基于深度学习的一维生理信号的特征提取与状态识别的制作方法
本发明涉及医学数据处理技术领域,尤其涉及一种生理信号特征提取及分类识别方法,具体是基于深度学习的一维生理信号的特征提取与状态识别。
背景技术:
生理信号由自主神经系统和内分泌系统支配,不受主观意识控制,能客观、真实地反应个体的生理、精神、情绪状态,因此得到了越来越广泛的研究与应用。生理信号是个体的生理、精神、情绪等状态的外在表现,能直接、真实地反应这些状态的变化,因此,已经有许多研究者使用不同的分类器对基于生理信号(脑电-eeg、心电、肌电、呼吸、皮电等)的个体状态进行识别。虽然目前适用于生理信号个体状态识别的分类器在不断增多,识别率也在不断提高,但大部分分类器需要人工提取特征,识别率的高低和人工经验有关且不稳定、离实际应用还有一定的距离。如moghimi等人利用线性判别分析分类器对基于脑血氧变化量的情绪状态进行识别,识别率为72%左右
2011年,李淑芳等人采用经验模式分解emd和支持向量机svm针对脑电信号进行癫痫状态分类,首先用经验模式分解emd将脑电eeg信号分成多个经验模式分量,然后提取有效特征,再用支持向量机svm对脑电eeg信号进行分类,最后对癫痫发作间歇期和发作期的识别率达到99%。2014年,niu等人利遗传算法进行特征选择并利用k近邻分类器对基于心电、肌电、呼吸、皮电的情绪状态进行识别,识别率达96%。但这种依赖于不同方法组合或者不同信号组合的方法取得的较高的识别率具有高度特异性的特点,很难推广到一般情况,且找到某种组合方式本身也具有较大的偶然性。
自从2012年hinton等人使用卷积神经网络在imagenet比赛中脱颖而出,将深度学习的研究推到了高潮,从此在信号和信息处理领域的研究引起了许多关注和应用,特别是在图像处理、语音识别等方向更是取得了前所未有的效果。随着深度学习的快速发展,深度学习在脑电、肌电、心电、皮电等生理电信号处理方面也得到了初步的应用,并取得了令人惊喜的效果。经过不断的发展,已经出现了大量的深度学习框架(如:deeplearntoolbox、caffe、deeplearning等)和模型(如:深度信念网络(deepbeliefnet,dbn)、稀疏自动编码器、循环神经网络等)。但是,如何利用和改进这些框架和模型,使之适用于实际问题,是当前需要研究的内容。
技术实现要素:
针对传统浅层分类器需要人工提取特征、识别效果不稳定等问题,本发明旨在提供一种基于深度学习的一维生理信号特征提取及状态识别方法,有效解决传统的一维生理信号分类过程中需要人工选择特征输入致使分类精度不高的问题,其通过深信度网络的非线性映射,自动得到高度可分的特征和特征组合用于分类,并且不断优化网络结构得到更好的分类效果。
本发明的基本思路是:基于深度学习的一维生理信号的特征提取与状态识别数据库网络模型dbn,模型采用“预训练+微调”训练过程:预训练过程是采用自下而上的无监督训练,基本原则是首先训练第一个隐含层,然后逐层训练下一个隐含层,并将上一个隐含层结点的输出作为输入,将本隐含层结点的输出作为下一个隐含层的输入;微调过程是通过对带标签数据进行自上而下的监督训练,使得误差反向传播,对模型参数进行微调,微调过程一般使用的是误差反向转播算法bp算法。“预训练+微调”的训练过程可以视作将大量的参数进行分组,为每一组参数找寻局部看起来较好的设置,然后再将这些局部较优解联合起来寻找全局的最优解,使用不同的激活函数、cd算法、小批量梯度下降算法进行权值的迭代更新技术.本发明的技术方案既利用了模型大量参数提供的自由度,又有效节省了训练的开销。
dbn模型由多个rbm堆叠而成。dbn模型的训练过程为:在预训练阶段,首先训练第一个rbm,然后将训练好的结点作为第二个rbm的输入,再训练第二个rbm,以此类推;所有rbm训练完成之后使用bp算法对网络进行微调。dbn通过多个rbm堆叠,每层对上一层进行处理可以看做是对输入的逐层加工,把初始值与输出类别之间联系不密切的输入转化成与类别更密切的表示。
