牙颌三维数字模型的分割方法与流程
本申请总体上涉及牙颌三维数字模型的分割方法,尤其是涉及利用深度学习能力的人工神经网络对牙颌三维数字模型进行分割的方法。
背景技术:
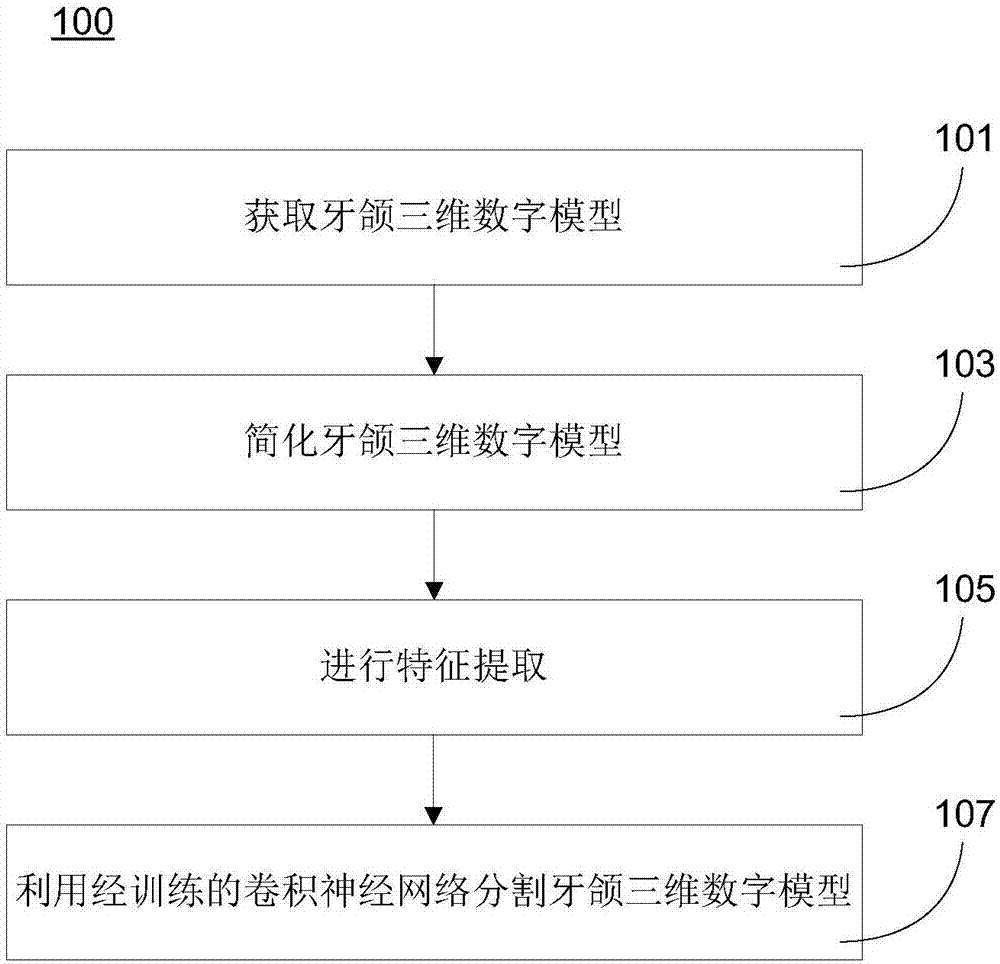
:如今,牙科治疗越来越多地借助计算机技术,在很多情况下需要对扫描获得的包括牙列与至少部分牙龈的牙颌的三维数字模型进行分割,把各牙齿的牙冠部分分割开,包括各牙冠与牙龈之间以及相邻牙冠之间的分割。通过计算机用户界面手工分割牙颌的三维数字模型虽然具有分割精度高的优点,但效率较低。基于曲率计算或骨架线技术,利用计算机对牙颌的三维数字模型进行自动分割的方案虽然可以解放人力,但具有以下缺点:(一)对于非标准的牙颌三维数字模型(比如,缺少一颗或多颗牙齿、牙齿形状不符合常规和/或牙颌三维数字模型中噪声较大)的分割准确率较低;(二)很难保证分割得到的牙龈线是平滑的;以及(三)对噪声较为敏感,因此对牙颌三位数字模型的质量要求较高。鉴于以上,有必要提供一种新的牙颌三维数字模型的分割方法。技术实现要素:本申请的一方面提供了一种牙颌三维数字模型的分割方法,包括:获取第一牙颌三维数字模型;以及利用经训练的深度人工神经网络分割所述第一牙颌三维数字模型的各牙齿。在一些实施方式中,所述人工神经网络是经过多个预先完成分割的牙颌三维数字模型的训练。在一些实施方式中,所述牙颌三维数字模型分割方法还包括:对所述第一牙颌三维数字模型进行分割之前,对其进行简化。在一些实施方式中,所述简化是分区域进行,其中,牙龈区域的简化程度高于牙齿区域。在一些实施方式中,所述简化是针对面片顶点进行简化。在一些实施方式中,所述简化算法包括与相邻面片夹角相关的分量,以降低夹角较小之处的简化概率。在一些实施方式中,所述牙颌三维数字模型分割方法还包括:对所述第一牙颌三维数字模型完成分割后,对分割边界进行优化,其中,所述对所述分割边界的优化是采用模糊聚类算法,该算法包括与面片夹角相关的分量,以提高夹角较小之处成为分割边界的概率。在一些实施方式中,所述人工神经网络是卷积神经网络。在一些实施方式中,所述卷积神经网络包括第一卷积神经网络和第二卷积神经网络,其中,所述第一卷积神经网络用于对牙龈和牙齿进行二分类,所述第二卷积神经网络用于基于所述第一卷积神经网络的结果,对牙齿进行多分类。在一些实施方式中,所述第二卷积神经网络用于对牙齿进行八分类,包括:中切牙、侧切牙、尖牙、第一前磨牙、第二前磨牙、第一磨牙、第二磨牙以及第三磨牙。在一些实施方式中,所述第一卷积神经网络和第二卷积神经网络至少之一包括“卷积层-卷积层-池层”结构。在一些实施方式中,所述第一卷积神经网络和第二卷积神经网络至少之一包括“卷积层-卷积层-池层-卷积层-卷积层-池层”结构。在一些实施方式中,所述第一卷积神经网络和第二卷积神经网络至少之一包括“全连接层-dropout-全连接层”结构。附图说明以下将结合附图及其详细描述对本申请的上述及其他特征作进一步说明。应当理解的是,这些附图仅示出了根据本申请的若干示例性的实施方式,因此不应被视为是对本申请保护范围的限制。除非特别指出,附图不必是成比例的,并且其中类似的标号表示类似的部件。图1为本申请一个实施例中的牙颌三维数字模型分割方法的示意性流程图;图2示意性地展示了本申请一个实施例中的卷积神经网络的结构;以及图3示意性地展示了本申请一个实施例中窄带领域的寻找。具体实施方式以下的详细描述中引用了构成本说明书一部分的附图。说明书和附图所提及的示意性实施方式仅仅出于是说明性之目的,并非意图限制本申请的保护范围。在本申请的启示下,本领域技术人员能够理解,可以采用许多其他的实施方式,并且可以对所描述实施方式做出各种改变,而不背离本申请的主旨和保护范围。