一种融合学术专长与社会网络的评审分配方法与流程
本发明涉及一种融合学术专长与社会网络的评审分配方法,属于计算机应用技术、论文/项目评审管理应用领域。
背景技术:
目前,国家和高校越来越重视学术及科学研究,论文和项目申请数量也逐年增多,在有限时间内将论文/项目分配给合适的评审成为困扰会议、期刊、项目组织者的难题。评审专家的审阅意见是论文录用或者项目授予的直接依据,因此确保评审结果的公正性、权威性,是组织者一直以来关注的重点。面对大量的论文/项目以及繁重的组织工作,利用计算机技术进行评审分配已成为趋势,但现有的方法大多是在满足用户设定的约束条件前提下,计算论文/项目与专家的专业领域相似度,作为评审分配的主要依据。在论文/项目的作者/申请人与专家存在现实中的直接或间接的学术交流的情况下,专家的主观因素会影响到评审过程的客观性,导致评审结果难免出现偏差。
论文/项目合作数据库记录了大量公开发布的文献资料,包含文章标题、文章作者及合作者、会议/期刊论文集、会议/期刊名称及发布时间等信息;该数据库中的论文/项目的作者/申请人包含了待分配的论文/项目的作者/申请人与专家,以及其他论文/项目的作者/申请人;利用论文/项目的作者/申请人与专家的合作路径,能够很好地反映出论文/项目的作者/申请人与专家在现实中的直接或间接的学术交流情况。
本方法基于论文/项目合作数据库建模社会网络,计算出论文/项目的作者/申请人与专家的合作距离;通过最大化论文/项目与专家的合作距离,降低专家的主观因素,提高了评审过程的客观性;同时结合专业领域标签,最大化论文/项目与专家的标签相似度,为评审分配提供系统全面、科学有效的解决方案。
与本文相关的论文主要有两篇,下文分别对这两篇论文进行剖析:
论文(1):全国青年管理科学与系统科学学术会议,2007年,作者张正文、唐锡晋,标题为论文分配的支持方法研究。该论文首先计算论文关键词向量和评审知识结构关键词向量之间的相似度作为客观相似度;接着根据评审之间是否有合作或发表过包含相同或同义的关键词,构建社会网络,以评审之间的知识结构关键词向量的相似度为权值,计算最大权值路径作为评审的主观相似度;最后结合评审个人倾向,计算综合相似度,按照递减排序进行评审分配。该论文所用方法虽然构建了结合了社会网络,但是该社会网络仅是用来计算评审之间的相似度,所用评审分配方法的主要依据是专家个人倾向、论文与评审或评审之间的关键词向量相似度,没有考虑论文作者与评审的学术交流情况。
论文(2):北京交通大学硕士学位论文,2014年,作者夏雷,标题为基于二部图匹配和聚类的论文分配方法研究。该论文构建论文与专家二部图网络,以边的权重作为分配权重;分配权重依据基础权重(值为1)、专家倾向、论文作者与专家是否同单位、论文与专家的研究领域进行计算;基于二部图的匈牙利算法和km算法,设计均衡分配算法实现了评审分配。该论文所用方法虽然构建了论文与评审的二部图网络,但是该二部图网络的权重计算的主要依据仍是个人倾向、论文与评审的研究领域相似度,依然没有考虑论文作者与评审的学术交流情况。
上述已有的评审分配方法虽然解决了按照论文/项目与专家的专业领域的进行评审分配的问题,但均没有考虑到论文/项目的作者/申请人与专家存在现实中的直接或间接的学术交流的情况,没有将学术专长和社会网络进行深度融合,很可能因专家的主观因素而影响评审结果的客观性。因此,评审分配方法具有很大的改进空间。本发明的目的是即是致力于解决上述评审分配方法的缺陷,提出一种融合学术专长与社会网络的评审分配方法。
技术实现要素:
本发明旨在解决已有的评审分配方法没有考虑论文/项目的作者/申请人与专家的学术交流而影响评审分配的客观性的缺陷,提出了一种融合学术专长与社会网络的评审分配方法。
一种融合学术专长与社会网络的评审分配方法,简称本方法,核心内容为:基于论文/项目合作数据库建模社会网络,提出论文/项目与专家的合作距离;综合论文/项目与专家的相似度与合作距离,提出论文/项目与专家的匹配度,确定最优化目标;采用最大匹配度优先与最小差调整算法,得出论文/项目的最优评审分配结果;本方法能够在满足论文/项目的作者/申请人与专家无合作、非师生、不属于同一机构的约束条件下,实现均衡评审分配,最大化评审分配的标签相似度和与合作距离和,确保评审结果的客观、公平、公正。
为实现上述目的,本方法包括如下步骤:
步骤1:根据给定数据集,建立标签集、带标签的论文/项目集与专家集,以及论文/项目集的作者/申请人集;得出论文/项目数及专家数、标签相似度矩阵以及论文/项目-专家的标签相似度;
其中,标签集,记为t;论文/项目集,记为p;专家集,记为r;论文/项目集p的作者/申请人集,记为a;集合大小|t|=h,|p|=g,|r|=f,|t|代表标签集t的大小,|p|代表论文/项目集p的大小,|r|代表专家集r的大小,且标签集t、论文/项目集p以及专家集r的大小,分别记为h,g,f,h,g及f均为大于1的整数常量;
对p中的任何一篇论文/项目p,p的标签集表示为t(p),p的作者/申请人集表示为a(p),|a(p)|为大于1的整数且不唯一,|a(p)|代表作者/申请人集a(p)的大小;对r中的任一专家r,r的标签表示为t(r);且
标签相似度矩阵,记为s[h][h];其中每个元素表示相应的一对标签的相似度,可以由用户设定或者通过论文/项目合作关系数据库统计计算得到;
其中,论文/项目-专家的标签相似度,定义为论文/项目p与专家r的标签相似度的最大值,用公式(1)表示:
s(p,r)=maxs[ti][tj],ti∈t(p),tj∈t(r);(1)
其中,s(p,r)代表论文/项目p与专家r的标签相似度的最大值,max是求最大值的函数,s[ti][tj]代表相似度矩阵中标签ti和标签tj的相似度;其中,ti代表t(p)中第i个标签,tj代表t(r)中第j个标签;下标i,j为大于等于0,小于h的整数变量;
步骤2:建模社会网络,确定最大合作距离,得出论文/项目集的作者/申请人-专家的合作距离数组及论文/项目-专家的合作距离;
其中,建模社会网络可以通过论文/项目合作关系数据库获得,具体为:
社会网络,记为g,g=(v,e)为权值为1的无向网;其中节点集,记为v,|v|=n,|v|表示节点集v的大小,n为大于1的整数常量;每个节点代表一位作者/申请人;且步骤1中的专家集
任意两名作者/申请人的合作距离定义为相应的两个节点之间的最短路径;最大合作距离,记为maxd,如果两个节点之间不可达或者最短路径值大于maxd,则合作距离设为maxd;最大合作距离由用户给定;
计算论文/项目集的作者/申请人-专家的合作距离数组d[g][f],其中,每个元素d[p][r],是由论文/项目p的作者/申请人与专家r的合作距离组成的向量;元素d[p][r]的长度为|a(p)|,a(p)代表论文/项目p的作者/申请人集;
论文/项目-专家的合作距离定义为论文/项目p的作者/申请人与专家r的合作距离组成的向量中的最小值,用公式(2)表示:
d(p,r)=mind[p][r];(2)
其中,d(p,r)代表论文/项目p与专家r的合作距离,min是求最小值的函数;
步骤3:确定约束条件,计算论文/项目-专家的指示关系;
