一种基于强化学习的小脑模型建模方法与流程
本发明渉及一种基于强化学习的小脑模型建模方法,属于神经工程与生物信息系统建模技术领域。
背景技术:
人的小脑位于大脑半球后方,覆盖在脑桥及延髓之上,横跨在中脑和延髓之间,具有协调运动的功能。在协调运动过程中,小脑不仅会接收大脑皮层的运动命令并传递给脊髓肌肉系统,同时也会接收本体感受器的反馈信息,对部分运动命令进行实时的调整。凭借这种功能机理,哺乳动物能够实现对躯体以及四肢快速、稳定、准确地控制,其理想的控制效果一直是各种控制方法所追求的目标。因此,对于控制学领域而言,深入了解小脑的解剖学和生理学特性,探索其功能机理,并以此为基础建立小脑模型,无疑会为控制理论的发展提供新的思路。另一方面,小脑性共济失调因其病变部位和诱因的不同而种类繁多,对其的诊断与治疗一直是临床上的一大难题。建立小脑模型,在模型的基础上建立小脑性共济失调的表征,可以为临床提供新的参考,所得的结果也具有普适性和可移植性,在医学领域具有重大的价值。
基于以上目的,多年来医学与控制学相关领域的众多学者进行了相关的探索,建立了多种小脑模型,如albus依据小脑皮层不同分区具有不同功能的特性及小脑所具有的学习功能,提出了小脑关联控制器模型;kawato将小脑比作一种可模拟运动器官输入输出特性的系统,提出了小脑内部模型等。现有的建模方法主要集中在对健康小脑的功能表达方面,通常用以实现机器人系统或简单手臂的协调运动控制。这样的建模方法主要关心的是系统的可行性,实现的复杂程度和控制的效果等因素,因而在建模时会对小脑内部结构进行大量的简化甚至会忽略其内部生理学信息。此外,现有小脑模型的学习过程通常采用监督学习方式,认为攀爬纤维传递具有指导性的误差信号,与其放电的“全”或“无”特性不符。针对以上问题,需要从小脑解剖学和生理学角度出发,利用控制学相关原理,从微观结构与机制的角度,模拟和复制其功能,建立能够表达其自身特性的小脑模型。
技术实现要素:
为了克服现有技术存在的不足,本发明目的是提供一种基于强化学习的小脑模型建模方法。本发明利用神经网络等相关控制方法,在神经元层次上对小脑的结构以及功能等进行表达以体现小脑的自身特性,同时,采用基于强化学习机制的学习过程比较符合攀爬纤维的放电特性,从而使建立的小脑模型更具有生物合理性。
为了实现上述发明目的,解决已有技术中所存在的问题,本发明采取的技术方案是:一种基于强化学习的小脑模型建模方法,包括以下步骤:
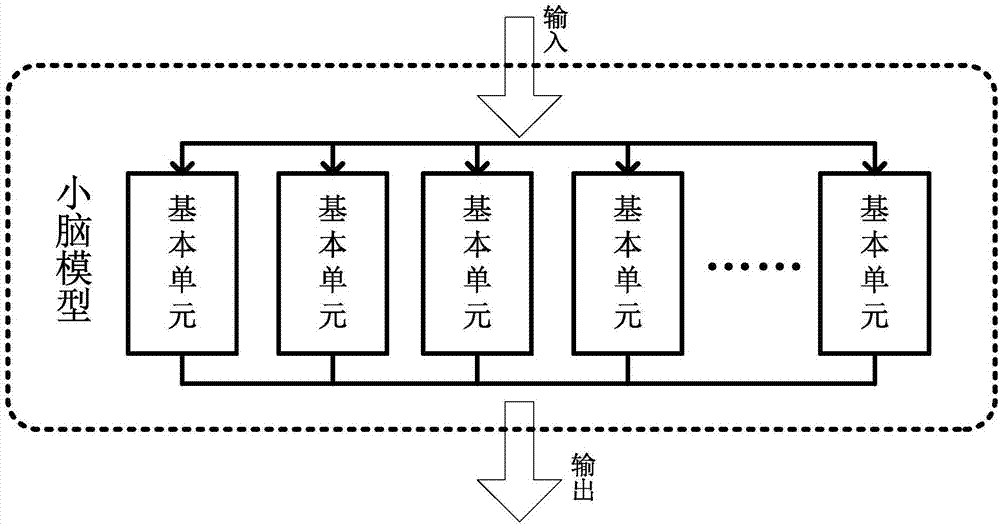
步骤a、建立小脑模型的基本结构,基于小脑皮层的匀质结构特性,使用具有相同结构的p个基本单元的阵列来建立小脑模型的总体结构,p表示基本单元的数量,每个基本单元接收相同的输入信息,随后进入步骤b;
步骤b、根据效应器的状态信息,计算各个基本单元中平行纤维的状态,具体包括以下子步骤:
子步骤b1、将效应器的状态空间进行均匀划分,划分的数量与每个基本单元中平行纤维的数量m相同,每条平行纤维对应一个状态空间区域;
子步骤b2、根据效应器所处的状态,确定第k个基本单元中的平行纤维的状态值xki,其值具有二值性,用“0”表示抑制状态,“1”表示激活状态,当效应器的状态位于第i条平行纤维对应的状态空间区域时,则xki赋值为1,其中,k=1,2,…p,i=1,2,…m,i表示第i条平行纤维,然后进入步骤c;
步骤c、计算各个基本单元的输出命令,从而得到小脑模块输出命令,具体包括以下子步骤:
子步骤c1、计算第k个基本单元的网状结构输出,此基本单元中各个浦肯野细胞的状态值为ykj,其值随时间改变,j=1,2,…n,n表示浦肯野细胞数目,具体包括以下子步骤:
子步骤c11、利用公式(1)计算第k个基本单元中第j个浦肯野细胞在t时刻的膜电位值qkj(t),
式中,wkij表示第i条平行纤维与第j个浦肯野细胞形成的突触的记忆权值,由于该类突触为小脑学习记忆的载体,因此wkij设为可调,其初始值设为1,小脑模块的输出通过调整其值大小来改变;
