人脸特征点的相对坐标约束方法以及定位方法与流程
本发明涉及计算机视觉领域,更具体涉及一种人脸识别的方法。
背景技术:
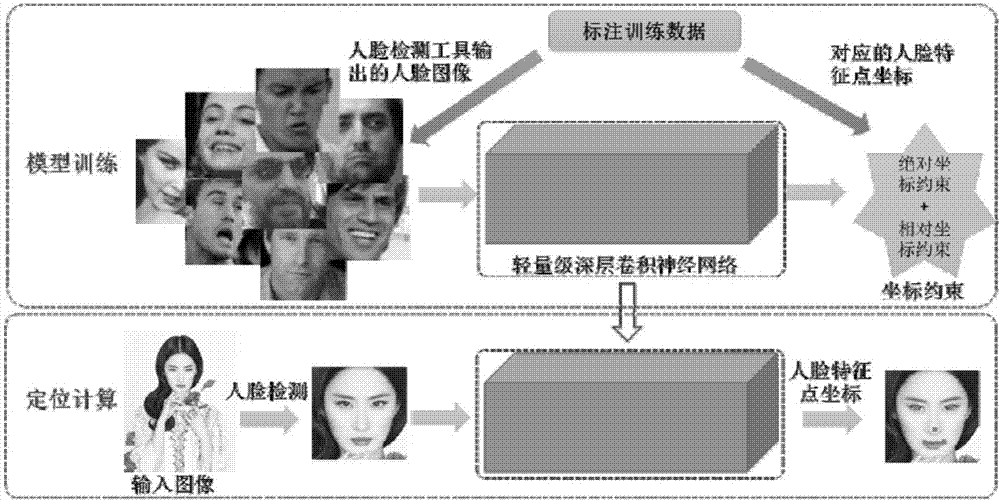
:人脸特征点自动定位可以分为模型训练和定位计算两大阶段,模型训练具体过程如下:1)收集一批训练用的人脸图像数据;2)人工标记每个人脸训练图像上各特征点位置;3)设计一个人脸特征点模型及其训练学习方法;4)从人工标记的训练人脸图像数据集中训练出模型的具体参数,用于定位识别阶段计算。定位计算阶段具体过程如下:1)输入一张人脸图像;2)检测人脸区域方框;3)把上步人脸区域内的图像输入上一阶段所学习的模型中计算得出特征点定位识别结果。目前主流的人脸特征点定位都是采用基于回归的方法。这些方法将人脸特征点定位当作一个多元变量回归问题,即将人脸图像当作输入变量、将人脸特征点坐标作为输出变量进行回归。这类方法又可以分为两小类:1)基于手工设计特征的方法;2)基于深度学习的方法。基于手工设计的方法首先提取图像的二值特征或小波等特征,然后通过随机森林或者决策树学习映射函数。基于深度学习的方法将特征提取与映射函数学习统一起来通过反向传播的方法学习到一个深层卷积神经网络(cnn)或递归神经网络(rnn)进行图片到坐标的端到端的映射。目前基于深度学习的方法效果要显著好于手工特征的方法。虽然现有的基于深度神经网络模型的方法达到了非常高的精度,但是其突出缺点在于网络参数过多导致定位速度过慢,若减少其参数则会显著降低其定位精度。其次,现有基于回归的方法(无论是手工设计特征还是深度网络学习特征),他们的优化目标(约束条件)全部是绝对坐标位置。具体地说,这些方法全是以欧式损失作为坐标约束条件。欧式坐标约束可以保证预测特征点接近于其对应的真实特征点,但是欧式损失这类绝对坐标约束条件并没有考虑到两个特征点之间的相对关系,会出现如图1所示的错误情况。在只看任何一个预测点的情况下,其都非常接近于真实点,然而两个预测点之间的相对位置和真实点相比出现较大误差。在只看任何一个预测点1’和2’的情况下,其都分别非常接近于真实点1和2,然而两个预测点1’和2’之间的相对位置和真实点1和2相比出现较大误差。技术实现要素:本发明所要解决的技术问题之一在于提供了一种能够帮助准确的定位人脸特征的人脸特征点的相对坐标约束方法。本发明所要解决的技术问题之二在于提供了一种能够准确定位人脸特征的方法。本发明是通过以下技术方案解决上述技术问题之一的:一种人脸特征点的相对坐标约束的方法,在人脸定位的过程中,计算任意两个人脸特征点i和j的相对位置,使得任意两个预测人脸特征点i和j的相对位置尽可能接近于其对应的两个真实的人脸特征点之间的相对位置。具体的,所述相对坐标约束的方法具体包括:假设现有训练数据集记为包含n张用于训练的人脸图像,其中in表示第n个图像,pn表示第n个图像的人脸特征点,且每张图像标注了m个人脸特征点,即pn=[pnx1,pnx2,...pnxm,pny1,pny2,...pnym]∈r2m,这里pnx*,pny*分别表示图像in的第*个特征点的横坐标与纵坐标,*∈(0,m);首先定义两个符号,即δnijx和δnijy用来衡量图像in的两个特征点i和j之间