基于GPU+CPU异构平台的三维大地电磁反演并行方法与流程
本发明涉及地质电磁勘探技术领域,尤其涉及一种基于gpu+cpu异构平台的三维大地电磁反演并行方法。
背景技术:
大地电磁法(mt)作为一种实用的低成本(相对于地震勘探)地球物理勘探方法,在构造研究、石油勘探、矿产及水文勘探等领域扮演着重要角色,是探测岩石层电性结构的主要方法。大地电磁法的基本原理是:通过观测天然变化的电磁场水平分量,经过数据处理计算阻抗和倾子张量数据,然后反演求得地下电阻率分布。在大地电磁法勘探数据的反演解释中,主要的计算过程包括正演和反演,正演是指已知地下的电阻率分布,根据电磁理论计算地面上不同测点不同频率的观测数据的过程;反演是指根据观测数据,求取地下的真实电阻率分布的过程,反演是一种最优化数学过程,其算法核心是求解当前猜测模型的正演,并对正演结果与实际观测数据做误差评价,求取修正量。
近年来,三维大地电磁法的正演、反演技术已实用化并取得了巨大进展。然而,随着勘探数据集的增大、对于勘探精度的需求不断提高,要求三维mt反演的计算速度更快、计算平台成本更低廉。在现有技术中,主要采用两种并行方案来提高计算速度。方案一、基于单机的多核cpu并行计算方案(如openmp),在反演的正演核中同时求解n个大型稀疏复线性方程组,n为计算机支持的最大并行线程数,例如,对于四核八线程cpu,可以同时执行8个线性方程组求解,因此,如果需要求解40个大型线性方程组,则需重复执行5次。该方案的缺点是由于单机只有一条系统总线,在同一时刻只有一个进程在执行,并行计算效率由cpu本身的缓存决定,一般加速比仅为cpu线程数的一半左右;方案二、适应并行计算集群(pc-cluster)的多节点并行计算方案(如openmpi),每个计算节点(等价于一台单机)在需要做三维大地电磁反演的正演计算时会被分配任务,求解得到结果后再通过高速局域网汇总结果到主计算节点。该方案的缺点是并行机价格昂贵,并且需要专门的机房和维护人员,计算程序无法安装在大地电磁数据采集的野外计算机上,而且针对并行机的mpi编程协议相对比较复杂,增加了开发成本,且代码的调试和维护非常困难。
技术实现要素:
本发明的目的在于克服上述现有技术的缺陷,提供能够充分利用单机硬件资源并提高三维大地电磁反演的并行计算能力的技术方案。
根据本发明的一方面,提供了一种基于gpu+cpu异构平台的三维大地电磁反演并行方法,包括:
步骤1:基于网格剖分和单元电阻率值形成三维大地电磁的正演方程组;
步骤2:获取求解所述正演方程组所需的存储空间大小;
步骤3:基于所述存储空间大小获取gpu最大并行线程数ng和cpu最大并行线程数nc;
步骤4:将求解所述正演方程组的并行计算任务分配给空闲的gpu线程和cpu线程执行。
优选地,在步骤4中,计算任务的分配顺序是,优先分配空闲的gpu线程,若gpu线程均不空闲则分配给cpu线程。
优选地,所述正演方程组表示为:
其中,xx、xy和xz为求解向量,bx、by和bz分别是各方向电场对应的右端项子向量,
优选地,以按行压缩的稀疏矩阵方式将所述系数矩阵存储为行指针数组、列下标数组和非零数值数组,所述列下标数组用于表示非零元素的列数,所述行指针数组用于表示该行的起始非零元素在列下标数组中的位置,所述非零数值数组表示所述系数矩阵中的非零元素。
