一种基于文件知识图谱的开源软件社区专家推荐方法与流程
本发明涉及软件工程与推荐系统领域,特别是涉及一种基于文件知识图谱的开源软件社区专家推荐方法。
背景技术:
目前,开源软件社区日益受到开发者的关注与参与,越来越多的优秀项目从这里诞生。它的核心思想是众人共同来完成项目,由于开发者可能身处于不同的地方,所以尽管这种全球化的分布式项目开发方式吸引了许多开发者加入,节约了人力成本,但由于项目成员之间的工作交流往往通过自主地电子通讯方式,受到时间与空间因素的影响,甚至制约了那些新加入的或不熟练的开发者尽快熟悉项目。有研究指出在开源软件项目中有4%至30%的开发者存在联系专家的困境。他们有时为了寻找与自己开发方向相类似的专家,浪费了太多时间,通常比那些不需要联系专家的开发者多花费12天来完成项目中的任务,严重影响了开发进度。为了克服开源软件社区开发者联系专家的不便性,给软件开发者推荐专家显得非常有必要。
传统的专家推荐系统,通过项目组的不同成员对项目文件的历史工作情况来评测成员之间的相似性,基于成员之间的相似性做出推荐;或者通过成员对不同项目文件的历史工作情况来评测项目文件之间的相似性,基于相似性的项目文件所附属的专家做出推荐。这类推荐方法计算复杂度高,结构比较单一,使用成本较高。由于在开源软件社区开发者寻找专家的行为,本身是一种基于当前项目任务为动机的过程,所以同一个开发者在处理不同项目文件时,可能需要寻找不同方面的专家,传统的专家推荐系统很难处理这类实时推荐问题。
技术实现要素:
为了克服现有专家推荐系统的实时性较差、精准性较低、时间成本较高、开发效率较低的不足,本发明提供一种实时性良好、精准性较高、时间成本较低、开发效率较高的基于文件知识图谱的开源软件社区专家推荐方法。
本发明解决其技术问题所采用的技术方案如下:
一种基于文件知识图谱的开源软件社区专家推荐方法,包括以下步骤:
s1:针对开源软件社区中的某个项目,根据文件路径计算两两文件路径之间的相似度,构建项目文件关系网络;
s2:对项目文件关系网络,使用node2vec算法,提取网络中各个文件的知识图谱特征;
s3:将开发者本人的历史编辑文件特征,与其联系过的专家的历史编辑文件特征整合为该开发者的已知开发行为特征;
s4:根据开发者的历史已知特征,训练随机森林模型,用于推荐其开发过程中需要联系的专家。
所述步骤s1中,计算两两文件路径之间的相似度,文件1与文件2在某个项目中的绝对路径分别为:f1,f2,则文件1与文件2的路径相似度为
其中stringcomparison(f1,f2)为文件1与文件2的绝对路径中的相同部分个数;max(length(f1),length(f2))为文件1与文件2的绝对路径长度的最大值。
所述步骤s1中,构建项目文件关系网络:项目文件关系网络g(v,e,w),其中v表示文件作为网络节点,e表示两两文件的关系连边,w表示两两文件的路径相似度权重。
所述步骤s2中,对步骤s1得到的项目文件关系网络,使用node2vec算法,提取网络中各个文件的知识图谱特征:n维向量rν∈r1×n。提取特征过程分为以下3步:根据项目文件关系网络g(v,e,w),定义每个节点随机游走的规则;根据节点随机游走的规则,对网络g′(v,e,π)进行随机游走,保存游走记录;对游走记录最大似然函数,得到每个文件节点的知识图谱特征。
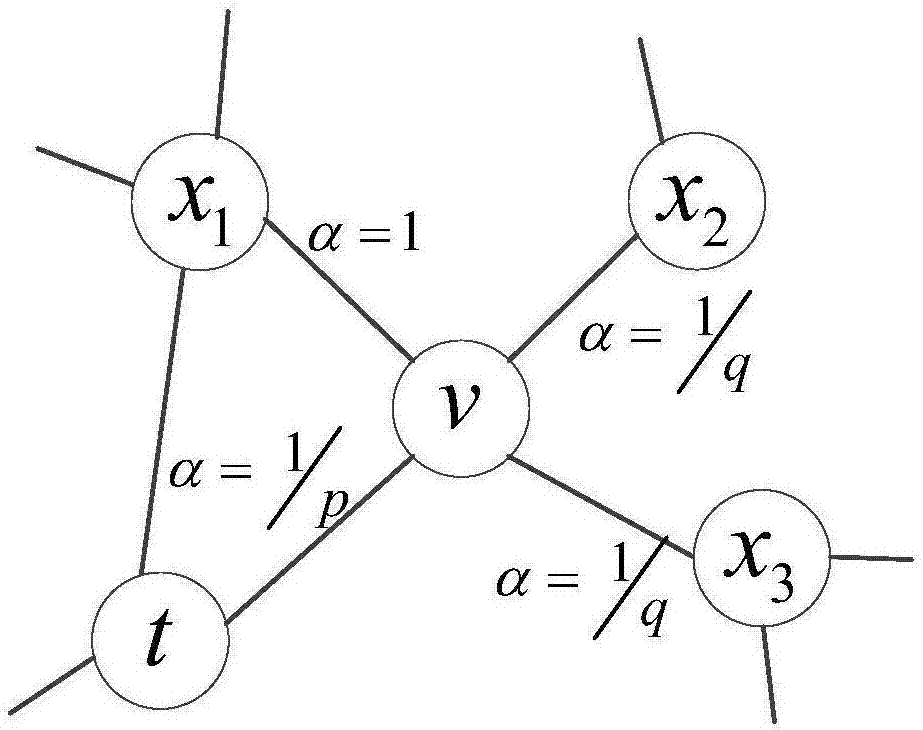
所述步骤s2中,根据项目文件关系网络g(v,e,w),定义每个节点随机游走的规则,假设上一时刻在节点t,现在随机游走到节点v,则下一步从节点v出发,会游走到节点v的其中一个邻居节点v′∈{t,x1,x2,x3},游走概率πvv′定义为
πvv′=αpq(t,v′)·wvv′