其中,约束条件为论文/项目的任一作者/申请人与专家无合作发表论文/申请项目、非师生关系、不属于同一机构;论文/项目的作者/申请人与专家是否无合作,可通过论文/项目-专家的合作距离得出;论文/项目的作者/申请人与专家是否非师生关系、不属于同一机构的条件由用户给定;
其中,论文/项目-专家的指示关系,记为b(p,r),表示论文/项目p的任一作者/申请人a与专家r是否满足无合作发表论文/申请项目、非师生关系、不属于同一机构的约束条件;不满足约束条件,值为1,表示存在论文/项目p的作者/申请人a与专家r有关系,则不可分配;满足约束条件,值为0,表示论文/项目p的任一作者/申请人a与专家r没有关系,则可分配;论文/项目-专家的指示关系定义用公式(3)表示:
其中,p为论文/项目,r为专家,a是p的作者/申请人集a(p)中的作者/申请人;
步骤4:确定步骤1中的论文/项目集中每篇论文/项目的审阅数、论文/项目数及专家数,计算平均审阅数及冗余审阅数;
其中,每篇论文/项目的审阅数,记为k,k为整数常量且k>1;
平均审阅数,记为averagenum,平均审阅数的计算公式为(4):
其中,
冗余审阅数,记为remainnum,冗余审阅数的计算公式为(5):
remainnum=(k×g)%f;(5)
其中,(k×g)%f表示(k×g)对f取整数类型余数;
为了保证均衡分配,专家集r中每名专家r的审阅数,记为r.num,r.num等于averagenum或averagenum-1;审阅数等于averagenum的专家子集,记为ra,|ra|等于remainnum,|ra|表示ra的大小;
步骤5:根据步骤1中论文/项目-专家的标签相似度、步骤2中论文/项目-专家的合作距离及最大合作距离,确定论文/项目-专家的匹配度;
其中,论文/项目-专家的匹配度用公式(6)表示:
其中,m(p,r)代表论文/项目p与专家r的匹配度,d(p,r)代表代表论文/项目p与专家r的合作距离,s(p,r)代表代表论文/项目p与专家r的标签相似度,max是求最大值的函数;α为平衡参数,由用户给定;从公式(6)可以看出,论文/项目与专家的标签相似度越高、合作距离越远,匹配度m(p,r)就越高;
步骤6:建立结果集并将其初始化为空,初始化结果集的匹配度和、标签相似度和、合作距离和为零;
其中,结果集存储最优分配方案,记为result,是由二元组<p,r>组成的集合;结果集result的形式为:
其中,分配给论文/项目pi的专家集,记为
结果集result的匹配度和,记为summatching,用公式(7)表示:
其中,
结果集result的标签相似度和,记为sumsimilarity,用公式(8)表示:
其中,
结果集result的合作距离和,记为sumdistance,用公式(9)表示:
其中,
步骤7:根据步骤3中论文/项目-专家的指示关系、步骤4中平均审阅数及冗余审阅数、步骤6中结果集的匹配度和,确定最优化目标;
其中,评审分配的最优化问题为,在满足约束条件下,实现均衡评审分配,最大化论文/项目与专家的标签相似度和、合作距离和;
本方法综合论文/项目与专家的标签相似度与合作距离,将最优分配方案的目标转化为:在满足约束条件下,实现均衡评审分配,最大化结果集result的匹配度和;此最优化分配问题用公式(10)表示:
公式(10)中,第一行表示最优化目标是最大化结果集的匹配度和,其中,summatching代表结果集result的匹配度和,max是求最大值的函数;第二行至第七行为最优化目标的约束条件,其中i,j为大于等于0小于g的整数变量,s,t为大于等于0小于k的整数变量,上标s,t表示序号,下标pi,pj分别表示论文/项目集中的第i与j篇论文/项目,
