基于集成学习的多目标优化SAR图像变化检测方法与流程
本发明属于图像处理
技术领域:
,特别涉及一种sar图像变化检测方法,可用于遥感、医疗诊断和视频监控。
背景技术:
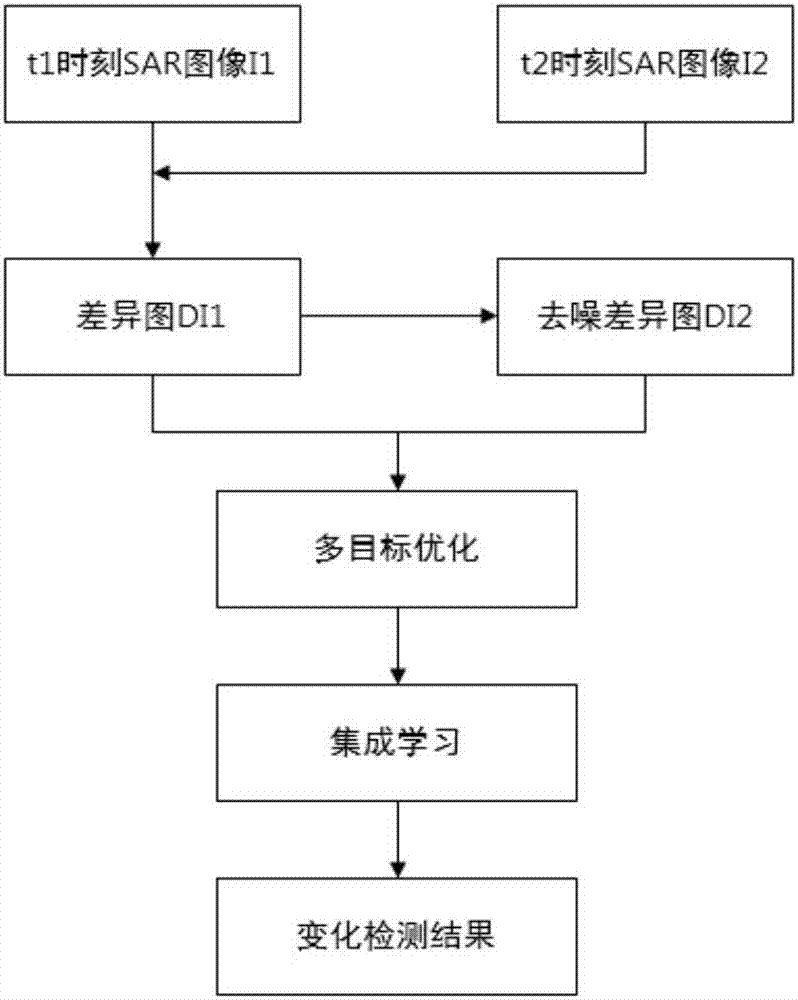
:由于合成孔径雷达sar不受云层覆盖和大气条件等因素的影响,sar图像技术在人们的日常生活中扮演着不可或缺的重要角色。而sar图像技术中的sar图像变化检测技术更起着尤为关键的作用。sar图像变化检测技术就是研究同一场景不同时段的两幅或者多幅sar图像发生的变化。它的应用场景很广泛,包括自然生态的监控,自然灾害评估和预防,获取地貌变化信息等。但是sar图像变化检测也经常会遇到难题,导致这些困难的原因很多,主要原因有:sar成像系统或者传感器自身所固有的斑点噪声的影响,不同时段成像回波角度不同所带来的差异,不同时段相隔时间长所带来的雷达自身内部结构发生的差异。从近年来对sar图像变化检测的研究来看,现有的图像变化检测可分为两种:第一种是差异图分类方法,它的核心是差异图的产生。该差异图分类方法包括差值法、比值法和对数比值法。差值法是最原始的处理方法,此方法的最大的缺点是对斑点噪声的抑制很差;比值法优点是在一定程度上抑制了斑点噪声,但是效果不是很明显,它的最大的缺点是加性噪声较多;对数比值法将加性噪声转化为乘性噪声,该方法通过对数转换后差异图得到了非线性拉伸,它的优点是增强了变化类和非变化类的对比度,但是它的缺点是差异图的准确度还不高。第二种是后分类比较法,该方法的关键是差异图中变化信息的提取,它的缺点是存在分类累积误差问题,影响分类的准确度。技术实现要素:本发明的目的在于针对上述已有技术的不足,提出一种基于集成学习的多目标优sar图像变化检测方法,以进一步优化并减少噪声,提高变化检测的准确度。实现本发明目的的技术方案是对输入的两幅sar图像y1和y2采用波动参数划分的方法产生原始差异图d1;再对原始差异图d1去噪得到去噪差异图d2;由原始差异图d1和去噪差异图d2构造两个目标函数,并计算得到这两个目标函数的函数值同时最小的解集,进而得到多个二值图像;对这多个二值图像再采用集成学习的方法得到最终的变化检测图像r。其步骤包括如下:(1)输入两幅同一地区不同时段的sar图像y1和y2,并对其进行滤波处理,得到滤波处理后的两幅图像i1和i2;(2)根据滤波处理后的两幅图像i1和i2产生原始差异图d1;2a)定义原始差异图的参数:小值像素接近函数f1,大值像素接近函数f2和波动参数h;2b)根据2a)定义的参数之间关系,计算原始差异图d1在位置x处的灰度值d1(x),其中x=1,2,...,m,m是原始差异图d1像素点的总个数;2c)根据2b)中计算出的每个像素点的灰度值d1(x)得到原始差异图d1;(3)对原始差异图d1进行滤波得到去噪差异图d2,并根据原始差异图d1和去噪差异图d2构造两个不同的目标函数f1(v1,v2)和f2(v1,v2),计算得到这两个目标函数的函数值同时最小的解集,由这个解集得到二值图像qk,k=1,2,...,100;(4)从二值图像qk中选取前99幅图像ts,s=1,2,...,99,采用集成学习的方法集成这99幅图像,得到最终的变化检测图像r。本发明与现有技术相比具有以下优点:1.本发明通过小值像素接近函数f1,大值像素接近函数f2和波动参数h的之间的关系来确定原始差异图d1在位置x处的分段函数计算方式,能够有效减少斑点噪声,保留图像局部信息。