其中dtv′指的是网络中节点t与节点v′的最短权重路径长度,p和q分别是控制随机游走返回到上一时刻的节点、控制随机游走选择深度遍历或广度遍历的常数项因子,wvv′指的是项目文件关系网络g(v,e,w)中,节点v与节点v′之间的相似度权重。
所述步骤s2中,根据节点随机游走的规则,得到网络g′(v,e,π),对网络g′中所有节点进行π权重概率、总步长l的随机游走,每次将游走记录放入walk列表中,循环设定次数。
所述步骤s2中,针对walk列表中所有位置上的节点,用随机梯度下降法最优化函数
所述步骤s3中,将开发者的所有邮件联系数据按时间先后顺序排序,取前一半时间的数据作为训练数据,后一半时间的数据作为测试数据;针对每条开发者的邮件联系数据,将其当时联系的专家作为标签;定义:ra∈r1×n,为该开发者在此邮件联系时间之前的最近时刻编辑的文件集合的知识图谱特征的向量和;rb∈r1×n,为该开发者在此邮件联系时间之前的所有历史编辑的文件集合的知识图谱特征的向量和;rc∈r1×n,为该开发者在此邮件联系时间之前的最近时刻联系过的专家在最近一次编辑的文件集合的知识图谱特征的向量和;rd∈r1×n,为该开发者在此邮件联系时间之前的最近时刻联系过的专家的历史编辑文件集合的知识图谱特征的向量和;整合这4个向量特征(ra,rb,rc,rd)∈r1×4n,作为该开发者的历史已知特征。
所述步骤s4中,根据开发者的历史已知特征(ra,rb,rc,rd)∈r1×4n以及相应的专家标签数据,使用训练数据构建随机森林模型,用于推荐其在测试数据里的开发过程中需要联系的专家。
本发明的技术构思为:本发明根据node2vec算法框架(参考文献:[1]grovera,leskovecj.node2vec:scalablefeaturelearningfornetworks,proceedingsofthe22ndacmsigkddinternationalconferenceonknowledgediscoveryanddatamining.acm,2016:855-864,即grovera,leskovecj.node2vec:网络的可扩展特征学习,proceedingsofthe22ndacmsigkddinternationalconferenceonknowledgediscoveryanddatamining.acm,2016:855-864),将每个项目文件转化为各个知识图谱,通过将开源软件社区开发者当前涉及到的这些文件的图谱信息,实时地为该开发者预测并推荐与其目前项目开发工作相关的专家。
本发明有益效果如下:本发明将每个项目文件转化为各个知识图谱,通过将开源软件社区开发者当前涉及到的这些文件的图谱信息,预测并推荐相应的专家。本发明不仅改善了传统的专家推荐系统计算复杂度高、结构单一的缺点,通过当前项目开发者的工作状态,还有效地实现了专家推荐的实时性精准性,大大节省了开发者联系专家的时间成本,提高了开发效率。
附图说明
图1为本发明实施例的基于文件知识图谱的开源软件社区专家推荐的流程图;
图2为本发明实施例的关于node2vec算法涉及的子网络示意图。
具体实施方式
下面结合附图对本发明做进一步说明。
参照图1和图2,一种基于文件知识图谱的开源软件社区专家推荐方法,本发明使用apache软件基金会(apachesoftwarefoundation)中的20个项目的成员提交文件数据、电子邮件交流数据以及各个文件路径数据。
本发明包括以下四个步骤:
s1:针对开源软件社区中的某个项目,根据文件路径计算两两文件路径之间的相似度,构建项目文件关系网络;
s2:对项目文件关系网络,使用node2vec算法,提取网络中各个文件的知识图谱特征;
s3:将开发者本人的历史编辑文件特征,与其联系过的专家的历史编辑文件特征整合为该开发者的已知开发行为特征;
s4:根据开发者的历史已知特征,训练随机森林模型,用于推荐其开发过程中需要联系的专家。