步骤8:建立论文/项目-专家的分配数组,记录论文/项目-专家的分配状态、匹配度、标签相似度与合作距离,并将分配数组中的元素初始化为零向量;
论文/项目-专家的分配数组,记为q[g][f];分配数组的每个元素是由论文/项目-专家的分配状态、匹配度、标签相似度与合作距离组成的向量:论文/项目-专家的分配状态,记为selected(1已分配、0可分配、-1不可分配);论文/项目-专家的匹配度,记为m;论文/项目-专家的标签相似度,记为s;论文/项目-专家的合作距离,记为d;初始化分配数组的每个元素为零向量,即(0,0,0,0);
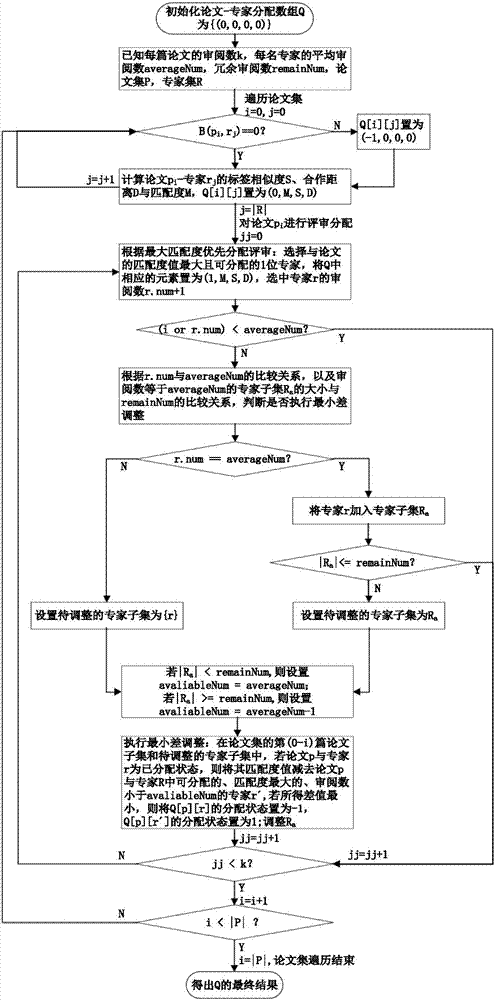
步骤9:遍历论文/项目集,在满足最优化目标的约束条件的前提下,依次进行评审分配,并得出论文/项目-专家的分配数组的最终结果;
其中,最优化目标的约束条件为公式(10)中的第二行至第七行;
对于论文/项目集p中的每篇论文/项目pi,0≤i<g,依次进行评审分配,具体按照以下步骤执行:
步骤9.1:对于专家集r中的每名专家rj,0≤j<f,若b(pi,rj)==0,则计算论文/项目pi-专家rj的标签相似度s、合作距离d和匹配度m,将q[i][j]置为(0,m,s,d);若b(pi,rj)==1,则将q[i][j]置为(-1,0,0,0);其中,pi表示论文/项目集中的第i篇论文/项目,rj表示专家集中的第j名专家;
步骤9.2:为论文/项目pi分配k位评审,0≤jj<k,执行最大匹配度优先与最小差调整算法,具体为:
步骤9.2.1:根据最大匹配度优先分配评审,具体为:选择与论文/项目pi的匹配度最大且可分配的1位专家r,将q中相应的元素的selected置为1,选中专家r的审阅数r.num加1;
步骤9.2.2:若i<averagenum或选中专家r的审阅数小于averagenum,不用调整,转至步骤9.2.5;
步骤9.2.3:根据选中专家r的审阅数与averagenum的比较关系,以及审阅数等于averagenum的专家子集ra的大小与remainnum的比较关系,判断是否执行最小差调整;若需要调整,则设置待调整的专家子集;否则转至步骤9.2.5;具体为:
①若选中专家r的审阅数等于averagenum,将专家r加入审阅数等于averagenum的专家子集ra;加入后,若|ra|≤remainnum,不用调整,转至9.2.5;若|ra|>remainnum,需要调整,设置待调整的专家子集为ra;
②若选中专家r的审阅数大于averagenum,需要调整,设置待调整的专家子集为{r};
步骤9.2.4:根据最小差原则调整分配状态;
其中,最小差原则为:首先,若|ra|<remainnum,设置最小差调整的专家审阅数为available=averagenum;若|ra|≥remainnum,设置最小差调整的专家审阅数为available=averagenum-1;其次,在论文/项目集的第(0-i)篇论文子集和待调整的专家子集中,若论文/项目p与专家r为已分配状态,则将论文/项目p与专家r的匹配度值,减去p与专家集r中可分配的、匹配度最大的且审阅数小于available的专家r′的匹配度,若所得差值最小,则将q[p][r]的分配状态置为-1,q[p][r′]的分配状态置为1;根据调整后专家r的审阅数r.num以及专家r′的审阅数r′.num,调整ra;
