基于HBase的告警数据存储方法及装置与流程
本发明涉及数据处理
技术领域:
,尤其涉及一种基于hbase的告警数据存储方法及装置。
背景技术:
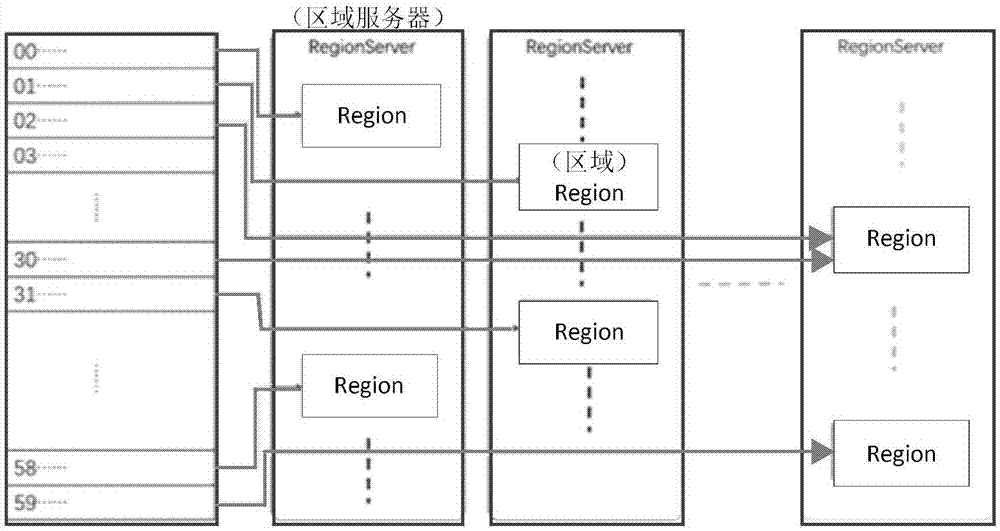
:故障管理系统是一个面向全专业的复杂的通信网络的实时监控系统,主要用于全网的设备故障监控,对故障信息进行处理,辅助故障定位和解决。随着网络规模的增长,系统所需要处理和存储的数据越来越多,对数据库的查询性能影响越来越大,尽管对数据库进行了各方面的优化,仍然无法很好的满足用户需要。特别是,目前数据分析需求的需要,从告警数据库中获取大量数据时对服务器产生了很大的压力。现有的故障管理系统的告警数据通常是在经过处理后存储在oracle、informix等关系型数据库中,在需要时从数据库查询将满足条件的数据返回给应用层,并随着这几年用户对数据价值的重视,逐渐开始对告警数据的进行一些关联规则的挖掘分析。而且,目前电信运营支撑系统oss相关系统中,经过故障管理系统处理后的告警数据仍然以oracle等关系型数据库为主,主要是通过对告警数据库进行一些优化措施来尽可能的满足系统和用户的需要。现有技术中对于关系型数据库在存储海量告警后的查询性能问题,当前流行的解决方案是通过使用企业级搜索应用服务器solr来进行告警数据的辅助查询。通过solr定时的对告警数据库中的告警数据建立全文索引,这样可以通过solr来查询满足条件的告警数据,缓解告警数据库压力,保证告警查询的性能。但是,这种方案的缺点为告警是实时的数据,而solr的索引则是通过任务来定时生成,造成了最新的告警数据没有被创建索引,也就无法通过solr查询到最新的告警数据,存在一定的时延。鉴于此,如何对告警数据进行存储,以使后续能查询到最新的告警数据,满足告警数据存取需求成为目前需要解决的技术问题。技术实现要素:为解决上述的技术问题,本发明实施例提供一种基于hbase的告警数据存储方法及装置,能够实现对告警数据进行存储,以使后续能查询到最新的告警数据,满足告警数据存取需求。第一方面,本发明实施例提供一种基于hbase的告警数据存储方法,包括:获取告警数据和所述告警数据中的告警字段在预设时间段内的使用频率;根据所述使用频率,将所述告警数据中的所有告警字段划分为热字段和冷字段,并将划分为热字段的告警字段和划分为冷字段的告警字段分别归属到预先创建的hbase告警数据表中的不同列族;根据告警发生时间,对所述告警数据中的每条告警记录进行散列处理,并根据散列处理结果,按照预设行主键格式生成每一条告警记录在所述hbase告警数据表中的行主键rowkey,以使不同时刻的告警记录均匀分散到所述hbase告警数据表的各个region上,同时向预先创建的辅助索引表写入索引数据。可选地,所述热字段至少包括网管告警流水号,同时所述热字段还包括以下告警字段中的一个或多个:网管告警级别、网元名称、设备类型、专业、告警发生时间、告警清除时间、告警定位对象名称、告警定位对象类型、告警标题、告警可能原因、告警类别、告警正文、告警清除状态、省、地区、县、厂家、是否需要上报集团、告警工程状态、派单状态、工单状态、工单号、机房名称、关联方式、定位信息、退服原因、退服类型、该事件对设备的影响、该事件对业务的影响、是否前转声光告警牌和/或短信前传标记。可选地,所述冷字段包括以下告警字段中的一个或多个:接口版本号、连续消息序号、厂家告警唯一标识、网元ip和/或告警来源。可选地,在将划分为热字段的告警字段和划分为冷字段的告警字段分别归属到预先创建的hbase告警数据表中的不同列族之前,所述方法还包括:创建具有预设数量个region的hbase告警数据表,所述预设数量个region均匀分布在hbase集群的各个区域服务器regionserver上;根据索引名或索引名的前n个字母确定所述hbase告警数据表的辅助索引表的region数量m,创建具有m个region的所述辅助索引表,使所述hbase告警数据表中的每条告警记录的每类索引均对应所述辅助索引表中的一条索引数据,所述m个region均匀分布在hbase集群的各个区域服务器regionserver上,n和m均为正整数;其中,所述hbase告警数据表的字段包括:行主键rowkey、时间戳timestamp、第一列族和第二列族;所述辅助索引表的字段包括:rowkey、timestamp和第三列族,索引数据的所有字段均归属于所述第三列族。可选地,所述第一列族的名称为h,所述第二列族的名称为c,相应地,所述将划分为热字段的告警字段和划分为冷字段的告警字段分别归属到预先创建的hbase告警数据表中的不同列族,包括:将划分为热字段的告警字段归属到预先创建的hbase告警数据表中的第一列族,将划分为冷字段的告警字段归属到预先创建的hbase告警数据表中的第二列族。