人工智能的实现方法及装置与流程
本发明涉及人工智能技术领域,更具体地,涉及一种人工智能的实现方法及装置。
背景技术:
ai(artificialintelligence,人工智能)是指利用计算机等现代化工具来模拟人类或者其它生物的思维和行动的技术。随着ai技术的日渐进步,ai技术已被应用于生产生活的各个方面。例如,当ai技术被应用于游戏应用程序或者一些仿真模拟系统中时,会生成一个与人或者其它生物具有相似行为的虚拟主体,该主体即为ai智能体。由于ai智能体能表现出与人或者其它生物的行为类似,从而可以提高游戏应用程序的可玩性或仿真模拟系统的代入感。在设计ai相关的游戏应用程序或者仿真模拟系统中时,如何使ai智能体实现相应的ai行为,是提高游戏的可玩性或仿真模拟系统的代入感的重点。
相关技术中提供了一种人工智能的实现方法,主要是通过预先设置固定的行为策略来控制ai智能体的移动以及相关行为。具体地,可为ai智能体设置固定的移动路径,让ai智能体在游戏场景或仿真场景内按照移动路径移动。另外,还可让ai智能体按照固定的行为方式循环重复相应的行为。
在实现本发明的过程中,发现相关技术至少存在以下问题:
由于在游戏场景或仿真模拟系统中,ai智能体的行为方式通常需要基于周围环境以及互动机制而产生相应的变化,当ai智能体按照固定的移动路径来移动,并按照固定的行为模式循环重复相应的行为,会导致模拟效果较差,从而降低了游戏的可玩性或仿真模拟系统的代入感。
技术实现要素:
由于在游戏场景或仿真模拟系统中,ai智能体的行为方式通常需要基于周围环境以及互动机制而产生相应的变化,当ai智能体按照固定的移动路径来移动,并按照固定的行为模式循环重复相应的行为时,会导致模拟效果较差,从而降低了游戏的可玩性或仿真模拟系统的代入感。为了解决上述问题,本发明提供一种克服上述问题或者至少部分地解决上述问题的人工智能的实现方法及装置。
根据本发明的第一方面,提供了一种人工智能的实现方法,该方法包括:
步骤1,对于已产生的任一ai智能体,将任一ai智能体作为指定智能体,获取指定智能体当前的状态触发信息;
步骤2,根据状态触发信息,确定指定智能体的状态;
步骤3,在对指定智能体进行下一次心跳计数时,基于改变后的状态,确定指定智能体的行为模式,以使得指定智能体基于行为模式执行相应的行为。
本发明提供的方法,对于已产生的任一ai智能体,通过将任一ai智能体作为指定智能体,获取指定智能体当前的状态触发信息。根据状态触发信息,确定指定智能体的状态。在对指定智能体进行下一次心跳计数时,基于改变后的状态,改变指定智能体的行为模式,以使得指定智能体基于行为模式执行相应的行为。由于ai智能体可实时获取状态触发信息,依据状态触发信息来改变自身状态,并根据改变后的状态执行相应的行为,从而ai智能体能够基于需求实时改变自身的行为方式,进而相应的模拟效果较好,并提高了游戏的可玩性或仿真模拟系统的代入感。
结合第一方面的第一种可能的实现方式,在第二种可能的实现方式中,指定智能体的状态为状态集中的任一种状态;状态集包括出生状态、自由状态、玩耍状态、逃跑状态、觅食状态、被吃状态、追捕状态以及进食状态。
结合第一方面的第二种可能的实现方式,在第三种可能的实现方式中,状态触发信息为产生指定智能体后的累积时长,步骤2进一步包括:
当指定智能体的当前状态为出生状态且累积时长大于第一预设阈值时,将指定智能体改变为自由状态。
结合第一方面的第二种可能的实现方式,在第四种可能的实现方式中,状态触发信息为玩耍概率值,步骤2进一步包括:
当指定智能体的当前状态为自由状态且玩耍概率值大于第二预设阈值时,将指定智能体改变为玩耍状态。