的相对位置关系,计算方法如公式(2)和公式(3)所示:其中,pnxi和pnxj分别表示图像in的第i个和第j个特征点的横真实的坐标,pnyi和pnyj分别表示图像in的第i个和第j个特征点的真实的纵坐标,和分别表示算法预测的图像in的第i个和第j个特征点的横坐标,和分别表示算法预测的图像in的第i个和第j个特征点的纵坐标;因此,获得相对坐标约束误差函数lr的计算公式如下:本发明是通过以下技术方案解决上述技术问题之二的:一种采用上述的人脸特征点的相对坐标约束的方法的人脸特征点定位方法,分为模型训练和定位计算两大阶段:模型训练流程如下:1)收集一批训练用的人脸图像数据;2)人工标记每个人脸训练图像上各特征点位置;3)在坐标约束方法的监督下学习深度映射函数模型,用于定位识别阶段计算;定位识别流程如下:1)输入一张人脸图像;2)检测人脸区域方框;3)把上步人脸区域方框内的图像输入模型训练阶段所学习的模型中计算对应的人脸特征点坐标;所述模型训练流程中的步骤3)中,采用了相对坐标约束的方法进行训练。所述相对坐标约束的方法具体包括:假设现有训练数据集记为包含n张用于训练的人脸图像,其中in表示第n个图像,pn表示第n个图像的人脸特征点,且每张图像标注了m个人脸特征点,即pn=[pnx1,pnx2,...pnxm,pny1,pny2,...pnym]∈r2m,这里pnx*,pny*分别表示图像in的第*个特征点的横坐标与纵坐标,*∈(0,m);首先定义两个符号,即δnijx和δnijy用来衡量图像in的两个特征点i和j之间的相对位置关系,计算方法如公式(2)和公式(3)所示:其中,pnxi和pnxj分别表示图像in的第i个和第j个特征点的横真实的坐标,pnyi和pnyj分别表示图像in的第i个和第j个特征点的真实的纵坐标,和分别表示算法预测的图像in的第i个和第j个特征点的横坐标,和分别表示算法预测的图像in的第i个和第j个特征点的纵坐标;因此,获得相对坐标约束误差函数lr的计算公式如下:优化的,所述模型训练流程中的步骤3)中,综合利用了现有的绝对坐标约束le和本发明提出的相对坐标约束lr,最终的总约束函数形式如下:l=le+λlr(5)其中,公式(1)中的是算法预测的人脸特征点,pn是真实的人脸特征点,公式(5)中的λ是超参数,用以平衡绝对随时和相对损失对总效果的影响,对于超参数λ,通过遍历的方法得到其最优值。优化的,对于5个特征点,λ的最优值是0.006。优化的,对于68个特征点,λ的最优值是0.0006。优化的,所述步骤三中,构建用于人脸特征点定位的深层神经网络的结构共7个卷积层,3个最大值池化层和3个全连接层。优化的,所述深层神经网络的结构具体为:卷积层、池化层、卷积层、卷积层、池化层、卷积层、卷积层、池化层、卷积层、卷积层、全连接层、全连接层、全连接层。优化的,每个卷积层的卷积核大小为2‐4,每个池化层的池化核大小为1‐3。本发明相比现有技术具有以下优点:1、可以提高任意姿态下人脸特征点定位精度的相对坐标约束方法,且本发明提出的约束方法只需在网络训练中进行相关操作,对于训练完成的网络进行实际使用时不增加任何计算量。2、本发明提出的轻量级的高性能人脸特征点定位神经网络结构,可以在较少参数的条件下获得更丰富的图片语义特征。