联合特定人物和场景的视频实例检索方法及系统与流程
本发明属于视频检索
技术领域:
,涉及一种视频实例检索技术方案,尤其涉及联合特定人物和场景的视频实例检索方法及系统。
背景技术:
:在视频分析与检索技术评测中,视频实例检索是指给定查询样例(大量视频片段或者图像数据)和视频库,从视频库中检索出现了给定查询样例的所有视频片段(镜头),并根据与给定查询样例的相似程度进行排序。查询样例可以是不同场景的含特定的人、车、物等特定目标的若干图像,有时也会给出包含该目标的视频片段。联合特定人物和场景的视频实例检索是指在海量视频数据中检索出某一特定人物在某一特定场景出现的片段。该技术有助于公安人员在海量监控视频中排除不相关目标,关注重点目标,聚焦、观察、分析嫌疑对象,显著提高海量监控视频浏览效率,进而对提高公安部门应急处置能力和社会治安综合防控能力、维护人民生命财产安全具有重要意义。目前联合特定人物和场景的视频实例检索技术所面临的挑战重要来自于三个方面:第一、视频量巨大,存在大量的噪声,从海量的视频中找到少许待查目标非常不易;第二,检索人物存在衣着不一、姿态变换、场景角度变换等情况;第三,面临场景光照变化大、遮挡严重等情况。现有联合特定人物和场景的视频实例检索方法一般先分别检索特定人物和场景,再用后融合方式融合特定人物和场景检索结果得到联合人物和场景的视频实例检索结果。特定人物和场景检索结果一般是用分数来表示,分数越高,表示相应镜头含有查询样例的概率越大,融合方法可以是相加或者相乘同一镜头下特定人物和场景的分数。然而即使是正确的待查镜头,镜头对应人物检索结果或者场景检索结果也不一定高。中国专利文献号cn105678250a,公开(公告)日2016.06.15,公开了一种视频中的人脸识别方法和装置,该发明所述的视频中的人脸识别方法和装置采用动态识别方法,利用视频中各帧图像在时间维度上具有关联性的特征对各帧图像的信息进行互补,从而提高人脸识别的准确性,该方法虽然属于视频检索
技术领域:
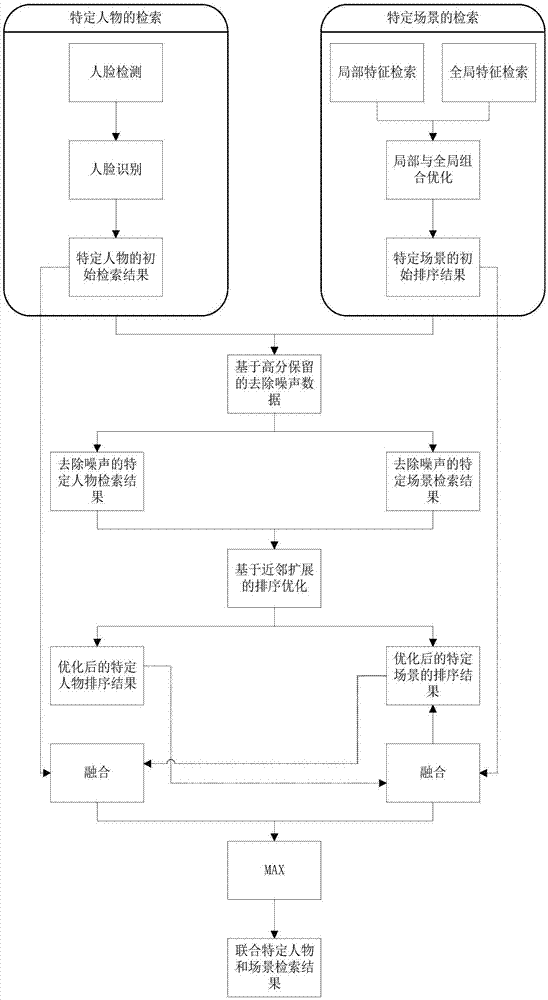
,但该方法只进行了人物的检索而没有场景检索,与一种联合特定人物和场景的视频实例检索的研究角度是不同的。中国专利文献号cn106022313a,公开(公告日)2016.10.12,公开了一种能自动适应场景的人脸识别方法,该方法所述的自动适应场景的人脸识别方法是指采用了卷积神经网络算法模型进行补偿,与传统的手工操作相比,具有更强的自动型,并没有涉及到场景的检索,与一种联合特定人物和场景的视频实例检索的研究角度是不同的。中国专利文献号cn104794219a,公开(公告)日2015.07.22,公开了一种基于地理位置信息的场景检索方法,该方法利用场景图像的地理信息和全局描述子进行索引,过滤大量的非相关的图像,提高视觉词汇空间验证的效率和图像匹配的准确率,该方法只进行了场景的检索而没有进行人物检索,与一种联合特定人物和场景的视频实例检索的研究角度是不同的。中国专利文献号cn104820711a,公开(公告)日2015.08.05,公开了一种复杂场景下对人形目标的视频检索方法,该方法通过不断在线调整搜索图像的相似度,在线更新,模型更新后产生新的一轮检索结果,该方法允许人机交互在新更新机器视觉识别模型库来得到一个满意的检索结果,该方法不是自动生成结果,因而该方法的检索性能还有待提升,而且与我们联合特定人物和场景的视频实例检索方法中通过融合人物和场景的检索结果得到最后的结果是不同的。