一种分布式数据管理方法与流程
本发明属于分布式数据存储领域,更具体地,涉及一种分布式数据管理方法。
背景技术:
分布式数据管理,是指通过网络,以类似本地文件系统的方式访问其它节点上的数据。
存取文件实际对应的是存取文件的各个块,在获得文件的元数据信息后,需要继续获得文件的块信息。传统做法是基于块分布表的方式,即在内存中维护一个块分布表,表中存放了文件块的存储位置,通过查询块分布表来获得文件块信息。
在存取文件的时候,先获取到文件的元数据信息,然后再存取对应文件数据。元数据意指描述数据的数据,一般包括文件大小、位置、创建时间等信息。传统的分布式数据管理采用的是单个节点存放元数据的方式,即存取文件时,首先访问存放元数据的节点,获取到文件元数据后,再根据元数据存取文件。这样元数据管理带来的内存、计算等开销将由一个特点的节点承担,系统的资源及性能将受到限制。
在获取元数据信息的时侯,需要根据该元数据对应的文件的文件名,来定位元数据所在位置。元数据通常以文件树的形式组织,这样便于查找。在传统的文件系统中,查找元数据需要从根节点开始,根据名称逐层匹配路径。当文件系统的目录深度过大,这无疑会带来较大的性能开销。
在写文件的时候,为了系统的稳定性,需要写日志,记录修改操作,用于系统出错后的恢复操作。传统的文件系统,日志与文件数据是分开的,即单独使用一个文件用来存放日志。这就意味着,每次写文件需要进行两次文件输入输出,这显然会带来额外的性能开销。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种分布式数据管理方法,其目的在于将分布式数据管理的元数据管理功能分散到多个节点,并建立映射关系;同时支持文件元数据副本和文件数据副本,确保副本被分布到不同的节点,在读写文件元数据或文件数据时,当主存储端失效时,副本存储端能够迅速接替主存储端工作,由此解决现有元数据管理带来的内存、计算等开销将由一个特点的节点承担,系统的资源及性能将受到限制即数据副本分布可靠性不够的问题。
为实现上述目的,按照本发明的一个方面,提供了一种分布式数据管理方法,所述方法包括:
建立文件信息和多个节点的映射关系;在所述多个节点中,其中一个节点存储该文件的元数据,其他每个节点都存储有该文件的元数据副本;
建立文件元数据信息和多个节点的映射关系;在所述多个节点中,其中一个节点存储该文件数据,其他每个节点都存储有该文件数据副本;
所述元数据树结构采用普通多叉树与哈希表相结合的结构,在元数据的数据结构中加入全路径字段;
在写文件时,直接将日志追加在文件数据之后。
进一步地,所述方法还包括:
读写文件元数据时,对文件元数据进行读写操作,若成功,则对文件元数据副本进行同步操作;若失败,则对文件元数据副本进行读写操作。
进一步地,所述方法还包括:
读写文件数据时,对文件数据进行读写操作,若成功,则对文件数据副本进行同步操作;若失败,则对文件数据副本进行读写操作。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有以下技术特征及有益效果:
(1)在元数据树结构设计中,选择普通多叉树与哈希表结合的实现结构,一方面可以利用哈希进行快速查找,减少访存次数;另一方面可以利用树形结构方便的完成对整个目录文件的修改操作。在元数据的数据结构里加入了全路径字段,在查找以后,直接对比全路径名就可确定查找到的节点与需求节点是否一致,而不用从根节点开始逐层匹配路径;
