一种自动生成小说文本情感曲线并预测推荐的方法与流程
本发明属于计算机自然语言处理中的情感分析邻域,涉及一种自动生成小说文本情感曲线并预测推荐的方法。
背景技术:
心理学研究表明,人们倾向于对那些具有熟悉模式的故事更有好感,而讨厌那些和自身的经验相悖的故事情节。kurtvonnegut认为,故事的情感曲线是小说阅读价值的核心体现;好的小说往往具有相似的情感变化模式。为了更好的分析小说文本的情感变化,需要生成小说文本的情感曲线并进行相关的比较分析。
有关小说文本的情感曲线生成的问题尚处在探究阶段。虽然对于段落以及短文本存在各种各样的情感分析评价方法,但是对于生成情感曲线,也就是情感分数的时间序列这一任务来说,基本上还是使用比较通用的文本采样+情感词典映射的技术组合。
在以往的相关技术中,并没有关注如何通过比较小说的情感曲线来更进一步地为文本分析提供帮助这一问题;相关的工作都只有对小说的情感曲线进行定性分析,在这些工作中为了方便分析也只采用了对定长的小说曲线(也就是具有相同时间解析度的时间序列)计算曼哈顿距离(manhattandistance)等方法。事实上,对于这种具有特定单独“时间轴”的数据应当使用时间序列分析方面的方法。
传统上对于距离类相关回归分析任务,并没有统一的很好的方法,尤其对于曲线间的距离这一不同于传统欧式空间中的距离。这些距离度量虽然可能可以更好地反映时间序列之间的关系,但是特定的度量可能不满足三角不等式,而使得该种度量无法简单地套用传统的机器学习方法。
技术实现要素:
发明目的:本发明主要是针对在现有的小说文本分析中对于小说文本总体情感变化特征缺乏考虑这一问题,提出了一种能够综合考察不同文本之间的情感变化异同,并通过机器学习过程给出小说的相关统计量预测和推荐的方法。
为了解决上述技术问题,本发明公开了一种自动生成小说文本情感曲线并预测推荐的方法。该方法所有的步骤均运行于windows平台,对来自古登堡计划(www.gutenberg.org)的小说文本数据集生成曲线,给出下载量预测并推荐。
本发明中所使用的python的spacy工具包(spacy.io),是由“explosionai”组织(twitter.com/explosion_ai)编写的一个用于自然语言处理的开源工具包。
本发明中使用的labmt情感词汇表(neuro.imm.dtu.dk/wiki/labmt),是petersheridandodds等人为他们的论文(arxiv.org/abs/1101.5120v3)所提供的补充材料。labmt情感词汇表取自广泛数据集,使用众包服务得到大众对主要单词的情感评分;每个单词都会获得50次以上独立评估,因此labmt情感词典的单词情感评分有广泛性和客观性。
本发明中有关传统的高斯过程的具体实施步骤,是现有的技术,在c.e.rasmussen等人的《gaussianprocessesformachinelearning》(mit出版社,2006)一书中有详细叙述。
本发明中所涉及的有关计算两条时间序列的动态时间规整距离的技术,是来自于时间序列分析领域的现有技术,但是在传统自然语言处理邻域引用较少。本发明主要是将其引入到新的计算小说文本的情感曲线之间这一问题中来,并且在实际应用的后续步骤中,也对该技术生成距离矩阵做出了修正,以满足后续模型的要求。
本发明所述方法主要包括如下步骤:
步骤1,从小说文本中生成小说的情感曲线。
步骤2,计算步骤1中得到的情感曲线的两两之间的动态规整距离矩阵。