本发明的目的是这样达到的:
建立基于深度学习的一维生理信号的特征提取与状态识别数据分析模型dbn,dbn模型采用“预训练+微调”训练过程:预训练过程采用自下而上的无监督训练,首先训练第一个隐含层,然后逐层训练下一个隐含层,并将上一个隐含层结点的输出作为输入,将本隐含层结点的输出作为下一个隐含层的输入;微调过程通过对带标签数据进行自上而下的监督训练,在预训练阶段,首先训练第一个rbm,然后将训练好的结点作为第二个rbm的输入,再训练第二个rbm,以此类推;所有rbm训练完成之后使用bp算法对网络进行微调,最后将深信度网络输出的特征向量输入softmax分类器中,对纳入到的一维生理信号的个体状态做出判断。
提取及分类方法的步骤:
s1:纳入一维生理信号,包括脑电、心电、肌电、呼吸、皮电中一个或多个,并对其进行预处理操作和特征映射操作,在标准空间内进行特征映射,得到标准空间内的特征映射图,预处理含去噪、滤波、层次分解、重构操作;
s2:构建一个包括输入层、多个受限玻尔兹曼机rbm、一个反向传播结构以及一个分类器的深信度网络dbn,其中,所述受限玻尔兹曼机rbm作为整个网络的核心结构在数量上有1~n个,在结构上互相嵌套;
s3:使用步骤s2构建的所述深信度网络对步骤s1中经预处理和特征映射后的一维生理信号进行特征提取,提取过程含rbm训练和bp算法对网络进行微调;rbm训练和bp算法包括:
1)、在rbm训练和bp算法微调中,每一层输出之前均进行批归一化处理;
2)、在gibbs采样中多次迭代采用了k次迭代的cd算法cd-k算法;
3)、在使用gibbs采样最大可能地拟合输入数据转变为求解输入样本的极大似然估计中选用dropout法来防止过拟合;
4)、在bp算法对网络进行微调过程中,在以目标的负梯度方向对参数进行调整时,采用小批量梯度下降算法对每组小样本采进行权值的迭代更新;
5)、在自下而上的前向传播过程选择sigmoid激活函数;在自上而下的反向传播时选择relu激活函数;
s4:将步骤s3中所述深信度网络输出的特征向量输入softmax分类器中,对纳入到的一维生理信号的个体状态做出判断。
s31:所述在rbm训练和bp算法微调中,每一层输出之前均进行批归一化处理,是选用z-score标准化方法进行归一化处理,对训练集和测试集分别利用z-score将数据变换为均值为0、标准差为1的正态分布,再将数据变换到[0,1]的范围内,z-score标准化方法利用袁术数据的均值和标准差进行归一化,公式如下:
上式中u表示每一维的平均值,σ表示每一维的标准差,处理后的数据符合均值为0,标准差为1)的标准正太分布;
s32:在gibbs采样中多次迭代采用k次迭代的cd算法cd-k算法是:
对于一个输入样本:v=(v1,v2,…,vm),根据rbm,得到样本v编码后的输出样本h=(h1,h2,…,hn),这n维编码后的输出理解为是抽取了n个特征的输入样本:
1)输入一个训练样本x0,隐含层层数m,学习率ε;
2)初始化可视层v1=x0、权值w、可视层偏置b、隐含层偏置c为接近于0;
3)fori<m;
4)利用公式
5)将步骤(3)得到的结果带入利用公式
6)将步骤(4)得到的结果带入公式
7)根据梯度下降算法,更新w、b、c:%rec表示重构后的模
△w=ε(<vihj>data-<vihj>rec)
△b=ε(<vi>data-<vi>rec)
△c=ε(<hj>data-<hj>rec)
8)endfor;
9)输出更新后的w、b、c。
s33:在使用gibbs采样最大可能地拟合输入数据转变为求解输入样本的极大似然估计中选用dropout法来防止过拟合,是dropout通过改变模型本身来实现防止过拟;dropout随机地“删除”隐含层一部分的结点,被“删除”的结点只是暂时视作不存在,参数暂时不更新,但还是需要保留,下一次迭代这些结点又有可能会参加训练;
