一种基于极限学习机的不确定数据分类方法与流程
本发明属于学术领域中不确定数据分类问题技术领域,尤其涉及一种基于极限学习机的不确定数据分类方法。
背景技术:
现有的分类方法被广泛应用于数值唯一的数据分类问题。然而,在军工、基于位置的服务、金融等领域的许多真实应用中,数值服从某种分布的不确定数据普遍存在,如果使用传统的分类方法对不确定数据进行分类,那么极有可能会给出错误的结果,给决策者错误的信息,从而造成损失。所以,如何正确的分类不确定数据,对于现实应用具有极其重要的研究价值。决策树、svm、最近邻等主流的分类方法对不确定数据过于敏感,不能满足对不确定数据分类准确率和时间效率的需求,需要进一步探索更加准确、更为高效的不确定数据分类方法。
技术实现要素:
本发明的目的主要针对现有研究的一些不足之处,提出了一种全新的基于极限学习机的不确定数据分类方法,通过属性区间和概率密度函数对不确定数据进行建模,然后对传统的极限学习机方法的框架进行了修改,更改了输入层接收数据的类型以及隐藏层的激活函数,在充分利用不确定数据信息的基础上,使用新的方法框架,为不确定数据分类提供了一种更为准确和高效的方法。
本发明的技术方案:
一种基于极限学习机的不确定数据分类方法(uncertainextremelearningmachine,简称uelm),步骤如下:
1)处理数据,初始化方法框架计算需要的参数;
2)根据1)中处理的数据,计算不确定数据的属性区间以及对应的分布参数;
3)根据2)中计算得到的属性区间以及分布参数计算得到本方法框架的中间结果隐藏层的输出矩阵;
4)根据3)的输出矩阵和训练数据集的类标签矩阵计算得到连接隐藏层和输出层的参数;
5)根据4)计算得到的参数可以对新的不确定对象进行类标签的预测。
具体步骤如下:
通过使用概率密度函数对不确定数据建模,同时修改激活函数来解决不确定数据分类问题;
(1)初始化阶段
初始化阶段包括不确定区间的生成和高斯分布参数的计算;
(1.1)不确定区间的生成:对于每一个不确定对象o的每个属性a来说,假设属性a的最小取值和最大取值分别为vmin和vmax,则其属性值v的不确定区间表示为:[v-(v-vmin)*u*rand1,v+(vmax-v)*u*rand2],其中,u表示取值范围为[0,1]之间的控制数据不确定程度的参数,rand1和rand2表示取值范围为[0,1]之间的随机数;
(1.2)高斯分布参数的计算:对于每个不确定对象o来说,高斯分布的期望值μ为训练数据集dtrain中的每个属性a的属性值v,标准差为σ=0.25*(vmax-vmin)*u;
(2)训练阶段
首先计算激活函数,本方法中的激活函数的计算公式为:
g(x)=prob(wtx+b≥0)(1)
其中,函数prob(wtx+b≥0)表示wtx+b≥0的概率,x表示输入数据集d中数据的属性值向量,w、b分别表示连接输入层和隐藏层的权重参数矩阵、隐藏层的偏倚参数;
公式(1)的计算方法如下:
其中,z=wtx+b,(μz,σz)表示z的高斯分布参数,z的取值区间为[az,bz],区间[cz,dz]是[az,bz]和[0,+∞)两个区间的交集;
然后,根据公式(2)得到的隐藏层输出矩阵h=g(z)以及训练数据集dtrain的类标签01矩阵t,按照公式(3)求解隐藏层和输出层的连接参数β;
其中,
(3)预测阶段