中国专利文献号cn104517104a,空开(公告)日2015.04.15,公开了一种基于监控场景下人脸识别方法及系统,该方法通过采用gabor特征和多尺度rilpq特征分数级的融合方式,减小了人脸图像光照不均匀、存在旋转角度以及图像模糊等问题对人脸识别产生的影响,有效地提高了监控场景下的人脸识别率,该发明不能适用于除了监控场景下的其他场景,为了将联合特定人物和场景的视频实例检索方法适用于多个场景,该方法还有优化的空间。技术实现要素:针对现有技术存在的不足,本发明提供了一种联合特定人物和场景的视频实例检索技术方案,通过对初始检索结果采用高分保留、近邻扩展的排序优化后再进行融合得到最后的排序结果,进而提升检索出特定人物在特定场景出现的准确率。本发明所采用的技术方案是一种联合特定人物和场景的视频实例检索方法,包括以下步骤,步骤1,视频中特定人物的实例检索,包括针对一个查询人物p进行检索,输出查询人物p和查询视频库中每一个镜头的相似度分数,得到特定人物检索的排序结果,作为初始的人物检索结果;步骤2,视频中特定场景的实例检索,包括针对一个查询场景s进行检索,包括以下子步骤,步骤2.1,进行基于局部特征的特定目标检索;步骤2.2,进行基于全局特征的特定场景检索;步骤2.3,实现基于局部与全局组合优化的特定场景检索,包括根据基于局部特征的特定目标检索结果和基于全局特征的特定场景检索结果对镜头进行交叉重排,得到最终的特定场景检索的排序结果,作为初始的场景检索结果;步骤3,实现基于高分保留的视频实例检索,去除步骤1所得特定人物检索的排序结果和步骤2所得特定场景检索的排序结果中的排名靠后的结果,得到去噪后的人物检索结果和去噪后的场景检索结果;步骤4,实现基于近邻扩展的视频实例检索,包括根据步骤3所得结果进行基于近邻扩展的优化,得到近邻扩展后的人物检索结果和近邻扩展后的场景检索结果;步骤5,融合特定人物检索和特定场景检索结果,包括对于每个镜头,融合初始的场景检索结果与近邻扩展后的人物检索结果,再融合初始的人物检索结果和近邻扩展后的场景检索结果,取两种融合结果的最大值,得到视频实例检索的镜头排序结果。而且,所述基于局部特征的特定目标检索,包括对一个查询场景s相应的多张待查图片,提取每张待查图片中各目标区域的bow特征;提取查询视频库所有镜头中所有关键帧的bow特征;根据bow特征,对各待查图片的每个目标区域,计算与各镜头中所有关键帧分别的欧式距离,取最小欧式距离为目标区域与镜头的相似度;对各镜头,分别取所有目标区域与该镜头的相似度最大值作为镜头的相似度分数,得到基于局部特征的特定目标检索结果;而且,所述基于全局特征的特定场景检索,包括对一个查询场景s相应的多张待查图片,提取每张待查图片的cnn特征,提取查询视频库所有镜头中所有关键帧的cnn特征;根据cnn特征,对各待查图片,计算与各镜头中所有关键帧分别的欧式距离,取最小欧式距离为待查图片与镜头的相似度;对各镜头,分别取所有待查图片与该镜头的相似度最大值作为镜头的相似度分数,得到基于全局特征的特定目标检索结果;而且,进行基于近邻扩展的优化,实现方式如下,设任意人脸或场景相应镜头n初始分数为f(n),e(i,n)为被镜头i经过高斯近邻调整后的镜头分数,其中i,n∈[1,n],n为待检索的镜头总数,e(i,n)定义如下,e(i,n)=f(i)g(n-i)r(n)其中,g(n)为高斯序列,r(n)为矩形窗序列;经过基于高斯模型的分数调整后,每个镜头得到分数e(n+τ,n),...,e(n+1,n),e(n,n),...,e(n-τ,n),选择调整后的最高分代表镜头调整后的分数。