优选地,使用一组公共行指针和列下标数组来存储所有并行线程中的系数矩阵的所述行指针数组和所述列下标数组。
优选地,采用预条件稳定双共轭梯度法求解每个并行线程的三维大地电磁正演方程组。
优选地,对于每个并行线程,需要的所述存储空间包括临时向量的内存需求、系数矩阵的内存需求和系数矩阵的预条件分解阵的内存需求。
优选地,所述系数矩阵的内存需求字节数为:ma=(n+1+nnz_a)*sizeof(int)+nnz_a*sizeof(double)*2,所述系数矩阵的预条件分解阵的内存需求字节数为:mp=(n+1+nnz_p)*sizeof(int)+nnz_p*sizeof(double)*2,所述临时向量的内存需求字节数为:mv=9*n*sizeof(double)*2,其中,n表示系数矩阵的行数,nnz_a表示系数矩阵的非0元素个数,nnz_p表示预条件分解阵的非0元素个数,sizeof(int)表示整形变量需要的字节数,sizeof(double)表示双精度浮点型变量需要的字节数。
优选地,所述gpu最大并行线程数为:ng=0.8*mg/m,ng表述gpu最大并行线程数,mg表示gpu支持的最大全局内存大小,m=ma+mp+mv表示gpu单线程所需的存储空间大小。
与现有技术相比,本发明的优点在于:充分利用基于gpu+cpu的异构平台的硬件资源,使用gpu参与三维大地电磁反演的并行计算;针对三维大地电磁方程组系数的特点,通过尽量压缩内存需求的方式,提高gpu可支持的并行线程数,从而增加了gpu并行计算的适应场景。
附图说明
以下附图仅对本发明作示意性的说明和解释,并不用于限定本发明的范围,其中:
图1示出了根据本发明实施例的基于gpu+cpu异构平台的三维大地电磁反演并行方法的流程图。
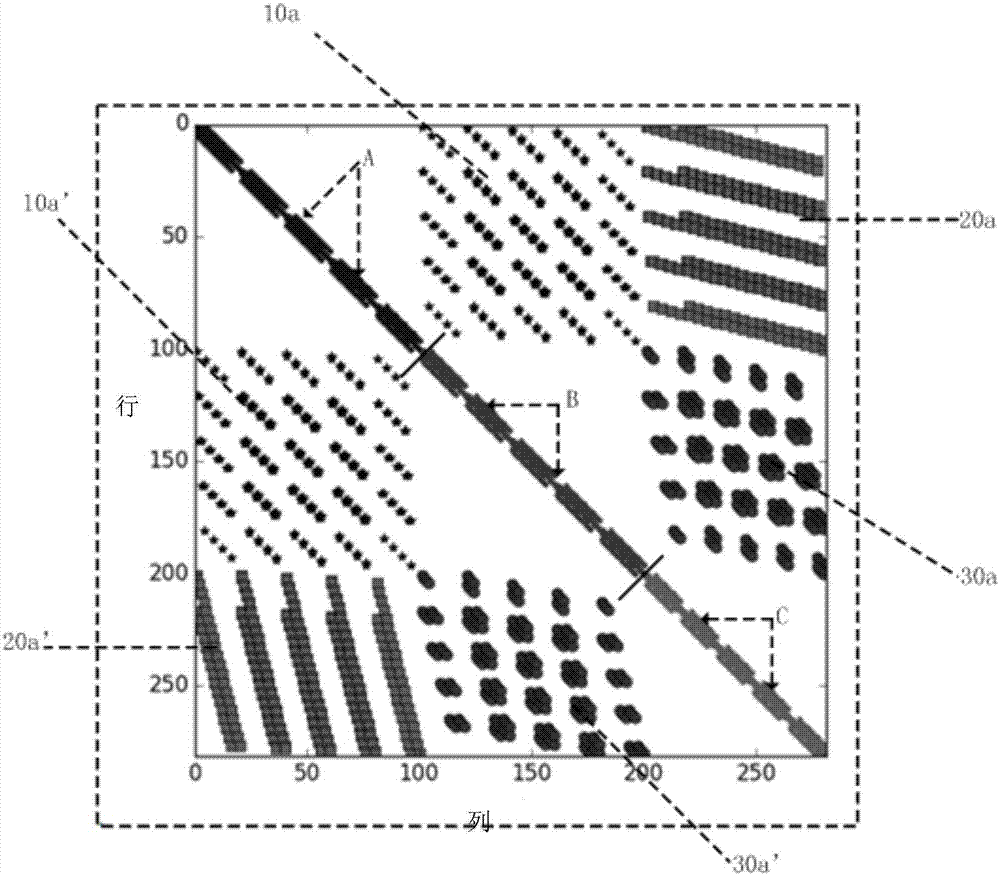
图2示出了典型三维mt有限差分正演系数矩阵的稀疏模式示意图。
图3示出了稀疏矩阵csr三元组压缩存储格式示意图。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对本发明提出的基于gpu+cpu异构平台的三维大地电磁反演并行方法作进一步说明。
本发明的并行计算方案实施步骤为:获得三维大地电磁的正演矩阵方程组;获取本机gpu支持的最大并行线程数ng;获取cpu的最大并行线程数nc;在一组待分配的并行求解正演方程组的任务中,优先分配ng个gpu任务,并分配nc个cpu任务。
现参照图1,结合本发明的一个实施例描述具体步骤,需要说明的是,说明书中描述的该方法的各个步骤并非一定是必须的,而是可以根据实际情形省略或替换其中的一个或多个步骤。
第一步:获取正演矩阵方程组
首先,根据大地电磁反演的剖分和单元电阻率值形成初始正演矩阵方程组,典型地,初始正演矩阵方程组的形式为:
其中,ex、ey和ez分别表示求解向量的子向量,bx、by和bz分别是各方向电场对应的右端项子向量。axx、byy和czz分别为麦克斯韦方程电场二阶旋度三分量展开的系数子矩阵,除主对角元素外,其它所有元素均和频率及单元电导率无关。
在线性方程组(1)中,axy=byx、axz=czx、byz=czy,并且axx、byy和czz都是对称子矩阵,可将其简写为:
其中,axx=axx,ayy=byy,azz=czz;axy=axy,axz=axz;ayz=byz,省略号表示对称,xx=ex,xy=ey,xz=ez为求解向量。且axx、ayy和azz均为对称子矩阵。
第二步:采用压缩稀疏矩阵存储形式表示初始矩阵。
方程组(2)是大量元素为零的稀疏系统,具有典型的稀疏模式,图2示出了典型三维mt有限差分正演系数矩阵的稀疏结构(5×5×5,表示反演网格的x,y,z三个方向的网格剖分数目,也就是说网格有5*5*5=125个网格单元),其中,a、b、c像素点分别表示axx,ayy,azz,10a和10a’表示axy和ayx,20a和20a’表示axz和azx,30a和13a’表示ayz和azy。
在三维有限差分正演方程组中,系数矩阵每行最多有13个非零元素,为了节省内存空间和避免零元素的冗余运算,可考虑使用压缩存储方式。
在此实施例中,采用按行压缩的csr(compressedsparserow)压缩格式。csr是一种三元组压缩方式,使用列下标(colinds)、行指针(rowptrs)和非零值(values)三个向量来存储整个矩阵,其中,列下标colinds表示非零元素所位于的列数;行指针rowptrs表示该行从列下标中的哪个元素开始。行指针rowptrs中的最后一个元素是列下标中最后一个元素的编号,行指针rowptrs中的其他元素每个代表一行。如图3所示,对于最右侧的稀疏矩阵
例如,在一个实际应用的示例中,采用以下的c++代码实现按行存储的csr格式。
第三步:计算求解方程组所需的存储空间。
方程组(2)的求解方法有多种,例如,krylov子空间迭代法等、以多波前(multifrontalmethod)技术为代表的直接法。在此实施例中,为了适应小内存场景,可采用krylov子空间迭代法中的预条件稳定双共轭梯度法(bicgstab)。该方法的收敛速度与预条件阵p的选择有关,每次迭代中近似快速求解pp=r,其中,p表示构建的预条件矩阵,p表示预条件系统的快速近似解,r表示预条件系统的右端项。
在本文中,使用公式(2)的系数矩阵的带状对称部分来构建预条件,令:
为了便于理解,下面列出了bicgstab算法的伪代码。在下述步骤中r0是初始残差向量,b是右端项,a是系数矩阵,x0是初始解,
//bicgstab算法的伪代码
step1:r0=b-ax0
step2:选择任意向量
step3:设定系数:ρ0=α=ω0=1
step4:设定向量:v0=0,p0=0
step5:循环k=0,1,…:
5.1
5.2β=(ρk+1/ρk)(α/ωk)
5.3pk+1=rk+β·(pk-ωkvk)
5.4快速求解py=pk+1,vk+1=ay(y为中间向量)
5.5
5.6s=rk-αvk+1(s为中间向量)
5.7快速求解pz=s,t=az(z、t为中间向量)
5.8快速求解prk+1=t
5.9
5.10xk+1=xk+α·y+ωk+1z
5.11rk+1=s-ωk+1·t
5.12如果
//bicgstab算法的伪代码
其中,p是稀疏对称hermitian矩阵,快速求解pp=r需要对p进行不完全分解,在本发明中,可以采用不带填充的不完全lu分解和不完全cholesky分解两种方式,它们各有优点,使用不完全lu分解避免了根号操作,但需要存储分解后的下三角和上三角两个矩阵;不完全cholesky分解只需要存储分解后的上三角(由于p对称),但分解过程的根号操作可能导致数值计算错误。为了适应gpu的小内存场景,优选地,采用易于编程实现、内存需求最小、分解快的不完全cholesky分解法。