根据训练阶段计算得到的参数β对新的不确定数据对象进行类标签的预测;和训练阶段一样,根据公式(2)使用预测数据集dtest中数据的属性值向量x得到htest,则每个需要预测的不确定对象会获得一个针对每一个类的概率向量,假设一共包含m个类,则该概率向量包含m个概率值,最终选取概率值最大的那个类作为该不确定对象的预测类标签。
本发明的有益效果:本发明提出了一种全新的基于极限学习机的不确定数据分类方法。本发明方法利用属性区间和概率密度函数对不确定数据进行建模,从而避免了不确定信息的丢失问题;此外本发明方法在传统elm的基础上针对不确定数据进行了修改,改变了输入层可接收的数据格式以及隐藏层的激活函数,这样从方法本身的层面使得本方法能够更好的处理不确定数据分类问题。通过实验将本发明方法与同样基于elm来处理不确定数据的分类方法avg和selm进行对比,验证了本发明方法在分类准确率和时间效率方面极强的竞争力。
附图说明
图1是本发明方法的基础方法,不确定数据感知器方法的实例描述。
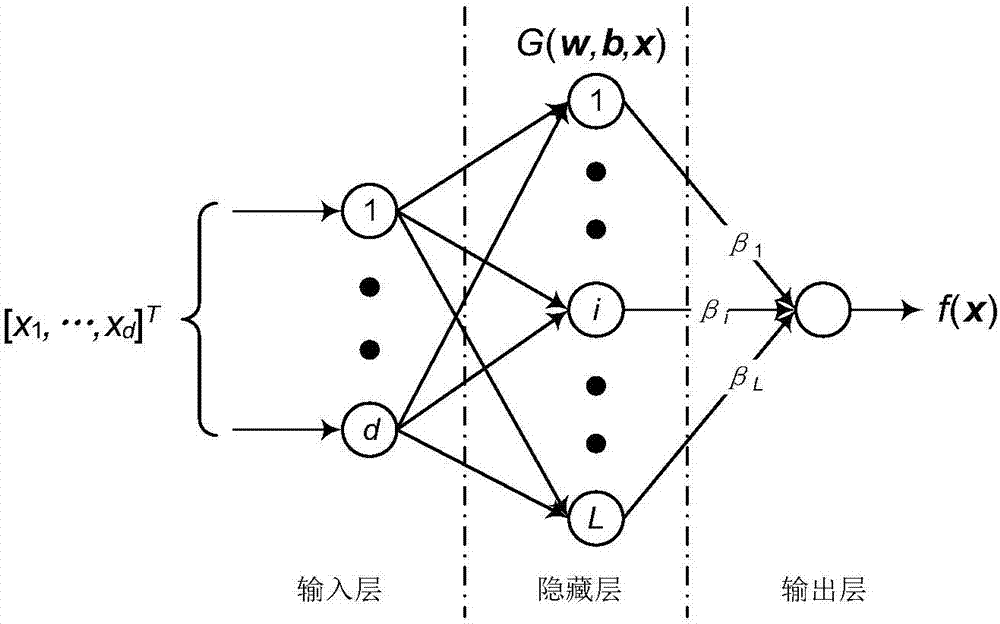
图2是本发明方法的基础方法,极限学习机方法的网络结构图。
图3是本发明方法的网络结构图。
图4(a)~(f)是本发明方法对uci标准数据集在时间效率上的实验结果图。
具体实施方式
以下结合附图和技术方案,进一步说明本发明的具体实施方式。
本发明提供了一种基于极限学习机的不确定数据分类方法,主要包括三部分:初始化阶段、训练阶段和测试阶段。
(1)初始化阶段
本发明的方法在初始化阶段主要分成两部分:不确定数据生成以及参数的设置。由于目前用于实验的标准数据集中不确定数据太少,所以在实验过程中需要将数据集进行处理,将其转换成不确定数据集,然后再进行相关的方法实验。不确定数据的生成过程在不确定数据领域有几种公认的方法,本发明方法中的不确定数据生成包括不确定数据区间的生成以及不确定数据抽样点的生成两部分:
不确定数据区间生成:对于每一个不确定对象o的每个属性a来说,假设属性a的最小取值和最大取值分别为vmin和vmax,则其属性值v的不确定区间表示为:[v-(v-vmin)*u*rand1,v+(vmax-v)*u*rand2],其中,u表示取值范围为[0,1]之间的控制数据不确定程度的参数,rand1和rand2表示取值范围为[0,1]之间的随机数。
不确定数据抽样点的生成:对于每个不确定对象o来说,高斯分布的期望值μ为训练数据集dtrain中的每个属性a的属性值v,标准差为σ=0.25*(vmax-vmin)*u。
在参数设置过程中,除了要对极限学习机框架中的一些参数进行设置,此外不确定数据也需要不确定程度以及抽样点个数参数的设置。有关方法框架中的参数主要包括,连接输入层和隐藏层的权重参数、隐藏层的偏倚参数以及隐藏层的节点个数。
(2)训练阶段
首先计算激活函数,本方法中的激活函数的计算公式为:
g(x)=prob(wtx+b≥0)(1)
其中,函数prob(wtx+b≥0)表示wtx+b≥0的概率,x表示输入数据集d中数据的属性值向量,w、b分别表示连接输入层和隐藏层的权重参数矩阵、隐藏层的偏倚参数;
公式(1)的计算方法如下:
其中,z=wtx+b,(μz,σz)表示z的高斯分布参数,z的取值区间为[az,bz],区间[cz,dz]是[az,bz]和[0,+∞)两个区间的交集;
然后,根据公式(2)得到的隐藏层输出矩阵h=g(z)以及训练数据集dtrain的类标签01矩阵t,例如有两个数据实例,分别属于1和2两个类,那么
其中,
(3)预测阶段