s34:在bp算法对网络进行微调过程中,在以目标的负梯度方向对参数进行调整时,采用小批量梯度下降算法对每组小样本采进行权值的迭代更新,步骤为:
1)每次从全部输入样本中随机抽取一组小样本,每组小样本包含的样本数量为mini-batch;
2)对每组小样本采用批量梯度下降算法进行权值的迭代更新;
3)重复步骤1)和2),重复次数为:全部输入样本数量/mini-batch;
s35:在以目标的负梯度方向对参数进行调整时,在自下而上的前向传播过程选择sigmoid激活函数;
选择过程是:输入样本的极大似然估计
对参数进行求导,求解似然函数求解最大值,利用梯度上升法将目标函数不断提升,直到达到停止条件;对似然函数求最大值的过程得到第j个可视层结点被激活(值为“1”)的概率和第i个隐含层结点被激活的概率分别为:
上式中f为sigmoid激活函数;
sigmoid激活函数定义为
对sigmoid函数求导可得:
将导数为0的激活函数叫做软饱和激活函数,而将|x|大于某个数时导数为0的激活函数叫做硬饱和激活函数,即:
在自上而下的反向传播时选择relu激活函数,relu(x)在x<0时会出现硬饱和现象,但当x>0时,relu(x)的导数为1,不会出现“梯度消失”,所以在反向传播过程中,梯度弥散现象较轻,收敛更快,可以有效缓解“梯度消失”现象。relu函数定义为:
relu(x)=max(0,x)(0-7)
所述在s33选用dropout法来防止过拟合,使用dropout方法之前,网络的训练流程是先把输入通过网络前向传播,然后使用bp算法把误差逆向传播,使用dropout方法之后,训练流程变为:
1)随机删除网络中部分隐含层结点;
2)把输入通过剩余的结点前向传播,再使用bp算法将误差通过剩余的结点逆向传播;
3)恢复被删除的结点,而这时被“删除”的结点的参数没有更新,未被删除的结点的参数已经更新了;重复以上三个步骤,直到迭代完成。
将深信度网络输出的特征向量输入softmax分类器中,参数c在范围[2-10,210]内寻找最佳的分类准确率。
在使用gibbs采样中,抽取n个特征的输入样本的具体步骤如下:对似然函数求最大值的过程得到第j个可视层结点被激活(值为“1”)的概率和第i个隐含层结点被激活的概率分别为:
上式中f为sigmoid激活函数;
1)首先利用公式(2-13)计算隐含层第i个结点被激活(取值为“1”)的概率p(hi=1|v);
2)然后根据gibbs采样拟合输入数据,得到h=(h1,h2,…,hn),具体过程为:产生一个0~1的随机数,如果随机数的值小于p(hi=1|v),那么hi的值为“1”,否则为“0”;
3)根据步骤(1)、(2)得到的编码后的h进行解码得到原来的输入v’,同样地,首先利用公式(2-12)计算p(vj=1|h),得到可视层第j个结点被激活的概率;
4)同步骤(2)一样,产生一个0~1的随机数,如果随机数的值小于p(vj=1|h),那么vj’的值为“1”,否则为“0”;
5)将步骤(4)得到的v’带入公式并同步骤(2)一样通过gibbs采样计算得到h’;
6)最后根据公式(2-14)、(2-15)、(2-16)更新权值、可视层偏置、隐含层偏置;其中η为学习率,表示权值或偏置更新的时候增加或减少的速率;
δw=η(vh-v'h')(0-9)
δb=η(v-v')(0-10)
δc=η(h-h')(0-11)。
本发明的积极效果是:
1、有效解决了传统的一维生理信号分类过程中需要人工选择特征输入致使分类精度不高的问题,通过深信度网络的非线性映射,自动得到高度可分的特征/特征组合用于分类,并且可以不断优化网络结构得到更好的分类效果。“预训练+微调”的训练过程可以视作将大量的参数进行分组,为每一组参数找寻局部看起来较好的设置,然后再将这些局部较优解联合起来寻找全局的最优解,这样技术方案既利用了模型大量参数提供的自由度,又有效节省了训练的开销。
2、gibbs采样是一种基于马尔科夫蒙特卡罗的采样方法,充分利用条件概率分布,迭代地对x的每个分量进行抽样,随着迭代次数的增加,条件概率分布将以抽样次数的几何级数的速度收敛于联合概率分布,缩短收敛时间。