应当理解的是,在此说明并图示的本申请的各个方面可以按照很多不同的配置来布置、替换、组合、分离和设计,这些不同配置都在本申请的保护范围之内。本申请的一方面提供了一种利用深度人工神经网络分割牙颌三维数字模型的方法,下面以卷积神经网络为例进行说明。深度人工神经网络是具有深度学习能力的人工神经网络。深度学习是通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。请参图1,为本申请一个实施例中的牙颌三维数字模型分割方法100的示意性流程图。在101中,获取牙颌的三维数字模型。在一些实施方式中,可以直接扫描患者的牙颌,获取牙颌三维数字模型。在又一些实施方式中,可以扫描患者牙颌的实体模型,比如石膏模型,获取牙颌三维数字模型。在又一些实施方式中,可以扫描患者牙颌的咬模,获取牙颌三维数字模型。在一个实施例中,可以基于三角网格构建牙颌三维数字模型,下面以此类牙颌三维数字模型为例进行说明。可以理解,还可以基于其他类型的网格构建牙颌三维数字模型,比如四边形网格、五边形网格、六边形网格等,此处不再进行一一说明。在103中,简化牙颌三维数字模型。在一个实施例中,可以对101中获得的牙颌三维数字模型进行简化,以提高后续计算效率。在一个实施例中,可以针对面片的顶点进行简化,即删除部分顶点,以简化牙颌三维数字模型。对于以三角网格构建的牙颌三维数字模型,可以将其上的每一个三角形片称为一个面片。在一个实施例中,可以基于二次误差度量(QuadricErrorMetrics)简化牙颌三维数字模型。首先,对于牙颌三维数字模型面片的每个顶点,根据方程式(1)计算Q矩阵:Q=∑p∈planes(v)Kp方程式(1)其中,planes(v)表示原始顶点(未经简化的牙颌三维数字模型的面片的顶点)相关平面的集合,Kp由以下方程式(2)表达,其中,p由以下方程式(3)表达,p=[abcd]T方程式(3)其中,p代表以下方程式(4)的平面方程的系数,ax+by+cz+d=0方程式(4)其中,a、b以及c满足以下条件,a2+b2+c2=1方程式(5)在一个实施例中,可以针对每一对顶点组合计算合并误差,然后迭代选取最小误差的顶点组合进行收缩,并更新所有相关的边的误差。基于Q矩阵的计算,可以获得简化后的顶点。在一个实施例中,可以引入最小化能量函数,以按牙齿、牙龈线和牙龈,粗略地把牙颌三维数字模型进行分区,以便针对不同区域采用不同的简化程度。比如,可以提高对牙龈区域的简化程度,降低对牙龈线和牙齿区域的简化程度。在一个实施例中,可以采用以下方程式(6)所表示的最小化能量函数。E(x)=∑i∈νEunary(i)+λ∑(i,j)∈εEpairwise(i,j)方程式(6)其中,v表示牙颌三维数字模型所有面片的集合;ε表示相邻面片关系的集合,包括牙齿-牙齿、牙龈-牙龈、牙龈线-牙龈线、牙龈-牙龈线及牙齿-牙龈线。其中,Eunary是根据面片所处的位置赋予面片的权重,以在经简化的模型上尽可能保留一些特征(比如,牙龈线、牙冠信息等),其可以由以下方程式(7)表达,Eunary=ε1E1+ε2E2-ε3E3方程式(7)其中,ε1、ε2以及ε3满足以下条件,ε1+ε2+ε3=1方程式(8)其中,E1代表牙齿和牙龈的概率能量,是沿z轴递减的方向赋予面片由大到小的权重。E2表示由局部最高点(比如磨牙上的尖点,对上颌模型而言,为局部区域z轴最大值点)向外广搜,赋予面片的由大到小的权重,距离所述局部最高点越近,面片属于牙齿的概率越大。E3表示按面片与模型中心的距离由近及远,赋予面片的由小到大的权重,以此降低舌侧牙龈的干扰。Eunary越大,表示面片属于牙齿的可能性越高。