结合第一方面的第二种可能的实现方式,在第五种可能的实现方式中,状态触发信息为饱食度,步骤2进一步包括:
当指定智能体的当前状态为自由状态且指定智能体的饱食度低于第三预设阈值时,将指定智能体的状态改变为觅食状态。
结合第一方面的第二种可能的实现方式,在第六种可能的实现方式中,状态触发信息为位置信息,步骤2进一步包括:
基于位置信息,确定指定智能体的感知区域;
当在感知区域内达到状态改变的触发条件时,从状态集中选取相应的状态,作为指定智能体改变后的状态。
结合第一方面的第六种可能的实现方式,在第七种可能的实现方式中,感知区域为视野区域,当在感知区域内达到状态改变的触发条件时,从状态集中选取相应的状态,作为指定智能体改变后的状态,包括:
当指定智能体的当前状态为觅食状态、且在视野区域检测到作为捕食目标的其它ai智能体时,将指定智能体的状态改变为追捕状态。
结合第一方面的第六种可能的实现方式,在第八种可能的实现方式中,感知区域为碰撞区域,当在感知区域内达到状态改变的触发条件时,从状态集中选取相应的状态,作为指定智能体改变后的状态,包括:
当指定智能体的当前状态为追捕状态时,将指定智能体追捕的ai智能体作为目标智能体,若检测到指定智能体的碰撞区域与目标智能体的碰撞区域存在重叠区域,将指定智能体的状态改变为进食状态,将目标智能体的状态改变为被吃状态。
结合第一方面的第六种可能的实现方式,在第九种可能的实现方式中,感知区域为感应区域,当在感知区域内达到状态改变的触发条件时,从状态集中选取相应的状态,作为指定智能体改变后的状态,包括:
当在感应区域检测到捕食指定智能体的其它ai智能体时,将指定智能体的状态改变为逃跑状态。
根据本发明的第二方面,提供了一种人工智能的实现装置,该装置包括:
获取模块,用于对于已产生的任一ai智能体,将任一ai智能体作为指定智能体,获取指定智能体当前的状态触发信息;
第一确定模块,用于根据状态触发信息,确定指定智能体的状态;
第二确定模块,用于在对指定智能体进行下一次心跳计数时,基于改变后的状态,确定指定智能体的行为模式,以使得指定智能体基于行为模式执行相应的行为。
根据本发明的第三方面,提供了一种人工智能的实现设备,该设备包括至少一个处理器;以及
与处理器通信连接的至少一个存储器,其中:存储器存储有可被处理器执行的程序指令,处理器调用程序指令能够执行上述第一方面或第一方面的各种可能的实现方式所提供的人工智能的实现方法。
根据本发明的第四方面,提供了一种非暂态计算机可读存储介质,该非暂态计算机可读存储介质存储计算机指令,该计算机指令使该计算机执行上述第一方面或第一方面的各种可能的实现方式所提供的人工智能的实现方法。
应当理解的是,以上的一般描述和后文的细节描述是示例性和解释性的,并不能限制本发明。
附图说明
图1为本发明实施例的一种人工智能的实现方法的流程示意图;
图2为本发明实施例的一种人工智能的实现方法的流程示意图;
图3为本发明实施例的一种状态的迁移示意图;
图4为本发明实施例的一种人工智能的实现装置的框图;
图5为本发明实施例的一种人工智能的实现设备的框图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
目前ai技术已被用于生产生活的各个方面,如可被应用于游戏或者一些仿真模拟系统中。由于ai智能体能表现出与人或者其它生物的行为类似,从而可以提高游戏应用程序的可玩性或仿真模拟系统的代入感。相关技术中提供了一种人工智能的实现方法,主要是通过预先设置固定的行为策略来控制ai智能体的移动以及相关行为。例如,以游戏场景为例,游戏中的npc(non-player-controlledcharacter,非玩家控制角色)按照固定的路径来回移动,即使周围环境因素发生改变也不会改变自身的移动方式。