可选地,所述根据告警发生时间,对所述告警数据中的每条告警记录进行散列处理,并根据散列处理结果,按照预设行主键格式生成每一条告警记录在所述hbase告警数据表中的行主键rowkey,以使不同时刻的告警记录均匀分散到所述hbase告警数据表的各个region上,包括:针对所述告警数据中的每条告警记录:按照预设网管告警流水号格式,在该条告警记录中的通过计数器生成的网管告警流水号中添加该条告警记录的告警发生时间,获得该条告警记录的新的网管告警流水号,其中,所述预设格式为:告警发生时间+通过计数器生成的序列号,其中所述告警发生时间的格式为:年+月+日+时+分+秒;以秒为粒度,将该条告警记录的告警发生时间中的各个部分按照秒、分、时、日、月、年的顺序排列,作为该条告警记录的散列值;将该条告警记录的散列值作为该条告警记录在所述hbase告警数据表的行主键rowkey的前缀,将该条告警记录的新的网管告警流水号中的通过计数器生成的序列号作为该条告警记录在所述hbase告警数据表的rowkey的后缀,以使不同时刻的告警记录均匀分散到所述hbase告警数据表的各个region上。可选地,所述辅助索引表中的rowkey由索引名+索引值+所述新的网管告警流水号组成;其中,所述索引名为查询条件的组合的字母或数字标识,用于唯一标识一类索引,所述索引值为查询条件的组合。可选地,所述查询条件的字段包括:网管告警流水号、开始时间、结束时间、地市、设备厂商、设备类型、告警专业、告警级别、告警标题、告警类别、响应级别、工程状态、工单状态、派单状态、清除状态和/或网元在网状态;相应地,所述查询条件的组合为:将网管告警流水号、开始时间和结束时间三个查询条件之外的其他查询条件进行组合作为索引值,然后去掉重复组合、前缀组合以及不需要的组合,得到全部查询条件的组合;其中,所述重复组合为条件相同但顺序不同的组合类型,所述前缀组合为一个查询条件的组合是另一个查询条件的组合的前缀。可选地,在向预先创建的辅助索引表写入索引数据之后,所述方法还包括:获取查询条件并进行组合,获得查询组合的索引名,将所获取的查询条件按照该索引名所对应的索引类型的预设条件顺序进行拼接以计算出索引值,并将所获取的查询条件中的开始时间和结束时间分别转化为所述新的网管告警流水号的格式,获得满足所获取的查询条件的rowkey范围;利用scan操作,获取所述满足所获取的查询条件的rowkey范围对应的索引数据,并利用该索引数据rowkey中的网管告警流水号对所述hbase告警数据表进行查询,以获得满足所获取的查询条件的告警数据。第二方面,本发明实施例提供一种基于hbase的告警数据存储装置,包括:第一获取模块,用于获取告警数据和所述告警数据中的告警字段在预设时间段内的使用频率;划分模块,用于根据所述使用频率,将所述告警数据中的所有告警字段划分为热字段和冷字段,并将划分为热字段的告警字段和划分为冷字段的告警字段分别归属到预先创建的hbase告警数据表中的不同列族;处理模块,用于根据告警发生时间,对所述告警数据中的每条告警记录进行散列处理,并根据散列处理结果,按照预设行主键格式生成每一条告警记录在所述hbase告警数据表中的行主键rowkey,以使不同时刻的告警记录均匀分散到所述hbase告警数据表的各个region上,同时向预先创建的辅助索引表写入索引数据。第三方面,本发明实施例提供一种电子设备,包括:处理器、存储器、总线及存储在存储器上并可在处理器上运行的计算机程序;其中,所述处理器,存储器通过所述总线完成相互间的通信;所述处理器执行所述计算机程序时实现上述方法。第四方面,本发明实施例提供一种非暂态计算机可读存储介质,所述存储介质上存储有计算机程序,该计算机程序被处理器执行时实现上述方法。由上述技术方案可知,本发明实施例的基于hbase的告警数据存储方法及装置,通过获取告警数据和所述告警数据中的告警字段在预设时间段内的使用频率;根据所述使用频率,将所述告警数据中的所有告警字段划分为热字段和冷字段,并将划分为热字段的告警字段和划分为冷字段的告警字段分别归属到预先创建的hbase告警数据表中的不同列族;根据告警发生时间,对所述告警数据中的每条告警记录进行散列处理,并根据散列处理结果,按照预设行主键格式生成每一条告警记录在所述hbase告警数据表中的行主键rowkey,以使不同时刻的告警记录均匀分散到所述hbase告警数据表的各个region上,同时向预先创建的辅助索引表写入索引数据,由此,能够实现对告警数据进行存储,以使后续能查询到最新的告警数据,满足告警数据存取需求,可以显著提高后续对告警数据查询的效率。