本发明还相应提供一种联合特定人物和场景的视频实例检索系统,包括以下模块,人物检索模块,用于视频中特定人物的实例检索,包括针对一个查询人物p进行检索,输出查询人物p和查询视频库中每一个镜头的相似度分数,得到特定人物检索的排序结果,作为初始的人物检索结果;场景检索模块,用于视频中特定场景的实例检索,包括针对一个查询场景s进行检索,包括以下单元,局部检索单元,用于进行基于局部特征的特定目标检索;全局检索单元,用于进行基于全局特征的特定场景检索;组合检索单元,用于实现基于局部与全局组合优化的特定场景检索,包括根据基于局部特征的特定目标检索结果和基于全局特征的特定场景检索结果对镜头进行交叉重排,得到最终的特定场景检索的排序结果,作为初始的场景检索结果;初步优化模块,用于实现基于高分保留的视频实例检索,去除人物检索模块所得特定人物检索的排序结果和场景检索模块所得特定场景检索的排序结果中的排名靠后的结果,得到去噪后人物检索结果和去噪后场景检索结果;近邻优化模块,用于实现基于近邻扩展的视频实例检索,包括根据初步优化模块所得结果进行基于近邻扩展的优化,得到近邻扩展后的人物检索结果和近邻扩展后的场景检索结果;融合优化模块,用于融合特定人物检索和特定场景检索结果,包括对于每个镜头,融合初始的场景检索结果与近邻扩展后的人物检索结果,再融合初始的人物检索结果和近邻扩展后的场景检索结果,取两种融合结果的最大值,得到视频实例检索的镜头排序结果。而且,所述基于局部特征的特定目标检索,包括对一个查询场景s相应的多张待查图片,提取每张待查图片中各目标区域的bow特征;提取查询视频库所有镜头中所有关键帧的bow特征;根据bow特征,对各待查图片的每个目标区域,计算与各镜头中所有关键帧分别的欧式距离,取最小欧式距离为目标区域与镜头的相似度;对各镜头,分别取所有目标区域与该镜头的相似度最大值作为镜头的相似度分数,得到基于局部特征的特定目标检索结果;而且,所述基于全局特征的特定场景检索,包括对一个查询场景s相应的多张待查图片,提取每张待查图片的cnn特征,提取查询视频库所有镜头中所有关键帧的cnn特征;根据cnn特征,对各待查图片,计算与各镜头中所有关键帧分别的欧式距离,取最小欧式距离为待查图片与镜头的相似度;对各镜头,分别取所有待查图片与该镜头的相似度最大值作为镜头的相似度分数,得到基于全局特征的特定目标检索结果;而且,进行基于近邻扩展的优化,实现方式如下,设任意人脸或场景相应镜头n初始分数为f(n),e(i,n)为被镜头i经过高斯近邻调整后的镜头分数,其中i,n∈[1,n],n为待检索的镜头总数,e(i,n)定义如下,e(i,n)=f(i)g(n-i)r(n)其中,g(n)为高斯序列,r(n)为矩形窗序列;经过基于高斯模型的分数调整后,每个镜头得到分数e(n+τ,n),...,e(n+1,n),e(n,n),...,e(n-τ,n),选择调整后的最高分代表镜头调整后的分数。与现有联合特定人物和场景的视频实例检索技术相比,本发明主要具有以下优点和有益效果:1)与现有技术相比,本发明去除了初始排序结果中排名靠后的结果,使得排名靠前的检索结果更加可靠;2)与现有技术相比,本发明基于近邻高分镜头来调整低分镜头,使得许多误删的镜头被重排在排序结果靠前位置,使得视频实例检索排序结果更加可靠;3)本发明引入排序融合的方式来改进联合特定人物和场景的视频实例检索技术的性能,在排序层面上的优化使得方案拓展性和适用性很强。附图说明图1为本发明实施例原理示意图。图2为本发明实施例流程图。具体实施方式为了便于本