3、每一层输出之前均进行批归一化处理,对训练集和测试集分别利用z-score将数据变换为均值为0、标准差为1的正态分布,再将数据变换到[0,1]的范围内,大大提高网络的泛化能力,提高网络的训练速度。
4、本发明可选激活函数有:sigmoid、relu;本发明所涉及到的深信度网络分为前向传播过程和反向传播过程,前向传播和反向传播可以选择同样的激活函数选择也可选择不同的激活函数,适用于各种不同生理信号需要。
5、对于gibbs算法需要进行多次迭代,收敛速度较慢的问题,本发明在gibbs算法基础上利用对比散度cd-k算法,能够快速地求出模型的期望值,通过k次迭代就获得模型的估计,且k取较小的值时就可以得到较好的近似。
6、本发明选用dropout法来防止过拟合,从总体上降低过拟合,提高效率。
附图说明
图1是本发明的dbn网路模型结构及训练过程图。
图2是本发明的bp网络结构图。
图3是sigmoid激活函数图。
图4是relu激活函数图。
图5是dropout前后的网络结构图,其中,左边是dropout前的网络结构;右边是dropout后的网络结构。
图6-1是分类器svm识别结果混淆矩阵图。
图6-2是分类器dbn识别结果混淆矩阵图。
图7是实施例中训练后dbn的第一层的权值的平均绝对值分布图。
具体实施方式
本实施例实验所用的硬件、软件环境如表4-1所示:
表4-1
数据获取:
本实验数据是由上海交通大学提供的情绪脑电数据库(sjtuemotioneegdataset,seed)[,这个数据库包含了基于脑电信号的三种情绪数据(积极、消极、中性)。数据采集于15个被试者,每次实验要求每个被试者观看15个能诱发这三种情绪的电影片段,在被试者观看电影片段的过程中,用62通道的干电极脑电帽采集被试者的脑电信号,每次实验每个被试者得到15组脑电信号,根据被试者的描述对每组脑电信号标记标签(积极为“+1”,消极为“-1”,中性为“0”),分别有5组“积极”、5组“消极”、5组“中性”。每个被试者间隔7天或7天以上的时间再次进行上述实验,每个被试者共参加3次实验,因此对于15个被试者,共获得15×3×15=675组脑电数据,本文将一次实验中的前12组数据(包含了4组积极情绪,4组中性情绪,4组消极情绪)作为训练集,后3组数据(包含了1组积极情绪,1组中性情绪,1组消极情绪)作为测试集。
采集到原始数据后,数据提供方对原始脑电信号进行预处理,然后再通过滤波获取脑电信号五个频段(delta频段(1~3hz)、theta频段(4~7hz)、alpha频段(8~13hz)、beta频段(14~30hz)、gamma频段(31~50hz))的信号。再在这五个频段的基础上使用六种特征变换方法对每个频段下的数据进行了特征提取,分别为:psd、de、asm、dasm、rasm、dcau,这六种特征变换具有计算简单、能有效代表脑电信号等特点。de是在香农熵的概念上扩展而来,能有效地测试连续随机变量的复杂性,脑电信号中低频能量的成分较多,de可以有效地将脑电信号中低频能量部分和高频能量部分进行区分,由于有62个通道,所以de的样本维数为62×5=310。另有研究表明,大脑的不对称活动在情绪处理有显著影响,因此在de的基础上提取了dasm、rasm作为27对大脑非对称电极的de之间的差分不对称和有理不对称,将dasm和rasm组合就得到了asm。dcau表示23对大脑额叶和后叶电极的de的差分。除了进行了de特征变换外,还提取了psd特征。psd、de、asm、dasm、rasm、dcau六种特征变换,每个特征变换样本的特征维数分别为:310、310、270、135、135、115。
实验流程:
本实验基于deeplearntoolbox框架的dbn模型,并在此基础上引入了批归一化算法和relu激活函数。在gibbs采样中多次迭代采用了k次迭代的cd算法cd-k算法。在使用gibbs采样最大可能地拟合输入数据转变为求解输入样本的极大似然估计中选用dropout法来防止过拟合;在bp算法对网络进行微调过程中,在以目标的负梯度方向对参数进行调整时,采用小批量梯度下降算法对每组小样本采进行权值的迭代更新。通过反复实验调整dbn模型的各项参数,确定最优的dbn模型,并与svm的分类结果进行对比。对基于不同被试者每次实验、不同脑电信号的特征变换以及不同频段的识别结果进行了分析,并对迭代次数、学习率、隐含层结点数对分类结果的影响进行了讨论。
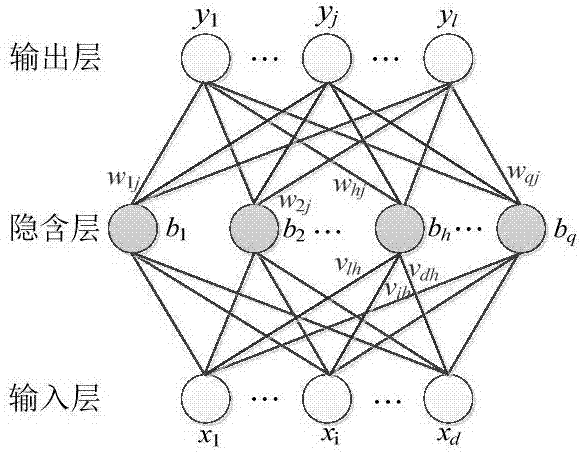
如图1所示,为本发明使用的dbn模型进行训练分类的流程图,首先将原始的训练集和测试集进行归一化,然后将训练集和测试集带入模型进行训练分类。图2是bp网路结构图。从图1、2知道,训练主要分为预训练和微调两个步骤,然后将调整更新后的权值、偏置带入分类器进行预测分类,最后根据预测结果和实际结果之间的差计算分类准确率。rbm训练参数有:隐含层与可视层之间的连接权值wij(i=1,2,3,…,n;j=1,2,3,…,m)、可视层偏置b=(b1,b2,b3,…,bm),隐含层偏置c=(c1,c2,c3,…,cn)。
dbn的训练主要是不断调节权值和偏置的过程,而对权值和偏置的影响最大的就是网络的深度,即隐含层的层数和每个隐含层的结点数。当隐含层层数较小时网络的学习能力不够,只能学习到一些浅层特征,且当隐含层层数减少为1时则变为人工神经网络;理论上讲,增加隐含层的层数可以更准确地抽象输入数据的本质,使分类效果更好,但随着层数的增加,会给整个模型带来更多的参数,训练时间增长,使得dbn的泛化能力下降,导致过拟合。本实施例结合原始数据实际情况,选择使用2个隐含层,加上输入层和输出层共4层。以de特征为例,输入层结点数为310,输出层结点数为3,中间包含了两个隐含层,隐含层结点数分别在50~500和20~500两个范围中选择。
在以目标的负梯度方向对参数进行调整时,采用小批量梯度下降算法对每组小样本采进行权值的迭代更新,步骤为:
1)每次从全部输入样本中随机抽取一组小样本,每组小样本包含的样本数量为mini-batch;
2)对每组小样本采用批量梯度下降算法进行权值的迭代更新;
3)重复步骤1)和2),重复次数为:全部输入样本数量/mini-batch;
本实施例的具体步骤归纳为dbn和bp两个部分,具体步骤如下:
1):初始化dbn:隐含层层数,隐含层结点数,迭代次数,学习率,动量,每组小样本包含的样本数量mini-batch,mini-batch即m,要求能被全部输入样本的数量整除;连接权值w,可视层偏置b,隐含层偏置c都设置为0;
2):fori<隐含层层数%rbm的训练;
3):repeat;
4):forj<(n1/mini-batch1);
5):训练rbm,并根据公式(2-17)~(2-19)
δw'=m×δw+η(vh-v'h')(0-12)
δb'=m×δb+η(v-v')(0-13)
δc'=m×δc+η(h-h')(0-14)
更新连接权值w、可视层偏置b、隐含层偏置c;
6)根据公式(2-13)计算当层的输出,并作为下一个隐含层的输入
7):endfor
8):until循环次数=迭代次数;
9):endfor
10):初始化bp:类别数,激活函数,学习率,动量;迭代次数,分类器;用上
面得到的连接权值w、可视层偏置b、隐含层偏置c初始化bp;
11):repeat;
12):forl<(n1/mini-batch2);
13):根据公式(2-23)计算每个隐含层的输出,并计算误差e;
14):根据公式(2-31)~(2-33)更连接权值w、可视层偏置b、隐含层偏置c;
15):endfor
16):until循环次数=迭代次数;
17):将测试集,连接权值w、可视层偏置b、隐含层偏置c;带入公式(2-23)计
算预测标签y’;
18):计算每个类别的真实标签y;
19):输出每个类别分类准确率。