附图说明图1为本发明一实施例提供的一种基于hbase的告警数据存储方法的流程示意图;图2为本发明实施例提供的一种基于时间的散列分布示意图;图3为本发明实施例提供的一举例的网管告警流水号查询耗时示意图;图4为本发明实施例提供的方法与现有技术的条件查询平均耗时对比示意图;图5为本发明一实施例提供的一种基于hbase的告警数据存储装置的结构示意图;图6为本发明实施例提供的一种电子设备的实体结构示意图。具体实施方式为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他的实施例,都属于本发明保护的范围。图1示出了本发明一实施例提供的基于hbase的告警数据存储方法的流程示意图,如图1所示,本实施例的基于hbase的告警数据存储方法如下所述。101、获取告警数据和所述告警数据中的告警字段在预设时间段内的使用频率。可以理解的是,所获取的告警数据为故障管理系统的告警数据,所述告警数据中的告警字段在预设时间段内的使用频率为所述告警数据中的告警字段在故障管理系统的历史的预设时间段内的使用频率,本实施例并不对其进行限制,可根据实际情况进行设置。102、根据所述使用频率,将所述告警数据中的所有告警字段划分为热字段和冷字段,并将划分为热字段的告警字段和划分为冷字段的告警字段分别归属到预先创建的hbase告警数据表中的不同列族。在具体应用中,所述热字段是被系统或用户频繁使用的字段,所述热字段至少包括网管告警流水号,同时所述热字段还可以包括以下告警字段中的一个或多个:网管告警级别、网元名称、设备类型、专业、告警发生时间、告警清除时间、告警定位对象名称、告警定位对象类型、告警标题、告警可能原因、告警类别、告警正文、告警清除状态、省、地区、县、厂家、是否需要上报集团、告警工程状态、派单状态、工单状态、工单号、机房名称、关联方式、定位信息、退服原因、退服类型、该事件对设备的影响、该事件对业务的影响、是否前转声光告警牌和/或短信前传标记等字段,本实施例并不对其进行限制。在具体应用中,所述冷字段是一般在详情查看时进行查询才会呈现,被使用频率较低,所述冷字段可以包括以下告警字段中的一个或多个:接口版本号、连续消息序号、厂家告警唯一标识、网元ip和/或告警来源等字段,本实施例并不对其进行限制。可以理解的是,本实施例所述方法使用了分离原则。由于所述告警数据的一条告警记录通常情况下可能有一百多个字段,而这些字段在故障管理系统中日常被使用的频率不一样,比如很多字段只有在进行详情查询时才会用到,一天可能被使用一两次,而有些字段每天的被使用频率却高达几百次。针对这种使用情况,本实施例利用hbase的按列族columnfamily进行存储特点(使用不同的存储装置store存储不同的columnfamily),按日常使用中告警字段被使用的频率划分为热字段和冷字段,将热字段和冷字段分别归属到不同的columnfamily中分开存储,日常的告警使用时只读取一个columnfamily中的字段内容,将使用频率低的字段归属到另一个columnfamily中,一定程度上可以提高数据读取的效率。在具体应用中,在所述步骤102之前,还可以包括图中未示出的步骤s1-s2:s1、创建具有预设数量个region(区域)的hbase告警数据表(alarms),所述预设数量个region均匀分布在hbase集群的各个区域服务器regionserver上。具体地,可以将所述hbase告警数据表的行主键rowkey均匀分割为预设数量个区间,每个区间作为一个region,将预设数量个region均匀分布在hbase集群的各个区域服务器regionserver上。现有技术中hbase表在创建后默认只有一个region,而伴随着数据的增长,达到配置的限额时,这个region就会自动发生分裂,分裂成两个region。这种分裂会一直这样进行下去,每当region达到限额就会分裂。而在故障管理系统中的告警数据增长比较快,这样就会导致region的分裂很频繁,而region分裂一般比较耗时,并且需要消耗一定的中央处理器cpu资源,会在一定程度影响hbase的性能。另一个问题就是网管告警这种数据是按时间序列发生的,不进行预分区时,所有的写入都会集中在某个region中,这样就也很容易形成热点。本实施例通过对hbase告警数据表进行预分区,可以事先分配预设数量个region,当数据写入时,根据rowkey的值直接写入对应的region内,使得数据能够按照既定的分布策略进行存储,这样可以尽量避免热点问题和减少频繁分裂造成的性能问题。通过下面步骤103对所述告警数据中的每条告警记录进行的散列处理,可以得到hbase告警数据表的rowkey分布区间为(000,600),即所述预设数量为360,将其均匀切割为360个区间,每个区间作为一个region。