一种基于KSP算法的资源描述框架查询方法和系统与流程
本发明涉及语义网数据检索技术,尤其涉及一种基于ksp算法的资源描述框架查询方法和系统。
背景技术:
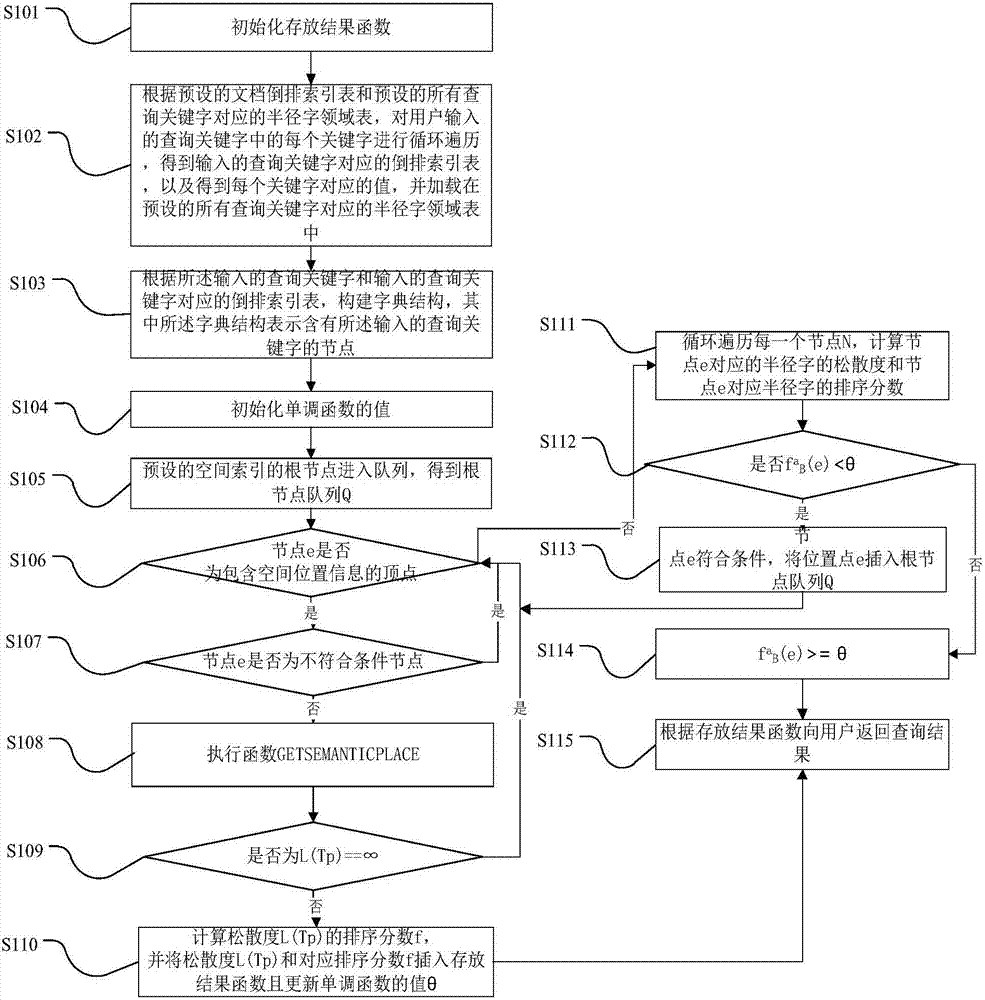
:资源描述框架(resourcedescriptionframework,rdf)是用于表达web资源的元数据的通用框架,它使用统一资源描述符(uri)来表示事物,用简单的属性和属性值来描述事物,rdf把数据表示为<主体,谓词,客体>,其中用于标识事物为主体,用于区分主语对象各个不同属性的那部分为谓词,陈述中用于区分各个属性的值的部分叫做客体。因此rdf知识库也可以看做是一个有向图,其中顶点是资源、性质、文字、描述,边是谓词用来描述顶点之间的关系。rdf知识库可以建模成一个有向图,其中顶点表示实体,边表示实体之间关系。在rdf图中我们称存在空间坐标的顶点为位置顶点(places)。我们用v表示rdf图中的任意顶点,用p表示位置顶点。每一个rdf三元组对应一条从一个实体(主体)到另一个实体(客体)的有向边。为了实现关键字的搜索,每一个实体都对应一个文档,用ψ表示,该文档是从该实体对应的资源、性质、文字、描述中提取的关键字组成。语义位置(semanticplace)是rdf图的一颗子树,该子树以位置顶点p为根,且包含所有的查询关键字。从一个给定的位置顶点p出发可以构造多个语义位置。现有的rdf数据是使用结构化查询语言(structuredquerylanguage)进行访问,如sparql(simpleprotocolandrdfquerylanguage)。但是标准的sparql查询需要用户完全了解语言本身,并且了解数据域。因此sparql限制数据访问主要是数据域专家,因为它对普通用户是不友好的,也就是说对rdf数据进行查询时,需要用户懂得查询语言和rdf语义,否则无法进行查询。技术实现要素:本发明旨在解决现有技术中需要用户懂得查询语言和rdf语义否则无法进行查询的技术问题,提供一种基于ksp算法的资源描述框架查询方法和系统。本发明的实施例提供一种基于ksp算法的资源描述框架查询方法,用于利用ksp算法在rdf图上搜索查询关键字的语义位置,所述查询方法包括以下步骤:初始化存放结果函数hk,其中存放结果函数hk用于保存符合条件的语义位置qsp,符合条件的语义位置qsp为包含所有查询关键字的子树,k为符合条件的语义位置qsp的数量;根据预设的文档倒排索引表和预设的所有查询关键字对应的半径字领域表,对用户输入的查询关键字中的每个关键字进行循环遍历,得到输入的查询关键字对应的倒排索引表,以及得到每个关键字对应的值,并加载在预设的所有查询关键字对应的半径字领域表中;根据所述输入的查询关键字和输入的查询关键字对应的倒排索引表,构建字典结构,其中所述字典结构表示含有所述输入的查询关键字的节点;初始化单调排序函数的值θ,其中单调排序函数表示对根据输入的查询关键字查找的多个最紧凑的符合条件的语义位置进行排序,最紧凑的符合条件的语义位置表示为以p为根节点的松散度最小的符合条件的语义位置;预设的空间索引中根节点进入队列,得到位置节点队列q;根据输入的查询关键字和位置节点队列q,遍历预设的空间索引得到节点e,并对节点e进行判断;当节点e为包含空间位置信息的顶点,判断e是否为不符合条件节点,若e为不符合条件节点则结束本次循环,进入下次循环,当节点e为包含空间位置信息的顶点,且判断节点e不是不符合条件节点时,则执行函数getsemanticplace,得到符合条件的语义位置的子树tp和子树tp的松散度值l(tp),并判断是否为l(tp)==+∞,如果是,则结束本次循环,如果否,计算松散度值l(tp)的排序分数f,并将松散度值l(tp)和对应排序分数f插入存放结果函数hk且更新单调排序函数的值θ;当节点e为节点n时,循环遍历节点n下的每一个节点,计算n下每个节点e对应的半径字的松散度值和对应半径字的排序分数当时,则把对应节点e插入位置节点队列q并返回所述根据输入的查询关键字和位置节点队列q,在预设的空间索引中查找节点e的步骤,直到根据存放结果函数hk向用户返回查询结果。