从以上步骤可以看到,训练分为预训练(步骤1~9)和微调(步骤10~16)两个步骤,然后将调整更新后的权值、偏置带入分类器进行预测分类,最后根据预测结果和实际结果之间的差计算分类准确率。由于本发明在deeplearntoolbox框架的基础上引入了批归一化算法,所以在每一层输出之前要进行批归一化处理,在步骤6、13、17在带入激活函数之前都要进行批归一化处理。
步骤13)如图2所示:图2给出了一个有d个输入结点、q个隐含层结点、l个输出结点的bp网络结构,其中输入层结点x=(x1,x2,…,xi,…,xd),隐含层结点b=(b1,b2,…,bh,…bq),输出结点y=(y1,y2,…,yj,…,yl),θj表示输出层第j个结点的阈值,γh表示第h个隐含层结点的阈值,vih表示第i个输入层结点与第h个隐含层之间的权值,whj表示第h个隐含层结点与第j个输出层结点之间的权值。
由输入层结点和权值得到隐含层第h个结点的输入为:
由隐含层结点和权值得到输出层第j个结点的输入为:
上式中bh表示隐含层第h个结点的输出,根据上式可得到计算公式为:
假如一个输入样本(xk,yk),若经过bp网络训练得到的输出
那么,网络最后的均方误差ek为:
对于图2所示的bp网络结构,需要确定的参数共有:(d+l+1)×q+l个,分别为:d×q个输入层与隐含层之间的权值、q×l个隐含层到输出层之间的权值、q个隐含层结点的阈值、l个输出层结点的阈值。bp算法是一个不断迭代更新的过程,上述参数都可以根据下式来更新估计(其中v代表任意一种参数):
v←v+δv(0-20)
bp算法是基于梯度下降的,以目标的负梯度方向对参数进行调整,因此,当学习率η给定时,权值的改变量为:
根据图2可以看出,whj是先通过影响隐含层输出的第j个结点的输入值βj,再影响第j个结点的输出值
若采用sigmoid函数作为激活函数,则:
f'(x)=f(x)(1-f(x))(0-23)
根据公式(2-23)、(2-24)、(2-28)可以得到第j个输出层结点的梯度项gj为:
类似地,第h个隐含层结点的梯度项eh为:
因此,将公式(2-22)、(2-29)带入公式(2-27)就可以得到权值whj的更新公式:
δwhj=ηgjbh(0-26)
同样地,可以得到θj、vih、γh的更新公式,分别为:
δθj=-ηgj(0-27)
δvih=ηehxi(0-28)
δγh=-ηeh(0-29)
参见附图3、4。
激活函数是在学习过程中加入非线性因素来解决线性不可分的问题,本发明可选激活函数有:sigmoid、relu;本发明所涉及到的深信度网络分为自下而上的前向传播过程和在自上而下的反向传播过程,前向传播和反向传播可以选择同样的激活函数也可以选择不同的激活函数。
sigmoid是应用最广的激活函数,定义为:
函数曲线如图3所示,对sigmoid函数求导可得:
将导数为0的激活函数叫做软饱和激活函数,而将|x|大于某个数时导数为
0的激活函数叫做硬饱和激活函数,即:
由于sigmoid的软饱和性,在后向传递时,sigmoid向下传导的梯度中包含了一个与导数f’(x)有关的因子,若输入落入软饱和区,f’(x)的值就趋近于0,因此向下传递的梯度会很小,从而使得网络参数训练效果不好,这也是曾经阻碍神经网络发展的重要原因。这种现象又被称为“梯度消失”,一般网络层数在5层以内时比较容易发生。虽然sigmoid激活函数会出现“梯度消失”现象,但也有一些优点:sigmoid在物理意义上与生物神经元模型最为接近,sigmoid将输入压缩至(0,1)范围内,可以视作对输入的归一化处理,也可以视作分类的概率(比如:激活函数的输出为0.9,那么可以解释为90%的概率为正样本)。
修正线性函数(rectifiedlinearfunction,relu)同sigmoid函数相比,可以有效缓解“梯度消失”现象,relu函数定义为:
relu(x)=max(0,x)(0-33)