步骤9.2.5:jj=jj+1;若jj<k,转至步骤9.2.1;
步骤9.3:i=i+1;若i<g,转至步骤9.1;
步骤10:根据步骤9得出的论文/项目-专家的分配数组的最终结果,计算得结果集,以及结果集的匹配度和、标签相似度和、合作距离和;
根据论文/项目-专家的分配数组q的最终结果,可得最优评审分配的结果集result,计算对应的匹配度和summatching、标签相似度和sumsimilarity、合作距离和sumdistance,输出结果;
至此,从步骤1到步骤10,完成了一种融合学术专长与社会网络的评审分配方法。
有益效果
一种融合学术专长与社会网络的评审分配方法,与现有技术对比,本方法具有如下有益效果:
1.本方法基于论文/项目数据库建模社会网络,提出论文/项目的作者/申请人与专家的合作距离,应用于评审分配方法中,可以降低专家的主观因素,提高了评审过程的客观性;
2.相较于仅依靠专业领域相似度进行评审分配的方法相比,本方法综合考虑论文/项目与专家的标签相似度与合作距离,提出论文/项目与专家的匹配度,确立了更加全面的最优化目标;
3.本方法设计了最大匹配度优先与最小差调整算法,能够在满足最优化目标的约束条件下,实现均衡评审分配,最大化结果集的标签相似度和与合作距离和,提供更加合理的评审分配方案;
4.本方法适用于不同形式的学术会议、期刊及项目的评审分配场景中,应用范围广,实用性强,易于推广。
附图说明
图1为本发明“一种融合学术专长与社会网络的评审分配方法”中的评审分配方法及实施例1的流程示意图;
图2为本发明“一种融合学术专长与社会网络的评审分配方法”中的最大匹配度优先与最小差调整算法及实施例4的流程示意图。
具体实施方式
下面根据附图及实施例对本发明进行详细说明,但本发明的具体实施形式并不局限于此。
实施例1
本实施例详细阐述了本发明“一种融合学术专长与社会网络的评审分配方法”应用于某学术会议在论文评审管理时的评审分配的流程。
图1为本方法的算法流程图以及本实施例的流程图;从图中可看出,本方法包含如下步骤:
步骤a:给定4个标签、带标签的10篇论文和7名专家,每篇论文由2名作者共同完成,建立标签集、带标签的论文集与专家集,以及论文集的作者集;得出论文数及专家数、标签相似度矩阵以及论文-专家的标签相似度;
具体到本实施例,建立标签集t={a,b,c,d},带标签的论文集p={p0,p1,p2,p3,p4,p5,p6,p7,p8,p9},带标签的专家集r={r0,r1,r2,r3,r4,r5,r6};集合大小|t|=4,|p|=10,|r|=7;建立论文集的作者集:a={a(p0),a(p1),a(p2),a(p3),a(p4),a(p5),a(p6),a(p7),a(p8),
论文集p的标签t(p)={t(p0),t(p1),t(p2),t(p3),t(p4),t(p5),t(p6),t(p7),t(p8),t(p9)}={(a,b),(a,c),(d),(b,c),(a,b),(c,d),(b),(a),(b,d),(c)};专家集的r标签t(r)={t(r0),t(r1),t(r2),t(r3),t(r4),t(r5),t(r6)}={(a),(b),(c),(d),(a),(c),(d)};
根据论文合作数据库统计计算得标签相似度矩阵s[4][4]:
根据论文-专家标签相似度定义,可得论文-专家的标签相似度s(p,r):
步骤b:基于论文合作数据库建立包含200个节点、5000条边的权值为1的无向社交网络g,给定最大合作距离maxd=50,得出论文集的作者-专家的合作距离数组d[10][7]及论文-专家的合作距离d(p,r);