本发明还提供一种实施例的基于ksp算法的资源描述框架查询系统,用于利用ksp算法在rdf图上搜索查询关键字的语义位置,所述查询系统包括:第一初始化模块,用于初始化存放结果函数hk,其中存放结果函数hk用于保存符合条件的语义位置qsp,符合条件的语义位置qsp为包含所有查询关键字的子树,k为符合条件的语义位置qsp的数量;循环遍历模块,用于根据预设的文档倒排索引表和预设的所有查询关键字对应的半径字领域表,对用户输入的查询关键字中的每个关键字进行循环遍历,得到输入的查询关键字对应的倒排索引表,以及得到每个关键字对应的值,并加载在预设的所有查询关键字对应的半径字领域表中;构建模块,用于根据所述输入的查询关键字和输入的查询关键字对应的倒排索引表,构建字典结构,其中所述字典结构表示含有所述输入的查询关键字的节点;第二初始化模块,用于初始化单调排序函数的值θ,其中单调排序函数表示对根据输入的查询关键字查找的多个最紧凑的符合条件的语义位置进行排序,最紧凑的符合条件的语义位置表示为以p为根节点的松散度最小的符合条件的语义位置;生成队列模块,用于预设的空间索引的根节点进入队列,得到位置节点队列q;查找循环模块,用于根据输入的查询关键字和位置节点队列q,遍历预设的空间索引得到节点e并对节点e进行判断;顶点处理模块,用于当节点e为包含空间位置信息的顶点时,判断节点e是否为不符合条件节点,若节点e为不符合条件节点则结束本次循环,进入下次循环,当节点e为包含空间位置信息的顶点,且节点e不是不符合条件节点,则执行函数getsemanticplace,得到符合条件的语义位置的子树tp和子树tp的松散度值l(tp),并判断是否为l(tp)==+∞,如果是,则结束本次循环,如果否,计算松散度值l(tp)的排序分数f,并将松散度值l(tp)和对应排序分数f插入存放结果函数hk且更新单调排序函数的值θ;节点处理模块,用于节点e为节点n时,循环遍历节点n下的每一个节点,计算n下每个节点e对应的半径字的松散度值和对应半径字的排序分数当时,则把对应节点e插入位置节点队列q并进入查找循环模块,直到输出结果模块,用于根据存放结果函数hk向用户返回查询结果。本发明还提供一种实施例的计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述方法的步骤。本发明的技术方案与现有技术相比,有益效果在于:该ksp算法对用户是友好的,用户不需要掌握专门的查询语言,只需要输入查询的关键字,算法将返回在查询位置附近,包含所有关键字的子树。附图说明图1是本发明基于ksp算法的资源描述框架查询方法一种实施例的流程图。图2是本发明基于ksp算法的资源描述框架查询方法另一种实施例的流程图。图3是本发明文档倒排索引表一种实施例的示意图。图4是本发明所有查询关键字对应的半径字领域表的创建方法一种实施例的流程图。图5是本发明基于ksp算法的资源描述框架查询系统一种实施例的结构示意图。具体实施方式下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。具体的,ksp算法中的查询序列q由三部分组成,包括查询位置q.λ,查询关键字q.ψ,和语义位置数量k。具体的,对于一个给定ksp查询序列q,和一个rdf图g=<v,e>,其中v表示rdf图的顶点,e表示rdf图的边,符合条件的语义位置qsp是一棵树tp=<v',e'>,其中tp的根节点为p,并且满足为了方便介绍,用<p,(v1,v2...)>表示一个语义位置,其中p是根节点,(v1,v2...)表示其他所有的顶点。给定一个查询序列q可能存在多个符合条件的语义位置qsp,符合条件的语义位置qsp有相同的根节点p,但(v1,v2...)不同。因此还需要计算tp的松散度l(tp)。具体的,对于一个给定qsptp=<v',e'>,令表示从根节点p到包含关键字ti的节点v的最短距离,其中ti∈q.ψ,d(p,v)为p到v的最短距离,所以tp的松散度值l(tp)为:如果松散度越小,根节点和其他节点覆盖了所有输入的查询关键字的相关性越高。因此对于一个给定的位置顶点p,以位置顶点p为根节点,我们要找的是最紧凑的符合条件的语义位置tqsp,表示以p为根节点的松散度值最小的qsp。另外,在rdf图上,对于一个给定的ksp的查询序列q,查询结果为k个tqsp,且这k个tqsp的分数(rankingscore)是所有tqsp中最小的,松散度l(tp)的排序分数f,用函数f(l(tp),s(q,p))表示,l(tp)为子树tp松散度,s(q,p)为q.