其中,Epairwise描述相邻面片属于不同类别时所产生的代价,其基本思想是若相邻面片夹角较小,说明该处特征明显,那么降低相关顶点被简化的可能性。其中,Epairwise可以由以下方程式(9)表达,其中,S表示与置信牙齿区域相连的面片集合,T表示与置信牙龈区域或其他牙齿区域相连的面片集合,w为参考神经网络预测结果赋予Epairwise的权值。其中,AngDist表示相邻面片的角度距离,其可以由以下方程式(10)表达,其中,αij表示相邻面片i和j的法向夹角,η为预先设定的一个较小的正数。对牙颌三维数字模型进行粗略分区时,希望分割线尽可能在牙龈线上,而不是在牙齿间缝隙或磨牙的牙槽线上。在一个实施例中,可以将所有极大曲率在一定范围内(k邻域)的顶点作为种子点,即可能的分割边界。但是在这些种子点中,有两种区域的点是不希望将其作为分割边界,即磨牙上的牙槽线和牙齿间缝隙,可以把这两种区域的顶点作为保护点。因此,可以减少和种子点相关边的权重,同时增大保护点相关边的权重。权重越小,被切割的可能性越大。关于种子点的寻找,可以对整个模型进行曲率分析,将顶点极大曲率落在[s1,s2]间的顶点作为种子点。在一个实施例中,对于上颌的牙颌三维数字模型,可以设置s1=-14.0,s2=-0.4。关于切割点的寻找,可以对每个种子点设定一个BFS搜索(BreadthFirstSearch)区域,寻找在这个区域内最大测地线距离的两个点,若这两个点的欧氏距离小于某个阈值,则认为该点为牙齿间缝隙,因为这一特性与凹槽相符。为降低算法复杂度,可以对顶点进行随机采样,采样点附近的顶点可以认为和采样点具有相同的性质。关于保护点,可以从局部最高点出发进行BFS搜索,在这部分内的种子点可以认为是牙槽线上的点。对原始的牙颌三维数字模型进行简化后即获得经简化的牙颌三维数字模型。在105中,进行特征提取。在经简化的牙颌三维数字模型上提取卷积神经网络所需的输入特征。在一个实施例中,可以提取以下特征:CurvatureFeature、PCAFeature(PrincipalComponentsAnalysis)、ShapeDiameterFeature、DistancefromMedialSurface、AverageGeodesicDistance、ShapeContexts、SpinImages以及坐标特征。除坐标特征外的其他特征的提取可参由EvangelosKalogerakis、AaronHertzmann以及KaranSingh在ACMTransactionsonGraphics,29(3),2010上发表的《Learning3DMeshSegmentationandLabeling》。以下对这些特征的提取进行简单说明。1)CurvatureFeature在一个实施例中,可以采用以下方法提取CurvatureFeature。首先,选择与P点临近的N个顶点,在一个实施例中,可以利用连接信息以缩减搜索空间,提高计算效率。接着,基于满足以下条件的二次矩阵块F(x,y,z)拟合所有临近的顶点,F(x,y,z)=0方程式(11)计算P点在所述矩阵块上的映射P0,且满足以下条件,F(P0)=0方程式(12)在P0点基于所述矩阵块计算曲率特性,即可作为P点的曲率。若对所有临近顶点,其中,a~n为拟合平面函数F(x,y,z)的系数,那么,可以把矩阵B-1A的两个特征值k1和k2作为主曲率,其中,其中,系数E、F、G为F(x,y,z)的一阶偏导,系数L、M、N为F(x,y,z)的二阶偏导。2)PCAFeature在一个实施例中,可以构造不同范围的局部面片中心的协方差矩阵,辅以面积权重,计算其3个奇异值s1、s2以及s3。范围可以由多种测地线距离半径所决定,比如5%、10%、20%等。