例如,若集群规划有10个regionserver,每个regionserver上能预先分配36个region。具体地,可以通过壳shell或者应用程序编程接口api来创建告警数据表(alarms),例如在shell中通过create‘alarms’,‘h’,‘c’创建一个名为alarms的表,该表包含h和c两个列族columnfamily,表alarms的逻辑视图如下述表1所示。表1rowkeytimestampcolumnfamily(h)columnfamily(c)…………………………………………可以理解的是,告警数据是一种基于时间的流式数据,网管告警流水号随着时间而递增,如果不进行处理直接以网管告警流水号作为rowkey,那么几乎所有的写操作都会集中在某一个节点的同一个region上造成热点。热点的出现,极大的降低了集群的性能和稳定性,生产环境中应尽量避免热点的出现。所以,本实施例利用均衡原则,通过对rowkey进行散列设计并对hbase告警数据表进行预分区,可以将告警数据尽量均匀的分布到hbase集群中的各个节点上。告警写入时,能够尽量将put操作分布到各个节点上,避免了新数据全部添加到一个region中,导致一个节点负荷过高的问题。而写入时告警数据可以均匀分布到各个region中,告警读取时也就能将操作分布到各个region上来读,尽可能的避免了热点的出现。所述均衡原则主要是通过设计将操作均匀的分布到集群中的各个节点上,并尽量避免相关操作可能出现的热点情况。可以理解的是,由于hbase会对每个值都保存的列族columnfamily名称,会占用一定的存储空间,所以在命名上越短越好,而不必使用一些可读性强的字符串作为其名称。因此本实施例可使用hot单词的首字母h作为第一列族的名称,使用cool单词的首字母c作为第二列族的名称,相应地,所述步骤102中,可以将划分为热字段的告警字段归属到预先创建的hbase告警数据表中的第一列族h,将划分为冷字段的告警字段归属到预先创建的hbase告警数据表中的第二列族c。s2、根据索引名或索引名的前n个字母确定所述hbase告警数据表的辅助索引表的region数量m,创建具有m个region的所述辅助索引表,使所述hbase告警数据表中的每条告警记录的每类索引均对应所述辅助索引表中的一条索引数据,所述m个region均匀分布在hbase集群的各个区域服务器regionserver上,n和m均为正整数;其中,所述hbase告警数据表的字段包括:行主键rowkey、时间戳timestamp、第一列族和第二列族;所述辅助索引表的字段包括:rowkey、timestamp和第三列族,索引数据的所有字段均归属于所述第三列族。可以理解的是,通过对条件查询问题的分析,hbase可以通过辅助索引表来存储二级索引数据,通过对每条告警数据创建对应的索引来提高条件组合查询的效率,满足故障管理系统的告警数据条件查询的需要,可以使在后续条件查询时,先根据条件搜索辅助索引表获取满足条件的索引,然后再根据索引信息解析告警数据的相关rowkey并去hbase告警数据表进行查询。由于索引数据比较简单,索引数据主要包括:索引名、索引值和网管告警流水号,因此辅助索引表的结构也比较简单,仅包含一个columnfamily列族,即索引数据的所有字段(即索引名、索引值和网管告警流水号)均归属于所述第三列族。举例来说,可通过shell进行辅助索引表的创建:create‘almindex’,‘i’,辅助索引表的逻辑视图如下述表21所示。表2rowkeytimestampcolumnfamily(i)……/……/在具体应用中,所述辅助索引表中的rowkey可以由索引名+索引值+所述新的网管告警流水号组成,所述索引名、索引值和所述新的网管告警流水号之间可以以竖线分隔;其中,所述索引名为查询条件的组合的字母或数字标识,用于唯一标识一类索引,所述索引值为查询条件的组合。可以理解的是,如果将条件组合信息和索引相关内容作为rowkey的一部分存储在rowkey中,那么仅通过rowkey即可完成对索引数据的表达和存储,这样辅助索引表中的columnfamily就可以不必存储其他数据,能够节约一定的存储资源。辅助索引表的记录数是hbase告警数据表的记录数乘以索引种类数,即需要将hbase告警数据表中的每条告警记录的每类索引都对应一条索引数据,因而这种方式可以很好的减小存储空间的消耗。可以理解的是,每当有一条告警写入数据表时,可以通过定义好的协处理器向辅助索引表写入对应的索引数据。