λ查询位置和p之间的欧式距离。函数f(l(tp),s(q,p))可以为任意的单调排序函数,f(l(tp),s(q,p))=l(tp)×s(q,p)。本发明一个实施例的基于ksp算法的资源描述框架查询方法,用于利用ksp算法在rdf图上搜索查询关键字的语义位置,如图1所示,所述构造方法包括以下步骤:步骤s101,初始化存放结果函数hk,其中存放结果函数hk用于保存符合条件的语义位置qsp,符合条件的语义位置qsp为包含所有查询关键字的子树,k为符合条件的语义位置qsp的数量;步骤s102,根据预设的文档倒排索引表和预设的所有查询关键字对应的半径字领域表,对用户输入的查询关键字中的每个关键字进行循环遍历,得到输入的查询关键字对应的倒排索引表,以及得到每个关键字对应的值,并加载在预设的所有查询关键字对应的半径字领域表中;步骤s103,根据所述输入的查询关键字和输入的查询关键字对应的倒排索引表,构建字典结构,其中所述字典结构表示含有所述输入的查询关键字的节点;步骤s104,初始化单调排序函数的值θ,其中单调排序函数表示对根据输入的查询关键字查找的多个最紧凑的符合条件进行排序,最紧凑的符合条件的语义位置表示为以p为根节点的松散度最小的符合条件的语义位置;步骤s105,预设的空间索引的根节点进入队列,得到位置节点队列q;步骤s106,根据输入的查询关键字和位置节点队列q,遍历预设的空间索引得到节点e,并对节点e进行判断,当节点e为包含空间位置信息的顶点,进入步骤s107,当节点e为节点n,进入步骤s111;步骤s107,判断节点e是否为不符合条件节点,如果是,则结束本次循环,进入下次循环即返回步骤s106,如果否,进入步骤s108;步骤s108,执行函数getsemanticplace,得到符合条件的语义位置的子树tp和子树tp的松散度值l(tp);步骤s109,判断是否为l(tp)==+∞,如果是,结束本次循环即返回步骤s106,如果否,进入步骤s110;步骤s110;计算松散度值l(tp)的排序分数f,并将松散度值l(tp)和对应排序分数f插入存放结果函数hk且更新单调排序函数的值θ,进入步骤s115;步骤s111,循环遍历每一个节点n,计算节点e对应的半径字的松散度值和节点e对应半径字的排序分数步骤s112,判断是否如果是,进入步骤s113,如果否,进入步骤s114;步骤s113,当时,节点e符合条件,将对应的节点e插入位置节点队列q,并返回s106;步骤s114,进入步骤s115;步骤s115,根据存放结果函数hk向用户返回查询结果,也就是说,向用户返回包含所有输入的查询关键字的子树,并且该子树的根节点靠近查询位置。步骤s101,具体为,初始化hk中的元素按照f(l(tp),s(q,p))排序;hk中存放的是qsp,即存放最终的结果,其中qsp为包含所有查询关键字的子树。步骤s102,具体为:循环遍历查询关键字q.ψ中的每个关键字ti,做一下处理:首先从预设的文档倒排索引表i中,查找关键字ti对一个的值,并保存,接着从预设的所有查询关键字对应的半径字领域表即α-radiuswordneighborhood表iα中,加载关键字ti所对应的值,并保存。步骤s103,具体为,建立一个字典结构mq.ψ,结构为{节点,(t1,t2,...)}表示含有查询关键字的节点。步骤s104,具体为,初始化θ=+∞;θ为rankingscoref的值。在步骤s105中,对于预设的空间索引是在查询之前建立好的,所以用于输入不同的查询关键字对应的空间索引是相同的。另外,位置节点队列q中保存多个位置节点,所述多个位置节点是符合查询要求的,其中位置节点包含位置信息,而普通节点不包含位置信息。步骤s106,具体为:查找循环条件为e=getnext(q,r,q),函数getnext表示在r-tree上使用增强nn算法(incrementalnnalgorithm)查找节点e,若节点e是位置顶点,即包含空间位置信息的顶点,则进入步骤s107,若节点e不是位置顶点则进入步骤s111。