一种基于数据流预测的Storm任务伸缩调度算法的制作方法
本发明属于数据交换网络领域,涉及一种基于数据流预测的storm任务伸缩调度算法。
背景技术:
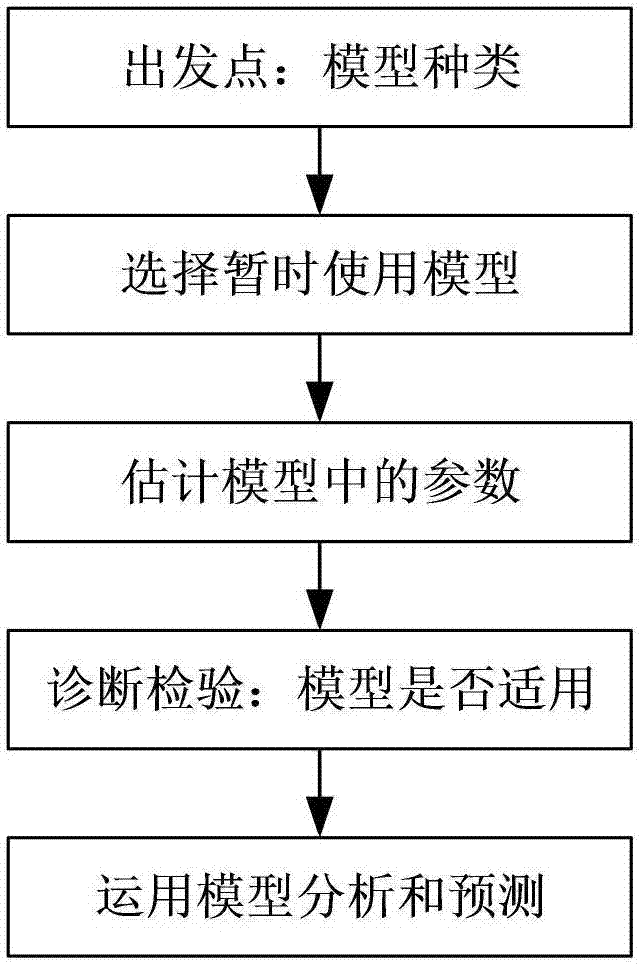
:云计算、物联网、社交媒体以及移动互联网等新兴技术和应用模式的普及和推广,促使全球数据量急剧增加,推动人类社会进入大数据时代。在大数据背景下,数据蕴含了丰富的内涵和价值,数据的时效性越来越重要,数据的流式特征也越来越显著,流式计算的重要性也越来越突出。业界推出了s4、spark、storm等流式计算框架。storm是个实时的、分布式的以及具备高容错的计算系统。storm可以处理大批量的数据,也可以在保证高可靠性的前提下让处理进行得更实时化,能快速处理或输出所有信息。storm具备容错和分布计算等特性,可以到不同的机器上进行大批量的数据处理。正因storm所表现出来的强大功能,使得它被广泛应用于国内外的互联网企业,如twitter、阿里巴巴、雅虎等。但在storm的应用及研究中,发现其在多个方面都有待完善。storm是一个实时流式计算框架,时效性要求高,而调度算法的好坏直接影响到tuple的处理时延。storm中默认的任务调度器使用轮询调度的策略,首先是计算集群中可供分配的slot资源,并判断当前已分配给运行topology的slot是否需要重新分配,然后对可分配的slot进行排序。计算topology的executor信息,最后将资源平均地分配给topology。在调度算法的优化上,业界已有许多相关研究:l.aniello等提出了一种将相互通信频率高的executor调度到同一个slot上来减少网络通信的改进调度算法,分为离线版:分析topology的静态结构,决定那些executor应该放在同一个slot;在线版:监控executor运行时的通信情况,将通信频率高的executor放到同一个slot。jielongxu等指出l.aniello所提出的离线处理忽视了集群中结点的负载情况和在线处理的调度算法模型缺乏有力的数学证明。作者在此基础上进行了优化,提出将executor按照trafficload降序排列,然后按序依次将executor分配到负载最轻的slot上,同时每个workernode上同一个topology的executor会被分配到同一个slot上和每个workernode的任务量不会过载。pengb等提出一种最大化资源利用率的同时最小化网络通信来提升系统性能的调度算法。其要解决的核心问题是:如何找到一种task到workernode的映射,使所有的资源请求都能够得到满足同时结点不会出现资源过载。longs等结合storm的不同应用场景,如恢复历史调度任务、单节点任务调度、资源需求调度等,对storm的资源分配和调度算法做了改进。sund等提出基于分布式qos(qualityofservice)感知的调度算法,使得storm适用于地理信息系统的研究中。在上述的调度算法中,是针对用户配置好topology任务并行度的调度,忽视了用户配置的topology中的worker数和各个组件的executor数对处理性能也有着严重的影响。当storm要处理的数据流比较平稳时,存在一个较优的各组件间的并行度关系,而用户很难在提交topology时设置出各个组件的较优并行度,当设置不合理时会造成tuple处理时延的增加。同时,在某些业务中,如微博中实时热词统计,storm要处理的微博数据流是实时变化的,一天中存在高峰期低峰期,并且有时会因为某个事件出现爆炸式的增长,此时仅仅通过上述的调度算法的优化并不能达到目的。因此希望storm计算框架中能预测要处理的数据流,动态调整topology中各个组件的并行度,即对用户提交的任务能进行弹性伸缩。在现有的关于storm弹性伸缩中,对topology中各组件间的关联性考虑不足,同时在弹性伸缩时采用简单的添加或较少各组件的并行度,直到获得较优的各组件并行度,这个过程中可能会进行多次任务调度,而每次任务调度是有时间开销的,因此在一定程度上增加了tuple的处理时延。同时现有的伸缩调整都是在系统负载发生变化时才对用户提交的topology中各组件的并行度进行调整,而每次的调整都需要一定的时间,因此在一定程度上来说降低了系统的吞吐量。技术实现要素:有鉴于此,本发明的目的在于提供一种基于数据流预测的storm任务伸缩调度算法,提前预测变化,根据监控得到的运行数据快速高效的求得topology中各组件的较优并行度,从而提高吞吐量,降低处理时延。