Hadoop数据仓库的自动导入数据方法及系统与流程
本发明涉及了一种hadoop数据仓库的自动导入数据方法及系统。
背景技术:
随着企业要存储和分析处理的数据量越来越大,hadoop越来越受到重视,hadoop是apache软件基金会的开源项目。hadoop实现了一个分布式文件系统(hadoopdistributedfilesystem),简称hdfs。由于hadoop在可伸缩性、健壮性、计算性能和成本上具有无可替代的优势,已然成为当前主流的大数据存储和分析平台。
目前应用于大数据分析的基础数据通常是保存于如mysql、sqlsever、db2等关系型数据库中,由于对数据分析和处理的需要,需要将这些基础数据进行筛选并导入至hadoop的hive数据仓库中,通过hadoop平台的运算处理能力实现针对大数据的数据分析。sqoop是一款开源工具,利用sqoop我们能够在hadoop生态圈中建立一个供其他服务器调用的接口,通过调用该接口可以实现将关系型数据库中指定的数据导入到hadoop的hdfs中,hadoop最终再将这些hdfs文件导入至hive数据仓库中。由于用于分析的数据经常性会变动,每次进行数据更新时,都需要采用人工敲入代码的方式来调用数据传输接口,面对复杂的传输和处理流程,要求工作人员必须定时定期操作,因此费时费力。
技术实现要素:
针对现有技术的不足,本发明提供了一种hadoop数据仓库的自动导入数据方法及系统,解决了现有技术中每次将关系型数据库中的数据传输至hadoop的数据仓库时需要人工操作的不便之处。
为实现上述目的,本发明提供了一种hadoop数据仓库的自动导入数据方法,包括:
步骤一:搭载hadoop数据仓库的服务器c预先配置用于从搭载关系型数据库的服务器a中获取数据的数据传输接口;
步骤二:搭载作业调度器的服务器b预先配置用于调用所述数据传输接口的调用命令以及执行该调用命令的执行周期;
步骤三:服务器b按照执行周期定期执行调用命令;
步骤四:服务器c从服务器a中获取数据并生成hdfs分布式文件系统文件;
步骤五:服务器c将生成的hdfs文件导入至hive数据仓库中。
作为本发明的进一步改进,
所述步骤一具体包括:
服务器c预先配置数据传输接口的接口参数,该接口参数包括用于和服务器a建立连接关系的服务器a的数据库地址、数据库用户名和密码、服务器c的主机名以及用户名和密码,以及用于获取指定数据的数据筛选条件、表名以及列名。
作为本发明的进一步改进,
所述步骤三和步骤四之间还包括:
步骤a:服务器b监控服务器a中hdfs文件的生成情况;
所述步骤四和步骤五之间还包括:
步骤b:服务器b在监控到服务器a中hdfs文件生成完毕后向服务器c发送将hdfs数据导入至hive数据仓库的指令。
本发明还提供了一种hadoop数据仓库的自动导入数据系统,包括:
服务器a,用于搭载存储基础数据的关系型数据库;
服务器b,用于搭载作业调度器,用于预先配置调用所述数据传输接口的调用命令,以及按照执行周期定期执行调用命令;