2.本发明在计算第一目标函数f1(v1,v2)和第二目标函数f2(v1,v2)的函数值时采用了多目标优化的方法,同时在得到最终的变化检测图像r时使用了集成学习的方法,提高了sar图像变化检测结果的准确度。附图说明图1为本发明的实现总流程图。图2为bern数据集原始图像及变化参考图。图3为ottawa数据集原始图像及变化参考图。图4为mulargia数据集原始图像及变化参考图。图5为用本发明测试bern、ottawa、mulargia数据集得到的二值图像r。图6为用现有的mofcm算法测试bern数据集得到的二值图像r。图7为用现有的mofcm算法测试ottawa数据集得到的二值图像r。图8为用现有的mofcm算法测试mulargia数据集得到的二值图像r。图9为用现有的flicm算法测试bern、ottawa、mulargia数据集得到的二值图像r。图10为用现有的mrfsm算法测试bern、ottawa、mulargia数据集得到的二值图像r。图11为用现有的mrffcm算法测试bern、ottawa、mulargia数据集得到的二值图像r。具体实施方式下面结合附图对本发明做详细说明:参照图1,本发明的实现步骤如下:步骤1,输入两幅同一地区不同时段的sar图像y1和y2,并对其进行滤波处理,得到滤波处理后的两幅图像i1和i2。本发明中采用的输入图像y1和y2来自bern数据集,ottawa数据集,mulargia数据集这三个数据集。bern数据集原始图像分别是通过ers-2获得的1999年4月和1999年5月瑞士bern地区的图像,第一幅图像是在洪水灾害刚刚发生后获得的,图像中阴暗部分为受洪水影响的区域,第二幅图像是洪水几乎完全消失的时候获得的,图像的大小为301×301,灰度级为256,等效视数为10.89和9.26。ottawa数据集原始图像分别为加拿大的ottawa地区的1997年5月和1997年8月的图像,图像的大小为290×350,灰度级为256。两幅图像的变化信息主要是由于因夏季雨季来临,洪水淹没了部分陆地地区所致。mulargia数据集原始图像分别为1996年7月和1996年9月的landsat-5卫星tm第五波段在意大利撒丁岛mulargia湖泊区域得到的图像组成,变化区域是由湖水水位上涨引起的,两幅图像的大小均为300×412。对图像的滤波预处理,现有方法主要有:中值滤波,均值滤波,维纳滤波,本实例使用的是维纳滤波对输入的两幅sar图像进行预处理,即将两幅sar图像y1,y2分别作为matlab中维纳滤波函数的输入,输出滤波后的两幅sar图像i1,i2。步骤2,根据滤波处理后的两幅图像i1和i2产生原始差异图d1。现有产生差异图的方法有:差值法,比值法,对数比值法,本实例使用与现有技术不同的另一种方法,其差异图的产生步骤如下:2a)定义原始差异图的参数:小值像素接近函数f1,大值像素接近函数f2和波动参数h;2a1)定义小值像素接近函数为滤波处理后的两幅图像i1和i2在位置x处的灰度值中,其较小的像素与其邻域ωx中的像素的接近程度,其中n为滤波处理后的两幅图像i1和i2在位置x处邻域中像素点的个数;2a2)定义大值像素接近函数为滤波处理后的两幅图像i1和i2在位置x处的灰度值中,其较大的像素与其邻域ωx中的像素的接近程度;2a3)定义波动参数h在0~10范围内,h取值为2;2b)根据2a)定义的参数之间关系,计算原始差异图d1在位置x处的灰度值d1(x),其中x=1,2,...,m,m是原始差异图d1像素点的总个数;2c)根据2b)中计算出的每个像素点的灰度值d1(x)得到原始差异图d1。