步骤3,利用步骤2中得到的动态规整距离矩阵,通过改进的高斯过程给出下载量预测。
步骤4,利用步骤2中得到的动态规整距离,将对应小说文本按距离大小从小到大排序,输出距离最近的小说标题作为推荐。
本发明步骤1包括如下步骤:
步骤1-1,利用python的自然语言处理工具包spacy将小说的训练文本和目标文本分词,并去除标点符号、人物称谓简称(如mr,mrs等)这些不影响文本的有效单词个数的元素,得到文本的单词列表。
步骤1-2,将文本的单词列表按顺序分割成单词窗口,依次计算出每个单词窗口的平均情感分数。
步骤1-3,将步骤1-2中得到的情感分数依次排列,生成一组情感分数的时间序列,计算出该时间序列的移动平均序列。最后得到的移动平均序列即作为小说的情感曲线。
本发明步骤1-2包括如下步骤:
步骤1-2-1,将文本的单词列表按照单词窗口大小nw等分分割成文本窗口。
步骤1-2-2,通过labmt情感词汇表得到常用单词的情感分数映射表,形式是一个从单词到情感分数的映射函数havg(w)。
步骤1-2-3,统计文本窗口中出现在情感分数映射表中的单词和单词出现的频数;
步骤1-2-4,通过如下公式计算每个文本窗口t的情感分数havg(t):
其中,窗口中出现在情感分数映射表中的单词分别为w1,w2,…,wn,窗口出现在表中的单词的总数为n,第i个单词wi对应的情感分数为havg(wi),第i个单词wi在文本窗口t中对应的频数为fi(t),i取值范围为1~n。
步骤1-2-1包括如下步骤:
步骤1-2-1-1,针对文本的单词列表和需要生成的文本窗口大小nw,计算出需要分割的文本窗口个数l=l/nw,其中l是文本的单词列表的总长度;
步骤1-2-1-2,根据如下公式计算每个文本窗口的开始位置tbj和结束位置tej:
tbj=nw×j+1,
tej=nw×(j+1),
其中j=1…l;
步骤1-2-1-3,依据每个文本窗口在文本单次列表中开始位置和结束位置依次生成分割后的文本窗口。
步骤2包括如下步骤:
步骤2-1,针对所有小说文本的两两配对,依次选取两条对应小说情感曲线的情感分数的时间序列s1…sn和t1…tm,sn表示时间序列s1…sn中第n个元素,tm表示时间序列t1…tm中第m个元素,n、m取值为自然数,设定窗口大小为w1,
步骤2-2,预置一个大小为n×m的矩阵dtw,矩阵方向从下往上再从左往右,其中dtw是动态时间规整(dynamictimewrapping)的英文简写,矩阵最左下角的值dtw[0,0]为0,其他所有值为正无穷;
步骤2-3,按照从下往上,从左往右的顺序,依次考察位于索引a,b的矩阵元素;矩阵的首行与首列不用考虑,如果a和b的差值大于w1也不用考虑,a取值范围为1~n,b取值范围为1~m。从该矩阵元素相邻的左边、下边、左下矩阵元素取最小值,加上时间序列对应元素sa,tb之间的距离,用这个新值替换当前考察的矩阵元素的值;
步骤2-4,返回dtw矩阵最右上角的值dtw[n,m],作为两个目标情感分数时间序列之间的动态时间规整距离;
步骤2-5,反复进行步骤2-1~步骤2-4,,直到得到所有文本的两两之间的动态时间规整距离,将这些动态时间规整距离排列成一个动态时间规整距离的矩阵。
本发明步骤3包括如下步骤:
步骤3-1,将训练文本的下载量数据取对数,得到训练数据对数下载量y。
步骤3-2,对于训练文本生成的动态规整距离矩阵k,计算出它的最小特征值λmin。
步骤3-3,输入噪声水平
步骤3-4,对于修正后的噪声水平