子步骤c12、浦肯野细胞的状态具有二值性,用“0”表示抑制状态,“1”表示激活状态,结合子步骤c11计算得到的qkj(t),利用公式(2)、(3)计算在t时刻时第k个基本单元中第j个浦肯野细胞的状态值,
对于初始时刻,t=1时,
当t>1时,ykj(t)还与上一时刻ykj(t-1)的值相关,赋值方法为,
式中,φ、η分别为浦肯野细胞膜电位的去极化和复极化的阈值,为固定常数,且φ>η,设定φ=1,η=0.8;
子步骤c2、根据反馈环路loop状态与基本单元中的浦肯野细胞的状态,计算各个基本单元输出,loop具有两种状态,即on与off状态,二者转化的条件为:当小脑模块开始执行命令输出时,loop由off转变为on状态;而当基本单元中的所有的pc都处于激活状态时,loop由on转变为off状态,根据loop不同状态,利用公式(4)计算第k个基本单元的输出命令ok(t),
式中,γ表示命令调整系数,设为常数,则在t时刻小脑模块的输出命令为o(t)=[o1(t),o2(t),…op(t)],若o(t)为零向量,则执行步骤d,即完成一次小脑模块命令的输出,否则执行子步骤c3;
子步骤c3、根据权值调整公式,计算当前小脑模块记忆信息对应的控制命令输出,具体包括以下子步骤:
子步骤c31、根据权值调整公式(5),调整第k个基本单元在t+1时刻的平行纤维和浦肯野细胞形成的突触记忆权值wkij(t+1)的大小,
式中,λ为调整系数,设为常数,δwkij(t)为在t时刻时平行纤维和浦肯野细胞形成的突触记忆权值的变化量,wkij(t)表示在t时刻平行纤维和浦肯野细胞形成的突触记忆权值;
子步骤c32、根据t时刻的小脑模块输出命令o(t)和小脑命令到效应器运动控制命令的映射关系f,利用公式(6)计算t+1时刻效应器的状态,
式中,δm(t)表示t时刻小脑命令控制效应器运动而产生的状态的调整值,m(t)表示t时刻效应器的状态,m(t+1)表示t+1时刻效应器的状态,随后再次执行子步骤b2;
步骤d、执行小脑模块学习功能,通过调整小脑模块的记忆权值,进而改变小脑模块的命令输出,若小脑模块首次进入学习过程,则执行子步骤d1,否则,执行子步骤d2;
子步骤d1、设定基于强化学习机制的小脑模型的相关要素的初始值,具体包括以下子步骤:
子步骤d11、设定所有平行纤维的状态值函数v的初始值均为1,其中,当平行纤维所处的状态为s时,其值函数可表示为vs;
子步骤d12、制定初始条件下,行为选择的策略为π(a),其具体内容为:在不同状态下,选择各个行为a的概率相同;其中,行为a表示选择一个基本单元激活,同时,每个基本单元激活都产生一个模值相同的基本单元输出命令ok';
子步骤d2、计算效应器的状态与期望值的误差,若在预先设定的允许范围之内,则建模完成,否则执行子步骤d3;
子步骤d3、判定对应基本单元的攀爬纤维的状态,具体包括以下子步骤:
子步骤d31、根据步骤b,确定在t时刻各个基本单元中平行纤维的状态s(t),并计算状态值函数vs(t);
子步骤d32、根据当前策略π(a),选择t时刻的行为a(t),并得到小脑模块的输出命令o',其中,o'=[0,0,…,ok',0,…],根据公式(6),可得到效应器的状态信息,再次根据步骤b,确定在t+1时刻各个基本单元中平行纤维的状态s(t+1),并计算状态值函数vs(t+1);同时,根据公式(7)计算环境反馈的奖惩值,
式中,r(t+1)表示在t+1时刻的奖惩值;
子步骤d33、根据公式(8)计算在t时刻的td误差δ(t),
δ(t)=r(t+1)+vs(t)-vs(t+1)(8)
子步骤d34、根据公式(9)修改行为选择策略,
式中,pr(s,a)表示在状态s下,选择行为a的倾向性,β为常值系数;
子步骤d35、根据公式(10)确定对应基本单元的攀爬纤维的状态,
式中,ck表示激活对应基本单元的攀爬纤维状态值;