例如,有5个查询条件的组合中有13种索引,则每当有新的告警数据写入hbase告警数据表时,需要向辅助索引表中写入13条索引数据来完成对索引的创建。因此,可以根据索引名进行预分区,使得同一类索引集中在一个region中,使得写入操作能够均匀分布在各个region上,而读取操作能够在一个region中进行以提升读取效率。13种索引在表中按字典顺序存储,我们将每类索引放在一个region中。需要说明的是,在索引种类不是很多时,可以按索引类型进行分区,但当索引的条件很多时,索引种类也很多,只按索引名进行分区可能会导致数万个region,并不适合用于region划分。因此在大量索引类型时,预分区时可以考虑按前面一两位字符组合进行分区。例如,使用首字母进行预分区最多有26个分区,使用前两个字母进行分区最多可以得到650个分区。103、根据告警发生时间,对所述告警数据中的每条告警记录进行散列处理,并根据散列处理结果,按照预设行主键格式生成每一条告警记录在所述hbase告警数据表中的行主键rowkey,以使不同时刻的告警记录均匀分散到所述hbase告警数据表的各个region上(可参考图2),同时向预先创建的辅助索引表写入索引数据。可以理解的是,散列处理是有效避免热点发生的一种方式。通过散列,将连续发生的告警数据分散到各个regionserver上,可以避免对同一regionserver的某个region进行集中读写的热点问题。为了使数据的分布尽可能均衡到各个regionserver上并且满足告警实时更新的并发性和吞吐量的需求,所述步骤103中的“根据告警发生时间,对所述告警数据中的每条告警记录进行散列处理,并根据散列处理结果,按照预设行主键格式生成每一条告警记录在所述hbase告警数据表中的行主键rowkey,以使不同时刻的告警记录均匀分散到所述hbase告警数据表的各个region上”可以包括:针对所述告警数据中的每条告警记录:按照预设网管告警流水号格式,在该条告警记录中的通过计数器生成的网管告警流水号中添加该条告警记录的告警发生时间,获得该条告警记录的新的网管告警流水号,其中,所述预设格式为:告警发生时间+通过计数器生成的序列号,其中所述告警发生时间的格式为:年+月+日+时+分+秒;以秒为粒度,将该条告警记录的告警发生时间(yyyy-mm-ddhh24:mi:ss)中的各个部分按照秒ss、分mi、时hh24(24小时制)、日dd、月mm、年yy(年的后两位数)的顺序排列,作为该条告警记录的散列值hashing=ss+mi+hh24+dd+mm+yy,这样可以使同一秒内发生的告警记录集中到一起,不同时刻发生的告警记录能够分散,例如,对于告警发生时间为2015-05-2905:44:30的一条告警记录,可计算得到散列值为304405290515,按图2中的分区,该条告警记录可定位到最后一个regionserver的某个region上;将该条告警记录的散列值作为该条告警记录在所述hbase告警数据表的行主键rowkey的前缀,将该条告警记录的新的网管告警流水号中的通过计数器生成的序列号作为该条告警记录在所述hbase告警数据表的rowkey的后缀,以使不同时刻的告警记录均匀分散到所述hbase告警数据表的各个region上,能够保证告警数据在regionserver上的均衡分布。具体地,所述hbase告警数据表的rowkey的前缀与后缀之间可以以竖线分隔。可以理解的是,上述通过计数器生成的序列号可以为四位序列号,该序列号主要是为了标识出发生在同一秒内的各条告警数据,避免同一秒内发生的告警得到一个相同的流水号。四位序列号的格式为数字0-9的组合,即从0000-9999,一共104组合。一般来说,每秒发生超过一万条告警是很严重的生产事故,这种的情况几乎不会发生,因此0-9的数字组合在通常情况下能够满足实际系统的需要。当然为了扩展,在以后可以根据实际情况需求,通过计数器生成的序列号也可以为大于四位的序列号,即在数字0-9的组合的基础上再增加其他组合,比如大写字母a-z。将告警发生时间包含在网管告警流水号中后,可以通过网管告警流水号直接获取告警的发生时间,也能通过告警发生时间确定告警流水号的范围。以此类型的网管告警流水号作为rowkey的一部分,对数据的查询性能有一定的帮助。举例来说,若上述通过计数器生成的序列号为四位序列号,2015-05-2905:44:30的一条告警记录,根据告警流水号生成规则生成的新的网管告警流水号为201602290544300001,由散列方式计算得到散列结果为304405290216,则该条告警记录的rowkey为:3044052902160001,将散列结果(rowkey的前缀)、流水序列号(rowkey的后缀)以竖线分隔,得到的rowkey为:304405290216|0001。