技术领域:
普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。参见图1,本发明所采用的技术方案是一种联合特定人物和场景的视频实例检索方法,联合特定人物和场景的视频实例检索实现时分别从检索特定人物和场景入手,首先基于人脸识别技术和局部与全局组合优化的特定场景检索得到特定人物和特定场景检索结果,对特定人物和特定场景检索结果做高分保留、近邻扩展的排序优化,最后融合优化后的特定人物和特定场景检索结果得到联合特定人物和场景的视频实例检索结果。本实施例采用matlabr2015b和vs2013作为仿真实验平台,在国际视频分析与检索技术测评trecvid的实例检索任务instancesearch(ins)数据集上进行测试。ins数据集包含464个小时的英国bbc电视剧《东区人》中的244个视频片段,这244个片段被分成471,526个镜头,每个镜头下有多帧图片,且这些视频和图片中出现了许多人物和场景,由于拍摄角度、时间变换等因素,这些人物和场景一直都在变化。参见图2,本发明实施例的流程包括:步骤1,视频中特定人物的实例检索:针对一个特定的查询人物p,利用人脸识别技术来实现特定人物检索,输出特定的查询人物p和查询视频库每一个镜头的相似度分数,得到特定人物检索的排序结果,作为初始的人物检索结果。人脸识别技术具体实现可采用现有技术,例如基于faster-rcnn采用尺度自适应的深度卷积回归网络进行人脸检测,主要包含人脸候选人形成和人脸/背景分类两个步骤,faster-rcnn为深度学习网络模型;并采用深度卷积神经网络学习人脸特征,进行人脸识别。可利用预先建立的大型casia-webface人脸库训练网络,该人脸库中含有8万个行人,并且每个行人含有500-800张人脸。具体实施时,可参考文献:y.zhu,j.wang,c.zhao,h.guoandh.lu.scale-adaptivedeconvolutionalregressionnetworkforpedestriandetection,accv,2016.haiyunguo,etal.multi-view3dobjectretrievalwithdeepembeddingnetwork,icip,2016.本领域技术人员可自行选择使用的具体人脸识别技术,本发明不予赘述。步骤2,视频中特定场景的实例检索:针对一个特定的查询场景s,基于给定场景图片的局部和全局特征实现特定场景检索,查询视频库中每个视频有多个镜头,每个镜头有多张关键帧,本发明要求找出哪些包含查询场景s的镜头,最后每个镜头的结果由某一张关键帧的结果来表示。实施例中,步骤2具体实现包括以下子步骤:步骤2.1,基于局部特征的特定目标检索;对一个查询场景s给出多张待查图片,以每张待查图片中的不同的刚性物体为待检索的特定的目标,其具体实现包括以下子步骤:步骤2.1.1,提取一张待查图片某目标区域的bow特征(bow表示词袋),采用sift算法提取特征后,对sift特征进行tf-idf(关键词频率一逆频率)策略加权且进行了root(取方根)和归一化操作,最后,将目标区域中sift点依次与预先训练所得码书中每个视觉词汇比较,找出欧式距离小的3个视觉词汇,用这3个视觉词汇代表该特征点(软匹配方法),对各sift点分别处理完成后,计算该目标区域中视觉词汇的直方图分布状况,即可得到目标区域的bow特征。