在上述bicgstab迭代流程中,输入数据为按照csr压缩存储的稀疏系数矩阵a,预条件的不完全cholesky分解阵p,未知数向量x,右端项b。
在三维大地电磁有限差分正演中,假设x、y、z三个方向的单元格数目分别为nx、ny和nz,这三个方向的单元格数是反演之前由用户设定的,一般和测点分布有关,则系数矩阵的行数n可以按如下的公式计算:
n=nx*(ny-1)*(nz-1)+(nx-1)*ny*(nz-1)+(nx-1)*(ny-1)*nz
预条件矩阵的不完全cholesky分解阵的非0元个数nnz_p为:
nnz_p=n+nx*(ny-1)*(nz-2)+nx*(ny-2)*(nz-1)+(nx-1)*ny*(nz-2)+(nx-2)*ny*(nz-1)+(nx-2)*(ny-1)*nz+(nx-1)*(ny-2)*nz。
系数矩阵的非0元个数nnz_a为:
nnz_a=nnz_p+8*(nx-1)*(ny-1)*(nz-1)+4*(nx-1)*(ny-1)*(nz-1)。
综上所述,只要通过三个方向的单元个数nx、ny、nz即可求得系数矩阵的行数n、预条件矩阵的分解阵的非0元个数nnz_p、以及系数矩阵的非0元个数nnz_a。
在一个gpu线程中在gpu上开辟的内存空间包括稀疏矩阵需要的存储空间和计算过程中向量所需的存储空间。在此实施例的bicgstab算法中,x、b、r、r_tld、p、p_hat、s、s_hat、v、h这10个向量中b向量和r向量在算法中可以合并,因此向量内存需求的字节数为mv=9*n*sizeof(double)*2。
其中,所有向量和矩阵的参数均是双精度复数类型,双精度复数类型在c/c++语言系统下的字节数为sizeof(double)*2,即实部和虚部均为double型;9是求解方程的算法中涉及到合并之后的向量个数。
而稀疏矩阵的内存需求分两个部分,整形的下标数组和非0元素数组的大小,系数矩阵a的内存需求字节数ma为:
ma=(n+1+nnz_a)*sizeof(int)+nnz_a*sizeof(double)*2
预条件矩阵的分解阵的内存需求字节数mp为:
mp=(n+1+nnz_p)*sizeof(int)+nnz_p*sizeof(double)*2
从而单一gpu线程的一个频率的三维大地电磁有限差分正演的bicgstab迭代求解的总内存需求包括计算向量的内存需求、系数矩阵的内存需求和预条件矩阵的分解阵的内存需求三者之和,即单线程的总内存需求m=mv+ma+mp个字节。
本领域的技术人员应当理解,尽管上述以预条件稳定双共轭梯度法(bicgstab)为例,介绍了计算求解方程组的所需存储空间的方法,但是也可以利用本发明的原理采用其它的算法或矩阵分解方法来获得存储空间的大小。
第四步:分配gpu并行线程数和cpu的并行线程数。
为了实现并行计算,在此步骤中需要分配执行方程组求解的gpu并行线程数和cpu的并行线程数。