当节点e是位置顶点,做以下处理:首先若节点e不符合删除规则1,则跳出本次循环,进入下次循环;再次回到步骤s106,开始新的循环;接着,执行函数getsemanticplace,得到tp的值;若l(tp)==+∞,说明没有找到,则跳出本次循环,进入下次循环;接着,计算l(tp)的rankingscore,并将l(tp)和对应的rankingscoref插入到hk中,即hk.add(tp,f);最后,更新θ的值,进入步骤s115。当节点e是节点n时,循环遍历n下的每一个节点e,做以下操作;针对每个节点:首先,计算节点e的α-boundonthelooseness删除规则2,接着计算节点e的α-boundontherankingscore删除规则3,最后根据删除规则2,3可以判定,当是,对应的节点e符合条件,可以插入队列q,即toq,直到进入步骤s115。具体的,所述存放结果函数hk中保存符合条件的语义位置qsp按照最紧凑的符合条件的语义位置的排序分数大小进行排序。在具体实施中,步骤s108,所述执行函数getsemanticplace,如图2所示,具体包括:步骤s201,初始化子树tp,其中,tp表示以p为顶点,包含所有查询关键字的一颗子树;步骤s202,初始化子树tp的松散度值l(tp)以使l(tp)=1;步骤s203,查询的关键字q.ψ保存到数字集b中;步骤s204,从顶点p开始使用bfs(breadth-first-search)方式遍历rdf图且数字集b不为空;步骤s205,把bfs方式得到的节点v添加到子树tp中;步骤s206,在所述字典结构中查找节点v包含的查询关键字;步骤s207,判断节点v包含的查询关键字和数字集b的交集是否为空,如果否,进入步骤s208,如果是,进入步骤s209;步骤s208,如果否,输出l(tp)=+∞和tp=null;步骤s209,如果是,根据节点v包含的查询关键字和数字集b的交集中元素的个数以及节点v和顶点p之间的距离的得到子树tp的松散度值l(tp);步骤s210,从数字集b中删除节点v包含的查询关键字和数字集b的交集得到当前的数字集b;步骤s211,当前的数字集b是否为空,如果否,返回步骤s204,如果是,进入步骤s208,也就是说,直到数字集b为空,输出l(tp)=+∞和tp=null。具体的,步骤s209的计算公式如下:l(tp)+=|b∩v.ψq|×d(p,v);其中,|b∩v.ψq|表示b和v.ψq的交集中元素的个数,d(p,v)为位置顶点p到节点v的最短距离。也就是说,ksp算法通过执行sp和getsemanticplace两个函数以输出输入的查询关键字的返回结果,sp函数内部调用getsemanticplace函数,函数sp(q,r,g,i,ia)的内容具体为,步骤s101至步骤s115的过程。函数getsemanticplace(q.ψ,p,g,mq.ψ)的内容具体为,步骤s201至步骤s211的过程,该函数的作用是输出tp和l(tp),其中q表示查询序列,r表示预设的空间索引,g表示rdf图,i表示预设的文档倒排索引表,iα表示预设的所有查询关键字对应的半径字领域表。在具体实施中,所述查询方法还包括以下步骤:创建预设的空间索引。具体的,在步骤s101之前,创建预设的空间索引。所述创建预设的空间索引的步骤,具体为:从rdf数据中提取含有坐标信息的数据,得到预设的空间索引。因为rdf图数据比较大,为了提高查询的速度,首先从rdf数据中提取含有坐标信息的数据,创建预设的空间索引r-tree使得查询的速度可以得到有效的提高。在具体实施中,所述查询方法还包括以下步骤:对每个节点的文档中的关键字建立倒排索引以得到预设的文档倒排索引表,倒排索引表的格式为(关键字,节点),具体的,在步骤s101之前,对每个节点的文档中的关键字建立倒排索引以得到预设的文档倒排索引表i,文档倒排索引表的格式为(关键字,节点),如图3所示。