附图说明图1是现有的方法的缺陷示意图;图2是本发明实施例提出的人脸特征点定位实现总体流程示意图;图3是本发明提出的相对坐标约束为什么可以以及如何克服现有绝对坐标约束的缺点解释示意图;图4是本发明实施例提出的用于人脸特征点定位的轻量级高表示力深层卷积神经网络结构;图5是实际人脸特征点定位效果图;图6是使用本发明实施例的定位方法的测试结果。具体实施方式下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。请参阅图2所示,本发明实施例提供的人脸特征点定位方法的整体框架是采用深层卷积神经网络的回归结构,即把人脸特征点定位当作回归任务。具体地说,将原始人脸图像作为输入特征,将人脸特征点的坐标当作输出,深层卷积网络用来进行人脸图像到特征点坐标的映射。本发明设计一种轻量级且高表示力的深层卷积网络结构在本发明提出的新的坐标约束方法的监督下学习映射函数。本发明实施例提供的人脸特征点定位方法分为模型训练和定位计算两大阶段:模型训练流程如下:1)收集一批训练用的人脸图像数据;2)人工标记每个人脸训练图像上各特征点位置;3)在坐标约束方法的监督下学习深度映射函数模型,用于定位识别阶段计算。定位计算流程如下:1)输入一张含有人脸的图像;2)检测人脸区域方框;3)把上步人脸区域方框内的图像输入模型训练阶段所学习的模型中计算对应的人脸特征点坐标。上述模型训练流程中的步骤1)、2)以及定位计算流程均是采用现有的方法实现。上述模型训练流程中的步骤3)中,采用了相对坐标约束的方法进行训练,具体为:假设现有训练数据集记为包含n张用于训练的人脸图像,其中in表示第n个图像,pn表示第n个图像的人脸特征点,且每张图像标注了m个人脸特征点,即pn=[pnx1,pnx2,...pnxm,pny1,pny2,...pnym]∈r2m,这里pnx*,pny*分别表示图像in的第*个特征点的横坐标与纵坐标,*∈(0,m)。现有方法的优化目标都是最小化预测点与真实点之间的绝对位置误差,即把如下事(1)计算的欧式损失le当作深度神经网络的损失函数:公式(1)中的是算法预测的人脸特征点,pn是真实的人脸特征点。在公式(1)的基础上,现有的深度学习的方法都将人脸特征点定位当作一个深度回归问题。缺点是明显的,如图1所示,公式(1)只能保证每个预测特征点的绝对坐标与其对应的真实特征点接近,并不能保证两个预测特征点之间的相对位置是正确的。本发明实施例提出了一种相对坐标约束的方法完美的解决了公式(1)所存在的问题,具体如下:首先定义两个符号,即δnijx和δnijy用来衡量图像in的两个特征点i和j之间的相对位置关系,计算方法如公式(2)和公式(3)所示:其中,pnxi和pnxj分别表示图像in的第i个和第j个特征点的真实的横坐标,pnyi和pnyj分别表示图像in的第i个和第j个特征点的真实的纵坐标,和分别表示算法预测的图像in的第i个和第j个特征点的横坐标,和分别表示算法预测的图像in的第i个和第j个特征点的纵坐标;因此,我们可以获得相对坐标约束误差函数lr的计算公式如下:从公式(4)我们可以看出,本发明提出的相对坐标约束考虑了任意两个人脸特征点i和j的相对位置,使得任意两个预测人脸特征点i和j的相对位置尽可能接近于其对应的两个真实的人脸特征点之间的相对位置。