为达到上述目的,本发明提供如下技术方案:一种基于数据流预测的storm任务伸缩调度算法,包括以下步骤:s1:设置目标函数;s2:求解topology中worker数和各个组件的executor数;s3:预测topology要处理的数据流并求解开始组件spout所需的executor数;s4:任务调度。进一步,所述s1设置目标函数为:其中,ntuple为所处理tuple的数量,trec为tuple由发送节点到处理节点所需的接受时间,tqueue为tuple到处理节点后因bolt繁忙tuple排队的时间,tproc为tuple的逻辑处理时间,tsend为tuple处理完后形成新的tuple的发送时间。进一步,所述s2具体为:s201:确定topology中开始组件spout所需的executor数,通过公式依次求得后继组件中的较优的executor数;其中,nexecutori为第i个组件的executor数量,nexecutori-1为第i-1个组件的executor数量,vgenerate为前一组件的executor的tuple产生速度,通过监控topology的运行数据然后取平均值获得,t为一个周期开始后的时间,σ为通过多次试验然后取得一个较优的值,vproc为第i个组件中executor的tuple处理速度,通过监控topology的运行数据然后取平均值获得;s202:求得topology所需的executor总数;s203:根据storm官方建议每个worker中15个executor,求解得到topology所需的worker数。进一步,所述s3具体为:使用时间序列模型(autoregressiveinregratedmovingaverage,arima)预测topology要处理的数据量,arima(p,d,q)表示为:xt=σ1xt-1+σ2xt-2+…+σpxt-p+ut-θ1ut-1-θ1ut-1-…-θqut,其中p为自回归项数;q为滑动平均项数;xt-1,xt-2为xt的前期值;ut,ut-1,ut-2为xt在t期,t-1期,t-2期的随机误差项,是相互独立的白噪声序列;d是使原序列xt由非平稳时间序列转换为平稳时间序列时对其成为平稳序列所做的差分次数;σ1,σ2,…,σp为自回归系数,θ1,θ2,…,θq为移动平均系数,是模型的待估参数。进一步,所述s4具体为:当获得topology中各组件较优的并行度后,进行storm任务调度;使用线上调度算法,在运行时,通过监控获得实时数据,包括executor的负载情况、executor的tuple接受率和发送率、集群中的节点负载;然后进行调度,在调度中最小化节点间的网络通信,并保存集群中的节点负载均衡;所述线上调度算法具体为:将executor按照trafficload降序排列,然后按序依次将executor分配到负载最轻的slot上,同时每个workernode上同一个topology的executor会被分配到同一个slot上并且每个workernode不过载。本发明的有益效果在于:本发明克服了现有对topology中各组件间的关联性考虑的不足,弥补了不能快速高效地求解到用户提交topology中各组件的较优并行度的不足,以及避免了对数据实时变化处理的忽视。本发明结合时间序列模型和线上调度算法,监控topology的运行,建立模型,求解topology中worker数和各个组件的executor数,预测topology要处理的数据量并求解开始组件spout所需的executor数,将新得到topology任务通过storm中的线上调度策略进行调度。本发明具有提前预测变化的优点,并能根据监控得到的运行数据快速高效的求得topology中各组件的较优并行度,从而提高了吞吐量,降低了处理时延。附图说明为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:图1为本发明的示意图;图2为时间序列模型的简图;图3为算法实施系统结构图。具体实施方式下面将结合附图,对本发明的优选实施例进行详细的描述。如图3所示,本发明的实施包括三个模块:topology监控模块、伸缩模块和调度模块。在topology监控模块中,可以调用nimbusclient的thrift接口获取ui上对storm中各topology运行的监控数据和ganglia集群监控工具来获得各节点和负载数据,然后我们将数据保存到数据库mysql中,伸缩调整模块在每个周期开始时通过前面周期保存在mysql中各topology的运行数据,然后通过上述模型求解该周期内topology的伸缩方案,然后进行调度。