每一组可以有以下几种特征描述:s1/(s1+s2+s3)、s2/(s1+s2+s3)、s3/(s1+s2+s3)、(s1+s2)/(s1+s2+s3)、(s1+s3)/(s1+s2+s3)、(s2+s3)/(s1+s2+s3)、s1/s2、s1/s3、s2/s3、s1/s2+s1/s3、s1/s2+s2/s3及s1/s3+s2/s3。3)ShapeDiameterFeature在一个实施例中,可以这么定义ShapeDiameterFeature(简称“SDF”):在面片中心点上向该点法向量反向的一定角度内发射一定数量的射线,这些射线与另一面相交形成线段。以长度中值的线段为标准,计算所有长度在规定标准差之内的线段的加权平均值、中值、均方,作为该点的SDF值。在一个实施例中,可以加入计算获得的SDF的多种对数化版本(对应正规化项α=1,2,4,8),如以下方程式(16),4)DistancefromMedialSurface在一个实施例中,可以把面片三个顶点的坐标平均值作为面片中心点的坐标值。然后在牙颌三维数字模型所定义的形状内,找到以所述面片中心点为切点的最大内切圆。由该内切圆的圆心向四周均衡地发射射线,与曲面相交(即牙颌三维数字模型所定义的封闭的形状),计算所有线段的长度。可以计算这些线段长度的加权平均、中值、均方作为特征,并可以加入归一化和对数化版本。5)AverageGeodesicDistance该特征用于描述面片之间的离散程度。在一个实施例中,可以计算曲面所有面片中心之间,对应的平均测地线距离。还可以把均方距离和占不同距离百分比范围的值作为特征。然后,进行归一化。6)ShapeContexts在一个实施例中,可以针对每一个面片,计算其他面片对应的分布(辅以面积权重),分别用面片法向量的角度和对数化测地线距离来描述。在一个实施例中,可以建立6个测地线距离区间和6个角度区间。7)SpinImages在一个实施例中,可以根据以下方法进行计算。首先,以顶点P法向量为中轴建立柱面坐标系。然后,根据以下方程式(17)把3D点投射到2DSpinImage上,其中,α表示到法向量n的径向距离,β表示到切平面的轴向距离,n表示经过P点的法向量,X表示3D点的坐标(x,y,z)。8)坐标特征在一个实施例中,可以加入以下7项坐标特征:顶点的x、y、z坐标值、坐标原点到顶点的距离r、经过坐标原点和顶点的直线与z轴的夹角θ、经过坐标原点和顶点的直线与y轴的夹角及基于以上,可以得到共600项特征,构成20×30的特征矩阵。特征维数请参下表1:特征CURPCASCAGDSDFDISSICD总维数维数64482701572241007600特征提取完成后,可以把提取到的特征输入经训练的卷积神经网络进行分类/分割。在107中,利用经训练的卷积神经网络分割牙颌三维数字模型。在一个实施例中,可以基于caffe深度学习平台和python语言搭建卷积神经网络。请参图2,示意性地展示了本申请一个实施例中的卷积神经网络200的结构。卷积神经网络200依次包括以下11个层:输入层201、卷积层203、卷积层205、池层207、卷积层209、卷积层211、池层213、全连接层215、dropout层217、全连接层219、softmax层221以及输出层223。采用“卷积层-卷积层-池层”的结构能够降低对局部特征的敏感性,提高计算效率,不易过拟合,减少噪声影响。在该实施例中,采用4层卷积层以充分分析特征数据,获取局部信息,得出较佳的权重。采用2层池化层能够保留一部分全局信息,并具有一定的防止过拟合效果。相比于“全连接层-全连接层”结构,“全连接层-dropout-全连接层”结构能在一定程度防止过拟合,增加预测准确率。dropout层具有一定的防止过拟合的作用。