由于在游戏场景或仿真模拟系统中,ai智能体的行为方式通常需要基于周围环境以及互动机制而产生相应的变化,当ai智能体按照固定的移动路径来移动,并按照固定的行为模式循环重复相应的行为时,会导致模拟效果较差,进而降低了游戏的可玩性或仿真模拟系统的代入感。
针对相关技术中的问题,本发明实施例提供了一种人工智能的实现方法。本发明实施例提供的方法,可以适用于游戏场景,也可以适用于仿真模拟系统。其中,本发明实施例提供的方法可适用于游戏中npc行为方式的控制,也可以适用于仿真模拟系统中仿真对象行为方式的控制,本发明实施例对此不作具体限定。为了便于说明,本发明实施例以应用方向为仿真模拟系统为例,对仿真模拟系统中仿真对象相应的人工智能实现方法进行说明。
仿真模拟系统的应用场景通常很多,如不同生态系统内的生物形态或者生物之间食物链的仿真模拟。其中,仿真模拟的生态系统可以为森林、草原、荒漠、冰川、海洋、河流、湖泊或湿地等,本发明实施例对此不作具体限定。为了便于说明,本发明实施例以海洋生态系统中生物之间食物链的仿真模拟为例,对不同生物的人工智能实现方法进行说明。
需要说明的是,仿真模拟系统通常需要通过一定形式的进行展示,本发明实施例可通过ar(augmentedreality,增强现实)多媒体技术进行展示。具体地,可通过在ar多媒体相应的投影设备在四周墙壁上形成海底世界食物链的仿真模拟投影。例如,可以在封闭空间的中央布置三台ar多媒体相应的投影设备,从而可实现封闭空间内360度的投影覆盖。其中,每台投影设备可对应投影120度的投影区域。
当然,除了三台投影设备之外,还可以通过其它数量的投影设备实现投影,本发明实施例对此不作具体限定。为了便于说明,本发明实施例以其中一台投影设备为例,对投影设备产生投影中ai智能体的人工智能实现方法进行说明。其中,每台投影设备可称为一个客户端。同一个场景space中可包含多个客户端(投影设备),每个space的投影数据可来源于mmo(massivelymultiplayeronline,大型多人在线游戏)服务器。由于mmo服务器需要提供投影数据,在执行本发明实施例之前,可先基于mmo服务器,通过unity3d技术建立海底世界的三维场景,并基于三维场景建立海底世界食物链的仿真模拟系统。
参见图1,该方法包括:101、对于已产生的任一ai智能体,将任一ai智能体作为指定智能体,获取指定智能体当前的状态触发信息;102、根据状态触发信息,确定指定智能体的状态;103、在对指定智能体进行下一次心跳计数时,基于改变后的状态,改变指定智能体的行为模式,以使得指定智能体基于行为模式执行相应的行为。
由于本发明实施例是以海洋生态系统为例,从而ai智能体可以为海洋生态系统中的不同鱼类。状态触发信息可用于对触发ai智能体的不同状态,从而改变其状态。心跳计数可通过心跳定时器来实现,每个space可对应一个心跳定时器。其中,心跳定时器可用于模拟鱼类的“心跳”,从而可通过鱼类每次的“心跳”,让鱼类进行“思考”,以改变相应的“行为”。
本发明实施例提供的方法,对于已产生的任一ai智能体,通过将任一ai智能体作为指定智能体,获取指定智能体当前的状态触发信息。根据状态触发信息,确定指定智能体的状态。在对指定智能体进行下一次心跳计数时,基于改变后的状态,改变指定智能体的行为模式,以使得指定智能体基于行为模式执行相应的行为。由于ai智能体可实时获取状态触发信息,依据状态触发信息来改变自身状态,并根据改变后的状态执行相应的行为,从而ai智能体能够基于需求实时改变自身的行为方式,进而相应的模拟效果较好,并提高了游戏的可玩性或仿真模拟系统的代入感。