在具体实施中,如图4所示,所述查询方法还包括以下步骤:步骤s401,从顶点p开始使用bfs方式遍历rdf图;步骤s402,当遍历到节点v时,遍历节点v的文档中的关键字t,若(t,d(p,v))在wn(p)中没有出现过,则将(t,d(p,v))添加到预设的所有查询关键字对应的半径字领域表中,其中wn(p)表示从p到每一个查询关键字ti的最短距离的集合{(ti,dg(p,ti))},dg(p,ti)≤α表示从根节点p到包含查询关键字ti的顶点的最短的距离,(t,d(p,v))表示顶点v对应的文档信息,包含查询关键字t;步骤s403,当得到所有的叶子节点的半径字领域后,按照从叶子节点到非叶子节点的顺序,计算wn(n)的值,wn(n)表示非叶子节点n下所有的位置顶点{pj}对应的wn(pj)的联合,非叶子节点n下面包含一系列的位置顶点{pj};步骤s404,对于非叶子节点n,{ei}表示n下的节点,wn(n)初始化为空,若(t,dg(ei,t))在wn(n)没有相应的值则将(t,dg(ei,t))添加到预设的所有查询关键字对应的半径字领域表中,若有值则将所述半径字邻域表中非叶子节点n对应的值更新为min(dg(n,t),dg(ei,t)),其中,(t,dg(ei,t))为关键字t在所述半径字邻域表中对应的值。具体的,顶点p可以是根节点,如果是根节点,则包含位置信息。顶点p可以是包含位置信息的节点,所以它是包含位置信息的所有可能节点,包括根节点。另外,所述预设的所有查询关键字对应的半径字领域表:是根据树建立起来的,其中树中的有叶子节点p,和非叶子节点n,首先算叶子节点的值,然后算非叶子节点的值,所以是叶子节点到非叶子节点,是一种自下到上的顺序。比如,以下所示表格为所述预设的所有查询关键字对应的半径字领域表。q.ψabbey...ancientcatholicromanhistory...dg(p1,ti)0...111-...dg(p2,ti)-...-001...dg(n,ti)0...1001...具体的,开始时初始化,使得所述预设的所有查询关键字对应的半径字领域表为空,步骤s401-步骤s404就是填充这张表。其中:abbey,ancient,catholic,roman,history为所述半径字领域表中关键字。(t,d(p,v)):表示顶点v的文档信息中,有查询关键字t,则对应的值就会插入到半径字邻域表中。(t,dg(ei,t)):表示关键字t,在半径字邻域表中对应的值。此处的ei就是上表中的p1,p2,即dg(ei,t)就是表中dg(p1,ti)对应的值。min(dg(n,t),dg(ei,t)):就是表中dg(n,ti)的值去掉所在列的最小值。比如,catholic所在的列,有值1,0所以min(dg(n,t),dg(ei,t))的值为0,也就是dg(n,ti)的值。由于在根据ksp算法构建tqsp的时候可能会遇到以下两种情况:(i)遍历完这个图后仍未找到包含输入查询关键字的tp,(ii)找到了tp,但是tp的排序分数f大于θ(当前已经找到的第k个tp的排序分数)。其中,tqsp为松散度最小的qsp针对情况。对于(i)的情况,在rdf图中,让表示以p为根节点子树不能包含所有的查询关键字。对于给定的查询关键字序列q.ψ,若此时的p节点为不符合条件节点。针对(ii)情况,为了提高算法的效率,定义wn(p),对位置顶点p,它的wn(p)表示从p到每一个查询关键字ti的最短距离的集合{(ti,dg(p,ti))},其中dg(p,ti)≤α,表示从根节点p到包含查询关键字ti的顶点的最短的距离。根据上述中对一个点的字邻域描述,我们可以得出对节点n的字邻域的定义,如对r-tree中的顶点n。定义wn(n),对于r-tree的节点n下面包含一系列的位置顶点{pj},wn(n)为一系列的{(ti,dg(n,ti))},其中wn(n)是节点n下所有的位置顶点{pj}对应的wn(pj)的联合,其中对于每个关键字ti,显然dg(n,ti)≤α。根据定义wn(p)和定义wn(n),可以创建节点对应的半径字领域表iα即预设的所有查询关键字对应的半径字领域表(α-radiuswordneighborhood表),用于提高算法效率。进一步,为了提高算法的效率,引理1:由于wn(p)表示位置定点p的半径字领域(α-radiuswordneighborhood)。对于给定的查询关键字q.ψ={t1,...,tj,...tm},为了不失一般性,假设第j个关键字在wn(p)已经有值,则以p为根节点的tp的tqsp的半径字松散度(α-boundonthelooseness)可表示为并且引理2:由于表示以p为根节点的tp的tqsp的半径字松散度,则对于给定的查询序列q对应的tp的半径字排序分数(α-boundontherankingscore)可表示为且引理3:由于wn(n)表示顶点n的半径字领域(α-radiuswordneighborhood),查询关键字q.