通过这种生成方式,rowkey的大小可以有16个字节,相对较小并且为8字节的倍数,也满足内存对齐的要求,能够充分利用操作系统的性能。可以理解的是,告警数据是时间序列类型的数据,如果不对rowkey进行散列处理,就会导致大量操作集中在一个region上的热点问题,因此rowkey的设计应尽可能的均匀地分布到各个region上。另外,过长的rowkey会占用更多的存储开销和降低内存利用率,进而影响到服务器的性能,因此rowkey可以不必使用可读性很强的字符串,而且其长度不易过大,一般建议在100字节以内。通过rowkey的这种设计方式能够带来两个方面的优势:首先以时间的时分秒进行的散列可以将告警数据相对均匀的分布到各个region上,能够较好的避免热点问题的发生;另外,由于网管告警流水号中包含有告警发生时间,可以通过网管告警流水号直接转化为rowkey,这样可以通过rowkey直接操作相关的告警数据,保证了根据网管告警流水号进行存取操作的效率,对于告警写入/更新、告警详情查询的需求能够保证一个很好的性能。可以理解的是,每条告警从发生到处理入库需要的时间会有差别(有些延时小,有些延时大),这样同一个时刻内发生的告警记录经过处理后,入库的时间点一般不会集中在一起。例如告警发生时间为2015-05-2905:44:20的一条告警记录,经过处理后可能入库时间在2015-05-2905:45:11,而同一时刻的其他告警入库时间可能在其他时间,如2015-05-2905:45:38。在具体应用中,在所述步骤103之后,本实施例所述方法还可以包括图中未示出的步骤104-105:104、获取查询条件并进行组合,获得查询组合的索引名,将所获取的查询条件按照该索引名所对应的索引类型的预设条件顺序进行拼接以计算出索引值,并将所获取的查询条件中的开始时间和结束时间分别转化为所述新的网管告警流水号的格式,获得满足所获取的查询条件的rowkey范围。在具体应用中,所述查询条件的字段可以包括:网管告警流水号、开始时间、结束时间、地市、设备厂商、设备类型、告警专业、告警级别、告警标题、告警类别、响应级别、工程状态、工单状态、派单状态、清除状态、网元在网状态等,本实施例并不对其进行限制;相应地,所述查询条件的组合可以为:将网管告警流水号、开始时间和结束时间三个查询条件之外的其他查询条件进行组合作为索引值,然后去掉重复组合、前缀组合以及不需要的组合,得到全部查询条件的组合;其中,所述重复组合为条件相同但顺序不同的组合类型,比如地市+告警专业+设备类型和设备类型+告警专业+地市,在实际查询时可以根据查询条件拼接出指定顺序的组合,因此重复组合是多余的,只保留一个即可;所述前缀组合为一个查询条件的组合是另一个查询条件的组合的前缀,比如地市+告警专业+设备类型就是地市+告警专业+设备类型+告警级别的前缀,按条件查询时满足后者的数据必定满足前者,可以通过后者的索引项来查询,因此前缀组合是多余的,可以去掉;最后将不需要的条件组合去掉,通过去除冗余索引可以提高索引的利用率。举例来说,2015-05-2905:44:20的一条告警记录,创建基于地市和专业查询的名为cm的索引,可通过索引名+地市+专业+网管告警流水号生成,即:cm济南市交换专业201602290544200001;为了直观,将各个部分以竖线分隔,即写入辅助索引表中的rowkey为:cm|济南市|交换专业|20160229054420|0001。以地市、设备厂商、设备类型、告警专业、告警级别为例,每个条件以字母或数字标识,即地市(a)、设备厂商(b)、设备类型(c)、告警专业(d)、告警级别(e),则处理后的查询条件的组合为abcde、bcde、cdea、deab、eabc、deb、ebc、eac、acd、abd、bd、ce、da共十三种。根据辅助索引表rowkey的生成方式,使用条件组合中的字符作为索引名,然后将该类索引中的各个条件进行组合形成索引值,并在最后添加网管告警流水号,得到索引表的rowkey。可以理解的是,所述步骤104可以这样可以快速地锁定满足查询条件的rowkey范围,提高条件查询的性能。举例来说,查询2016-01-1500:00:00到2016-01-1508:00:00的济南市交换专业发生的一级告警情况,通过前面的查询条件的组合(地市a,告警专业d、告警级别e)可以使用deab这一类索引,拼接查询条件为:济南市|交换专业|一级告警,并将开始时间转换为告警流水号格式为20160115000000|0000,将结束时间转换为告警流水号格式为20160115080000|9999,则可以确定满足查询条件的区间为:(deab|济南市|交换专业|一级告警|20160115000000|0000,deab|济南市|交换专业|一级告警|20160115080000|9999)。