作为一种可选实施例,指定智能体的状态为状态集中的任一种状态;状态集包括出生状态、自由状态、玩耍状态、逃跑状态、觅食状态、被吃状态、追捕状态以及进食状态。
作为一种可选实施例,状态触发信息为产生指定智能体后的累积时长,步骤2进一步包括:
当指定智能体的当前状态为出生状态且累积时长大于第一预设阈值时,将指定智能体改变为自由状态。
作为一种可选实施例,状态触发信息为玩耍概率值,步骤2进一步包括:
当指定智能体的当前状态为自由状态且玩耍概率值大于第二预设阈值时,将指定智能体改变为玩耍状态。
作为一种可选实施例,状态触发信息为饱食度,步骤2进一步包括:
当指定智能体的当前状态为自由状态且指定智能体的饱食度低于第三预设阈值时,将指定智能体的状态改变为觅食状态。
作为一种可选实施例,状态触发信息为位置信息,步骤2进一步包括:
基于位置信息,确定指定智能体的感知区域;
当在感知区域内达到状态改变的触发条件时,从状态集中选取相应的状态,作为指定智能体改变后的状态。
作为一种可选实施例,感知区域为视野区域,当在感知区域内达到状态改变的触发条件时,从状态集中选取相应的状态,作为指定智能体改变后的状态,包括:
当指定智能体的当前状态为觅食状态、且在视野区域检测到作为捕食目标的其它ai智能体时,将指定智能体的状态改变为追捕状态。
上述所有可选技术方案,可以采用任意结合形成本发明的可选实施例,在此不再一一赘述。
基于上述图1对应实施例的内容,本发明实施例提供了一种人工智能的实现方法。本发明实施例主要是以其中一个space为例,对该space产生投影中ai智能体的人工智能实现方法进行说明。其中,该space可对应一个心跳定时器,以用于触发不同的操作。通过为每个space设置一个心跳定时器,而不用为每个ai智能体各自设置一个心跳定时器,从而能够减少资源的消耗。
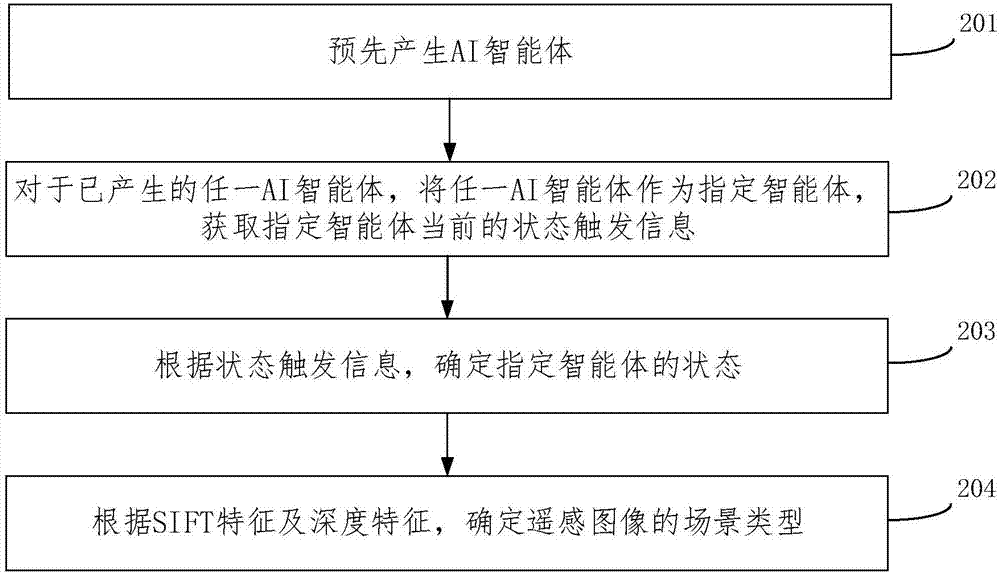
参见图2,该方法包括:201、预先产生ai智能体;202、对于已产生的任一ai智能体,将任一ai智能体作为指定智能体,获取指定智能体当前的状态触发信息;203、根据状态触发信息,确定指定智能体的状态;204、在对指定智能体进行下一次心跳计数时,基于改变后的状态,改变指定智能体的行为模式,以使得指定智能体基于行为模式执行相应的行为。
其中,201、预先产生ai智能体。
由上述图1对应实施例的内容可知,本发明实施例主要是对海底世界食物链进行仿真模拟,从而可先产生ai智能体。具体地,可在每次进行心跳技数时,按照预设数量产生ai智能体。当然,还可以按照随机触发的方式来产生ai智能体,本发明实施例不对ai智能体的产生时机或者方式作具体限定。
由于本发明实施例是对海底世界食物链的模拟,从而本步骤ai智能体可以为不同类型的鱼类。为了后续说明,本发明实施例以鱼类的类型为普通鱼、鱼群、食肉鱼、虎鲸以及美人鱼为例。其中,参与食物链的主体为普通鱼与食肉鱼,食肉鱼可以吃普通鱼。需要说明的是,普通鱼可分为多种类型,食肉鱼也可分为多种类型。每种类型食肉鱼的食谱除了可以包括一种或多种普通鱼,还可以包括其它类型的食肉鱼,本发明实施例对此不作具体限定。
另外,在上述列举的鱼类类型中,鱼群及美人鱼主要是作为海底世界的展示元素,而不参与食物链的仿真模拟。由于海底世界仿真模拟系统能够展示的鱼类总数量是有上限的,从而为了避免产生过多的鱼,在鱼类总数量达到上限值时,可控制虎鲸出现在场景内,并由虎鲸吃完场景内所有的鱼。另外,美人鱼可以在场景内随机出现,在虎鲸即将出现之前离开场景。
其中,202、对于已产生的任一ai智能体,将任一ai智能体作为指定智能体,获取指定智能体当前的状态触发信息。