步骤2.1.2,提取查询视频库的bow特征,这里提取查询视频库所有视频镜头中所有关键帧的bow特征,与提取待查图片的目标区域bow特征过程一致。步骤2.1.3,根据bow特征,对各待查图片的每个目标区域,计算与各镜头中所有关键帧分别的欧式距离,取最小欧式距离为目标区域与镜头的相似度。实施例中,基于bow特征的结果初排,利用上面两个步骤得到的bow特征,进行各待查图片的每个目标区域与各镜头中所有关键帧分别的相似度计算,相似度为欧式距离的倒数,选取目标区域与镜头内所有关键帧的最小欧式距离,代表目标区域与被查的某镜头间的距离,公式如下:d(ii,j)=min{d(ii,j1),d(ii,j2),...,d(ii,jn)}(1)其中ii代表所有待查图片中某待查图片的一个目标区域,j代表镜头,且该镜头内有n个关键帧j1,j2,…,jn,d(ii,jj)代表目标区域ii与镜头内某一关键帧jj间的距离,j=1,2,…,j,也即两幅图像间的距离。本方法采用目标区域与镜头内所有关键帧的最小距离(最小池化)来对图像与镜头间的相似度进行计算,其中d(ii,jj)采用一种查询自适应距离度量方法得到,可参见文献cai-zhizhu,hervejegou,shinichisatoh.query-adaptiveasymmetricaldissimi-laritiesforvisualobjectretrieval.iniccv.(2013)步骤2.1.4,对各镜头,分别取所有目标区域与该镜头的相似度最大值作为镜头的相似度分数,得到基于局部特征的特定目标检索结果。对于一个场景多张待查图片里面的多个目标,每个目标的查询结果都代表这个场景的检索结果,每个目标的查询结果都是以相似度分数来表示的,分数越高,表示该结果包含要找的场景的概率越大,本发明对所有待查图片中各目标的查询分数整体做一次max-pooling(取所有目标分数的最大值),来代表这个场景基于局部特征的检索结果。步骤2.2,基于全局特征的特定场景检索,通过一个查询场景s相应的多张待查图片,去检索场景,主要通过卷积神经网络模型来实现;其具体实现包括以下步骤:步骤2.2.1,基于rcnn的全局特征提取,实施例采用facebook公开在torch上训练好的残差网络(rcnn)模型进行图像的特征提取;取查询场景s相应的多张待查图片作为输入图片提取特征,将所有查询视频库中的关键帧作为输入图片提取特征。采用rcnn网络的两种输出,一种是输入图片经过网络学习后卷积层的输出特征,维度为2048*1,一种是输入图片的分别属于预定义的1000个类别的概率,维度为1000*1。步骤2.2.2,根据cnn特征,对各待查图片,计算与各镜头中所有关键帧分别的欧式距离,取最小欧式距离为待查图片与镜头的相似度。实施例中,通过上面的步骤,得到了各待查图片与查询视频库的cnn特征,这里采用2048*1的特征来表示图片,在结果排序上采用与基于局部特征的特定目标检索初排的方法类似,在待查图片与镜头内的若干张图像进行距离计算后,选取被查镜头的所有帧中与查询图片间的最小距离来代表该镜头与查询图片的相似度,还是采用公式(1)的方法。