下面通过对微博中的词语进行统计为例来对本发明进行具体实施说明:该实例中topology由三个组件构成,第一个组件是spout,命名为readerdata,用来读取在kafka中的微博记录,该实例中将读取到的微博记录通过nexttuple方法形成tuple发送到后面的bolt组件。第二个组件是bolt,命名为splitdata,它接收从spout发送过来的tuple,将这tuple中的微博分词之后,将每个词语再单独发送出去。第三个组件也是bolt,命名为statdata,它负责接收从第二个组件发送的词语,将这些词语的出现次数进行统计,然后将结果写入到日志中进行输出。在本实例中使用kafka生产者读取微博数据,然后发送到kafka服务器,kafka的消费者为spout,即readdata从kafka中获取微博记录。1、监控模块利用ganglia作为storm集群监控工具,获取storm集群中各节点的信息。同时storm集群自身会对运行的topology进行监控,可以在stormui中查看到各个topology的运行信息,包括topology的work数、executor数、每个组件接受的tuple数、发送的tuple数、处理时间等。其中stormui中的所有数据,我们可以调用nimbusclient的thrift接口获取,然后我们将获取的实时数据保存到mysql数据库中,供后面的伸缩模块和调度模块使用。本平台中将监控模块获取的各topology运行数据保存到mysql中,mysql数据库在构建数据库集群方面有着优异的性能,可以用来解决海量数据处理中的高并发、低延迟、大体量等问题。为了降低延迟,我们采用java数据库连接(javadatabaseconnectivity,jdbc)技术来实现连接的复用,这样减少了数据库连接和释放的时间。在数据库中建立表来存储监控得到的数据:表一监控storm集群信息名类型idintsupervisor_numinttotal_slotintused_slotintexecutor_numint表一为监控storm集群信息,包括从节点数量,总的slot数,可用的slot数,executor数量。表二监控storm集群中运行的topology信息名类型idinttopology_namevarcharwork_numberintexecutor_numberinttask_numberint表二为监控storm集群中运行的topology信息,包括topology的名称,topology所需的work数,topology所需的executor数,topology所需的task数。表三监控storm集群中运行topology的spout组件的信息表三为监控storm集群中运行topology的spout组件的信息,包括spout组件的名称,该组件所需的executor数量,该组件发送的tuple数量,该组件执行时间。表四监控storm集群中运行topology的bolt组件的信息名类型idintbolt_namevarcharexecutor_numberinttuple_compete_numinttuple_emitted_numinttuple_compete_numinttopology_namevarchar表四为监控storm集群中运行topology的bolt组件的信息,包括bolt组件的名称,该组件所需的executor数量,该组件完成的tuple数量,该组件发送的tuple数量,该组件执行tuple所需的处理时间。表五监控kafka中的运行信息名类型idintkafka_topologyvarcharrec_numintproc_numint表五为监控kafka中的运行信息,包括消费的topology名称,收到的消息数,被消费的消息数。2、伸缩模块在该实例中,首先初始化该topology中各组件的并行度都为1。在周期t开始时进行伸缩调度或集群中某节点高负载时进行伸缩调度。在伸缩模块中,从mysql中读取数据,获取参数的值,求得topology中三组件的并行度关系,然后再求得在该周期t内组件spout所需的executor数及bolt所需的executor数,最后获得topology中各个组件较优的并行度后,通过storm中的rebalance进行重调度。步骤一:求解topology中worker数和各个组件的executor数首先以稳定的速率生成微博记录到kafka,供topology中的组件spout读取。第二个bolt组件中executor的tuple处理速度为vproc,即单位时间内处理tuple的数量。通过mysql中的统计值该组件完成的tuple数量tuple_complete_num可以获得该组件的平均处理处理速率。