基于差分进化算法的分数阶希尔伯特变换阶次优化方法与流程
本发明涉及信号分析处理技术领域,特别是涉及一种基于差分进化算法的分数阶希尔伯特变换阶次优化方法。
背景技术:
希尔伯特变换在信号处理中是重要的分析方法,通常用于瞬时参数的计算和窄带信号的表示。它将一个实信号变换为对应的解析信号,使信号只包含正频率部分,从而降低信号的采样率。希尔伯特变换定义为幅度相等、相移±90°的空间滤波器,对输入信号进行希尔伯特变换可有效地提取其包络,然后对包络信号进行频域分析则可以获得特征频率。
分数阶希尔伯特变换(fht)定义为不同分数阶次(-2~2)下幅度相等、相移-90°~90°的改良型空间滤波器,利用较优阶次对信号进行分数阶希尔伯特变换包络分析,可以获得更显著的特征频率。而分数阶希尔伯特变换的阶次优化性成为信号分析时评估特征频率显著性的主要依据。在信号分析处理技术的发展中,对信号特征频率显著性的要求越来越高,因此信号进行包络分析时对分数阶希尔伯特变换的阶次的优化性提出了比较苛刻的要求。
如图1所示,分数阶希尔伯特变换阶次优化的传统方法的基本思想是,设置步进精度使阶次从-2至2等间隔改变,然后信号分析对比后得到优化后的阶次。步进精度即间隔为a,取值范围为-2~2,a值越小精度越高,最终阶次的误差则越小。信号分析方法的步骤为先在当前阶次p下进行信号fht,然后对信号包络进行峭度(k)计算,峭度最大的阶次为最终阶次。
假设设置步进间隔a=0.01,首先读取输入的信号数据并初始化当前阶次p=0和目前最终阶次pm=0。然后进入for循环在当前阶次p下进行信号fht和峭度分析,若当前阶次p比目前最终阶次pm更好,则令pm=p;否则跳过此步骤使当前阶次p加一步进间隔a,进入下一阶次的循环中。若阶次溢出即p大于1则完成优化结束程序,pm为获得的fht的优化后的阶次。最后利用最终阶次pm对振动信号进行分数阶希尔伯特变换和包络分析得到特征频率。
传统分数阶希尔伯特变换阶次优化方法,程序的运行时间取决于阶次精度的设置,寻求阶次的更优是以牺牲运行时间为代价的。造成这种现象的原因,是程序利用for循环将步进精度范围内的每一个阶次全部遍历一遍,这样步进精度设置的越高(a越小),for循环的次数越多,阶次优化的时间则越长。并且步进精度每高一个数量级时,程序的运行时间也会相应的高出一个数量级。如想得到10-6精度的优化阶次,则需要进行106次的计算。
技术实现要素:
本发明针对现有分数阶希尔伯特变换阶次优化方法的程序运行时间长、效率低的技术问题,提供一种程序运行时间短、效率高的基于差分进化算法的分数阶希尔伯特变换阶次优化方法。
为此,本发明提供一种基于差分进化算法的分数阶希尔伯特变换阶次优化方法,包括以下步骤:
步骤1,读取需要处理的信号数据,存入待处理的寄存器中,选择需要优化的阶次参数,设置优化的收敛精度,即允许的最大误差;
步骤2,使用差分进化算法,设置合适的算法参数和迭代次数,初始化种群,循环进行变异操作、交叉操作、峭度分析和选择操作来优化分数阶阶次,直到满足设置的收敛精度或达到最大迭代次数;
步骤3,对信号进行频域分析处理,使用优化后的阶次对信号进行分数阶希尔伯特变换,得到变换后的包络信号,对包络信号进行快速傅里叶变换,得到优化后的频谱信号和特征频率。
优选地,步骤2中初始化种群是在变量允许范围内随机生成,其表达式如下:
其中,rand()是0至1范围内的随机数,
xg=xi,g={xi1,g,xi2,g,…,xidim,g}(1)
其中,i=1,2,…,np,g=1,2,…,gm;gm代表最大进化数。
优选地,步骤2中差分变异操作的表达式如下:
vi,g+1=xr1,g+f×(xr2,g-xr3,g)(3)
其中r1,r2,r3∈[1,np],是随机抽取的整数,且满足i≠r1≠r2≠r3,vi,g+1表示变异矢量,f是变异算子。
