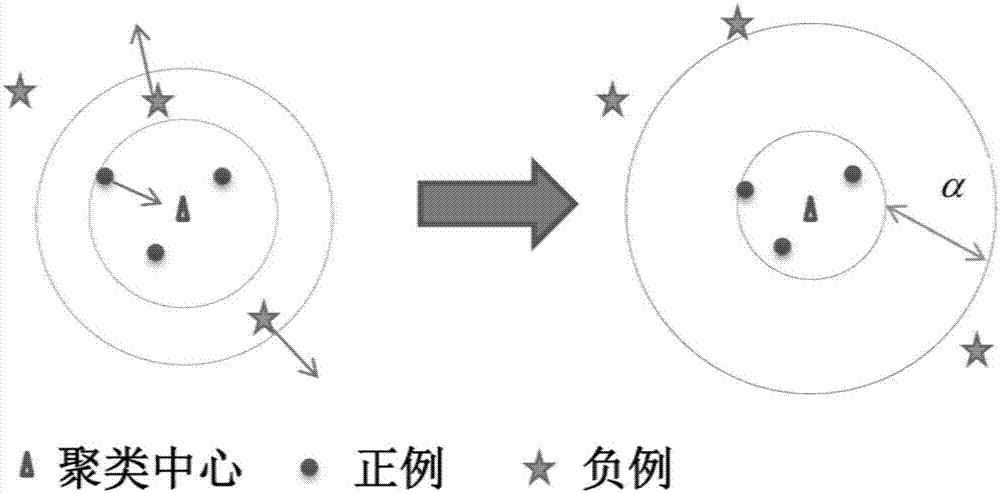
额外的竞争聚类损失的主要目标是希望自编码机学习到的特征具有以下性质:任意一个样例的编码到其聚类中心的距离要比不同簇的其他样例到该聚类中心的距离要大一个固定的正数;用公式(3)表达如下:
d(f(xi),ci*0+α≤d(f(xj),ci*)(3)
综合两种损失,得到模型的优化目标:
λ是用来平衡网络本身自编码机的最小重构损失和额外的竞争聚类损失之间的权重;
步骤s2中按照式(4)通过标准的反向传播算法对深度网络进行训练,更新网络的参数,并使用更新网络参数后的网络提取深度特征。
优选的,步骤s3中使用k-均值聚类对s2中得到的深度特征进行聚类,并计算可信聚类集对聚类结果进行筛选;
聚类中心和聚类类别的更新公式如下:
其中,上标“t”的变量代表第t次迭代时的参数,uj、ul代表聚类中心;βij代表样例xi与聚类中心uj之间的相似度,k-中心算法属于硬聚类算法,当样例xi属于聚类中心uj时βij的取值为1,否则取值为0;
在计算有效聚类集时,假设输入空间
首先,在高斯分布的假设下,根据利用极大似然估计得到先验概率和样本似然函数如下:
p(x=x|y=k)=n(μk,σk),k=1,2,…,k(8)
其中:
然后,计算后验概率,即为聚类可信度:
将聚类可信度大于聚类可信阈值γ的样本产生有效聚类集,参与下一轮网络参数的更新。
与现有技术相比,本发明的有益效果为:(1)竞争性聚类损失迫使网络去学习一个类内是紧凑的同时保证了类间的稀疏性的深度特征;(2)有效聚类集的引入,有效了提高了算法的稳定性,同时处理速度也更快。
本发明提出了基于竞争学习的深度聚类方法,用于改善已有聚类算法在大数据背景下的性能和稳定性,在一些有监督算法的初始化过程、探索大规模无标签数据的内在规律等方面有着十分重要的作用和广泛的应用空间。
附图说明
图1为竞争性聚类损失模型。
图2为方法流程图。
具体实施部分
附图仅用于示例性说明,不能理解为对本专利的限制;为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。下面结合附图对本发明的技术方案做进一步的说明。
一种基于竞争学习的深度聚类方法,包括以下步骤:
s1.输入网络数据参数,并进入网络循环体;
s2.使用网络本身的自编码机的最小重构损失加上额外的竞争聚类损失更新网络参数,使用更新网络参数后的网络提取深度特征,用于s3中的聚类;
s3.将s2中提取的深度特征输入已有的聚类模型进行聚类,更新聚类结果;,利用更新的聚类结果,计算可信聚类集以筛选出聚类可信度高的样例,其中聚类可信度高是指其聚类可信值大于聚类可信阈值γ;
步骤s1中输入的网络数据参数包括:样本集d={x1,x2,…,xn}、聚类中心数k、最大迭代次数t、聚类可信阈值γ和最小间隔α;其中样本集d={x1,x2,…,xn}是一组不含类别属性或标签的数据;
步骤s2中更新网络参数包括两种损失:自编码机的最小重构损失和额外的竞争聚类损失。
最小重构损失为:
其中包含一个编码(encode)函数h=f(x)和一个解码(decoder)函数x′=g(h);
额外的竞争聚类损失为:
其中,ci*为样例xi所属的聚类中心,xj为任意一个与xi不属于同一个聚类中心的样例,d(·)表示任意一种距离度量。该损失的主要目标是希望自编码机学习到的特征具有以下性质:任意一个样例的编码到其聚类中心的距离要比不同簇的其他样例到该聚类中心的距离要大一个固定的正数,直观的展示如图1。用公式表达如下:
d(f(xi),ci*)+α≤d(f(xj),ci*)公式3
综合两种损失,得到模型的优化目标:
λ是用来平衡网络本身自编码机的最小重构损失和额外的竞争聚类损失之间的权重;
步骤s2中按照上式(4)通过标准的反向传播算法进行训练,更新网络的参数,并使用更新网络参数后的网络提取深度特征。
步骤s3中可以使用任意一种传统的聚类算法对s2中得到的深度特征进行聚类,以k-均值聚类为例,聚类中心和聚类类别的更新公式如下:
其中上标“t”的变量代表第t次迭代时的参数,uj、ul代表聚类中心;βij代表样例xi与聚类中心uj之间的相似度,k-中心算法属于硬聚类算法,当样例xi属于聚类中心uj时βij的取值为1,否则取值为0。
在计算有效聚类集时,假设输入空间
首先,在高斯分布的假设下,根据利用极大似然估计可以得到先验概率和样本似然函数如下:
p(x=x|y=k)=n(μk,σk),k=1,2,…,k公式8
其中:
然后,计算后验概率,即为聚类可信度:
将聚类可信度大于某一固定阈值的样本产生有效聚类集,参与下一轮网络参数的更新。
步骤s4首先判断迭代次数是否达到预设的最高迭代次数,如果没有,则返回s2步骤,使用有效聚类集和新的聚类信息更新网络参数;如果已经达到了预设的迭代次数,则提取深度网络中的特征,使用任意一种传统的聚类算法进行聚类(本实施例中使用k-均值聚类),输出聚类结果。
图1为竞争性聚类损失模型的概念图,如果一个样例的编码到其聚类中心的距离要比不同簇的其他样例到该聚类中心的距离小于一个固定的正数,那么该样例会被拉向其聚类中心,而另一个样例会被推向远离该聚类中心。
以下为基于竞争学习的深度聚类方法更具体的模型,在这个模型中选取深度自编码机作为网络结构,k-均值算法作为聚类方法。
图2为本发明方法的流程图与主要算法步骤,其中包含数据输入、参数初始化与调优、网络参数更新、聚类信息更新、聚类等主要过程。
- 还没有人留言评论。精彩留言会获得点赞!