则组件tuple处理速度为nexecutori*vproc,其中nexecutori是该组件的executor数量,即表四中executor_number的值。其前一组件spout的executor的tuple产生速度为vgenerate,即单位时间内产生tuple的数量。通过表三中spout的监控数据tuple_emitted_num可以获得该spout的平均产生速率。则该组件的tuple产生速度为nexecutori-1*vgeneate,其中nexecutori-1是该组件的executor数量,即表三中的executor_number的值。则由下列公式求得readerdata与splitdata的比值为x1:x2同理可求得splitdate与statdata的比值为x2:x3,则该topology中组件readerdata、splitdata、statdata的比值为:x1:x2:x3。最后求得topology所需的executor总数,根据storm官方建议每个worker中15个executor,求解得到topology所需的worker数。步骤二:预测topology要处理的数据流并求解开始组件spout所需的executor数模拟twitter一天中发微博的情况,对所发的微博记录进行词语统计。如图2所示,在周期t开始时,使用时间序列模型arima(p,d,q)根据前面周期的数据到达速率进行预测本周期组件需要消费的数据量。在arima的各项系数p、d、q可以通过对历史数据的训练得到。影响时间序列的因素有很多,可能存在此消彼长、突然出现等现象,单凭一次训练得到的模型很难反应时间序列的长期变化,因此预测模型采用边训练边预测的方式,利用最新的历史数据,在预测前重新训练,修正arima模型中各项系数,然后再进行预测得到外部数据到达kafka中的速率vcome。上一周期kafka中spout未处理完的数据量为datasurplus,可用表五中的rev_num和proc_num的差值获得。组件spout的数据处理速率为nexucutori*vproc,其中nexecutori是组件spout的executor数量,vproc是单位时间内处理kafka中消息的数量。由下列公式知该周期开始t时间后spout组件的负载为:令load(t)=σ1,σ1通过多次实验取一个较优的值,使得spout组件在该负载下,kafka中的消息能尽快得到处理,降低消息的处理时延。则由上式求得:在该周期内spout较优的executor数y1,然后由步骤一中求得的readerdata、splitdata、statdata的比值,求得splitdata、statdata较优的executor数分别为y2、y3。则该topology所需的executor数量为y1+y2+y3,所需的work数量为大于(y1+y2+y3)/15的最小整数。然后判断是否需要进行伸缩调整,如果需要伸缩调整则调用storm中的reblance功能进行动态调整。3、调度模块当调用storm中的reblance后会进行新的调度。用户提交topology到storm集群后,计算时延在很大程度上取决于executor之间传输tuple的时延。线上调度算法通过减少网络传输的tuple的数量,即将相互通信的源executor和目标executor分配到相同的workernode上,能够极大的提升storm集群的计算性能。在统计微博词语的topology中readdata的task所在的executor会发送tuple给splitdata的task所在的executor,splitdata的task所在的executor会发送tuple给statdata的task所在的executor。假设运行时readdata、splitdata、statdata中task所对应的executor分别为e1、e2、e3,那么e1、e2、e3为相互通信的executor组,为了减少网络传输tuple的数量,应该将它们分配到同一节点上。如图1所示,具体步骤如下:采集运行周期t内,相互通信的executor之间的tuple传输速率;利用采集到的信息按照executor的传输速率进行降序排序。循环遍历executor,如果相互通信的executor在同一工作节点上,则对不进行调度;如果不在同一工作节点,则将相互通信的executor调度到同一工作节点上;监控各executor所在的节点的负载进行降序排列。当相互通信的executor不在同一工作节点时调度到当前负载最低的workernode上。直到所有executor都被处理后调度结束。最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1