在一个实施例中,softmax层可以根据实际需求设置参数的类型。在一个实施例中,可以如此定义卷积层的参数:[卷积核高,核宽,特征通道数,卷积核数量]。在一个实施例中,可以把卷积层203的参数设置为[3,5,1,6],把卷积层205的参数设置为[3,3,16,32],可以把卷积层209的参数设置为[3,3,32,64],可以把卷积层211的参数设置为[3,3,64,128]。在一个实施例中,可以如此定义池层的参数:[池化核高,核宽,池化类型]。在一个实施例中,可以把池层207的参数设置为[2,2,max],可以把池层213的参数设置为[2,2,max]。在一个实施例中,可以如此定义全连接层的参数:[输入数量,输出数量]。在一个实施例中,可以把全连接层215的参数设置为[1024,100],可以把全连接层219的参数设置为[100,2(or8)]。在一个实施例中,可以如此定义dropout层的参数:[丢弃百分比]。在一个实施例中,可以把dropout层217的参数设置为[0.5]。在一个实施例中,可以采用PReLU激活函数,能够在一定程度上避免梯度消失现象。在一个实施例中,为提高分类精度,可以采用两个模型。第一模型针对牙齿和牙龈进行二分类,第二模型针对牙齿进行八分类(中切牙、侧切牙、尖牙、第一前磨牙、第二前磨牙、第一磨牙、第二磨牙以及第三磨牙)。把提取的特征输入第一模型获得二分类结果,然后把二分类结果输入第二模型获得八分类结果。可以理解,第二模型也可以进行十六分类,直接对左边和右边的八颗牙齿进行分类。在一个实施例中,第一模型和第二模型可以均采用图2所示的卷积神经网络200的结构。把在105中提取的特征输入第一模型可获得二分类结果。把处理后的二分类结果输入第二模型可获得八分类结果。在构建卷积神经网络模型后,可以对其进行训练,使其能够分割牙颌三维数字模型。在一个实施例中,可以把卷积神经网络的训练参数设置如下(括号内为参数赋值):学习率(0.01)、momentum(0.9)、weight_decay(0.005)、lr_policy(poly)、power(0.75)、solver_mode(GPU)。在一个实施例中,可以用分割完成的牙颌三维数字模型,比如人工分割的牙颌三维数字模型,训练卷积神经网络。将105中提取的特征输入经训练的卷积神经网络就可对牙颌三维数字模型进行分割。通过卷积神经网络得出的面片的预测值只能大致区分牙颌各部分的区域,其本身可能并不连续,因此可以对得到的预测值进行优化。请参由Y.Boykov、O.Veksler、以及R.Zabih于2001年在IEEETPAMI23,11,1222–1239上发表的《FastApproximateEnergyMinimizationViaGraphCuts》,可以采用其中的multilabelgraph-cut方法进行多类别优化。请再参由KanGuo、DongqingZhou以及XiaowuChen在AcmTransactionsonGraphics,35(1);3,2015上发表的《3DMeshLabelingViaDeepConvolutionalNeuralNetworks》,能量函数可参考其中MeshLabelOptimization的定义。令T表示模型面片集合,t为某一面片,lt和pt表示将t标记为lt及其预测概率pt,Nt表示t的相邻面片。可以建立如下最小化能量函数:其中,λ为非负数。在一个实施例中,在牙齿牙龈二分类阶段,可以设置λ=20;去除牙龈后,在牙齿八分类阶段,可以设置λ=100;映射回原模型阶段,可以设置λ=50。其中,方程式(18)中的第一项可以定义如下,ξU(pt,lt)=-log10(pt(lt))方程式(19)其中,方程式(18)中的第二项可以定义如下,其中,v代表面片t的邻域的某一个面片。