根据训练阶段计算得到的参数β对新的不确定数据对象进行类标签的预测;和训练阶段一样,根据公式(2)使用预测数据集dtest中数据的属性值向量x得到htest,则每个需要预测的不确定对象会获得一个针对每一个类的概率向量,假设一共包含m个类,则该概率向量包含m个概率值,最终选取概率值最大的那个类作为该不确定对象的预测类标签。
f(dtest)=βthtest(4)
(4)实验结果
为了能够验证本发明方法在不确定数据分类问题上的准确率和时间效率,采用方法对比的方式进行实验,本发明方法与同样基于极限学习机的不确定数据分类方法avg和selm两种方法在准确率和时间效率上进行对比。实验过程中采用6个uci标准数据集进行实验。
采用的这6个uci标准数据集信息如表1所示。这些数据集可以分成两类:一种是数据集本身没有数据不确定性的,6个数据集中除了japanesevowel,其他的5个数据集都属于此类;另外一种是数据集本身就具有数据不确定性,这种数据集只有japanesevowel。在这6个数据集中,satellite和japanesevowel这两个数据集已经被分成训练集和测试集两部分。对于其他的4个数据集来说,这里使用5折交叉验证的方法,将数据集平均分成5份,5份轮流作为测试集,其他的4份作为训练集,完成5次实验求均值作为该数据集的实验结果。
表1实验数据集说明
bloodtransfusion数据集收集了748个供体的献血数据,特征信息包括:距离上次献血的月数、总共献血的次数、总共献血的量和距离第一次献血的月数,最后类标签表示该人在2007年三月有没有献血,其中1表示献血了,0表示没有献血。
breastcancer数据集是乳腺癌相关数据,其中包含30个描述肿瘤的特征,使用这些特征来判断患者的肿瘤为良性还是恶性。
glass数据集是通过分析玻璃的成分来判定玻璃的类别信息。数据集总共包含214个样本,每个样本由9个特征来描述,原始数据一共分为6个类(本来为7个类,有一个类没有样本)。
pageblock数据集收集了来自54个各不相同的文档的5473个样本,每个样本都是一个块,目的是通过这些文档中块的信息判断样本对应的类别,一共分为5个类:文本、水平线、图片、垂线和图表。
satellite数据集包含一个卫星图像中的多光谱值,其中包含4435个训练样本和2000个测试样本,目的是要根据给出的多光谱值把这些样本分成6个类。
japanesevowel数据集包含640个样本,每个样本表示9个人中一个人的日本元音的发音信息,每个样本包含12个数值属性,每个属性值包含7-29个抽样值,这些抽样点表示不确定信息,最终根据这些信息来判断每个样本的发音者是谁。
本发明方法实验的准确率公式(5)所示:
其中准确率在实验结果中越高表明方法的表现越好,最终的准确率实验结果如下表2所示。
表2准确率实验结果
表2展示了目前所有基于elm不确定数据分类方法在6个uci标准数据集上的准确率实验结果。每个数据集都要进行三个方法的实验,在每个方法上需要使用[1%,5%,10%,20%]这四种不同的不确定程度进行分类准确率实验。为了突出表现最好的结果,对于每个数据集在每个不确定程度下的三个方法实验结果中准确率最高的进行加粗处理。由于japanesevowel数据集的数据本身带有不确定性,不需要进行不确定数据的转换,所以该数据集在每个方法下的结果只有一个。从结果中可以看出,本发明uelm方法在所有数据集和所有不确定程度下都要比avg和selm方法具有更高的准确率。例如,本发明方法在satellite数据集上相对于avg和selm方法在准确率上提升了至少10%。这主要是因为本发明方法使用属性区间和概率密度函数替代期望值和抽样点对不确定信息进行建模,而且将不确定信息整合到elm方法框架中,那么将会得到更加准确的分类器。总的来说,uelm方法比较与其他基于elm的不确定数据分类方法总是给出一个更好的结果,即使在不确定程度比较高的情况下。