ψ={t1...,tj...,tm},为了不失一般性,假设第j个关键字在wn(n)中已经有相应的值,则在n节点下以p为根节点的tp对应的所有的tqsp可表示为并且引理4:由于表示以在节点n下以p为根节点的tp的tqsp对应的半径字松散度,对于给定的查询序列q,则在节点n下以p为根节点的所有的tp的半径字松散度可表示为其中s(q,n)表示q和n之间最小的空间距离,且根据引理2我们得出删除规则2,根据引理4得出删除规则3,来提高算法的效率,具体删除规则如下:删除规则2:对于给定的查询序列q,θ表示第k个候选tqsp的rankingscore。表示以p为根节点的tp的tqsp的α-boundontherankingscore。当时tp不是我们要查的结果,p可以被删除。删除规则3:对于给定的查询序列q,θ表示第k个候选tqsp的rankingscore,表示节点n下以p为根节点的tp的tqsp的α-boundontherankingscore,若则在n节点下任何节点都不满足条件,n可以被删除。基于ksp算法的资源描述框架查询方法,主要是实现图上关键字的搜索和rdf数据上关键字的搜索:由于关键字检索对用户的友好性,不仅用户检索网络数据,而且用于检索xml文档,关系型数据库,和图。传统上图的搜索算法将查询转化为在特征空间上的搜索,例如路径,频繁模式,和序列。这种搜索算法更多的关注图的结构而不是图的语义内容。图上关键字的查询通过利用内容和链接结构两者来确定图中一组密集链接的节点。由于这两种信息的重新实施,可提高结果的整体质量。而rdf数据上关键字的搜索,由于rdf数据是一种特殊类型的图数据也可以提供查询的效率。本发明还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述方法的步骤。本发明的一实施例中提供一种基于资源描述框架的ksp算法查询系统,用于利用ksp算法在rdf图上搜索查询关键字的语义位置,如图5所示,所述查询系统包括:第一初始化模块51,用于初始化存放结果函数hk,其中存放结果函数hk用于保存符合条件的语义位置qsp,符合条件的语义位置qsp为包含所有查询关键字的子树,k为符合条件的语义位置qsp的数量;循环遍历模块52,用于根据预设的文档倒排索引表和预设的所有查询关键字对应的半径字领域表,对用户输入的查询关键字中的每个关键字进行循环遍历,得到输入的查询关键字对应的倒排索引表,以及得到每个关键字对应的值,并加载在预设的所有查询关键字对应的半径字领域表中;构建模块53,用于根据所述输入的查询关键字和输入的查询关键字对应的倒排索引表,构建字典结构,其中所述字典结构表示含有所述输入的查询关键字的节点;第二初始化模块54,用于初始化单调排序函数的值θ,其中单调排序函数表示对根据输入的查询关键字查找的多个最紧凑的符合条件的语义位置进行排序,最紧凑的符合条件的语义位置表示为以p为根节点的松散度最小的符合条件的语义位置;生成队列模块55,用于预设的空间索引的根节点进入队列,得到位置节点队列q;查找循环模块56,用于根据输入的查询关键字和位置节点队列q,遍历预设的空间索引得到节点e,并对节点e进行判断;顶点处理模块57,于当节点e为包含空间位置信息的顶点时,判断节点e是否为不符合条件节点,若节点e为不符合条件节点则结束本次循环,进入下次循环,当节点e为包含空间位置信息的顶点,且节点e不是不符合条件节点,则执行函数getsemanticplace,得到符合条件的语义位置的子树tp和子树tp的松散度值l(tp),并判断是否为l(tp)==+∞,如果是,则结束本次循环,如果否,计算松散度值l(tp)的排序分数f,并将松散度值l(tp)和对应排序分数f插入存放结果函数hk且更新单调排序函数的值θ;节点处理模块58,用于节点e为节点n时,循环遍历节点n下的每一个节点,计算n下每个节点e对应的半径字的松散度值和对应半径字的排序分数当时,则把对应节点e插入位置节点队列q并进入查找循环模块,直到输出结果模块59,用于根据存放结果函数hk向用户返回查询结果。具体的,所述存放结果函数hk中保存符合条件的语义位置qsp按照最紧凑的符合条件的语义位置的排序分数大小进行排序。