一种基于Apriori算法的频繁项集挖掘方法与流程
本发明涉及大数据及数据挖掘的技术领域,尤其涉及一种频繁项集挖掘方法。
背景技术:
数据挖掘是指以某种方式分析数据源,通常是指海量数据,从中发现并提取一些潜在的有用的信息。目前,数据挖掘技术在人工智能和大数据领域受到广泛重视。其中,关联规则挖掘是数据挖掘的一个重要课题,顾名思义,它是从数据背后发现事物之间可能存在的关联或者联系。从这些大量事务记录中发现的关联规则,可以帮助人们做出决策。在所有关联规则挖掘的算法中,最有影响的是apriori算法,该算法通过发现支持度大于用户设定的最小支持度的频繁项目集,再从频繁项目集中挖掘出置信度大于用户设定的最小置信度的关联规则。
apriori算法的思想主要利用了向下封闭属性:如果一个项目集是频繁项集,那么它的非空子集必定是频繁项集。于是先生成频繁1-项集,再利用频繁1-项集生成频繁2-项集,然后根据频繁2-项集生成频繁3-项集......依次类推,直至生成所有的频繁项集,然后从频繁项集中找出符合条件的关联规则。第一步找出频繁1-项集很容易,只需循环扫描一次事务集合统计出项目集合中每个元素的支持度,然后根据设定的支持度阈值进行筛选即可得到。
下面将具体描述apiori算法是如何通过频繁(k-1)-项集生成频繁k-项集的。假设某个项目集s={s1,s2,...,sn}是频繁项集,那么它的(n-1)非空子集{s1,s2,...,sn-1},{s1,s2,...,sn-2,sn}...{s2,s3,...,sn}必定都是频繁项集,任何一个含有n个元素的集合a={a1,a2,...,an},它的(n-1)非空子集必行包含两项{a1,a2,...,an-2,an-1}和{a1,a2,...,an-2,an},对比这两个子集可以发现,它们的前(n-2)项是相同的,它们的并集就是集合a。对于频繁2-项集,它的所有1非空子集也必定是频繁项集,那么根据上面的性质,对于频繁2-项集中的任一个,在频繁1-项集中必定存在2个集合的并集与它相同。因此,在所有的1-频繁项集中找出只有最后一项不同的集合,将其合并,即可得到所有的包含2个元素的项目集。然而,得到的这些包含2个元素的项集不一定都是频繁项集,所以需要进行剪枝,剪枝的办法是看候选2-项集的所有1非空子集是否在频繁1-项集中,如果存在1非空子集不在频繁1-项集中,则将该2项集剔除。经过该步骤之后,剩下的则全是频繁项集,即频繁2-项集。依次类推,可以生成频繁3-项集,频繁4-项集,......,直至生成所有的频繁项集。
概括而言,apriori算法挖掘频繁项集的流程如下:首先扫描事务数据库,根据支持度阈值minsup产生频繁1-项集的集合f1;对集合f1进行连接操作,生成候选2-项集的集合c2;根据支持度阈值minsup对候选项集的集合c2进行剪枝,得到频繁2-项集的集合f2;再由f2得到c3和f3,以此类推,直到fk为空时结束。
apriori算法生成候选项集采用fk-1×fk-1方法,该方法将两个频繁(k-1)-项集连接成一个候选k-项集。其中,连接操作需满足的条件是:这两个频繁(k-1)-项集除最后一项不同之外,其余(k-2)项均完全相同。该算法存在一个很大的缺陷,它在产生候选k-项集的过程中需要对频繁(k-1)-项集进行反复对比以确定它们是否满足连接条件。该过程必须对(k-1)-项集中的各项进行逐一比对,这意味着将产生大量的重复比对工作,在对海量数据进行挖掘分析时,重复比对的工作量会急剧增加,相应地计算更耗时,严重影响计算效率和算法性能。