步骤c:给定作者与专家无合作、非师生、不属于同一机构的约束条件,计算论文-专家的指示关系;
具体到本实施例,论文p5中的作者
步骤d:确定每篇论文的审阅数k=3,论文数为10,专家数为7,计算平均审阅数及冗余审阅数;
具体到本实施例,计算平均审阅数
步骤e:根据步骤a中论文-专家的标签相似度、步骤b中论文-专家的合作距离及最大合作距离,确定论文-专家的匹配度;
具体本实施例,论文-专家的标签相似度为s(p,r),步骤2中论文-专家的合作距离d(p,r)及最大合作距离maxd=50,给定平衡参数α=0.5,论文-专家的匹配度计算公式为:
步骤f:建立结果集result,初始化为空;初始化结果集的匹配度和、标签相似度和、合作距离和为零;
具体本实施例,结果集result存储最优分配方案,是由10个二元组<p,r>组成的集合;结果集result的形式为:
其中分配给论文pi的专家集
初始化结果集的匹配度和summatching、标签相似度和sumsimilarity、合作距离和sumdistance为0;
步骤g:根据步骤c中论文-专家的指示关系、步骤d中平均审阅数及冗余审阅数以及步骤f中结果集的匹配度和,确定最优化目标;
步骤h:建立论文-专家的分配数组q[10][7],用来存储论文-专家的分配状态selected(1已分配、0可分配,-1不可分配)、匹配度m、标签相似度s与合作距离d;初始化分配数组的每个元素为零向量,即(0,0,0,0);
步骤i:遍历论文集,在满足最优化目标的约束条件的前提下,依次进行评审分配,并得出论文-专家的分配数组的最终结果;
对于论文集p中的每篇论文pi,0≤i<10,依次进行评审分配,具体按照以下步骤执行:
步骤i.1:对于专家集r中的每名专家rj,0≤j<7,若b(pi,rj)==0,则计算论文pi-专家rj的标签相似度s、合作距离d与匹配度m,将q[i][j]置为(0,m,s,d);若b(pi,rj)==1,则将q[i][j]置为(-1,0,0,0);
具体到本实施例,当i=5时,0≤j<7,计算后,q为:
步骤i.2:为论文pi分配3位评审,执行最大匹配度优先与最小差调整算法;
步骤i.3:i=i+1;若i<10,转至i.1;
步骤j:步骤i得出的论文-专家的分配数组的最终结果,计算得结果集,以及结果集的匹配度和、标签相似度和、合作距离和;
具体到本实施例,论文-专家的分配数组q[10][7]的最终结果为:
计算的最优评审分配的结果集result,即为最优分配结果:
{<p0,{r0,r1,r4}>,<p1,{r2,r3,r5}>,<p2,{r3,r5,r6}>,<p3,{r1,r2,r5}>,<p4,{r0,r2,r4}>,
<p5,{r0,r2,r6}>,<p6,{r3,r4,r6}>,<p7,{r0,r4,r6}>,<p8,{r1,r3,r4}>,<p9,{r1,r2,r5}>}
计算结果集result对应的匹配度和summatching=18.49,标签相似度和sumsimilarity=26.8,合作距离和sumdistance=509。
实施例2
本实施例按照实施例1所述的参数,具体阐述了本发明步骤2定义的论文/项目-专家的合作距离及实施例1的步骤b中的论文-专家的合作距离的计算过程。
具体过程为:社会网络g=(v,e),节点集|v|=200,且专家集
根据定义,计算得论文-专家的合作距离d(p,r):