在本步骤中,状态触发信息主要用于触发ai智能体的不同状态。ai智能体的状态可以为状态集中的任一种状态。其中,状态集可以包括出生状态、自由状态、玩耍状态、逃跑状态、觅食状态、被吃状态、追捕状态以及进食状态。当然,根据实际仿真模拟需求,状态集还可以包括其它状态,本发明实施例对此不作具体限定。
在上述列举的状态中,出生状态代表鱼类刚被产生时的保护状态。具体地,处于出生状态的鱼在一定时间内不会被攻击,饱食度不会改变,且可以自由移动。鱼在遇到食物链中的上级鱼类后会开始逃跑,即对应逃跑状态。鱼在饱食度下降到一定数值后开始寻找食物,这种状态即为觅食状态。鱼在饿时遇到食物链中的下级鱼类后会开始追捕,这种状态即为追捕状态。为了便于后续说明ai智能体的状态改变过程,本发明实施例以已产生的任一ai智能体为例,将该ai智能体作为指定智能体,从而对指定智能体的状态改变过程进行说明。
指定智能体在改变状态之前,会处于上述状态集所涵盖的某种状态下。在改变指定智能体的状态时,需要先根据指定智能体当前所处的状态来获取相应的状态触发信息,从而基于状态触发信息实现状态改变,具体过程可参考后续步骤中的内容。
其中,203、根据状态触发信息,确定指定智能体的状态。
由上述步骤可知,状态触发信息可根据指定智能体当前所处的状态来获取。相应地,在根据状态触发信息改变指定智能体的状态时,可以有不同的方式。具体地,若指定智能体的当前状态为出生状态,而状态触发信息为产生指定智能体后的累积时长,当累积时长大于第一预设阈值时,则指定智能体会失去出生时的被保护状态,并状态会改变为自由状态。需要说明的是,当指定智能体为鱼类时,该状态变化的过程可适用于任何类型的鱼,本发明实施例对此不作具体限定。
若指定智能体的当前状态为自由状态,而状态触发信息为玩耍概率值,当玩耍概率值大于第二预设阈值时,则指定智能体会进入玩耍状态。需要说明的是,若指定智能体的当前状态为玩耍状态,当玩耍时长大于一定数值时,则会玩耍结束并重新回到自由状态。此时,玩耍时长可作为状态触发信息,以使得指定智能体由玩耍状态改变为自由状态。需要说明的是,该状态变化的过程可适用于任何类型的鱼,本发明实施例对此不作具体限定。
若指定智能体的当前状态为自由状态,而状态触发信息为饱食度,当指定智能体的饱食度低于第三预设阈值时,将指定智能体的状态改变为觅食状态。其中,饱食度用于表明指定智能体的饥饿程度。饱食度越高表明指定智能体越不饥饿,饱食度越低表明指定智能体越饥饿。需要说明的是,这里的觅食状态指的是捕食其它鱼类。由上述实施例的内容可知,参与食物链的主要为普通鱼以及食肉鱼。普通鱼不会捕食其它鱼类,而食肉鱼会捕食其它鱼类。因此,该状态变化的过程可适用于食肉鱼类,本发明实施例对此不作具体限定。
由于海底世界的鱼类遇到天敌会逃跑,遇到猎物会追捕,为了仿真模拟该场景,状态触发信息还可以为指定智能体的位置信息。基于指定智能体的位置信息,当在指定智能体的周围检测到了天敌,指定智能体可以逃跑。当在指定智能体的周围检测到了猎物,则指定智能体会开始追捕。相应地,本发明不对根据状态触发信息,确定指定智能体的状态的方式作具体限定,包括但不限于:基于位置信息,确定指定智能体的感知区域;当在感知区域内达到状态改变的触发条件时,从状态集中选取相应的状态,作为指定智能体改变后的状态。
为了让指定智能体能够感知到猎物或者天敌,可为指定智能体设置感知区域。其中,感知区域可分为视野区域、感应区域以及碰撞区域,本发明实施例对此不作具体限定。在为指定智能体设置感知区域后,相当于给指定智能体增加了“触觉”,以用来感知周围的环境。上述三种区域的形状可以为圆形,对应的区域范围即以指定智能体为中心按照一定半径所形成的圆形区域,本发明实施例对此也不作具体限定。