在具体实施中,顶点处理模块57还用于:初始化子树tp,其中,tp表示以p为顶点,包含所有查询关键字的一颗子树;初始化子树tp的松散度l(tp)以使l(tp)=1;查询的关键字q.ψ保存到数字集b中;从顶点p开始使用bfs(breadth-first-search)方式遍历rdf图且数字集b不为空;把bfs方式得到的节点v添加到子树tp中;在所述字典结构中查找节点v包含的查询关键字;判断节点v包含的查询关键字和数字集b的交集是否为空;如果否,输出l(tp)=+∞和tp=null;如果是,根据节点v包含的查询关键字和数字集b的交集中元素的个数以及节点v和顶点p之间的距离的,得到子树tp的松散度值l(tp);从数字集b中删除节点v包含的查询关键字和数字集b的交集得到当前的数字集b;当前的数字集b是否为空,如果否,执行从顶点p开始使用bfs(breadth-first-search)方式遍历rdf图且数字集b不为空的内容;如果是,输出l(tp)=+∞和tp=null,也就是说,直到数字集b为空,输出l(tp)=+∞和tp=null。具体的,根据节点v包含的查询关键字和数字集b的交集中元素的个数以及节点v和顶点p之间的距离的得到子树tp的松散度l(tp)的值计算公式如下:l(tp)+=|b∩v.ψq|×d(p,v);其中,|b∩v.ψq|表示b和v.ψq的交集中元素的个数,d(p,v)为顶点p到节点v的最短距离。在具体实施中,所述查询系统还包括创建模块,用于创建预设的空间索引。具体的,创建模块还用于:从rdf数据中提取含有坐标信息的数据,得到预设的空间索引。因为rdf图数据比较大,为了提高查询的速度,首先从rdf数据中提取含有坐标信息的数据,创建预设的空间索引r-tree使得查询的速度可以得到有效的提高。在具体实施中,创建模块还用于:对每个节点的文档中的关键字建立倒排索引以得到预设的文档倒排索引表,倒排索引表的格式为(关键字,节点),如图3所示。在具体实施中,如图4所示,创建模块还用于:从位置顶点p开始使用bfs方式遍历rdf图;当遍历到节点v时,遍历节点v的文档中的关键字t,若(t,d(p,v))在wn(p)中没有出现过,则将(t,d(p,v))添加到预设的所有查询关键字对应的半径字领域表中,其中wn(p)表示从p到每一个查询关键字ti的最短距离的集合{(ti,dg(p,ti))},dg(p,ti)≤α表示从根节点p到包含查询关键字ti的顶点的最短的距离,(t,d(p,v))表示顶点v对应的文档信息,包含查询关键字t;得到所有的叶子节点的半径字领域后,按照从叶子节点到非叶子节点的顺序,计算wn(n)的值,wn(n)表示非叶子节点n下所有的位置顶点{pj}对应的wn(pj)的联合,非叶子节点n下面包含一系列的位置顶点{pj};对于非叶子节点n,{ei}表示n下的节点,wn(n)初始化为空,若(t,dg(ei,t))在wn(n)没有相应的值则将(t,dg(ei,t))添加到预设的所有查询关键字对应的半径字领域表中,若有值则将所述半径字邻域表中非叶子节点n对应的值更新为min(dg(n,t),dg(ei,t)),其中,(t,dg(ei,t))为关键字t在所述半径字邻域表中对应的值。具体的,顶点p可以是根节点,如果是根节点,则包含位置信息。顶点p可以是包含位置信息的节点,所以它是包含位置信息的所有可能节点,包括根节点。另外,所述预设的所有查询关键字对应的半径字领域表:是根据树建立起来的,其中树中的有叶子节点p,和非叶子节点n,首先算叶子节点的值,然后算非叶子节点的值,所以是叶子节点到非叶子节点,是一种自下到上的顺序。比如,以下所示表格为所述预设的所有查询关键字对应的半径字领域表。q.ψabbey...ancientcatholicromanhistory...dg(p1,ti)0...111-...dg(p2,ti)-...-001...dg(n,ti)0...1001...具体的,开始时初始化,使得所述预设的所有查询关键字对应的半径字领域表为空,创建模块的工作过程就是填充这张表。其中:abbey,ancient,catholic,roman,history为所述半径字领域表中关键字。(t,d(p,v)):表示顶点v的文档信息中,有查询关键字t,则对应的值就会插入到半径字邻域表中。(t,dg(ei,t)):表示关键字t,在半径字邻域表中对应的值。