所述步骤s1中,计算两两文件路径之间的相似度,文件1与文件2在某个项目中的绝对路径分别为:f1=“src/com/android/settings/locationsettings.java”,f2=“src/com/android/settings/utils.java”,则文件1与文件2的路径相似度为
其中stringcomparison(f1,f2)为文件1与文件2的绝对路径中的相同部分个数;max(length(f1),length(f2))为文件1与文件2的绝对路径长度的最大值,在本例中文件1与文件2的stringcomparison(f1,f2)=4,max(length(f1),length(f2))=5,则文件1与文件2的路径之间相似度为similarity(f1,f2)=0.8。
所述步骤s1中,构建项目文件关系网络:项目文件关系网络g(v,e,w),其中v表示文件作为网络节点,e表示两两文件的关系连边,w表示两两文件的路径相似度权重。
所述步骤s2中,对步骤s1得到的项目文件关系网络,使用node2vec算法,提取网络中各个文件的知识图谱特征,所述node2vec算法提取特征过程如下:
s2-1:根据项目文件关系网络g(v,e,w),定义每个节点随机游走的规则,附图2是某次随机游走的子网络示意图,假设上一时刻在节点t,现在随机游走到节点v,则下一步从节点v出发,会游走到节点v的其中一个邻居节点v′∈{t,x1,x2,x3},游走概率πvv′定义为
πvv′=αpq(t,v′)·wvv′
其中dtv′指的是网络中节点t与节点v′的最短权重路径长度,p和q分别是控制随机游走返回到上一时刻的节点、控制随机游走选择深度遍历或广度遍历的常数项因子,wvv′指的是项目文件关系网络g(v,e,w)中,节点v与节点v′之间的相似度权重;
s2-2:根据节点随机游走的规则,得到网络g′(v,e,π),对网络g′中所有节点进行π权重概率、总步长l的随机游走,每次将游走记录放入walk列表中,循环设定次数(例如5次);
s2-3:针对walk列表中所有位置上的节点,用随机梯度下降法最优化函数
所述步骤s3中,将开发者的所有邮件联系数据按时间先后顺序排序,取前一半时间的数据作为训练数据,后一半时间的数据作为测试数据;针对每条开发者的邮件联系数据,将其当时联系的专家作为标签;定义:ra∈r1×n,为该开发者在此邮件联系时间之前的最近时刻编辑的文件集合的知识图谱特征的向量和;rb∈r1×n,为该开发者在此邮件联系时间之前的所有历史编辑的文件集合的知识图谱特征的向量和;rc∈r1×n,为该开发者在此邮件联系时间之前的最近时刻联系过的专家在最近一次编辑的文件集合的知识图谱特征的向量和;rd∈r1×n,为该开发者在此邮件联系时间之前的最近时刻联系过的专家的历史编辑文件集合的知识图谱特征的向量和;整合这4个向量特征(ra,rb,rc,rd)∈r1×4n,作为该开发者的历史已知特征。
所述步骤s4中,根据开发者的历史已知特征(ra,rb,rc,rd)∈r1×4n以及相应的专家标签数据,使用训练数据构建随机森林模型,用于推荐其在测试数据里的开发过程中需要联系的专家。
如上所述为本发明在apache软件基金会的20个项目的开发者专家推荐方法的实施例介绍,本发明通过开发者当前编辑过的项目文件,及其之前邮件联系人的项目文件等开发状态,实时为该开发者提供与其项目开发状态相关的推荐专家列表。相比于传统专家推荐系统,有监督学习地提取相似度特征,本发明使用node2vec算法,以半监督深度学习的方式提取项目文件的知识图谱特征,能最大限度地发掘文件的属性特征,提高推荐效果。对发明而言仅仅是说明性的,而非限制性的。本专业技术人员理解,在发明权利要求所限定的精神和范围内可对其进行许多改变,修改,甚至等效,但都将落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!