函数曲线如图4所示,relu(x)在x<0时会出现硬饱和现象,但当x>0时,relu(x)的导数为1,不会出现“梯度消失”,所以在反向传播过程中,梯度弥散现象较轻,收敛更快。
本实施例的多次迭代采用k次迭代的cd算法cd-k算法:
对于一个输入样本:v=(v1,v2,…,vm),根据rbm,得到样本v编码后的输出样本h=(h1,h2,…,hn),这n维编码后的输出理解为是抽取了n个特征的输入样本,
步骤是:
1)输入一个训练样本x0,隐含层层数m,学习率ε;
2)初始化可视层v1=x0、权值w、可视层偏置b、隐含层偏置c为接近于0;
3)fori<m;
4)利用公式
5)将步骤(3)得到的结果带入利用公式
(6)将步骤(4)得到的结果带入公式
(7)根据梯度下降算法,更新w、b、c:%rec表示重构后的模
△w=ε(<vihj>data-<vihj>rec)
△b=ε(<vi>data-<vi>rec)
△c=ε(<hj>data-<hj>rec)
(8)endfor;
(9)输出更新后的w、b、c。
在dbn的训练过程中,很有可能因为隐含层层数较多、隐含层结点数较多,而样本数据量较小等原因导致过拟合,而过拟合会导致较差的分类效果。本发明选用dropout法来防止过拟合。
dropout也是正则化方法的一种,通过改变模型本身来实现防止过拟合。dropout的思想是:随机地“删除”隐含层一部分的结点,如删除50%。被“删除”的结点只是暂时视作不存在,参数暂时不更新,但还是需要保留,下一次迭代这些结点又有可能会参加训练。
在使用dropout前h1和h2之间的权值w2为:
w2=(w11,w12,w13,w14,w21,w22,w23,w24,w31,w32,w33,w34)(0-34)
若在h1的后面使用一个节点过滤函数m=[1,0,1],那么h1的部分结点将会随机被“删除”(中间结点被“删除”了),得到新的隐含层h1’:
从上式可以看出,结点h12被随机地“删除”了,那么在此次训练过程中,与结点h12相关的参数(w21,w22,w23,w24)不会得到更新,但这些参数并不是被置零了,只是暂时在本次迭代过程中不更新,若下次迭代中结点h12没有被“删除”,那么这些参数将会继续更新。
在使用dropout方法之前,网络的训练流程是先把输入通过网络前向传播,然后使用bp算法把误差逆向传播,使用dropout方法之后,训练流程变为:
1)随机删除网络中部分隐含层结点;
2)把输入通过剩余的结点前向传播,再使用bp算法将误差通过剩余的结点逆向传播;
3)恢复被删除的结点,而这时被“删除”的结点的参数没有更新,未被删除的结点的参数已经更新了;重复以上三个步骤,直到迭代完成。
本实施例deeplearntoolbox框架的dbn模型中无监督预训练和监督训练的各项参数设置如表4-2所示。
从表中可以看出,积极情绪相比消极情绪和中性情绪在gamma频段和beta频段具有较高的能量,消极情绪和中性情绪在gamma频段和beta频段的能量大小相似,消极情绪在alpha频段具有较高的能量。这些发现说明这三种情绪在高频频段存在特定的神经模式,为后续情绪的分类提供了依据。
表4-2
dbn的训练主要是不断调节权值和偏置的过程,而对权值和偏置的影响最大的就是网络的深度,即隐含层的层数和每个隐含层的结点数。当隐含层层数较小时网络的学习能力不够,只能学习到一些浅层特征,且当隐含层层数减少为1时则变为人工神经网络;理论上讲,增加隐含层的层数可以更准确地抽象输入数据的本质,使分类效果更好,但随着层数的增加,会给整个模型带来更多的参数,训练时间增长,使得dbn的泛化能力下降,导致过拟合。本实施例结合原始数据实际情况,选择使用2个隐含层,加上输入层和输出层共4层。以de特征为例,输入层结点数为310,输出层结点数为3,中间包含了两个隐含层,隐含层结点数分别在50~500和20~500两个范围中选择。
本实施例的情绪识别结果与分析如下:
基于脑电信号的情绪识别研究中一个非常重要的问题就是:能否准确、可靠地识别出同一个被试者在不同时间和不同状态下诱发的相同的情绪,因此本实施例对每个被试者三次实验的情绪数据进行了识别。以de特征为例,如表4-3所示,为使用svm和dbn两种分类器对15个被试者每一次实验的识别结果。
表4-3
从表4-3可以看出,尽管每次实验过程中采集装置、被试者的心理状况等可能会有不同程度的差异,但每个被试者在三次试验中都能得到相似的准确率(标准差的平均值为1.44%)。因此,基于脑电信号对情绪进行识别的实验是稳定且可重复的,所以在实际应用中,利用脑电信号对同一被试者不同时间的情绪进行识别是可行的。
同时可以看出,利用dbn进行识别的平均准确率为89.12%,标准差为6.54%,比数据提供方的识别效果(平均识别率为86.08%,标准差为8.34%)更好,平均识别率提高了3.04%,标准差降低了1.80%。
此外,从表中可以得到,svm的平均分类准确率为84.2%,标准差为9.24%,而基于dbn的平均分类准确率为89.12%,标准差为6.54%,dbn的分类效果明显好于svm,具有更高的分类准确率,稳定性也更好(平均值较高,标准差较低)。
如图6-1、6-2所示,为深信度网络-dbn和支持向量机-svm两种分类器对一个被试者一次实验数据进行识别得到的分类准确率混淆矩阵。图中行代表样本原来的类别,列代表分类器预测的类别,矩阵中的数字(i,j)表示类别i被识别为类别j的概率,图中右边的色条颜色与概率的大小对应。可以看出,积极和中性情绪都能被svm和dbn很好地识别;虽然消极情绪在svm和dbn中的识别效果都不是很好,但在svm中,消极情绪与中性和积极两种情绪混淆的部分都比较多(有31%的消极被识别为中性,24%的消极被识别为积极),而dbn能明显地提高消极情绪的识别结果(只有5%的消极被识别为中性,9%的消极被识别为积极)。
基于不同特征变换的情绪识别结果如下:
为了研究六种特征变换psd、de、dasm、rasm、asm、dcau对基于脑电信号的情绪识别的影响,如表4-4所示,为在全频段下使用不同特征变换的识别结果。
表4-4
从表4-4可以看出,相比传统使用的psd特征,dbn和svm两种分类器利用de特征识别的效果最好,具有最高的平均值和最低的标准差。这是因为de特征对于大脑情绪的高频特征具有一定程度上的平衡作用,使高频特征的作用变得强,因此,de特征相比psd特征更适用于基于脑电的情绪识别中。同时,dasm、rasm、asm、dcau这四种非对称特征对情绪的识别也具有较高的准确率,虽然这四种特征相比de特征和psd特征的维数较少(dasm为27维,rasm为27维,asm为54维,dcau为23维),但是也能达到与de特征相当的准确率,这说明情绪产生时脑电信号具有非对称性,大脑的非对称性活动在情绪识别中是有意义的。但还需要后续实验来进一步验证是否是因为特征维数的原因导致dasm、rasm、asm、dcau这四个特征的准确率相对de特征较低。
为了进一步研究频段对基于脑电信号的情绪识别的影响,如表4-5所示,为以de特征为例,使用不同频段和全频段下的脑电信号进行识别的结果(%)。
表4-5
通过表4-5可以发现使用不同频段的数据对情绪识别具有不同的效果,使用全频段的数据具有最好的效果。而五个频段中,beta频段和gamma频段的识别率具有相比其他三个频段具有较高的平均值和较低的标准差,因此可以说明beta频段和gamma频段在情绪识别中具有关键的作用。
参见附图7。
dbn将特征提取和特征选择结合在一起,可以自动选择出对分类有用的特征,而过滤掉与分类无关的特征。图7为经过训练后的dbn的第一个隐含层权值的平均绝对值的分布图,可以看出,训练后权值的较大值主要分布在beta频段和gamma频段。而权值较大表明与该权值相连的输入对最后输出的分类结果具有较大的贡献,这说明beta频段和gamma频段包含了更多与情绪有关的信息。因此可以将beta频段和gamma频段称为情绪的关键频段。
- 还没有人留言评论。精彩留言会获得点赞!