此处的ei就是上表中的p1,p2,即dg(ei,t)就是表中dg(p1,ti)对应的值。min(dg(n,t),dg(ei,t)):就是表中dg(n,ti)的值去掉所在列的最小值。比如,catholic所在的列,有值1,0所以min(dg(n,t),dg(ei,t))的值为0,也就是dg(n,ti)的值。由于在根据ksp算法构建tqsp的时候可能会遇到以下两种情况:(i)遍历完这个图后仍未找到包含输入查询关键字的tp,(ii)找到了tp,但是tp的排序分数f大于θ(当前已经找到的第k个tp的排序分数)。其中,tqsp为松散度最小的qsp针对情况。对于(i)的情况,在rdf图中,让表示以p为根节点子树不能包含所有的查询关键字。对于给定的查询关键字序列q.ψ,若此时的p节点为不符合条件节点。针对(ii)情况,为了提高算法的效率,定义wn(p),对位置顶点p,它的wn(p)表示从p到每一个查询关键字ti的最短距离的集合{(ti,dg(p,ti))},其中dg(p,ti)≤α,表示从根节点p到包含查询关键字ti的顶点的最短的距离。根据上述中对一个点的字邻域描述,我们可以得出对节点n的字邻域的定义,如对r-tree中的顶点n。定义wn(n),对于r-tree的节点n下面包含一系列的位置顶点{pj},wn(n)为一系列的{(ti,dg(n,ti))},其中wn(n)是节点n下所有的位置顶点{pj}对应的wn(pj)的联合,其中对于每个关键字ti,显然dg(n,ti)≤α。根据定义wn(p)和定义wn(n),可以创建节点对应的半径字领域表iα即预设的所有查询关键字对应的半径字领域表(α-radiuswordneighborhood表),用于提高算法效率。进一步,为了提高算法的效率,引理1:由于wn(p)表示顶点p的半径字领域(α-radiuswordneighborhood)。对于给定的查询关键字q.ψ={t1,...,tj,...tm},为了不失一般性,假设第j个关键字在wn(p)已经有值,则以p为根节点的tp的tqsp的半径字松散度(α-boundonthelooseness)可表示为并且引理2:由于表示以p为根节点的tp的tqsp的半径字松散度,则对于给定的查询序列q对应的tp的半径字排序分数(α-boundontherankingscore)可表示为且引理3:由于wn(n)表示顶点n的半径字领域(α-radiuswordneighborhood),查询关键字q.ψ={t1...,tj...,tm},为了不失一般性,假设第j个关键字在wn(n)中已经有相应的值,则在n节点下以p为根节点的tp对应的所有的tqsp可表示为并且引理4:由于表示以在节点n下以p为根节点的tp的tqsp对应的半径字松散度,对于给定的查询序列q,则在节点n下以p为根节点的所有的tp的半径字松散度可表示为其中s(q,n)表示q和n之间最小的空间距离,且根据引理2我们得出删除规则2,根据引理4得出删除规则3,来提高算法的效率,具体删除规则如下:删除规则2:对于给定的查询序列q,θ表示第k个候选tqsp的rankingscore。表示以p为根节点的tp的tqsp的α-boundontherankingscore。当时tp不是我们要查的结果,p可以被删除。删除规则3:对于给定的查询序列q,θ表示第k个候选tqsp的rankingscore,表示节点n下以p为根节点的tp的tqsp的α-boundontherankingscore,若则在n节点下任何节点都不满足条件,n可以被删除。基于ksp算法的资源描述框架查询系统,主要是实现图上关键字的搜索和rdf数据上关键字的搜索:由于关键字检索对用户的友好性,不仅用户检索网络数据,而且用于检索xml文档,关系型数据库,和图。传统上图的搜索算法将查询转化为在特征空间上的搜索,例如路径,频繁模式,和序列。这种搜索算法更多的关注图的结构而不是图的语义内容。图上关键字的查询通过利用内容和链接结构两者来确定图中一组密集链接的节点。由于这两种信息的重新实施,可提高结果的整体质量。而rdf数据上关键字的搜索,由于rdf数据是一种特殊类型的图数据也可以提供查询的效率。在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1