图3从向量的角度解释了本发明提出的相对坐标约束为什么可以以及如何克服现有绝对坐标约束的缺点。从图3中可以看出,传统的绝对坐标约束方法对于每一个目标点的优化是独立的,且传统方法的绝对坐标约束采用欧式误差函数作为优化目标,使得预测点的最优化空间处于真实点的周围。对于本发明提出的相对坐标约束,优化目标变为保证任意两个真实点之间的向量与其对应的两个预测点之间的向量相同,从而利用相对位置坐标信息克服了传统方法的缺陷。更进一步的,上述模型训练流程中的步骤3)中,综合利用了现有的绝对坐标约束le和本发明提出的相对坐标约束lr,本发明最终的总约束函数形式如下:l=le+λlr(5)公式(5)中的λ是超参数,用以平衡绝对损失和相对损失对总效果的影响。对于超参数λ,本发明通过遍历的方法得到其最优值,对于5个特征点,λ的最优值是0.006、对于68个特征点,λ的最优值是0.0006。上述模型训练流程中的步骤3)中,设计一种轻量级且高表示力的深层卷积网络结构在坐标约束方法的监督下学习深度映射函数模型,该深层神经网络的结构如图4所示,共7个卷积层,3个最大值池化层和3个全连接层。针对人脸这一特定目标,本发明从两个角度设计深层卷积网络的结构:1.1为了增加网络的表示力,本发明设计了一种可以在较少参数的条件下获得更丰富图片语义特征的深层卷积神经网络结构。具体地说,即在每一个池化层之后堆叠两个具有相同参数的卷积层,这种结构可以保证在同一语义特征尺度下学习到更丰富的语义特征,由于网络整体和局部都加深,本发明实施例提出的这种结构可以使整个网络结构在不同语义信息层级和同一语义信息层级内部的特征都进行更丰富的非线性映射。1.2为了减少模型的大小,本发明实施例严格控制各层神经元的尺寸,在极小的模型参数条件下保证了网络的表示能力,具体参数如表1所示。通过控制每一层特征图的个数,本发明实施例设计的深层网络模型大小可以控制在3m以内,虽然每一个卷积层的参数较少,但通过上述1.1中所描述网络结构可以获得比大参数模型更好的语义信息表示。表1各层类型卷积核(池化核)大小卷积层2‐4最大值池化层1‐3卷积层2‐4卷积层2‐4最大值池化层1‐3卷积层2‐4卷积层2‐4最大值池化层1‐3卷积层2‐4卷积层2‐4全连接层‐全连接层‐全连接层‐/‐/‐/2*特征点的个数经过验证,使用本发明实施例的人脸特征点定位方法,在常用的三个公开评测数据集上(mtfl,aflw,300-w)达到了最好的精度,平均误差如下表2所示(以所有人脸特征点的平均误差作为度量):表2数据集平均误差mtfl5.54aflw6.99300-w5.39模型仅有3mb且速度达到300fps(core-i5cpu)。实际检测效果示例如图5所示。图6展示的结果的测试数据来源于300-w,每张图像68个特征点,其中标号10所指的曲线为无遮挡图像检测效果,标号20所指的曲线为模拟遮挡图像1的检测效果,标号30所指的曲线为模拟遮挡图像2的检测效果,证明本发明提出的方法具有非常高的鲁棒性,可以解决各种严重遮挡情况。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1