改进的FP‑GROWTH方法与流程
本发明属于数据挖掘分析技术领域,涉及数据关联分析方法,更为具体的说,是涉及一种改进的fp-growth方法。
背景技术:
关联分析又称关联挖掘,是指在交易数据、关系数据或其他信息载体中,查找存在于项目集合或对象集合之间的频繁模式、关联、相关性或因果结构。在实际应用中,关联分析能够用于发现交易数据库中不同商品(项)之间的联系,例如常见的购物篮分析。
关联分析适用性广泛,为了挖掘数据库中数据的关联关系,常用的方法有apriori方法。apriori方法主要是根据数据库中具有最小支持度的数据集生成关联规则。但其缺陷也很明显,计算机系统的开销会随着数据库的记录的增加呈现出几何级数的增加,这就造成了计算效率的低下。而fp-growth方法能够很好地解决这个问题。
fp-growth方法通过扫描2次数据库形成频繁模式树,由此得到压缩的数据库映射,再根据得到的频繁模式树进行关联分析。growth算法相比于apriori算法有更强的适用性和更高的计算效率,但在某些数据的应用中尚有缺陷。例如航空数据数据量大重复率低,传统fp-growth算法建立fp-tree效率低下,速度慢,无法令人满意。虽然有学者针对fp-growth算法的不足提出了很多改进算法,但是这些改进算法并不能满足航空领域数据分析的需求,不能反映航空领域数据的特点,处理效率也不能满足需求。因此,如何使得fp-growth算法能够更好地适应航空领域数据分析需求、提升效率,成为亟待解决的问题。
技术实现要素:
针对fp-growth算法中,由于航空数据数据量大重复率低特点,导致的传统fp-growth算法建立fp-tree效率低和速度慢的问题,本发明设计了一种改进的fp-growth方法,能够显著提高fp-growth算法的运行效率。
为了达到上述目的,本发明提供如下技术方案:
改进的fp-growth方法,包括如下步骤:
步骤1,对数据库遍历,获取每个项的支持度,按顺序排列支持度得到list,根据list对数据库中的事务排序;
步骤2,根据得到的list,将数据库中的事务插入到一个fp-tree中;
步骤3,运用bloomfilter判断当前节点的子节点是否存在当前项,如果当前项存在于当前节点的子节点中,则寻找到该节点进行插入;如果当前项不存在于当前节点的子节点中,则产生一个新的节点进行插入;
步骤4,挖掘数据库中各项之间的关联关系。
进一步的,步骤1具体包括如下步骤:
步骤11,扫描一遍数据集,计算每个项的支持度;
步骤12,按照最小支持度删除不符合要求的项;
步骤13,按照支持度的逆序排列,排列结果即为list;
步骤14,将数据库中的各个事务按照list重新排列。
进一步的,步骤2具体包括:
步骤21,将当前事务的当前项插入当前节点的子节点中,对于第一次插入则当前节点为null节点;如果当前节点的子节点存在当前项,则将该子节点的支持度加1,如果不存在,则创建一个新的节点,新节点支持度为1;
步骤22,将当前节点移动到该子节点或新节点;
步骤23,将当前事务中的当前项移动到下一项,重复步骤21至步骤23;如果当前事务中的当前项没有下一项则移动到下一事务,重复步骤21至步骤23,如果没有下一事务则完成fp-tree的建立。
进一步的,步骤3中bloomfilter的判断过程如下:
计算数据集x中每一个字符串的k个hash值,然后将k个hash值插入到位数组v中,将要查询的事务分别计算k个hash值,模拟插入步骤,建立一个新的位数组v′,将与v进行对比,如果相同则说明要查询的事务在原事务集中。
进一步的,插入规则为,如果对应位的值为0,hash值为1,则将位数组中对应位置变为1,如果位数组中对应位置已经为1,则不作变动。
进一步的,步骤4具体包括如下步骤:
步骤41,按照list的逆序选择第一个节点n1,将包含n1的路径保存,删除其余的节点路径,并更新fp-tree中的支持度,生成条件模式树;
步骤42,按照list的逆序寻找n1的下一个节点n2,根据新树中的支持度删除不频繁项;
步骤43,按照list的逆序继续寻找n2下一个节点,重复步骤42,直到list中的第一个元素;
步骤44,合并所有的频繁项集,所得是以n1为节点的频繁项集;
步骤45,递归寻找n1的下一个节点,重复步骤41-步骤44,直到节点为null。