子步骤d4、根据公式(11),对小脑模块第k个基本单元中的每个pf-pc初始权值wkij(1)进行调整,
wkij(1)=wkij(1)-σ·ck·xkj·ekj(τ)(11)
式中,σ表示学习系数,τ为信号在神经通路上传导的时延,ekj(t)为第k个基本单元中的第j个pf所对应的资格迹,可通过下式进行描述,
子步骤d5、若vs(t+1)≥vs(t),则执行子步骤d2,否则,将效应器恢复到初始状态,将t重置为1,执行子步骤b2。
本发明有益效果是:一种基于强化学习的小脑模型建模方法,包括以下步骤:(1)建立小脑模型的基本结构,(2)根据效应器的状态信息,计算各个基本单元中的平行纤维状态,(3)计算各个基本单元的输出,从而得到小脑模块输出命令,(4)执行小脑模块学习功能。与已有技术相比,本发明以小脑自身的解剖学与生理学特性为出发点,在神经元水平上模拟、复制小脑的神经系统的结构与功能,解决了现有的许多小脑建模方法追求控制效果而忽略小脑本身特性的弊端。同时,将强化学习方法作为小脑学习过程所采取的机制能够很好地体现小脑学习过程中攀爬纤维放电的“全”或“无”的特点,使建立的小脑模型更具有生物的合理性。
附图说明
图1是本发明方法步骤流程图。
图2是本发明方法的小脑模型结构框图。
图3是本发明方法的小脑模型中的基本单元结构图。
图4是本发明方法的小脑模型控制效应器运动总体框图。
具体实施方式
下面结合附图对本发明作进一步说明。
如图1所示,一种基于强化学习的小脑模型建模方法,包括以下步骤:
步骤a、建立小脑模型的基本结构,如图2所示,基于小脑皮层的匀质结构特性,使用具有相同结构的p个基本单元的阵列来建立小脑模型的总体结构,p表示基本单元的数量,每个基本单元接收相同的输入信息,如图3所示,随后进入步骤b;
步骤b、根据效应器的状态信息,计算各个基本单元中平行纤维的状态,具体包括以下子步骤:
子步骤b1、将效应器的状态空间进行均匀划分,划分的数量与每个基本单元中平行纤维的数量m相同,每条平行纤维对应一个状态空间区域;
子步骤b2、根据效应器所处的状态,确定第k个基本单元中的平行纤维的状态值xki,其值具有二值性,用“0”表示抑制状态,“1”表示激活状态,当效应器的状态位于第i条平行纤维对应的状态空间区域时,则xki赋值为1,其中,k=1,2,…p,i=1,2,…m,i表示第i条平行纤维,然后进入步骤c;
步骤c、计算各个基本单元的输出命令,从而得到小脑模块输出命令,具体包括以下子步骤:
子步骤c1、计算第k个基本单元的网状结构输出,此基本单元中各个浦肯野细胞的状态值为ykj,其值随时间改变,j=1,2,…n,n表示浦肯野细胞数目,具体包括以下子步骤:
子步骤c11、利用公式(1)计算第k个基本单元中第j个浦肯野细胞在t时刻的膜电位值qkj(t),
式中,wkij表示第i条平行纤维与第j个浦肯野细胞形成的突触的记忆权值,由于该类突触为小脑学习记忆的载体,因此wkij设为可调,其初始值设为1,小脑模块的输出通过调整其值大小来改变;
子步骤c12、浦肯野细胞的状态具有二值性,用“0”表示抑制状态,“1”表示激活状态,结合子步骤c11计算得到的qkj(t),利用公式(2)、(3)计算在t时刻时第k个基本单元中第j个浦肯野细胞的状态值,
对于初始时刻,t=1时,
当t>1时,ykj(t)还与上一时刻ykj(t-1)的值相关,赋值方法为,
式中,φ、η分别为浦肯野细胞膜电位的去极化和复极化的阈值,为固定常数,且φ>η,设定φ=1,η=0.8;
子步骤c2、根据反馈环路(loop)状态与基本单元中的浦肯野细胞的状态,计算各个基本单元输出,loop具有两种状态,即on与off状态,二者转化的条件为:当小脑模块开始执行命令输出时,loop由off转变为on状态;而当基本单元中的所有的pc都处于激活状态时,loop由on转变为off状态,根据loop不同状态,利用公式(4)计算第k个基本单元的输出命令ok(t),