服务器c,用于搭载hadoop数据仓库,用于预先配置从搭载关系型数据库的服务器a中获取数据的数据传输接口,用于从服务器a中获取数据并生成hdfs文件,以及将生成的hdfs文件导入至hive数据仓库中。
作为本发明的进一步改进,
所述服务器b包括:
调用命令配置模块,用于输入数据传输接口的调用命令;
执行周期配置模块,用于配置执行调用指令的执行周期。
作为本发明的进一步改进,
所述服务器c包括:
数据传输接口配置模块,用于配置数据传输接口;
hdfs文件生成模块,用于将获取的数据转化为hdfs文件;
hive数据仓库导入模块,用于将生成的hdfs文件导入至hive数据仓库中。
作为本发明的进一步改进,
所述调用命令配置模块包括:
接口参数配置单元:用于配置数据传输接口的接口参数,接口参数包括数据筛选条件、服务器a的数据库地址、表名以及列名。
作为本发明的进一步改进,
所述服务器b还包括:
hdfs文件监控模块:用于监控服务器c中hdfs文件的生成情况;
指令发送模块:用于向服务器c发送将hdfs数据导入至hive数据仓库的指令。
本发明的有益效果是:本申请技术方案提供的hadoop数据仓库的自动导入数据方法及系统,应用于关系型数据库到分布式系统架构中hive数据仓库的数据导入,实现了关系型数据库的数据能够定时定期地导入至hadoop的hive数据仓库中。与传统技术相比,面对复杂的传输和处理流程不需要人工进行操作,节省了工作人员的时间,而且不容易出错。
附图说明
图1为本发明hadoop数据仓库的自动导入数据方法实施例的流程图;
图2为本发明hadoop数据仓库的自动导入数据系统实施例的结构框图;
图3为本发明hadoop数据仓库的自动导入数据系统实施例中服务器b的结构框图;
图4为本发明hadoop数据仓库的自动导入数据系统实施例中服务器c的结构框图;
图5为本发明hadoop数据仓库的自动导入数据系统实施例中调用命令配置模块的结构框图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下参照附图并举实施例,对本发明进一步详细说明。
本发明hadoop数据仓库的自动导入数据方法的实施例,如图1所示,包括:
步骤一100:搭载hadoop数据仓库的服务器c预先配置用于从搭载关系型数据库的服务器a中获取数据的数据传输接口;
步骤二101:搭载作业调度器的服务器b预先配置用于调用所述数据传输接口的调用命令以及执行该调用命令的执行周期;
步骤三102:服务器b按照执行周期定期执行调用命令;
步骤四103:服务器c从服务器a中获取数据并生成hdfs文件;
步骤五104:服务器c将生成的hdfs文件导入至hive数据仓库中。
在本实施例中,所述步骤一具体包括:
服务器c预先配置数据传输接口的接口参数,该接口参数包括用于和服务器a建立连接关系的服务器a的数据库地址、数据库用户名和密码、服务器c的主机名以及用户名和密码,以及用于获取指定数据的数据筛选条件、表名以及列名。
服务器b通过调用服务器a中预先配置的数据传输接口能够实现服务器a和服务器c之间建立连接关系,并且服务器c从服务器a中获取指定的数据。
在本实施例中,