105、利用scan(startrowkey,endrowkey)操作,获取所述满足所获取的查询条件的rowkey范围对应的索引数据,并利用该索引数据rowkey中的网管告警流水号对所述hbase告警数据表进行查询,以获得满足所获取的查询条件的告警数据。举例来说,本实施例对于hbase告警数据表按散列值的前三位预先划分360个区间,以确保请求能够相对均匀的分布到各个regionserver上,告警查询的主要条件有厂家(a)、地市(b)、设备类型(c)、告警专业(d)、告警级别(e)、退服类型(f)、工程状态(g)、响应级别(h)、预处理状态(i)、覆盖场景(j)、标准化状态(k)、告警状态(l)、派单方式(m)、网络一级分类(n)、梳理表版本(o)、告警类别(p)等16个条件,条件组合种类太多(去除前缀、重复和不用的,整理后有2000左右),不适合按索引名划分,因此使用首字母进行辅助索引表almindex的预分区划分,划分为17个区间。在进行表的预分区后,通过webui可查看region分布情况。图.regionserver状态。经过hbase存储告警数据的改造后,随机选取200条告警的告警流水号,在按流水号查询单条告警数据时,通过统计分析可发现查询耗时一般在0.2s~0.25s,参见图3。按条件进行查询时查询效率相对传统的告警存取方式有较大的改善。通过分别对一天、一周、一月、六个月等几个时间段内的满足三个组合条件(地市为济南市,厂家为华为,设备类型为交换机)的告警情况的进行查询并分析平均耗时情况,可以发现性能有明显提升,参见图4。另外,hbase可以无缝的支持spark计算集群对告警数据的需求,spark能够直接通过api直接来操作hbase,获取存储的hbase上的数据内容,方便了spark对数据集的获取。并且,由于hbase列存储的特性,可以只获取需要分析的字段内容,而不用将所有的一百多个字段读入内存中,降低了资源消耗和提升了数据获取效率。本实施例引入hbase后,故障管理系统将经过告警组件处理后的标准告警数据存储在hbase中,并在使用时通过查询接口从hbase中进行数据的查询。替换原始告警数据库后,故障管理系统的告警处理组件接口不变,通过调用相关的告警处理接口完成对hbase的操作。本实施例的基于hbase的告警数据存储方法,能够实现对告警数据进行存储,以使后续能查询到最新的告警数据,满足告警数据存取需求,可以显著提高后续对告警数据查询的效率。本实施例所述方法将hbase应用于运营商故障管理系统的告警数据存储中来解决目前的告警数据库瓶颈问题,提升告警数据的写入和读取效率,期望能够更好的为故障管理系统和数据挖掘任务提供数据服务。图5示出了本发明一实施例提供的一种基于hbase的告警数据存储装置的结构示意图,如图5所示,本实施例的基于hbase的告警数据存储装置,包括:第一获取模块51、划分模块52和处理模块53;其中:第一获取模块51,用于获取告警数据和所述告警数据中的告警字段在预设时间段内的使用频率;划分模块52,用于根据所述使用频率,将所述告警数据中的所有告警字段划分为热字段和冷字段,并将划分为热字段的告警字段和划分为冷字段的告警字段分别归属到预先创建的hbase告警数据表中的不同列族;处理模块53,用于根据告警发生时间,对所述告警数据中的每条告警记录进行散列处理,并根据散列处理结果,按照预设行主键格式生成每一条告警记录在所述hbase告警数据表中的行主键rowkey,以使不同时刻的告警记录均匀分散到所述hbase告警数据表的各个region上,同时向预先创建的辅助索引表写入索引数据。在具体应用中,本实施例所述装置还可以包括图中未示出的:第一创建模块,用于创建具有预设数量个region的hbase告警数据表,所述预设数量个region均匀分布在hbase集群的各个区域服务器regionserver上;第二创建模块,用于根据索引名或索引名的前n个字母确定所述hbase告警数据表的辅助索引表的region数量m,创建具有m个region的所述辅助索引表,使所述hbase告警数据表中的每条告警记录的每类索引均对应所述辅助索引表中的一条索引数据,所述m个region均匀分布在hbase集群的各个区域服务器regionserver上,n和m均为正整数;其中,所述hbase告警数据表的字段包括:行主键rowkey、时间戳timestamp、第一列族和第二列族;所述辅助索引表的字段包括:rowkey、timestamp和第三列族,索引数据的所有字段均归属于所述第三列族。