在去除牙龈之后,根据牙齿的对称性把面片分成了八类,但并没有区分牙齿的左右。由于牙齿模型沿着某一根轴左右对称,所以可以根据左右信息来进一步区分十六类牙齿。若以Y轴作对称轴为例,除了门牙之外的所有都可以用牙齿在X轴的正负来区分。对于门牙,可以在3D模型上建立一条最好的分割线来区分,依据X轴坐标信息,建立如下最小化能量函数:在一个实施例中,可以设X轴坐标大于零为左,反之为右。对于方程式(21)中的第一项而言,可以定义如下:Pt=P′t(maxProb-minProb)+0.5*(maxProb+minProb)方程式(23)其中,ftx表示t中心点的X轴坐标,可以把maxWidth的默认值设为12,把minProb的默认值设为10-8,maxProb=1-minProb。在一些情况下,相邻牙齿上的面片可能被分类到同一牙齿。这时,需要对这些面片进行识别并赋予正确的标记。实验发现这样三个现象:(一)牙齿粘连一般发生在相邻牙齿;(二)标记预测错误现象基本只偏移一个位置;(三)当只有一颗第二前磨牙时,容易将第二前磨牙预测为第一前磨牙。在一个实施例中,可以采用PCA分析来确定是否存在牙齿未分开的情况。对每颗预测牙齿进行PCA分析,并将最长轴投影到XY平面上,与预先设定的阈值进行比较(不同牙齿长度阈值不同),若投影后最长轴的长度比预设的阈值大,则认为牙齿可能存在粘连情况。在一个实施例中,可以采用graph-cut进行分割。可以基于以下最小化能量函数找到最佳的分割边界:该最小化能量函数与牙齿左右分割十分相似,其第二项的定义与方程式(18)所表达的最小化能量函数的第二项一致。在一个实施例中,在PCA分析时可以令长轴与Y轴成锐角,则粘连牙齿Y坐标偏小的下标定义为samll_idx,反之big_idx,同时令PCA分析获得的最长轴在XY平面上的投影的法向为OBB包围盒中心为COBB。对于方程式(25)的第一项而言,可以定义如下:Pt=P′t(maxProb-minProb)+0.5*(maxProb+minProb)方程式(27)其中,其中ft代表t中心点坐标,λ默认值为50,minProb默认值为10-8,maxProb=1-minProb。分割完牙齿后,可以进一步验证牙齿的边界是否合适。对于每颗牙齿,可以设定两个阈值,一是分割边界的PCA分析的最长轴不能超过的阈值,二是分割后得到的两个牙齿的表面积都应大于的阈值。若不满足上述两个条件,则认为该分割边界是错误的,认为该部分牙齿不存在粘连情况。分割完牙齿后,可以给牙齿标记。假定原标记编号为l,则分开的两颗牙齿的标记只有两种可能,(l-1,l)或(l,l+1),其中,l属于[1,8],门牙为1,第三磨牙为8。从门牙开始计数,令排在该牙齿前的牙齿个数为Countprev,之后的为Countnext,可以设计如下规则逐一判断:1.若Countprev+Countnext≥7,则labelnew={l.l},即无粘连情况;2.若上述不成立且Countnext+l=8,则labelnew={l-1.l};3.若上述不成立且Countprev=l-1,则labelnew={l.l+1};4.若上述不成立且相邻牙齿有Toothidx=l-1,则labelnew={l.l+1};5.若上述不成立,令其中编号较小的牙齿上,属于l的预测的表面积为Areal-1,now_idx,属于l-1的预测的表面积为Areal-1,small_idx,则有同理,在编号较大的牙齿上,属于l的预测的表面积为Areal,now_idx,属于l+1的预测的表面积为Areal,big_idx,则有若ratio1>ratio2,则labelnew={l.l+1},反之,labelnew={l-1.l}。