图4分别展示了6个uci数据集使用基于elm的不确定数据分类方法avg、selm和uelm三个方法的时间对比情况,图中展示把每个方法的训练时间和预测时间进行分开展示。例如,图4(a)和图4(b)分别展示了bloodtransfusion和breastcancer两个数据集的时间效率实验结果,其中每个子图中横坐标表示数据集的不确定程度,一共包含4个不同的不确定程度[1%,5%,10%,20%],纵坐标表示每种方法在不同的不确定程度下训练和预测所花费的时间取了以10为底的对数形式来表示,单位是秒。对于每个数据集的每个不确定程度来说,有6个子柱表示,左边3个子柱从左到右依次表示avg、selm和uelm三个方法的训练时间,右边的3个子柱从左到右依次表示avg、selm和uelm三个方法的预测时间。
通过图4可以看到,无论是在训练时间还是在预测时间上,本发明方法都要明显用时比selm方法要短很多,但是都比avg方法用时要长。例如,图4(e)中satellite数据集,在selm方法训练过程中平均消耗大概150秒的时间,而本发明uelm方法的训练过程平均只消耗大概3秒钟的时间,最短的avg方法只需要不到2秒钟;在预测过程中selm方法平均大概消耗4.5秒钟的时间,本发明uelm方法只要大概0.5秒钟的时间,最短的avg方法消耗0.05秒的时间。
通过上述的实验结果描述,经过分析,获得以下结论。之所以会出现图中所展示的结果是因为:(1)avg方法使用期望值的对不确定数据建模,将不确定数据分类问题直接转换成了确定数据的分类问题,只需要进行一遍传统elm方法的计算过程即可,预测过程同样如此;(2)但是本发明uelm方法首先需要从生成的不确定数据中计算得到分布的参数μ和σ,在训练的时候需要计算积分,这个积分计算过程将比avg在训练过程中花费大量时间,同理在预测过程中本发明uelm方法同样会计算积分,使得本发明uelm方法的预测效率大大降低。(3)selm方法在训练和预测过程中都需要对大量的抽样点数据进行计算,而且这些计算过程的时间效率明显低于本发明uelm方法中的积分运算,所以selm方法是这三个方法中消耗时间最长的。总的来说,本发明方法在时间效率上相较于avg和selm具有很强的竞争力。
综合上述,本发明uelm方法在准确率方面在这三个方法中的表现最好,虽然uelm方法在时间效率上相对于最简单的avg方法存在一定程度的弱势,但是uelm方法在准确率方面带来的优势完全可以弥补相对于avg方法在时间效率上的不足。而对于基于抽样点的selm方法来说,无论在准确率还是时间效率方面都与uelm方法存在较大的差距。综合准确率和时间效率来看,本发明uelm方法相较于其他两个方法avg和selm,本发明uelm方法存在较大的优势,具有极强的竞争力。
以上的所述乃是本发明的具体实施例及所运用的技术原理,若依本发明的构想所作的改变,其所产生的功能作用仍未超出说明书及附图所涵盖的精神时,仍应属本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!