步骤3,对原始差异图d1进行滤波得到去噪差异图d2,并根据原始差异图d1和去噪差异图d2构造两个不同的目标函数f1(v1,v2)和f2(v1,v2),计算得到这两个目标函数的函数值同时最小的解集,由这个解集得到二值图像qk,k=1,2,...,100。计算第一目标函数f1(v1,v2)和第二目标函数f2(v1,v2)的函数值的现有的方法主要有:moea/d算法,moea/de算法,nsga算法,本实例使用的是mofcm算法,其步骤如下:3a)对原始差异图d1进行滤波,得到去噪差异图d2;3b)随机产生均匀分布的n个权重向量w1,w2,...,wi...,wn,每一个权重向量的形式是wi=(wi1,wi2);3c)计算任意两个权重向量之间的欧式距离d(wi,wj),i,j=1,2,...n且i≠j,对第i个权重向量和其他权重向量的欧式距离按从小到到大排序,获得i个权重向量的t个最近的权重向量的上标集合:b(eq)={e1,...,eq...,et},由上标集合得到wi的t个最近的权重向量其中,eq表示第i个权重向量的最近的第q个权重向量的上标,q=1,2,...,t,其中wi1表示第一目标函数f1(vi1,vi2)所占的百分比,wi2表示第二目标函数f2(vi1,vi2)所占的百分比;3d)随机产生一个表示目标函数的解集的始化种群v1,v2,...,vi...,vn,每个种群的形式是vi=(vi1,vi2),其中vi1是第i个个体的第一维元素,vi2是第i个个体的第二维元素;3e)计算初始模糊隶属度矩阵u1,u2,...,ui...,un,其中每一个初始模糊隶属度矩阵的形式是uikx表示初始模糊隶属度矩阵中第i个个体的第k行对应的第x个隶属度,x=1,2,...,m,k=1,2,该uikx的计算公式如下:其中i=1,2,...,n,m=2,ukx满足约束3f)计算第一目标函数f1(vi1,vi2)和第二目标函数f2(vi1,vi2):3g)根据第一目标函数f1(vi1,vi2)和第二目标函数f2(vi1,vi2),计算权重和函数gws(vi|wi):gws(vi|wi)=wi1f1(vi1,vi2)+wi2f2(vi1,vi2);3h)设置当前循环次数b=1,总的循环次数t=100;3i)更新种群;3i1)从上标集合b(eq)选择两个下标s和l,使用遗传算子从vs和vl得到新的个体y,y的形式为y=(y1,y2),其中y1是个体y的第一维元素,y2是个体y的第二维元素;3i2)计算新的个体y的循环模糊隶属度矩阵:其中uykx表示循环模糊隶属度矩阵中个体y的第k行对应的第x个隶属度,循环模糊隶属度矩阵uy的每个元素uykx的计算公式如下:3i3)计算循环第一目标函数f1(y1,y2)和循环第二目标函数f2(y1,y2):3i4)根据循环第一目标函数f1(y1,y2)和循环第二目标函数f2(y1,y2),计算循环权重和函数gws(y|wi):gws(y|wi)=wi1f1(y1,y2)+wi2f2(y1,y2);3i5)比较循环权重函数gws(y|wi)和权重函数gws(vj|wi)的大小:如果gws(y|wi)≤gws(vj|wi),j∈b(eq),则将种群个体vj的值更新为y,并且将gws(y|wi)的值赋值给gws(vj|wi),反之,不进行任何操作;3j)判断更新的种群是否满足终止条件:如果不满足终止条件,即b<t,则b的值加1,返回步骤3h);如果满足终止条件,即b≥t,得到目标函数的解集v1,v2,...,vi...,vn,执行3j);3k)将目标函数的解集v1,v2,...,vi...,vn的vi分别代入公式:进而得到初始隶属度矩阵ui;3l)判断ui的第一行的每一个元素的大小:若元素的值大于0.5,则二值图像qk,k=1,2,...,100的对应像素的值为255。