在新的标记赋值过程中,还可能检测出一些明显预测错误的情况。1.当预测值为第三磨牙,但其直接相邻的牙齿为第一磨牙,则可以将第三磨牙更改为第二磨牙。2.在实际工程中,由于第二前磨牙常常被错误标记为第一磨牙。所以,当前磨牙只有一颗且与第一磨牙紧密相连时,则可以将该前磨牙标记为第二前磨牙。在简化模型完成牙齿分割后,将分割结果映射回原模型。由于简化模型和原模型的坐标是对应的,所以可以用ApproximateNearestNeighbor(简称“ANN”)算法将标记映射回原模型,同时将概率也映射回原模型。在完成从简化模型到原模型的映射之后,可以在原模型上再次做标记优化。由于简化模型和原模型的坐标是对应的,所以在原模型上的预测标记可以近似看成在简化模型上距离最近的面片。为提高查找效率,我们采用ANN算法寻找近似解。在映射回原模型的过程中,还将在简化模型上的预测概率同时映射回原模型。为尊重简化模型上的优化结果,在映射过程中,牙齿面片预测为l的概率增加一个固定值(除了边界的一个小邻域),再对概率进行归一化处理。需要注意的是,由于边界的预测并不可靠,所以在边界处的映射概率始终保持不变。简化模型经过标记优化过程后,还是可能在边界处产生一些问题。如牙齿三角区域(牙齿间牙龈乳突部分)有残留或者边界不平滑。因此,可以对边界进行优化。在一个实施例中,边界优化可以包括两个部分,一是用改进的模糊聚类算法(FuzzyClusteringAlgorithm)优化牙齿间残留区域或补充牙齿边界的缺口,二是采用最短路径平滑边界。请参由SagiKatz和AyelletTal在AcmTransactionsonGraphics,22(3):954{961,2003发表的《HierarchicalMeshDecompositionUsingFuzzyClusteringAndCuts》,可以采用FuzzyClusteringandCutsAlgorithm在一个模糊区域寻找最优边界。因此,对每颗牙齿进行优化可以寻找这样一个模糊区域,这个模糊区域既要包括牙齿的真正边界,同时也要尽可能小,这样模糊区域才能比较精准。另外,由于牙齿边界形态各异,有些边界本身比较平坦,仅靠以上文献中的方法可能无法保持这样一个边界情况,所以还需要尊重神经网络预测的结果。对于模糊区域边界面片,假设与置信牙齿区域相连的面片集为S,与置信牙龈区域或者其他牙齿相连的面片集为T。要在模糊区域寻找较佳的分割边界,也可以采用GraphCut算法,因此可以建立与方程式(6)相似的以下最小化能量函数:E(x)=∑i∈νEunary(i)+λ∑(i,j)∈εEpairwisenew(i,j)方程式(31)其中,Epairwisenew(i,j)=ωEpairwise(i,j)方程式(32)其中,其中,其中η为一个较小的正数,αij为相邻面片i、j的法向夹角。值得注意的是,对于T集合内的面片而言,与其他牙齿相连的面片与T端的Epairwise的数量级要小一点。ω表示改进的模糊聚类算法参数,它在一定程度上参考了神经网络的预测结果,即计算面片与预测边界线的距离,作为上述公式中Epairwise的权重。其中,x表示面片中心点距离预测边界的最短测地线距离,单位为mm,σ为一固定值,默认为0.05。相邻面片的夹角在很大程度上反映了局部特征,因此对边界进行优化时将相邻面片的夹角作为优化计算的一个分量,能够更好地优化边界。对每颗牙齿进行优化,为了比较精确的定位模糊区域,可以采用类似双向广搜的思想,即从当前边界和可能的边界双向广搜。可能的边界指的是在该牙齿或牙龈内极大曲率在一定阈值范围内的顶点,所以若该边界已经是牙齿与牙齿间的边界,则该区域不能是可能的边界,故需除去这一部分区域,令该区域为保护区域。