技术实现要素:
针对上述问题,本发明提供了一种基于apriori算法的新的频繁项集挖掘方法,能够在对海量数据进行挖掘时,大大减少频繁项集的重复比对工作,显著提升计算效率。
一种基于apriori算法的频繁项集挖掘方法,其特征在于,包括以下步骤:步骤a,扫描事务数据库,生成候选1-项集的集合c1,根据支持度阈值minsup对集合c1进行剪枝,得到频繁1-项集的集合f1;步骤b,使用双指针定位算法生成到候选k-项集的集合ck;步骤c,根据支持度阈值minsup对集合ck进行剪枝,得到频繁k-项集的集合fk;步骤d,重复步骤b和步骤c,直至fk为空。
其中,所述双指针算法生成候选k-项集的集合ck包括如下步骤:步骤1,将集合ck-1中的频繁(k-1)-项集按字典序进行排序;步骤2,设置第一指针和第二指针,两个指针均指向排序后的第一个频繁(k-1)-项集;步骤3,第一指针保持原位,第二指针下移一项,步骤4,将第二指针指向的项集与第一指针指向的项集进行比对,若比对结果满足连接条件,则将两个项集进行合并,生成一个候选k-项集,若比对结果不满足连接条件,则转至步骤6;步骤5,重复步骤3和步骤4;步骤6,记录所述第二指针的当前位置i,同时将第一指针与第二指针之间的项集两两进行合并,生成候选k-项集;步骤7,将第一指针和第二指针移至第i+1个频繁(k-1)-项集;步骤8,重复步骤3至步骤7,直至i等于频繁(k-1)-项集的总个数。
优选地,步骤3中所述的连接条件为:进行比对的两个频繁(k-1)-项集的前(k-2)项完全相同,且最后一项不同。
优选地,所述k的取值大于或等于2。
与传统的apriori频繁项集挖掘相比,本发明的技术方案通过创造性地使用双指针定位来记录每一次对比过程中第一个和最后一个满足连接条件的项的位置,极大地减少了重复比对的次数和工作量,挖掘频繁项集的效率也得以提高。本发明可以对智能家居企业的用户数据进行关联分析,挖掘出具有关联关系的产品组合,为企业提供有效的决策依据,便于他们将关联规则强的产品组合放在一起销售,以降低运营成本和提高成交率。
附图说明
通过结合附图的以下详细描述,本发明的上述及其他目的、特征和优点将变得更为明显。在附图中:
图1为本发明频繁项集挖掘方法的流程示意图;
图2为本发明一个实施例中排序后的频繁3-项集的示意图;
图3为本发明一个实施例中生成第一个候选4-项集的示意图;
图4为本发明一个实施例中生成第二个候选4-项集的示意图;
图5为本发明一个实施例中不满足连接条件时生成候选4-项集的示意图;
图6为本发明一个实施例中双指针均指向最后一个频繁3-项集时生成候选4-项集的示意图;
图7为两种频繁项集挖掘方法的效率对比曲线图。
具体实施方式
下面结合附图和实施例对本发明作进一步说明。
图1是本发明的流程示意图,提供一种频繁项集挖掘方法包括:步骤a,扫描事务数据库,生成候选1-项集的集合c1,根据支持度阈值minsup对集合c1进行剪枝,得到频繁1-项集的集合f1;步骤b,使用双指针定位算法生成到候选k-项集的集合ck;步骤c,根据支持度阈值minsup对集合ck进行剪枝,得到频繁k-项集的集合fk;步骤d,重复步骤b和步骤c,直至fk为空。其中,步骤a、c和d是本领域技术人员应该熟知的常规操作步骤,为简化篇幅起见,此处不再赘述。而本发明创造性地提出了一种双指针定位算法,并将该算法应用于对频繁(k-1)-项集进行更少量的计算即可得到所需的候选k-项集。