根据本发明的一个实施例,获得gpu线程数的方法是,对于nvidia公司的显卡gpu设备,其提供的cuda并行计算库提供了底层的api函数获取gpu设备的内存情况。假定计算机有两个gpu显卡,首先使用cudagetdevicecount(&ngpu)函数即可得到当前支持cuda并行的gpu设备个数为2,编号分别为0和1。本发明的计算方案在分配任务时优先分配gpu线程,所以在一个外部openmpi循环中,首先会查看0号gpu的情况,然后是1号gpu,以此类推。也可以首先分配gpu1的线程,本发明对gpu之间的并行线程分配顺序不作限制。
以0号gpu为例,首先,需要调用cudagetdeviceproperties(&prop,0)来获取0号gpu的属性prop,prop是一个cuda属性结构体,0号gpu支持的最大全局内存数目mg为prop.totalglobalmem,从而0号gpu的最大线程数ng0=0.8*mg/m(为了不超过显存空间,可向下取整),其中m为之前获得的单线程所需的总存储空间,这种分配方式给gpu留下了20%的空余空间,以用于cuda计算库的高级向量操作函数的扩展内存需求。在其他实施例中,也可以根据其他操作对内存的需求情况,预留多于或少于20%的空余空间。
根据本发明的一个实施例,获得cpu最大线程数nc的方法是,可以使用openmp协议的nc=omp_get_max_threads()函数,在默认情况下得到当前多核计算机的并行虚拟内存数,cpu线程数若大于这个数目则加速比会下降。该函数为openmp标准函数,其得到的是计算机能支持并行的最大虚拟线程数,nc表示在没有gpu设备的情况下,只用cpu进行密集型计算的最佳并行线程数。在cpu+gpu异构计算机上,由于gpu线程的密集计算在显卡上执行,还可以在nc个密集计算线程的基础上,增加ng个线程用于gpu并行计算的数据拷贝等空闲时间较多的线程,这ng个线程即gpu线程。
因此,基于本发明的方法,一个外部openmp循环需要分配nc个cpu线程和ng0+ng1+…个gpu线程,假设50*50*50的大地电磁问题,在单4g显存gpu、4核8线程计算机上,同时参与计算的线程数目为8个低速cpu线程和2个高速gpu线程。
上述分配方式中,存在的一个问题是,在求解问题规模太大的情况下,如果gpu显存不够,此时gpu的1个线程在求解方程时会反复的释放、申请、拷贝内存,从而降低gpu显存的计算速度,有可能整体加速比还不如纯cpu并行。因此,在一个实施例中,若mg*80%<m,则完全禁止gpu,仅分配用cpu来做并行计算。但应说明的是,对于大规模计算问题,并行的最佳方案是高成本的并行计算机集群而不是单机。
应理解的是,基于本发明的方法,在分配任务时,一次并行总任务数为ng+nc个,由于每个任务不是同时执行完毕的,假设某时刻已经空出了一个计算资源,此时需要给其分配新的计算任务,此新任务应优先分配给gpu,如果ng个gpu都不空闲,则分配给cpu,整个并行计算中,所有gpu和cpu计算资源均是无空闲的满负荷运作,它们所有的线程均是同时执行的。
上述根据图1的实施例重点描述了分配gpu和cpu线程数的方法以及系数矩阵的压缩存储方式。然而,对于基于gpu和cpu的异构并行计算而言,由于gpu内存有限,目前市场上最大的只有8g,一个大型大地电磁反演网格的串行求解线程可能需要4g左右的内存,需要进一步考虑大型复线性方程组的压缩存储问题。