如果不考虑论文-专家的合作距离,仅考虑最大化论文-专家的标签相似度,进行评审分配,则专家很可能因为主观因素而影响对论文的评审的客观性;其中论文-专家的标签相似度由实施例1的s(p,r)得出;
具体到本实施例,论文p6与专家r1的标签相似度为1,则论文p6会被分配给专家r1进行评审;而论文p6与专家r1的合作距离为1,表示论文p6与专家r1有合作,在现实中存在学术交流,则专家r1很可能会受到主观因素的影响而提高对论文p6的评审分数;同样,论文p1与专家r0、论文p4与专家r1、论文p8与专家r6的标签相似度均为1,而论文p1与专家r0、论文p4与专家r1、论文p8与专家r6的合作距离分别为3、4、3,论文的作者与专家有较短的合作路径,则很可能存在现实中的学术交流;如果仅按照最大化论文-专家的标签相似度进行评审分配,则不能保证评审的客观性;而实施例1中按照本发明所用评审分配方法得出的评审分配结果,论文p1,p4,p6,p8没有分配给相应的专家r0,r1,r1,r6,因而降低了专家的主观因素,提高了评审过程的客观性。
实施例3
本实施例按照实施例1所述的参数,具体阐述了本发明步骤5定义的论文/项目-专家的匹配度、步骤7定义的最优化目标及实施例1的步骤e的论文-专家的匹配度、步骤g确定的最优化目标。
具体到本实施例,步骤e:论文-专家的匹配度计算公式为:
步骤g:评审分配的最优化目标为:
maxsummatching
st.for0≤i,j<10andi≠j,0≤s,t<3ands≠t,that
forra,that|ra|==2
本实施例确立的最优化目标,在满足约束条件和均衡分配的前提下,最大化论文-专家的匹配度;而最大化论文-专家的匹配度,需要同时最大化论文-专家的标签相似度与合作距离;相较于仅依靠专业领域相似度进行评审分配的方法相比,本发明所用方法的最优化目标更加全面。
实施例4
本实施例具体阐述了本发明步骤9中叙述的最大匹配度优先与最小差调整算法及实施例1中步骤i的执行流程,算法流程如图2所示。
从图2中可以看出,最大匹配度优先与最小差调整算法的具体步骤为:
步骤i:遍历论文集,在满足最优化目标的约束条件的前提下,依次进行评审分配,并得出论文-专家的分配数组的最终结果;
对于论文集p中的每篇论文pi,0≤i<10,依次进行评审分配,具体按照以下步骤执行:
步骤i.1:对于专家集r中的每名专家rj,0≤j<7,若b(pi,rj)==0,则计算论文pi-专家rj的标签相似度s、合作距离d与匹配度m,将q[i][j]置为(0,m,s,d);若b(pi,rj)==1,则将q[i][j]置为(-1,0,0,0);
步骤i.2:为论文pi分配3位评审,0≤jj<3,执行最大匹配度优先与最小差调整算法,执行步骤为:
步骤i.2.1:根据最大匹配度优先分配评审,选择与论文pi的匹配度值最大且可分配的1位专家r,将q中相应的元素置为(1,m,s,d),选中专家r的审阅数加1;
具体到本实施例,当i=5,jj=0时,选择匹配度值最大且可分配的1位专家为r0,分配后,q为:
步骤i.2.2:若i<5或选中专家r的审阅数小于5,不用调整,转至i.2.5;
具体到本实施例,i=5,jj=0时,选中专家r0的审阅数为3,小于5,不用调整;
步骤i.2.3:根据选中专家r的审阅数与averagenum的比较关系,以及审阅数等于averagenum的专家子集ra的大小与remainnum的比较关系,判断是否执行最小差调整;若需要调整,则设置待调整的专家子集;否则转至i.2.5;