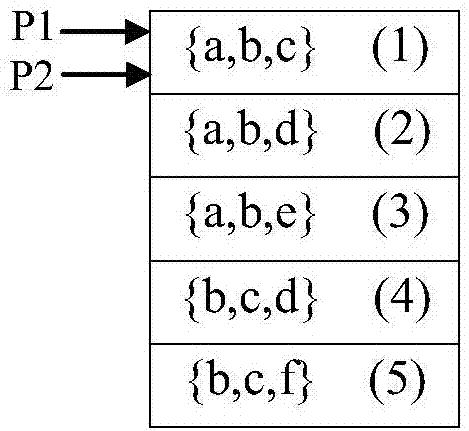
这里以由频繁3-项集生成候选4-项集为例对该步骤进行详细说明。图2-图6演示了根据本发明的频繁项集挖掘方法由频繁3-项集生成候选4-项集的过程,为了叙述方便,对每个频繁3-项集进行了编号。首先将编号为(1)的频繁项集依次与其后的频繁项集进行比对,分别与编号为(2)、(3)的频繁项集组合,产生{a,b,c,d}、{a,b,c,e}两个候选项集。当比对到编号为(4)的频繁项集时,发现不符合连接条件,不再向下比较。这时编号(2)和(3)的频繁项集可以不经过比较,直接合并生成候选项集{a,b,d,e}。然后从编号为(4)的频繁项集开始,重复上述过程。编号(4)和(5)的频繁项集合并生成候选项集{b,c,d,f}。至此,候选4-项集生成完毕。具体步骤描述如下:
步骤1,对频繁3-项集的集合按字典序进行排序,排序后见表1。
步骤2,设置两个指针,其中第一指针p1和第二指针p2均指向第一项{a,b,c}。
步骤3,指针p1保持不变,指针p2下移一位,指向第二项频繁3-项集,即{a,b,d}。
步骤4,如图3所示,将p2指向的项集{a,b,d}与p1指向的项集{a,b,c}进行比对,发现前两项完全相同,且最后一项不同,所以满足连接条件,对两者进行合并,生成一个候选4-项集{a,b,c,d}。
步骤5,因为满足连接条件所以重复步骤3和4,如图4所示,指针p1保持不动,指针p2继续下移一位,指向第三项频繁3-项集{a,b,e},继续比对{a,b,e}和{a,b,c},依然满足连接条件,则合并两个项集,生成第二个候选4-项集{a,b,c,e}。继续重复步骤3和4,发现此时p1和p2所指向的两个项集{a,b,c}和{b,c,d}不满足连接条件,则转至步骤6。
步骤6,如图5所示,记录指针p2的当前位置i=3,同时p1与p2之间的项集两两进行合并,生成第三个候选4-项集{a,b,d,e}。
步骤7,将指针p1和指针p2都移至第4个频繁3-项集。
步骤8,重复步骤3至步骤7,直至指针p2的位置i等于频繁3-项集的总个数,即i=5时结束计算,至此,可输出所有的候选4-项集,如图6所示。对候选4-项集进行基于支持度的剪枝操作,可以得到频繁4-项集的集合。同理,依照上述步骤可以由频繁4-项集生成候选5-项集,以此类推,计算出全部的频繁项集。
本发明的频繁项集挖掘方法在产生候选项集时运用字典进行排序的特性,充分利用了每一次比对判断的结果,有效地避免了重复判断,从而减少了判断次数,计算的速度和效率得到了提升。此外,还对本发明频繁项集挖掘方法的效率进行了验证,实验使用的计算机内存为8g,cpu主频为2.50ghz,操作系统为windows8.1。分别用传统的apriori算法和本发明的方法对10000条智能家居用户数据进行频繁项集挖掘,记录程序运行使用的时间。实验结果如图7所示,可以看出,在相同支持度条件下本发明的方法比传统apriori算法的执行效率更高。
可以理解的是,本公开不限于上述特定的实施方式,在不背离本公开精神及实质的情况下,本领域的技术人员可以根据本公开作出各种相应的修改和变形,并且对公开实施方式的修改、公开实施方式的特征的组合以及其它实施方式都意图被包含在所附权利要求限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!