在具体应用中,本实施例所述装置还可以包括图中未示出的:第二获取模块,用于获取查询条件并进行组合,获得查询组合的索引名,将所获取的查询条件按照该索引名所对应的索引类型的预设条件顺序进行拼接以计算出索引值,并将所获取的查询条件中的开始时间和结束时间分别转化为所述新的网管告警流水号的格式,获得满足所获取的查询条件的rowkey范围;查询模块,用于利用scan操作,获取所述满足所获取的查询条件的rowkey范围对应的索引数据,并利用该索引数据rowkey中的网管告警流水号对所述hbase告警数据表进行查询,以获得满足所获取的查询条件的告警数据。本实施例的基于hbase的告警数据存储装置,可以用于执行前述方法实施例的技术方案,其实现原理和技术效果类似,此处不再赘述。本实施例的基于hbase的告警数据存储装置,能够实现对告警数据进行存储,以使后续能查询到最新的告警数据,满足告警数据存取需求,可以显著提高后续对告警数据查询的效率。图6示出了本发明实施例提供的一种电子设备的实体结构示意图,如图6所示,该电子设备可以包括:处理器11、存储器12、总线13及存储在存储器12上并可在处理器11上运行的计算机程序;其中,所述处理器11,存储器12通过所述总线13完成相互间的通信;所述处理器11执行所述计算机程序时实现上述各方法实施例所提供的方法,例如包括:获取告警数据和所述告警数据中的告警字段在预设时间段内的使用频率;根据所述使用频率,将所述告警数据中的所有告警字段划分为热字段和冷字段,并将划分为热字段的告警字段和划分为冷字段的告警字段分别归属到预先创建的hbase告警数据表中的不同列族;根据告警发生时间,对所述告警数据中的每条告警记录进行散列处理,并根据散列处理结果,按照预设行主键格式生成每一条告警记录在所述hbase告警数据表中的行主键rowkey,以使不同时刻的告警记录均匀分散到所述hbase告警数据表的各个region上,同时向预先创建的辅助索引表写入索引数据。本发明实施例提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述各方法实施例所提供的方法,例如包括:获取告警数据和所述告警数据中的告警字段在预设时间段内的使用频率;根据所述使用频率,将所述告警数据中的所有告警字段划分为热字段和冷字段,并将划分为热字段的告警字段和划分为冷字段的告警字段分别归属到预先创建的hbase告警数据表中的不同列族;根据告警发生时间,对所述告警数据中的每条告警记录进行散列处理,并根据散列处理结果,按照预设行主键格式生成每一条告警记录在所述hbase告警数据表中的行主键rowkey,以使不同时刻的告警记录均匀分散到所述hbase告警数据表的各个region上,同时向预先创建的辅助索引表写入索引数据。本领域内的技术人员应明白,本申请的实施例可提供为方法、装置、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。本申请是参照根据本申请实施例的方法、装置、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置/系统。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。术语“上”、“下”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。本发明的说明书中,说明了大量具体细节。然而能够理解的是,本发明的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。类似地,应当理解,为了精简本发明公开并帮助理解各个发明方面中的一个或多个,在上面对本发明的示例性实施例的描述中,本发明的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的方法解释呈反映如下意图:即所要求保护的本发明要求比在每个权利要求中所明确记载的特征更多的特征。更确切地说,如权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本发明的单独实施例。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。本发明并不局限于任何单一的方面,也不局限于任何单一的实施例,也不局限于这些方面和/或实施例的任意组合和/或置换。而且,可以单独使用本发明的每个方面和/或实施例或者与一个或更多其他方面和/或其实施例结合使用。最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1