(2)将数据写操作和其相应的元数据日志操作同时进行,写在同一个文件里。为了尽可能减少日志开销,设计这种日志方案,将每次数据操作需要进行的两次日志行为减少为一次,即每次操作减少一次访存的开销,提高系统的效率;
(3)传统上由单个节点承担的分布式数据管理的元数据管理功能被分散到存储与管理区的多个通用处理单元中,即元数据管理带来的内存、计算等开销将由所有通用处理单元共同承担,消除了系统可能存在的资源及性能瓶颈,从而提高了系统可扩展性,当系统拓扑确定后,系统不依赖于某一中心节点即能工作;
(4)通过基于映射的数据访问方式,任何文件读写请求理论上都可以不再向元数据服务器请求定位信息,从而降低管理元数据、访问元数据所带来的开销,任何客户端或维护端可仅仅凭借文件名或文件内偏移地址等文件信息以及系统拓扑快速定位文件内任意一个字节所在的存储端;
(5)元数据和数据管理采用主从模式,主从存储端均保留元数据和数据副本,当主存储端失效时,从存储端能够迅速接替主存储端工作,有效提升系统可用性和可靠性。
附图说明
图1是本发明分布式元数据管理的示意图;
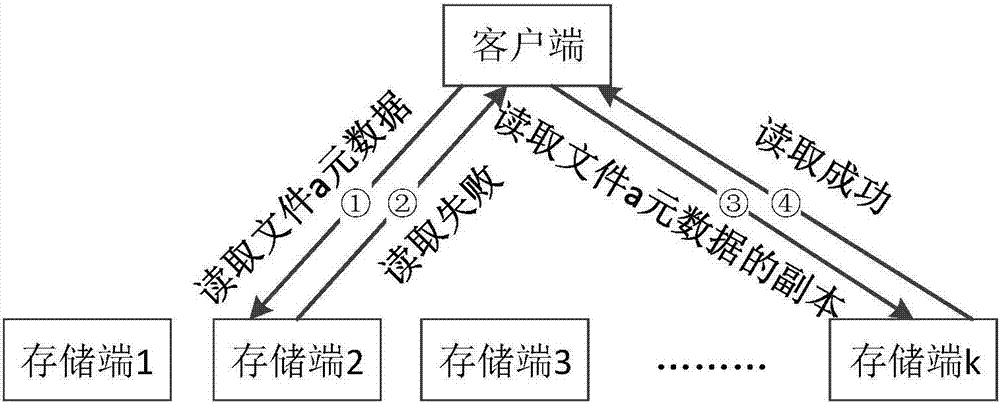
图2是本发明元数据读写的示意图;
图3是本发明数据读写的示意图;
图4是本发明元数据的数据结构示意图;
图5是本发明日志存放方式的示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明实施例中将会用到一些定义,其中的名词解释如下:
存储端:分布式数据管理中用于存储数据的节点;
如图1所示,本发明目的在于将分布式数据管理的元数据管理功能分散到多个节点,并建立映射关系;
现以具体实施例详细介绍其步骤:
(1)设计哈希函数1和哈希函数2,以文件所在的一级目录名作为输入,存储端编号为输出;
(2)对于分布式数据管理中某一文件,输入文件一级目录名到上一步设计的哈希函数中,哈希函数1输出对应的存储端n1存放了该文件的元数据,哈希函数2输出对应的存储端n2存放了该文件的元数据副本;
(3)如图2所示,读取该文件的元数据,从n1获取元数据;如果失败,则从n2获取元数据副本;
(4)设计哈希函数3和哈希函数4,以文件元数据编号为输入,存储端编号为输出;
(5)对于分布式数据管理中某一文件,输入文件元数据编号到上一步设计的哈希函数中,哈希函数3输出对应的存储端p1存放了该文件的数据,哈希函数4的输出对应的存储端p2存放了该文件的数据副本;
(6)如果是写文件,则执行步骤7;如果是读文件,则执行步骤8;
(7)向p1发送写请求,如果写成功,则p1将请求同步至p2;如果写失败,则向p2发送写请求;执行步骤9;
(8)向p1发送读请求;如果读失败,则如图3所示,向p2发送读请求;
(9)关闭文件,向n1发送关闭请求,如果关闭成功,则p1将请求同步至n2;如果关闭失败,则向n2发送关闭请求。
如图4所示,在元数据的数据结构中加入全路径字段,例如文件c的全路径为“/a/c”,则在该文件的元数据结构中加入字段“/a/c”。在进行查找时,不需要从根目录“/”到文件目录“/a”再到文件“/a/c”,而是直接通过对全路径“/a/c”进行哈希,从而定位到文件c的元数据。
如图5所示,在写文件完成之后,直接将日志追加在文件数据之后,不需要再打开其它文件,这样每次操作减少了一次访存的开销,提高系统的效率。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!