在一个实施例中,基于大地电磁的不同的求解线程矩阵虽然不同,但稀疏规律一样,使用一组行、列向量来表示所有矩阵的稀疏模式。例如,若有40个频率的大地电磁数据,系数矩阵有40个,每个矩阵的稀疏压缩存储需要rowptrs,colinds,vals三个数组表示,传统方式需要存40个这样的三个数组。而在本发明中,为了进一步降低内存需求,考虑到rowptrs,colinds这两个数组(大型致密)对于40个频率都是一样的,因此,只需存储一组rowptrs,colinds行列指针向量,和40个vals矩阵的非0元素向量,通过这种方式可以节省39*2个大型致密数组的存储空间。
具体如下:
若一个线性方程组的伪代码示意性表示为:
在传统方式的多个线程中,所有的稀疏矩阵在并行计算时内存表示为:
为了避免稀疏属性的行指针和列向量在同一并行架构内存中的重复内容,在本发明中,采用的新表示法为:
因此,通过这种方式,一方面压缩了内存,另一方面减少了gpu并行计算中的内存拷贝操作。对于每个计算线程而言,系数矩阵a和预条件分解矩阵p的下标向量都是一样的,如果每个线程都要申请单独的下标向量就会浪费了不少内存。例如,假定现在有40个频率,矩阵的规模为n行,a和p矩阵的非0元素为nnz_a和nnz_p个,那么完全可以用1下标数组结构体代替另外需要分配的40个,需要的下标结构体为4个整型数组,rowptra、colinda、rowptrp、colindp,一个gpu线程需要的显存大小ms为:
ms=(n+n+nnz_a+nnz_p)*sizeof(int)
而采用公用的下标结构体节省了39*ms的内存需求(假定40个线程同时并行),对于网格规模为100*100*100的问题来说,至少节省了4g的内存空间的申请、释放和拷贝工作,提速将非常明显。
总之,相对于现有技术,本发明的方案能够在现有的主流高配计算机上接近并行机的三维大地电磁反演计算速度,能够有效的提高计算速度并降低成本。
例如,以三维大地电磁反演的典型问题规模为例,假设需要反演40个频率、网格规模为50*50*50的数据,此时一个正演问题需要求解80个大型线性方程组,单核计算每个方程组时间为一个单位时间,内存需求为1g。假定计算机为4核8线程,gpu显存8g。计算机价格大约10000元左右。纯单机cpu并行(现有技术方案一)的加速比大致为4,那么一次正演需要20个单位时间。在不考虑数据网络传输成本的情况下,10个4核8线程节点并行机的一次正演需要2个单位时间。但并行计算机+机房+维护人员成本估计100万元左右。
而采用本发明的方法,gpu上可以并行执行8个线程,加速比最保守的估计为16(gpu线性代数库最低比串行快两倍),总体加速比为20,执行一次正演需要4个单位时间。不增加任何成本。
本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。
计算机可读存储介质可以是保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以包括但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、静态随机存取存储器(sram)、便携式压缩盘只读存储器(cd-rom)、数字多功能盘(dvd)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
- 还没有人留言评论。精彩留言会获得点赞!