步骤3-4包括如下步骤:
步骤3-4-1,输入动态规整距离矩阵k、训练数据目标值小说文本的对数下载量y、修正后的噪声水平
步骤3-4-2,计算矩阵
步骤3-4-3,计算核函数k*的系数矩阵α:
α=l1t\(l1\y),
运算符号a\b代表求解线性方程ax=b当中的x;
步骤3-4-4,计算目标对数下载量f*:
f*即为下载量预测值。
本发明通过生成可以随文本长度而适应的情感曲线,解决了以往因为技术和后续目的限制,采样文本生成情感曲线时容易造成信息缺失和冗余问题。因此,这种生成曲线的方法能够更为准确的体现小说文本的情感变化。并且,其准确性也可以在后续任务中得到验证。
本发明在步骤3中解决了通过改进后的高斯过程将动态时间规整距离应用到相关的统计量预测中。这里所做的实际修正虽然看似步骤比较简单,但是经过了严格的理论证明和实验验证的。理论上可以证明,通过步骤3提出的修正方法,可以保证给出的矩阵一定是正定的,从而保证了核函数的可用性,解决了将动态规整距离应用到高斯过程乃至一般的核方法所面临的正定性问题。而1000组模拟实验表明,即便对于随机数据,动态规整距离矩阵含负特征值的比率也不超过5%;在含负特征值的情况中,最大正特征值与最小负特征值模的比例也都高于25;这说明在保证了可用性的前提下,该方法不会对原始的距离特性造成太大影响。并且,这种改进可以完美地融入原高斯过程的框架中,具有便利性。
本发明开创性地通过利用小说文本的情感曲线之间的关系来对小说相关统计量进行定量预测。具体地,本发明引入时间序列分析中动态规整距离描述小说文本情感曲线的拓扑结构,并利用改进后的高斯过程对小说下载量进行了回归分析。
本发明所公开的方法中所使用的改进高斯过程能够解决现有技术中的问题。这种改进经过理论证明合理性和实验证明可行性,简单易实施,而且可以完美融入原始的高斯过程框架中。
有益效果:本发明通过生成给定小说文本的情感曲线,为分析小说的情感变化走向提供了有益参考。本发明公开方法中所包含的改进的高斯过程,可以接受更为广泛的距离函数作为核函数,扩大了高斯过程的适用范围,并间接地为相关的预测提高了准确度。本发明利用小说文本的情感曲线之间的关系来给出目标文本的下载量预测,这是一种完全创新的方法,相较于传统方法给出的预测正相关性更强。本发明通过有关动态时间规整距离的比较,为小说的相关性推荐提供了另外一种全新的角度。
附图说明
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述或其他方面的优点将会变得更加清楚。
图1是本发明的流程图。
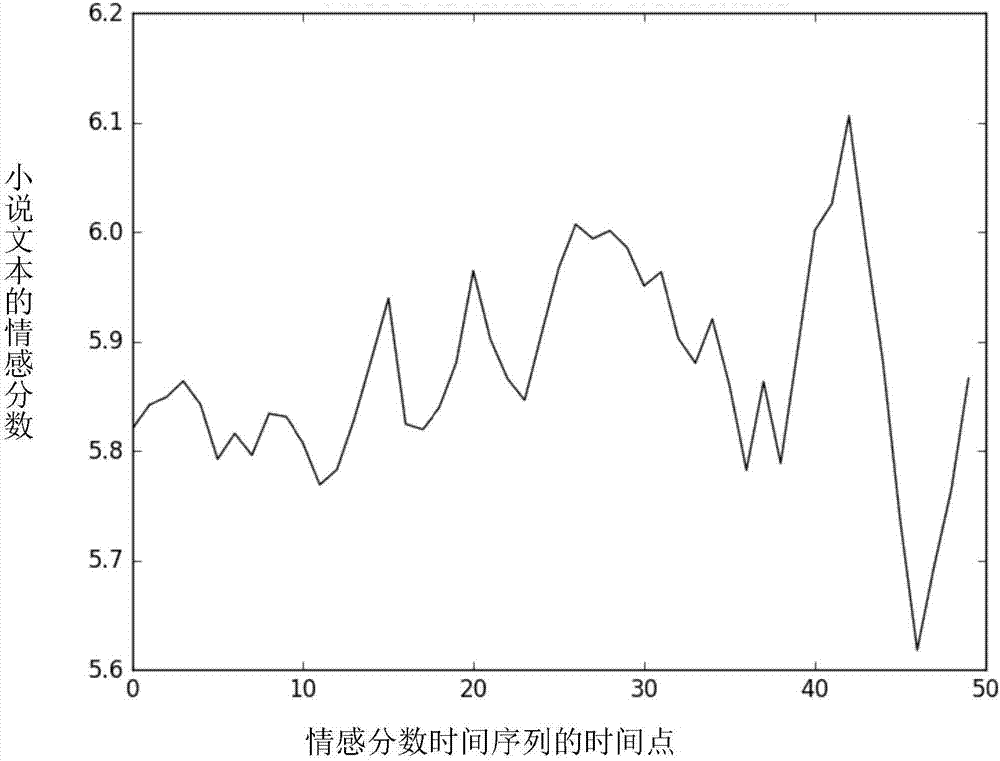
图2是本发明生成情感曲线。
图3是现有技术生成情感曲线。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
如图1所示,本发明公开了一种自动生成小说文本的情感曲线,并给出下载量预测和情感曲线最近似的小说推荐的方法。该方法的主要步骤如下:
步骤11,利用python的自然语言处理工具包spacy将小说的训练文本和目标文本分词,通过spacy的标注将标点符号去除,通过文本模版匹配的方式将人物称谓简称(如mr,mrs等)去除,得到文本的单词列表。
步骤12,将文本的单词列表按照文本窗口大小nw等分分割成文本窗口。
步骤13,通过labmt情感词汇表得到常用单词的情感分数映射表,形式是一个从单词到情感分数的映射函数havg(w)。