进一步的,所述步骤42中,如果有公共前缀,则进行合并。
与现有技术相比,本发明具有如下优点和有益效果:
本发明方法通过判断插入步骤与查询步骤中位数组的异同,简化fp-tree的插入时间,从而降低了建立fp-tree的时间,提高了方法的运行效率;在bloomfilter判断后,当数据不存在时直接插入一个新的节点,从而减少了遍历的判断过程,提高算法效率。与传统的fp-growth方法相比,在测试数据量比较大的时候本发明方法运行效率有明显的提高,能够显著优化航空数据的运算效率。
附图说明
图1为本发明提供的改进的fp-growth方法步骤流程图。
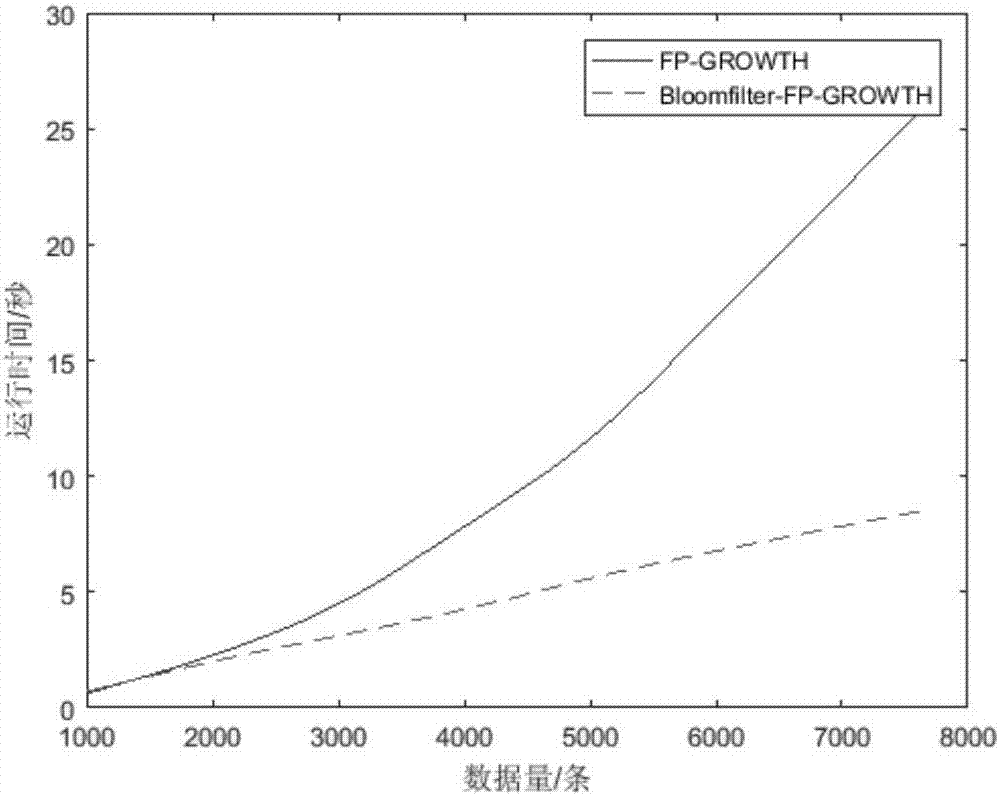
图2为改进的fp-growth算法和fp-growth算法运算时间对比图。
具体实施方式
以下将结合具体实施例对本发明提供的技术方案进行详细说明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
本发明提供的改进的fp-growth方法,如图1所示,包括如下步骤:
s1、对数据库遍历,获取每个项的支持度,得到list,根据list对数据库中的事务排序;
具体的,s1步骤具体包括如下步骤:
s11、扫描一遍数据集,计算每个项的支持度。
s12、按照最小支持度删除不符合要求的项,即如果当前项的支持度小于最小支持度则删去该项;
s13、按照支持度的逆序排列,排列结果即为list;
s14、将数据库中的各个事务按照list重新排列。
s2、根据得到的list,将数据库中的事务插入到一个fp-tree中;
具体的,s2步骤包括如下步骤:
s21,将当前事务的当前项插入当前节点的子节点中,对于第一次插入则当前节点为null节点;
如果当前节点的子节点存在当前项,则将该子节点的支持度加1,如果不存在,则创建一个新的节点,新节点支持度为1;
s22、将当前节点移动到该子节点或新节点;
s23、将当前事务中的当前项移动到下一项,重复步骤21至步骤23;如果当前事务中的当前项没有下一项则移动到下一事务,重复步骤21至步骤23,如果没有下一事务则完成fp-tree的建立。
s3、运用bloomfilter判断当前节点的子节点是否存在当前项;
具体操作为:计算数据集x中每一个字符串的k个hash值,然后将k个hash值插入到位数组v中,插入规则为,如果对应位的值为0,hash值为1,则将位数组中对应位置变为1,如果位数组中对应位置已经为1,则不作变动。将要查询的事务分别计算k个hash值,然后模拟插入步骤,建立一个新的位数组v′,然后将与v进行对比,如果相同则说明要查询的事务在原事务集中,即当前项存在于当前节点的子节点中。如果当前项存在于当前节点的子节点中,则寻找到该节点进行插入。如果当前项不存在于当前节点的子节点中,则产生一个新的节点进行插入。
该过程中,如果经过bloomfilter判断后,数据不存在,则可以直接插入一个新的节点,从而减少了遍历的判断过程,提高了算法的运行效率。
s4、挖掘数据库中各项之间的关联关系。
具体的,该步骤包括如下步骤:
s41、按照list的逆序选择第一个节点n1,将包含n1的路径保存,删除其余的节点路径,并更新fp-tree中的支持度,生成条件模式树。
s42、按照list的逆序寻找n1的下一个节点n2,根据新树中的支持度删除不频繁项,如果有公共前缀,则进行合并。
s43、按照list的逆序继续寻找n2下一个节点,重复步骤s42,直到list中的第一个元素。
s44、合并所有的频繁项集,所得是以n1为节点的频繁项集。
s45、递归寻找n1的下一个节点,重复s41-s44步骤,直到节点为null。
本发明利用真实航空数据,分别用fp-growth方法和本发明提供的改进的fp-growth方法进行运算,并针对上述两个方法从运算时间方面进行了对比,结果如图2所示。由图2可知:两种算法在测试数据量比较低的时候运行速度是一样的,但在测试数据量比较大的时候就有了明显的区别。从观察结果可知,改进的fp-growth在提高运行效率的方面拥有良好的表现,能够显著优化传统的fp-growth算法在航空数据方面的运算效率。
本发明方案所公开的技术手段不仅限于上述实施方式所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!