本发明进一步提出,根据输出的输入图片的分别属于预定义的1000个类别的概率,可以预设一个阈值,某一类的概率大于这个阈值,就判定改镜头含有这一类别,当要找的场景都是室内场景,对于判定为含有汽车等只会在室外场景出现的类别,可以将该镜头的分数置为0,有益于提高精度。步骤2.2.3,对各镜头,分别取所有待查图片与该镜头的相似度最大值作为镜头的相似度分数,得到基于全局特征的特定目标检索结果。从全局出发,与步骤2.1类似,首先,对一个查询场景s的多张待查图片,不同的待查图片的基于全局的目标检索结果(取距离d(ii,j)的倒数)进行归一化,然后,采用所有不同待查图片的最好结果代表该镜头,最后重排结果得到最终的基于全局特征的特定场景检索结果。本发明中,每个场景的每张待查图片都会和查询视频库做特征的距离度量,取距离度量的倒数就能得到每一张待查询图片和查询视频库里面的每一张关键帧的相似度分数,每一个镜头里面取分数最高的关键帧来表示这个镜头包含要找的场景的概率,最后对每一个场景的所有查询图片的检索结果做一次max-pooling(取所有目标分数的最大值),代表这个场景基于全局特征的检索结果。步骤2.3,基于局部与全局组合优化的特定场景检索,同时考虑全局与局部,分别交叉基于全局和局部特征的特定场景检索结果,重排镜头得到最终的特定场景的排序结果,作为初始的场景检索结果;具体实施时,可以采用预设的规则进行交叉,例如交叉排序查询结果,排名前3000的结果(排名结果是根据相似度分数来排的,分数越高,排名越靠前),为全局和局部各排名前1500的结果依次交替排序,其中全局在前,局部在后。步骤3,基于高分保留的视频实例检索:针对海量视频中存在大量非查询实例的视频的噪声数据,去除步骤1所得特定人物检索结果和步骤2所得特定场景检索结果中的排名靠后的结果,得到去噪后的人物检索结果和去噪后的场景检索结果。具体实施时,可以按比例去掉排名靠后的结果,例如从交叉排序查询结果中排名前3000的结果,去掉后1/3,例如排名第2001~3000的结果。步骤4,基于近邻扩展的视频实例检索:由于人或者场景会被遮挡,某些镜头的相似度分数不高被删除,本发明进一步提出对特定人物检索和特定场景检索结果进行近邻扩展的优化,具体实现步骤如下:对真实镜头中的低分镜头进行近邻扩展的优化,本方法提出基于高斯模型的分数调整方案,利用近邻高分镜头,提高低分镜头分数,达到调整低分镜头分数、提高低分镜头排名,使得许多误删的镜头被重排在排序结果靠前位置,使得排序结果更加可靠;具体实现包括以下子步骤:步骤4.1,假设任意人脸或场景相应镜头n初始分数为f(n),e(i,n)为被镜头i经过高斯近邻调整后的镜头分数,其中i,n∈[1,n],n为待检索的镜头总数,本实施例中n的取值为471,526,e(i,n)定义如下:e(i,n)=f(i)g(n-i)r(n)(2)其中g(n)为高斯序列,r(n)为矩形窗序列,二者的定义如下:r(k)=u(k+τ)-u(k-1-τ)(4)其中,参数k∈[0,±1,±2...],τ为前后扩展镜头数目,实验过程中τ的取值为8,u(z)为阶跃序列,根据参数z取值,公式如下:步骤4.2,理论上,经过基于高斯模型的分数调整后,每个镜头会得到分数e(n+τ,n),...,e(n+1,n),e(n,n),...,e(n-τ,n),本发明选择调整后的最高分代表该低分镜头调整后的分数,公式如下:f*(n)=max[e(n+τ,n),...,e(n+1,n),e(n,n),...,e(n-τ,n)](6)步骤5,融合特定人物检索和特定场景检索结果,得到最终联合特定人物和场景的视频实例检索结果。