在一个实施例中,可以采用以下算法来寻找牙齿模糊区域。经过改进的模糊聚类算法优化后,边界可能还存在不平滑区域。因此,还可以采用去除凸点和最短路径的思想优化牙齿边界。对于一个面片,若其相邻的两个面片的标记相同,且与其自身的标记不同,那么该三个面片的共同顶点为凸点。经过几次迭代后,凸点能够被消除。去除凸点只能局部优化边界,所以还可以使用最短路径的思想,对原边界进行平滑。可以在边界的窄带邻域内应用最短路径算法。请参图3,对于每一个牙齿,寻找窄带邻域的方法是,对于其边界上每一个顶点v,计算出两个夹角α和β,将大于一定阈值的α和β对应的边界点的1邻域或2邻域顶点加入窄带区域。找到窄带区域后,在该区域内使用最短路径法,寻找新边界。在该方法中,边v1v2的长度e可定义为:其中,其中,α为边v1v2相邻两个面片法向的夹角,η为一个很大的正数。引入角度距离的基本思想是α越小,边长越短。至此得到分割完成的牙颌三维数字模型。由于本申请中方程式较多,基于以上详细说明可以理解,不同方程式中的相同符号可能代表不同的意义,不同方程式中不同的符号可能代表相同的意义。可以理解,适用于分割牙颌三维数字模型的具有深度学习能力的人工神经网络的种类和结构有多种,各阶段的简化方法和优化方法也多种多样,因此,本申请的保护范围并不局限于以上的具体实施例。本申请引用了以下与人工神经网络相关的文献,其内容被并入本申请:[1]EvangelosKalogerakis,AaronHertzmann,andKaranSingh.Learning3DMeshSegmentationandLabeling.ACMTransactionsonGraphics,29(3),2010.[2]Y.Boykov,O.Veksler,andR.Zabih.2001.FastApproximateEnergyMinimizationViaGraphCuts.IEEETPAMI23,11,1222–1239.[3]SagiKatzandAyelletTal.HierarchicalMeshDecompositionUsingFuzzyClusteringandCuts.AcmTransactionsonGraphics,22(3):954{961,2003.[4]KanGuo,DongqingZhou,andXiaowuChen,3DMeshLabelingViaDeepConvolutionalNeuralNetworks.AcmTransactionsonGraphics,35(1);3,2015.尽管在此公开了本申请的多个方面和实施例,但在本申请的启发下,本申请的其他方面和实施例对于本领域技术人员而言也是显而易见的。在此公开的各个方面和实施例仅用于说明目的,而非限制目的。本申请的保护范围和主旨仅通过后附的权利要求书来确定。同样,各个图表可以示出所公开的方法和系统的示例性架构或其他配置,其有助于理解可包含在所公开的方法和系统中的特征和功能。要求保护的内容并不限于所示的示例性架构或配置,而所希望的特征可以用各种替代架构和配置来实现。除此之外,对于流程图、功能性描述和方法权利要求,这里所给出的方框顺序不应限于以同样的顺序实施以执行所述功能的各种实施例,除非在上下文中明确指出。除非另外明确指出,本文中所使用的术语和短语及其变体均应解释为开放式的,而不是限制性的。在一些实例中,诸如“一个或多个”、“至少”、“但不限于”这样的扩展性词汇和短语或者其他类似用语的出现不应理解为在可能没有这种扩展性用语的示例中意图或者需要表示缩窄的情况。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1