若元素的值小于0.5,则二值图像qk的对应像素的值为0。步骤4,从二值图像qk中选取前99幅图像ts,s=1,2,...,99,采用集成学习的方法集成这99幅图像,得到最终的变化检测图像r。4a)从二值图像qk中选取前99幅图像tg,g=1,2,...,99作为被集成的图像;4b)统计这99幅图像tg中统计在点(c,d)处像素灰度值为255的点的个数n1和灰度值为0的点的个数n2,其中c=1,2,...,col,d=1,2,...,row,col是图像tg的行数,row是图像tg的列数;4c)假设过渡标签图像p在点(c,d)的像素的灰度值为p(c,d),由n1和n2的大小关系得到过渡标签图像为p:如果n1≥n2,则过渡标签图像p的在点(c,d)处的像素点的灰度值p(c,d)=255;如果n1<n2,则过渡标签图像p的在点(c,d)处的像素点的灰度值p(c,d)=0;4d)分别比较二值图像tg和过渡标签图像p的所有像素点的灰度值,得到灰度值相同的点的个数same,计算评价准则total是二值图像tg像素点的总个数;4e)对arg按照从大到小的顺序进行排序,选取其中的最大的29个所对应的二值图像mapqa,a=1,2,...,29;4f)统计二值图像mapqa在点(c,d)处像素灰度值为255的点的个数m1和灰度值为0的点的个数m2;4g)假设最终变化检测结果二值图像r在点(c,d)的像素的灰度值为r(c,d),根据m1和m2的大小关系得到最终变化检测结果二值图像为r:如果m1≥m2,则最终变化检测结果二值图像r在点(c,d)处的像素点的灰度值r(c,d)=255;如果m1<m2,则最终变化检测结果二值图像r在点(c,d)处的像素点的r(c,d)=0。步骤5,根据r和已知的变化参考图像s,计算虚检数fp,漏检数fn,总错误数oe,和卡帕系数kc。5a)设变化参考图像s在x处的像素的灰度值用a(x)表示,设图像r在x处的像素的灰度值用b(x)表示,设nc为a(x)=255的像素点的个数,设nu为a(x)=0的像素点的个数,设tp为b(x)=255的像素点的个数,设tn为b(x)=0的像素点的个数,设mc为变化参考图像s的像素点的总个数;5b)由nu和tn计算虚检数fp,即fp=nu-tn;5c)由nc和tp计算漏检数fn,即fn=nc-tp;5d)由fp和fn计算总错误数oe,即oe=fp+fn;5e)由tp,tn和mc计算精确度pcc,即5f)由tp,tn,fp,fn,nc,nu和mc计算过度参数pre,即;5g)由pcc和pre计算卡帕系数kc,即通过步骤5可检验本发明对变化检测结果的精度高低,即通过计算卡帕系数kc指标检验变化检测结果的精度。本发明的实验效果通过以下仿真说明:1.