式中,γ表示命令调整系数,设为常数,则在t时刻小脑模块的输出命令为o(t)=[o1(t),o2(t),…op(t)],若o(t)为零向量,则执行步骤d,即完成一次小脑模块命令的输出,否则执行子步骤c3;
子步骤c3、根据权值调整公式,计算当前小脑模块记忆信息对应的控制命令输出,具体包括以下子步骤:
子步骤c31、根据权值调整公式(5),调整第k个基本单元在t+1时刻的平行纤维和浦肯野细胞形成的突触记忆权值wkij(t+1)的大小,
式中,λ为调整系数,设为常数,δwkij(t)为在t时刻时平行纤维和浦肯野细胞形成的突触记忆权值的变化量,wkij(t)表示在t时刻平行纤维和浦肯野细胞形成的突触记忆权值;
子步骤c32、根据t时刻的小脑模块输出命令o(t)和小脑命令到效应器运动控制命令的映射关系f,利用公式(6)计算t+1时刻效应器的状态,
式中,δm(t)表示t时刻小脑命令控制效应器运动而产生的状态的调整值,m(t)表示t时刻效应器得状态,m(t+1)表示t+1时刻效应器的状态,随后再次执行子步骤b2;
步骤d、执行小脑模块学习功能,通过调整小脑模块的记忆权值,进而改变小脑模块的命令输出,若小脑模块首次进入学习过程,则执行子步骤d1,否则,执行子步骤d2;
子步骤d1、设定基于强化学习机制的小脑模型的相关要素的初始值,具体包括以下子步骤:
子步骤d11、设定所有平行纤维的状态值函数v的初始值均为1,其中,当平行纤维所处的状态为s时,其值函数可表示为vs;
子步骤d12、制定初始条件下,行为选择的策略为π(a),其具体内容为:在不同状态下,选择各个行为a的概率相同;其中,行为a表示选择一个基本单元激活,同时,每个基本单元激活都产生一个模值相同的基本单元输出命令ok';
子步骤d2、计算效应器的状态与期望值的误差,若在预先设定的允许范围之内,则建模完成,否则执行子步骤d3;
子步骤d3、判定对应基本单元的攀爬纤维的状态,具体包括以下子步骤:
子步骤d31、根据步骤b,确定在t时刻各个基本单元中平行纤维的状态s(t),并计算状态值函数vs(t);
子步骤d32、根据当前策略π(a),选择t时刻的行为a(t),并得到小脑模块的输出命令o',其中,o'=[0,0,…,ok',0,…],根据公式(6),可得到效应器的状态信息,再次根据步骤b,确定在t+1时刻各个基本单元中平行纤维的状态s(t+1),并计算状态值函数vs(t+1);同时,根据公式(7)计算环境反馈的奖惩值,
式中,r(t+1)表示在t+1时刻的奖惩值;
子步骤d33、根据公式(8)计算在t时刻的td误差δ(t),
δ(t)=r(t+1)+vs(t)-vs(t+1)(19)
子步骤d34、根据公式(9)修改行为选择策略,
式中,pr(s,a)表示在状态s下,选择行为a的倾向性,β为常值系数;
子步骤d35、根据公式(10)确定对应基本单元的攀爬纤维的状态,
式中,ck表示激活对应基本单元的攀爬纤维状态值;
子步骤d4、根据公式(11),对小脑模块第k个基本单元中的每个pf-pc初始权值wkij(1)进行调整,
wkij(1)=wkij(1)-σ·ck·xkj·ekj(τ)(22)
式中,σ表示学习系数,τ为信号在神经通路上传导的时延,ekj(t)为第k个基本单元中的第j个pf所对应的资格迹,
子步骤d5、若vs(t+1)≥vs(t),则执行子步骤d2,否则,将效应器恢复到初始状态,将t重置为1,执行子步骤b2。
本发明优点在于:一种基于强化学习的小脑模型建模方法,是以小脑自身的解剖学与生理学特性为出发点,在神经元水平上模拟、复制小脑的神经系统的结构与功能,解决了现有的许多小脑建模方法追求控制效果而忽略小脑本身特性的弊端。同时,将强化学习方法作为小脑学习过程所采取的机制能够很好地体现小脑学习过程中攀爬纤维放电的“全”或“无”的特点,使建立的小脑模型更具有生物的合理性。
- 还没有人留言评论。精彩留言会获得点赞!