若指定智能体的当前状态为觅食状态,则对于指定智能体而言,只要落入视野内的猎物都会被作为追捕目标。相应地,感知区域可以为视野区域,当在视野区域内检测到作为捕食目标的其它ai智能体时,可将指定智能体的状态改变为追捕状态。在上述过程中,触发条件即为在视野区域内检测到作为捕食目标的其它ai智能体。需要说明的是,由于落入到指定智能体视野区域内的其它ai智能体可能会有很多,从而可预先建立指定智能体的食物列表。当食物列表内的其它ai智能体进入指定智能体的视野区域内时,指定智能体可从中任选一个ai智能体作为追捕对象,并进入追捕状态。
若指定智能体的当前状态为追捕状态,则对于指定智能体而言,只要落入到该指定智能体捕食范围内的猎物都会被捕食。相应地,感知区域可以为碰撞区域。指定智能体在追捕猎物时,当指定智能体的碰撞区域与其追捕猎物的碰撞区域之间存在重叠区域时,则表明指定智能体与其追捕的猎物发生了“碰撞”,即猎物落入指定智能体的捕食范围。相应地,可将指定智能体的状态变为进食状态。将被吃掉猎物的状态变为被吃状态。其中,上述感知区域的设定主要来源于mmo引擎提供的aoi(areaofinterest,兴趣区域)。aoi为mmo引擎提供的一个兴趣范围。为了减少ai带来的消耗,本发明实施例通过在配置文件中设置aoi的半径,同时在实体(ai智能体)被目击后,由witness目击者的回调函数onwitness中来激活相应的ai行为。如果实体没有被目击,则ai可被设置为不可用,从而达到优化性能的目的。
例如,以指定智能体为一条食肉鱼为例。若有其它鱼进入了或离开了该食肉鱼的视野区域,则可将进入或离开视野区域的其它鱼的标识、以及该食肉鱼的标识拼接为json字符串或unit字符串,通过客户端将字符串发送到mmo服务器。mmo服务器在消息类中接收客户端发送的json字符串或者uint字符串,并对字符串进行解析,从而基于解析得到的该食肉鱼的标识,获取该食肉鱼的实体。调用该实体中相应的处理方法,以使得该食肉鱼执行相应的追捕行为。
由于后续基于碰撞区域检测到的碰撞类型,可分为障碍物碰撞以及与捕食目标之间的碰撞,从而当服务器接收到碰撞区域对应的字符串时,可解析出实体(指定智能体)对应的碰撞类型,并让实体执行相应的行为。若该食肉鱼与障碍物发生了碰撞,则可调用相应的处理方法执行避障行为。若该食肉鱼与追捕目标发生了碰撞,则可调用相应的处理方法执行进食行为。
另外,指定智能体在进食结束后会增加自身的饱食度,并由进食状态回到自由状态。若指定智能体在回到自由状态后,饱食度还是低于第三预设阈值,则指定智能体又会回到觅食状态,并重复上述状态转变过程,直到饱食度大于第三预设阈值。
需要说明的是,指定智能体在追捕猎物时存在追捕失败的情形,即猎物逃出了视野区域。此时,指定智能体会由追捕状态重新回到觅食状态。被追捕的猎物,即被追捕的其它ai智能体会由逃跑状态重新回到自由状态。
为了让ai智能体感知到天敌,还可以为ai智能体设置感应区域。当在指定智能体的感应区域内检测到捕食指定智能体的其它ai智能体时,可将指定智能体的状态改变为逃跑状态。需要说明的是,在将指定智能体改变为逃跑状态之前,指定智能体所处的状态可以为玩耍状态、自由状态、追捕状态以及觅食状态。也即,若指定智能体的当前状态为玩耍状态、自由状态、追捕状态以及觅食状态,而在指定智能体的感应区域内检测到捕食指定智能体的其它ai智能体,则指定智能体的状态会被改变为逃跑状态。
另外,由于落入到指定智能体感应区域内的其它ai智能体可能会有很多,从而可预先建立指定智能体的天敌列表。当天敌列表内的其它ai智能体进入指定智能体的感应区域时,指定智能体可进入逃跑状态。其中,上述各种状态之间的迁移转换过程可参考图3。