所述步骤三102和步骤四103之间还包括:
步骤a110:服务器b监控服务器a中hdfs文件的生成情况;
服务器c在从服务器a中获取数据时,会生成相应的hdfs文件,服务器b定时通过hadoopfs-get<hdfsfile><localfileordir>语句获取此hdfs文件,以此判断数据获取是否完成。
所述步骤四103和步骤五104之间还包括:
步骤b120:服务器b在监控到服务器a中hdfs文件生成完毕后向服务器c发送将hdfs数据导入至hive数据仓库的指令。
在此过程中,服务器b向服务器c发送hive接口的load指令,服务器c在收到服务器b发送的指令后将hdfs文件导入至hive数据仓库中。
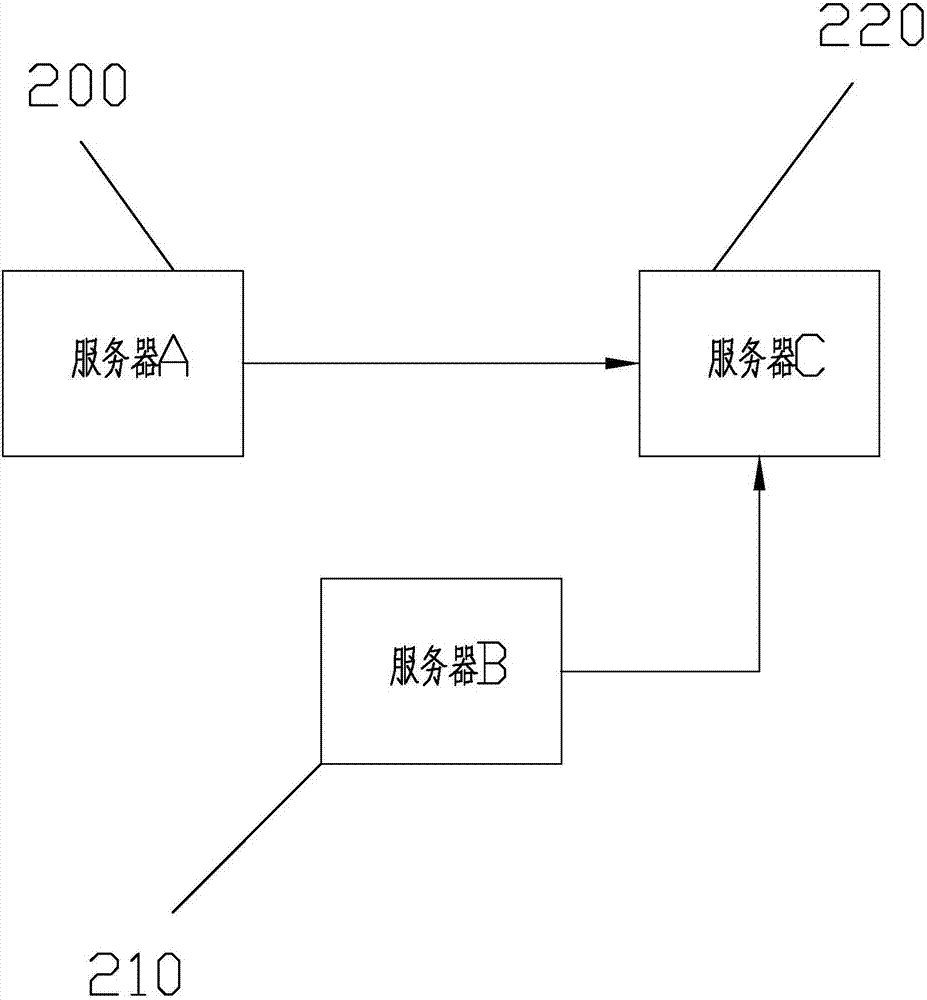
本发明hadoop数据仓库的自动导入数据系统的实施例如图2-5所示,包括:
服务器a200,用于搭载存储基础数据的关系型数据库;
服务器b210,用于搭载作业调度器,用于预先配置调用所述数据传输接口的调用命令,以及按照执行周期定期执行调用命令;
服务器c220,用于搭载hadoop数据仓库,用于预先配置从搭载关系型数据库的服务器a200中获取数据的数据传输接口,用于从服务器a200中获取数据并生成hdfs文件,以及将生成的hdfs文件导入至hive数据仓库中。
在本实施例中,所述服务器b210包括:
调用命令配置模块211,用于输入数据传输接口的调用命令;
执行周期配置模块212,用于配置执行调用指令的执行周期。
在本实施例中,所述服务器c220包括:
数据传输接口配置模块221,用于配置数据传输接口;
hdfs文件生成模块222,用于将获取的数据转化为hdfs文件;
hive数据仓库导入模块223,用于将生成的hdfs文件导入至hive数据仓库中。
在本实施例中,所述调用命令配置模块211包括:
接口参数配置单元211a:用于配置数据传输接口的接口参数,接口参数包括数据筛选条件、服务器a200的数据库地址、表名以及列名。
作为本发明的进一步改进,
所述服务器b210还包括:
hdfs文件监控模块213:用于监控服务器c220中hdfs文件的生成情况;
指令发送模块214:用于向服务器c220发送将hdfs数据导入至hive数据仓库的指令。
本发明应用于关系型数据库到分布式系统架构中hive数据仓库的数据导入,实现了关系型数据库的数据能够定时定期地导入至hadoop的hive数据仓库中。与传统技术相比,面对复杂的传输和处理流程不需要人工进行操作,节省了工作人员的时间,而且不容易出错。
需要说明的是,本发明中所述的服务器b和服务器c可以是同一服务器,当服务器b和服务器c为同一服务器时,该服务器同时搭载有hadoop集群和作业调度器,通过在该服务器端进行相应的配置,同样能够实现本发明所能达到的效果。
以上实施例,只是本发明优选地具体实施例的一种,本领域技术人员在本发明技术方案范围内进行的通常变化和替换都包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!