优选地,步骤2中交叉操作表达式如下:
其中,
优选地,在当前优化过程的阶次下,对信号进行分数阶希尔伯特变换得到包络信号,然后利用快速傅里叶变换对包络信号进行频域分析,之后对变换得到的频域信号进行步骤2中的峭度分析计算,其表达式如下:
其中,
优选地,步骤2中选择操作的表达式如下:
其中,
优选地,为保证
本发明的有益效果是,利用差分进化算法,通过变异操作、交叉操作、峭度分析和选择操作来优化分数阶阶次,计算300次左右即可达到10-6精度,相比于传统方法的106次运算,算法处理速度明显提升,能够高效率地完成分数阶希尔伯特变换的阶次优化,同时具有良好的精度和高鲁棒性。
附图说明
图1是传统分数阶希尔伯特变换阶次优化方法流程图;
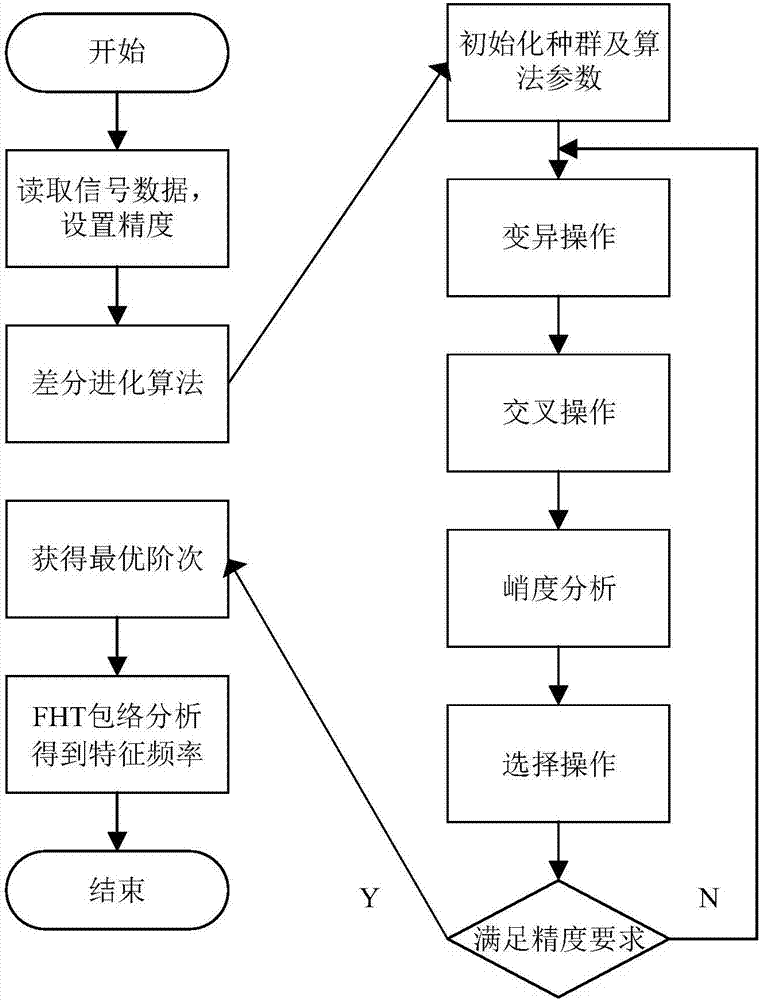
图2是基于差分进化算法的分数阶希尔伯特变换阶次优化方法流程图。
具体实施方式
下面结合实施例对本发明做进一步描述。
如图2所示,本发明一种基于差分进化算法的分数阶希尔伯特变换阶次优化方法,具体步骤如下:
步骤1,读取需要处理的信号数据,存入待处理的寄存器中。选择需要优化的阶次参数,设置优化的收敛精度,即允许的最大误差。
步骤2,使用差分进化算法(de),设置合适的算法参数和迭代次数,初始化种群,循环进行变异操作、交叉操作、峭度分析和选择操作来优化分数阶阶次,直到满足设置的收敛精度或达到最大迭代次数。其中,具体包括以下步骤:
(1)初始化种群:种群中的每一个个体代表问题的一个解。第g代种群包含np数量的个体,每个个体有dim维。其表达式如下:
xg=xi,g={xi1,g,xi2,g,…,xidim,g}(1)
其中,i=1,2,…,np,g=1,2,…,gm,gm代表最大进化数。
初始种群是在变量允许范围内随机生成,表达式如下:
其中,rand()是0至1范围内的随机数,
(2)差分变异操作。差分进化算法采用差分策略产生变异个体,采用二项交叉模式,从上一代种群中随机选择3个个体xi1,xi2,xi3,i≠r1≠r2≠r3,将其中两个个体向量差缩放后与待变异个体进行向量合成,表达式如下:
vi,g+1=xr1,g+f×(xr2,g-xr3,g)(3)
其中,r1,r2,r3∈[1,np],是随机抽取的整数,满足i≠r1≠r2≠r3,vi,g+1表示变异矢量,f是变异算子,它对差分矢量进行缩放,从而控制搜索步长。
(3)交叉操作:交叉算子把通过变异操作得到的变异矢量vi,g+1与个体目标矢量
其中,
为保证
(4)峭度分析:在当前优化过程的阶次下,对信号进行分数阶希尔伯特变换得到包络信号,然后利用快速傅里叶变换对包络信号进行频域分析,然后对变换得到的频域信号进行峭度(k)计算,其表达式如下:
其中,
(5)选择操作:在经过峭度分析得到当前向量的峭度之后,选择操作采用贪婪筛选算子,以峭度为标准,将当前向量和目标向量进行比较,较优者保存到下一代,贪婪筛选算子表达式如下:
其中,
基于de的方法,计算300次左右即可达到10-6精度,相比于传统方法的106次运算,算法处理速度明显提升。
步骤3,对信号进行频域分析处理,使用优化后的阶次对信号进行分数阶希尔伯特变换,得到变换后的包络信号,对包络信号进行快速傅里叶变换(fft),得到优化后的频谱信号和特征频率。
利用差分进化算法,通过变异操作、交叉操作、峭度分析和选择操作来优化分数阶阶次,计算速度快并且保持了良好的精度,解决了传统方法以牺牲运行时间为代价来获得更优阶次的缺点。采用该方法,能够高效率地完成分数阶希尔伯特变换的阶次优化,同时具有良好的精度和高鲁棒性。
惟以上者,仅为本发明的具体实施例而已,当不能以此限定本发明实施的范围,故其等同组件的置换,或依本发明专利保护范围所作的等同变化与修改,皆应仍属本发明权利要求书涵盖之范畴。
- 还没有人留言评论。精彩留言会获得点赞!