步骤14,统计文本窗口中出现在情感分数映射表中的单词和它们出现的频数。
步骤15,计算每个文本窗口t的情感分数,公式为:
其中,窗口出现在情感分数映射表中的单词分别为w1,w2,…,wn,窗口出现在表中的单词的总数为n,单词wi对应的情感分数为havg(wi),单词wi在文本窗口t中的对应的频数为fi(t)。
步骤16,将各个窗口的情感分数依次排列,生成一组情感分数的时间序列。
步骤17,计算步骤16中得到的情感分数时间序列的移动平均序列,即将原始情感分数时间序列的每一点上的情感分值替换为这个点相邻几个点的情感分值的平均值。该移动平均序列即作为小说的情感曲线。
步骤18,计算情感曲线的两两之间的动态规整距离矩阵。
步骤19,将训练文本的下载量数据取对数,得到训练数据预测值y。
步骤20,对于训练文本生成的动态规整距离矩阵k,计算出它的最小特征值λmin。
步骤21,输入噪声水平
步骤22,对于修正后的噪声水平
步骤23,根据动态规整距离矩阵,将对应小说文本按距离大小从小到大排序,输出距离最近的小说标题作为推荐。
本发明步骤12包括如下步骤:
步骤24:针对文本的单词列表和需要生成的文本窗口大小nw,计算出需要分割的文本窗口个数l=l/nw,其中l是文本的单词列表的总长度。
步骤25:根据如下公式计算每个文本窗口的开始位置tbj和结束位置tej:
tbj=nw×j+1,
tej=nw×(j+1),
其中j=1…l;
步骤26:依据每个窗口在文本单次列表中开始和结束位置依次生成分割后的文本窗口
本发明步骤18包括如下步骤:
步骤27,针对所有小说文本的两两配对,依次选取两条对应小说情感曲线的情感分数的时间序列s1…sn,t1…tm,sn表示时间序列s1…sn中第n个元素,tm表示时间序列t1…tm中第m个元素,n、m取值为自然数,设定窗口大小为w1,
步骤28,预置一个大小为n×m的矩阵dtw,矩阵方向从下往上再从左往右,其中dtw是动态时间规整(dynamictimewrapping)的英文简写,矩阵最左下角的值dtw[0,0]为0,其他所有值为正无穷。
步骤29,按照从下往上,从左往右的顺序,依次考察位于索引a,b的矩阵元素;矩阵的首行与首列不用考虑,如果a和b的差值大于w1也不用考虑,a取值范围为1~n,b取值范围为1~m。从该矩阵元素相邻的左边、下边、左下矩阵元素取最小值,加上时间序列对应元素sa,tb之间的距离,用这个新值替换当前考察的矩阵元素的值。
步骤30,返回dtw矩阵最右上角的值dtw[n,m],作为两个目标情感分数时间序列之间的动态时间规整距离。
步骤31,反复进行步骤27-30,直到得到所有文本的两两之间的动态时间规整距离。将这些动态时间规整距离排列成一个动态时间规整距离的矩阵。
本发明步骤22包括如下步骤:
步骤32,输入动态规整距离矩阵k(也就是高斯过程核函数),训练数据目标值小说文本的对数下载量y,噪声水平
步骤33,计算矩阵
步骤34,计算核函数k*的系数矩阵α:
α=l1t\(l1\y),
运算符号a\b代表求解线性方程ax=b当中的x。
步骤35,计算目标对数下载量f*:
实施例
本发明所用的算法全部由python语言编写实现。实验配置为intel(r)core(tm)i5-4200m处理器,主频为2.5ghz,内存为4g,python版本3.5.3,发行版anaconda3。
实验数据准备如下:1729篇来自古登堡计划的英文小说文本,文本单词总个数均在10000以上,文本月下载量均在100以上;通过古登堡计划网站得到的小说相关统计数据:包括小说名,下载量。