仿真实验采用的数据集:本实验仿真采用bern、ottawa和mulargia三个数据集,其中:bern数据集,如图2所示,其中图2(a)是通过ers-2获得的1999年4月瑞士bern地区的图像,图2(b)是通过ers-2获得的1999年5月瑞士bern地区的图像,图2(c)是变化参考图;ottawa数据集,如图3所示,其中图3(a)是加拿大ottawa地区的1997年5月的图像,图3(b)是加拿大ottawa地区的1997年8月的图像,图3(c)是变化参考图;mulargia数据集,如图4所示,其中图4(a)是1996年7月意大利撒丁岛mulargia湖泊区域的图像,图4(b)是1996年9月意大利撒丁岛mulargia湖泊区域的图像,图4(c)是变化参考图。2.仿真内容:仿真1:用本发明方法分别对bern数据集、ottawa数据集和mulargia数据集中的各2幅输入图像进行变化检测,结果如图5所示,其中:图5(a)为本发明仿真bern数据集得到的二值图像r,图5(b)为本发明仿真ottawa数据集的得到二值图像r,图5(c)为本发明仿真mulargia数据集的得到二值图像r。用本发明方法分别对bern数据集、ottawa数据集和mulargia数据集中的各2幅输入图像进行变化检测,再分别根据图2(c)图,图3(c)图,图4(c)图得到的虚检数fp,漏检数fn,总错误数oe,再根据虚检数fp,漏检数fn,总错误数oe计算卡帕系数kc,结果如表1:表1虚检数fp漏检数fn总错误数oe卡帕系数kcbern数据集951962910.867ottawa数据集540193224720.905mulargia数据集505831953770.709仿真2:用mofcm算法分别对bern数据集、ottawa数据集和mulargia数据集中的各2幅输入图像进行变化检测,结果如图6-8所示,其中:图6(a)~(f)为mofcm算法仿真bern数据集得到的二值图像r,图7(a)~(f)为mofcm算法仿真ottawa数据集的得到二值图像r,图8(a)~(f)为mofcm算法仿真mulargia数据集的得到二值图像r。用mofcm算法对bern数据集2幅输入图像进行变化检测,再根据图2(c)图得到的虚检数fp,漏检数fn,总错误数oe和虚检数fp、漏检数fn及总错误数oe,计算卡帕系数kc,结果如表2:表2种群代数虚检数fp漏检数fn总错误数oe卡帕系数kc1760468060.72920631697000.75240774888620.70860771938640.70680771938640.706100771938640.706用mofcm算法对ottawa数据集2幅输入图像进行变化检测,再根据图3(c)图,得到的虚检数fp,漏检数fn,总错误数oe和虚检数fp、漏检数fn及总错误数oe,计算卡帕系数kc,结果如表3:表3种群代数虚检数fp漏检数fn总错误数oe卡帕系数kc1178098627660.899203627115047770.833406007135773640.756605986154675320.749805986154675320.7491005986154675320.749用mofcm算法对mulargia数据集的2幅输入图像进行变化检测,再根据图4(c)图得到的虚检数fp,漏检数fn,总错误数oe和虚检数fp、漏检数fn及总错误数oe,计算卡帕系数kc,结果如表4:表4种群代数虚检数fp漏检数fn总错误数oe卡帕系数kc1604628463300.67320645429767510.65740630231366150.66160626931965880.66380626931965880.663100626931965880.663仿真3:用flicm算法分别对bern数据集、ottawa数据集和mulargia数据集中的各2幅输入图像进行变化检测,结果如图9所示,其中:图9(a)为用flicm算法仿真bern数据集得到的二值图像r,图9(b)为用flicm算法仿真ottawa数据集的得到二值图像r,图9(c)为用flicm算法仿真mulargia数据集的得到二值图像r。