实现方式为:先融合特定人物近邻扩展后的结果与特定场景检索结果,再融合特定人物检索结果和特定场景近邻扩展后的结果,最后对于每个镜头,取这两种结果的最大值来表示最后的融合结果,公式如下:其中fp(n),fs(n)为初始的特定人物和特定场景检索结果,为近邻扩展后的人物和场景检索结果。最后得到的f(n)越大,表示该镜头中查询人物p出现在查询场景s的概率越大。这样每个镜头都会得到一个相似度分数,依据这个分数会有一个排序,分数度越高,表示这个镜头中查询人物p出现在查询场景s的概率越大,排名越靠前。输出镜头排序结果给用户。具体实施时,本发明所提供方法可基于软件技术实现自动运行流程,也可采用模块化方式实现相应系统。本发明实施例提供一种联合特定人物和场景的视频实例检索系统,包括以下模块,人物检索模块,用于视频中特定人物的实例检索,包括针对一个查询人物p进行检索,输出查询人物p和查询视频库中每一个镜头的相似度分数,得到特定人物检索的排序结果,作为初始的人物检索结果;场景检索模块,用于视频中特定场景的实例检索,包括针对一个查询场景s进行检索,包括以下单元,局部检索单元,用于进行基于局部特征的特定目标检索;全局检索单元,用于进行基于全局特征的特定场景检索;组合检索单元,用于实现基于局部与全局组合优化的特定场景检索,包括根据基于局部特征的特定目标检索结果和基于全局特征的特定场景检索结果对镜头进行交叉重排,得到最终的特定场景检索的排序结果,作为初始的场景检索结果;初步优化模块,用于实现基于高分保留的视频实例检索,去除人物检索模块所得特定人物检索的排序结果和场景检索模块所得特定场景检索的排序结果中的排名靠后的结果,得到去噪后的人物检索结果和去噪后的场景检索结果;近邻优化模块,用于实现基于近邻扩展的视频实例检索,包括根据初步优化模块所得结果进行基于近邻扩展的优化,得到近邻扩展后的人物检索结果和近邻扩展后的场景检索结果;融合优化模块,用于融合特定人物检索和特定场景检索结果,包括对于每个镜头,融合初始的场景检索结果与近邻扩展后的人物检索结果,再融合初始的人物检索结果和近邻扩展后的场景检索结果,取两种融合结果的最大值,得到视频实例检索的镜头排序结果。各模块具体实现可参见相应步骤,本发明不予赘述。为便于了解本实施例技术方案的效果起见,采用图像检索领域广泛使用的平均准确率map(meanaverageprecision)作为效果评价指标,该方法同时考虑到精度和召回率,其计算公式如下:其中参数m表示排序列表中总个数,j∈{1,...,m}且均为整数。相同条件下,map值越大表示检索结果越靠前;上述过程中,对初始的联合特定人物和场景的视频实例检索结果以及进行了高分保留和近邻扩展排序优化后的联合特定人物和场景的视频实例检索结果分别计算了map值,见表1。从表1中可以发现,本发明的基于高分保留、近邻扩展的联合特定人物和场景的视频实例检索方法的检索性能明显提高。表1在ins数据集上的map值融合结果map初始结果0.1420人物的优化结果和初始的场景结果0.1539人物的初始结果和场景的优化结果0.2134人物的优化结果和场景的优化结果0.2241应当理解的是,本说明书未详细阐述的部分均属于现有技术。应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1