实施例1
本实施例在生成小说文本的情感曲线实验如下:
11.输入训练文本语料和测试文本语料,预处理后得到文本单词列表。
12.利用步骤11得到的单词列表生成文本的情感曲线,同时按照前人的方法生成对比的情感曲线作为对比。
实施例2
本实施例在通过小说文本的情感曲线比较给出下载量预测实验如下:
11.输入训练文本语料和测试文本语料,预处理后得到文本单词列表。
12.利用步骤11得到的单词列表生成文本的情感曲线。
13.计算情感曲线动态时间规整距离矩阵。
14.通过距离矩阵和改进的高斯过程给出测试文本的对数下载量。
实施例3
本实施例在通过小说文本的情感曲线比较给出相关文本推荐实验如下:
11.输入训练文本语料和测试文本语料,预处理后得到文本单词列表。
12.利用步骤11得到的单词列表生成文本的情感曲线。
13.计算情感曲线动态时间规整距离矩阵。
14.通过动态时间规整距离矩阵给相关文本进行排序并按照距离从小到大推荐。
本发明的目的是为了改进小说文本的情感曲线生成方法并作相关预测推荐,需要能够给出更为准确地体现原始文本情感变化特性的,并提升预测下载量的正相关性。为了验证本发明有效性,本发明和以往生成情感曲线的方法和若干传统模型进行了比较。
本发明生成情感曲线如图2所示,对比以往方法生成情感曲线如图3所示,这两张图的纵轴表示小说文本的情感分数,横轴表示对应采样窗口在文本中的位置(也就是情感分数时间序列的时间点)。以上两图均生成的是《爱丽丝梦游奇境》(alice’sadventuresinwonderland)这篇小说的情感曲线。可以看出尽管本发明使用了更少的采样窗口(时间解析度),但却更好地体现了小说文本的情感变化。以《爱丽丝梦游奇境》为例,在文本80%后原文情感急转直下,在国王和王后的审判中表现出了大量的负面情感,随后梦醒归于平静。本发明很好地表现出了这一文本的情感变化特征;而以往方法只能看出文本情感回归均值的情况。同时需要注明的是,这里关于小说文本的情感曲线的准确度提升是和后续模型预测的相关系数的提升是有因果关系且前后一致的,准确的绘制小说文本的情感曲线是为了更好地提升预测下载量这一客观数据。
表1是通过改进高斯过程给出目标文本下载量预测的对比:
表1
本发明的成果数据在最后一行。可以看出本发明相较于传统的纯文本特征和前人给出的曲线生成方法而言,下载量预测结果有更高的正相关性。
表2是根据情感曲线相似性做推荐结果例:
表2
可以看出,在表2中,对于仅仅依靠情感曲线做推荐的本发明来说,本发明成功给出原小说的另一篇修订文本表示作为最接近推荐小说,说明了本发明的通过情感曲线推荐的合理性;而且,表2也给出了在情感曲线方面比较接近的小说,说明了本发明的实用性。
本发明提出了一种自动生成小说文本情感曲线并预测推荐的方法,这种方法生成的情感曲线更能准确的反映文本情感变化状况。本发明提出的下载量预测方法是一种创新性的方法,着眼点不同于以往,在于关注利用小说文本总体情感变化;该方法在预测独立新文本的实际下载量时相对于传统的文本特征方法可以取得更高的正相关性。本发明推荐的情感曲线最接近小说文本也具有合理性和独特性,给有关小说文本的推荐任务提供了一个全新的角度。
本发明提供了一种自动生成小说文本情感曲线并预测推荐的方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
- 还没有人留言评论。精彩留言会获得点赞!