用flicm算法对bern数据集,ottawa数据集,mulargia数据集中的各2幅输入图像进行变化检测,再分别根据图2(c)图,图3(c)图,图4(c)图得到的虚检数fp,漏检数fn,总错误数oe和虚检数fp、漏检数fn及总错误数oe,计算卡帕系数kc,结果如表5:表5虚检数fp漏检数fn总错误数oe卡帕系数kcbern数据集1641733370.851ottawa数据集1160171428740.892mulargia数据集19074957200310.659仿真4::用mrfsm算法分别对bern数据集、ottawa数据集和mulargia数据集中的各2幅输入图像进行变化检测,结果如图10所示,其中:图10(a)为用mrfsm算法仿真bern数据集得到的二值图像r,图10(b)为用mrfsm算法仿真ottawa数据集的得到二值图像r,图10(c)为用mrfsm算法仿真mulargia数据集的得到二值图像r。用mrfsm算法对bern数据集,ottawa数据集,mulargia数据集中的各2幅输入图像进行变化检测,再分别根据图2(c)图,图3(c)图,图4(c)图得到的虚检数fp,漏检数fn,总错误数oe和虚检数fp、漏检数fn及总错误数oe,计算卡帕系数kc,结果如表6:表6虚检数fp漏检数fn总错误数oe卡帕系数kcbern数据集1033615103510.16ottawa数据集471218026510.897mulargia数据集159961116171120.694仿真5:用mrffcm算法分别对bern数据集、ottawa数据集和mulargia数据集中的各2幅输入图像进行变化检测,结果如图11所示,其中:图11(a)为用mrffcm算法仿真bern数据集得到的二值图像r,图11(b)为用mrffcm算法仿真ottawa数据集的得到二值图像r,图11(c)为用mrffcm算法仿真mulargia数据集的得到二值图像r。用mrffcm算法对bern数据集,ottawa数据集,mulargia数据集中的各2幅输入图像进行变化检测,再分别根据图2(c)图,图3(c)图,图4(c)图得到的虚检数fp,漏检数fn,总错误数oe和虚检数fp、漏检数fn及总错误数oe,计算卡帕系数kc,结果如表7:表7虚检数fp漏检数fn总错误数oe卡帕系数kcbern数据集346894350.828ottawa数据集474217626500.898mulargia数据集170101182181920.679将表1到表7进行整合,得到表8:表8整合后的三个数据集的不同算法的比较表由表8可以看出本发明的kc的值要大于现有mofcm算法,flicm算法,mrfsm算法,mrffcm算法kc的值,说明本发明比mofcm算法,flicm算法,mrfsm算法,mrffcm算法的变化检测方法效果好,减少了斑点噪声,保留了图像局部信息,提高了分类的准确度。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1