(a)若选中专家r的审阅数等于5,将专家r加入审阅数等于5的专家子集ra;加入后,若|ra|≤2,不用调整,转至i.2.5;若|ra|>2,需要调整,设置待调整的专家子集为ra;
具体到本实施例,当i=6,jj=2时,选定专家r5后,专家r5的审阅数为5,将r5加入ra,此时ra={r4,r5},|ra|≤2,不用调整,此时q为:
当i=9,jj=1时,选定专家r2后,专家r2的审阅数为5,将r2加入ra后,ra={r2,r4,r5},|ra|=3>2,需要调整,设置待调整专家子集为{r2,r4,r5};
(b)若选中专家r的审阅数大于5,需要调整,设置待调整的专家子集为{r};
具体到本实施例,当i=7,jj=0时,选中专家r4后,专家r4的审阅数为6,大于5,设置待调整专家子集为{r4};
步骤i.2.4:执行最小差调整;
调整原则为:若|ra|<2,设置最小差调整的专家审阅数为available=5;若|ra|≥2,设置最小差调整的专家审阅数为available=5-1=4;在论文集的(0-i)论文子集和待调整的专家子集中,若论文p与专家r为已分配状态,则将论文p与专家r的匹配度值,减去p与专家集r中、可分配的、审阅数小于available的、匹配度最大的专家r′的匹配度值,若所得差值最小,则将q[p][r]的分配状态置为-1,q[p][r′]的分配状态置为1;
具体到本实施例,当i=9,jj=1时,选定专家r2后,专家r2的审阅数为5,将r2加入ra,ra={r2,r4,r5},|ra|=3>2,待调整专家子集为{r2,r4,r5},调整前q为:
执行最小差调整:|ra|=3,设置available=4;在论文(0-9)中,与待调整专家子集{r2,r4,r5},与专家r2为已分配状态的论文为{p1,p3,p4,p5,p9},与专家r4为已分配状态的论文为{p0,p4,p6,p7,p8},与专家r5为已分配状态的论文为{p1,p2,p3,p6,p9},根据最小差定义,计算得最小差为:q[6][5].m-q[6][6].m=0.52-0.42=0.1,调整q[6][5]的分配状态置为-1,q[6][6]置为已分配;调整后ra={r2,r4},|ra|=2;调整后的q为:
当i=7,jj=0时,选中专家r4后,专家r4的审阅数为6,大于5,待调整专家子集为{r4},调整前q为:
执行最小差调整:|ra|=2,设置available=4;在论文(0-7)中,与待调整专家r4为已分配状态的论文为{p0,p1,p3,p4,p6,p7},根据最小差定义,计算得最小差为:q[1][4].m-q[1][3].m=0.56-0.55=0.01;调整q[1][4]的分配状态置为-1,q[1][3]置为已分配,调整后q为:
步骤i.2.5:jj=jj+1;若jj<3,转至i.2.1;
步骤i.3:i=i+1;若i<10,转至i.1;
由本实施例的最大匹配度优先与最小差调整算法的执行过程以及实施例1的评审分配结果可以看出,本发明所用方法能够在满足最优化目标的约束条件下,实现均衡评审分配,最大化结果集的标签相似度和与合作距离和,提供更加合理的评审分配方案。
实施例5
将实施例1中的某学术会议改成其他学术会议、期刊及项目的评审分配管理场景中,本发明所提出的评审分配方法依然有效。
上述实施方式中未述及的有关技术内容采取或借鉴已有技术即可实现。
以上所述为本发明的较佳实施例而已,本发明不应该局限于该实施例和附图所公开的内容。凡是不脱离本发明所公开的精神下完成的等效或修改,都落入本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!