需要说明的是,为了给用户较为真实的感受,增强与用户的交互体验,以尽量做到仿真模拟真实的海底世界,通常需要实现比较精确的碰撞检测。目前,一般的mmo服务器引擎提供的的范围触发器与两个实体的大小密切相关,在实现碰撞检测时容易出现穿透现象,不能满足仿真模拟的需求。另外,使用mmo服务器中常用的客户端进行碰撞器检测碰撞,将检测的信息发送至服务器,由服务器进行校验和操作。这样虽然做到了精确地检测碰撞,但是也带来了通信成本的增加。为了减少通信成本,本发明实施例通过客户端作筛选,从源头上减少信息量。与此同时,将json字符串尽量使用uint移位操作来进行传递,可减少消息长度。
其中,204、在对指定智能体进行下一次心跳计数时,基于改变后的状态,确定指定智能体的行为模式,以使得指定智能体基于行为模式执行相应的行为。
上述步骤203主要为指定智能体的状态改变的过程,即相当于给指定智能体加入了“思维”,让其根据外界因素或者自身因素的改变,以实现自身状态的迁移。指定智能体的状态在改变后,可以在下一次心跳计数时按照相应的行为模式以执行相应的行为。
具体地,指定智能体在进入出生状态后,可确定指定智能体的行为模式为自由移动,饥饿度不变且不会捕食及被捕食。另外,还可根据移动时自身的坐标与障碍物坐标之间的位置关系实时计算避障路线,并按照避障路线进行移动。
指定智能体在进入自由状态后,可确定指定智能体的行为模式为自由移动。若指定智能体为食肉鱼,则此时饱食度会开始下降。
当饱食度低于第三预设阈值时,指定智能体会进入觅食状态。在进入觅食状态后,可确定指定智能体的行为模式为自由移动,并同时持续降低饱食度。
当在指定智能体的视野区域内检测到食物列表中的其它ai智能体时,指定智能体会由觅食状态进入追捕状态。此时,可确定指定智能体的行为模式为追踪。另外,还可增加其移动速度并持续降低其饱食度。由于在追捕过程中,每一次进行心跳计数时,指定智能体需要获取改变后的状态,并基于改变后的状态来确定行为模式,以执行相应的行为,从而会造成行动上的延迟卡顿。为了解决该问题,可按照比心跳周期更短的周期,实时规划指定智能体的移动路线,从而预先确定指定智能体的行为方式,避免在心跳计数时产生的延迟卡顿。例如,若心跳计数的时间周期为1秒,则实时规划移动路线的周期可以为0.2秒,本发明实施例不对两者的周期长度作具体限定。
指定智能体在追捕其它ai智能体后,若指定智能体的碰撞区域与追捕目标的碰撞区域之间存在重叠区域,则指定智能体会进入进食状态。此时,可确定指定智能体的行为模式为进食。需要说明的是,指定智能体在进食完毕后,会根据进食目标的能量值提高自身的饱食度。另外,进食完毕后还可以有相应的消化时间,消化时间结束后再确认指定智能体下一阶段的状态。
指定智能体在被追捕到后,指定智能体会进入被吃状态。此时,可确定指定智能体的行为模式为销毁,即指定智能体会在场景中消失。指定智能体在进入玩耍状态后,可确定指定智能体的行为模式为玩耍。此时,可通过动画的方式使得指定智能体执行相应的玩耍行为。
本发明实施例提供的方法,通过预先产生ai智能体,对于已产生的任一ai智能体,将任一ai智能体作为指定智能体,获取指定智能体当前的状态触发信息。根据状态触发信息,确定指定智能体的状态。在对指定智能体进行下一次心跳计数时,基于改变后的状态,改变指定智能体的行为模式,以使得指定智能体基于行为模式执行相应的行为。由于ai智能体可实时获取状态触发信息,依据状态触发信息来改变自身状态,并根据改变后的状态执行相应的行为,从而ai智能体能够基于需求实时改变自身的行为方式,进而相应的模拟效果较好,并提高了游戏的可玩性或仿真模拟系统的代入感。
本发明实施例提供了一种人工智能的实现装置,该装置用于执行上述图1或图2对应的实施例中所提供的人工智能的实现方法。参见图4,该装置包括:
获取模块401,用于对于已产生的任一ai智能体,将任一ai智能体作为指定智能体,获取指定智能体当前的状态触发信息;
第一确定模块402,用于根据状态触发信息,确定指定智能体的状态;
第二确定模块403,用于在对指定智能体进行下一次心跳计数时,基于改变后的状态,确定指定智能体的行为模式,以使得指定智能体基于行为模式执行相应的行为。
作为一种可选实施例,指定智能体的状态为状态集中的任一种状态;状态集包括出生状态、自由状态、玩耍状态、逃跑状态、觅食状态、被吃状态、追捕状态以及进食状态。
作为一种可选实施例,状态触发信息为产生指定智能体后的累积时长,第一确定模块402,用于当指定智能体的当前状态为出生状态且累积时长大于第一预设阈值时,将指定智能体改变为自由状态。
作为一种可选实施例,状态触发信息为玩耍概率值,第一确定模块402,用于当指定智能体的当前状态为自由状态且玩耍概率值大于第二预设阈值时,将指定智能体改变为玩耍状态。
作为一种可选实施例,状态触发信息为饱食度,第一确定模块402,用于当指定智能体的当前状态为自由状态且指定智能体的饱食度低于第三预设阈值时,将指定智能体的状态改变为觅食状态。
作为一种可选实施例,状态触发信息为位置信息,第一确定模块402,包括:
确定单元,用于基于位置信息,确定指定智能体的感知区域;
选取单元,用于当在感知区域内达到状态改变的触发条件时,从状态集中选取相应的状态,作为指定智能体改变后的状态。
作为一种可选实施例,感知区域为视野区域,选取单元,用于当指定智能体的当前状态为觅食状态、且在视野区域检测到作为捕食目标的其它ai智能体时,将指定智能体的状态改变为追捕状态。
本发明实施例提供的装置,对于已产生的任一ai智能体,通过将任一ai智能体作为指定智能体,获取指定智能体当前的状态触发信息。根据状态触发信息,确定指定智能体的状态。在对指定智能体进行下一次心跳计数时,基于改变后的状态,改变指定智能体的行为模式,以使得指定智能体基于行为模式执行相应的行为。由于ai智能体可实时获取状态触发信息,依据状态触发信息来改变自身状态,并根据改变后的状态执行相应的行为,从而ai智能体能够基于需求实时改变自身的行为方式,进而相应的模拟效果较好,并提高了游戏的可玩性或仿真模拟系统的代入感。
本发明实施例提供了一种人工智能的实现设备。参见图5,该弹人工智能的实现设备包括:处理器(processor)501、存储器(memory)502和总线503;
其中,处理器501及存储器502分别通过总线503完成相互间的通信;
处理器501用于调用存储器502中的程序指令,以执行上述图1或图2对应实施例所提供的人工智能的实现方法,例如包括:对于已产生的任一ai智能体,将任一ai智能体作为指定智能体,获取指定智能体当前的状态触发信息;根据状态触发信息,确定指定智能体的状态;在对指定智能体进行下一次心跳计数时,基于改变后的状态,确定指定智能体的行为模式,以使得指定智能体基于行为模式执行相应的行为。
本发明实施例提供了一种非暂态计算机可读存储介质,该非暂态计算机可读存储介质存储计算机指令,该计算机指令使该计算机执行上述各方法实施例所提供的方法,例如包括:对于已产生的任一ai智能体,将任一ai智能体作为指定智能体,获取指定智能体当前的状态触发信息;根据状态触发信息,确定指定智能体的状态;在对指定智能体进行下一次心跳计数时,基于改变后的状态,确定指定智能体的行为模式,以使得指定智能体基于行为模式执行相应的行为。
最后,本申请的方法仅为较佳的实施方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!