一种融合相似性和共同评分项数量的概率矩阵分解模型的制作方法
本发明涉及推荐算法领域,具体涉及一种融合相似性和共同评分项数量的概率矩阵分解模型,主要是在传统的概率矩阵分解模型(probabilisticmatrixfactorization,pmf)中融合相似性和共同评分项数量,从而能缓解数据稀松性,提高推荐精度。
背景技术:
随着互联网技术的发展,以用户为中心的信息生产模式造成了互联网信息的爆炸式增长,人们面临着越来越严重的“信息过载”问题。推荐系统能够挖掘用户偏好,给用户推荐他们喜欢的项目(电影、图书、音乐和商品等),从而提供个性化的推荐服务,能有效缓解“信息过载”问题。推荐算法是推荐系统的核心,很大程度上决定了推荐系统的性能。目前主要的推荐算法包括基于内容的推荐、基于知识的推荐、基于关联规则的推荐、协同过滤推荐和组合推荐等。其中,协同过滤是目前应用最广泛且最成功的推荐技术。
按照对用户-项目评分矩阵的处理方式的差异,协同过滤可以分为基于内存(memory-based)和基于模型(model-based)的协同过滤推荐算法。前者首先利用整个用户-项目评分数据集计算用户(项目)相似度,然后根据相似度选择邻居用户(项目),再根据邻居用户(项目)的评分为目标用户作推荐;后者根据训练集数据学习得出一个复杂的模型,然后基于该模型和目标用户已评分数据,推导出目标用户对未评分项目的评分值。基于内存的协同过滤算法包括基于用户(user-based)和基于项目(item-based)的协同过滤算法,基于模型的协同过滤算法中最具代表性且应用最为广泛的是pmf。
基于内存的协同过滤推荐算法具有很高的局部学习能力,且能推荐新颖性高的项目,不足之处在于不能处理数据稀松性问题;而pmf具有高扩展性,强大的全局学习能力,且能较好地处理数据稀松性问题。大量研究都表明了两种协同算法的融合能结合两者优势,从而进一步提高推荐效果。为了结合两者的优势,很多学者致力于在pmf中融合相似性,虽然一定程度上提高了推荐精度,但却忽略了共同评分项数量对推荐结果的影响。有相关研究表明,用户(项目)之间的共同评分项数量能反应其相似性的可信赖程度,因而能影响推荐效果。
技术实现要素:
本发明的目的是为了克服上述背景技术的不足,提供一种融合相似性和共同评分项数量的概率矩阵分解模型,可以有效提高推荐精度。
一种融合相似性和共同评分项数量的概率矩阵分解模型,包括:
步骤1,建立用户-项目评分矩阵r,用户-项目评分矩阵r中各个元素为ri,j,i=1,2,..n,j=1,2,3,..m,n表示推荐系统中的用户数量,m表示推荐系统中的项目数量;
步骤2,建立评分指示矩阵ir,评分指示矩阵ir中各个元素
步骤3,通过皮尔森相关系数计算用户相似度矩阵d,用户相似度矩阵d中各个其中di,k表示用户i和用户k之间的相似性,
其中,j表示用户i和k共同评价过的项目集合,
步骤4,通过改进的余弦相似性计算项目相似度矩阵s,相似度矩阵s中各个元素sj,p表示项目j与项目p之间的相似性,
其中i为同时评价过项目j和p的用户集;
步骤5,建立用户共同评分项数量矩阵cd,用户共同评分项数量矩阵cd中各个元素
步骤6,建立项目共同评分项数量矩阵cs,项目共同评分项数量矩阵cs中各个元素
步骤7,将用户共同评分项矩阵cd和项目共同评分项矩阵cs代入罚函数ω(c),得到用户相似性权重矩阵id=ω(cd),和项目相似性权重矩阵is=ω(cs),
罚函数ω(c)为
其中,阈值α和β(α<β)分别表示最小评分项数量和最大评分项数量;
步骤8,建立损失函数
其中
较佳地,步骤1还包括对用户-项目评分矩阵r进行归一化处理,
ri,j=ri,j/k
其中,k为推荐系统规定的评分范围。
较佳地,在步骤8之后还包括:
步骤9,求解损失函数e中的变量u和v,通过随机梯度下降算法最小化损失函数e求解用户因子矩阵u和项目因子矩阵v,得到u和v的偏导数公式:
较佳地,在步骤9之后还包括:
步骤10,依据步骤9所得公式求解出u和v,推荐系统预测的用户i对项目j的评分
本发明的有益效果在于:本发明针对现阶段推荐算法面临的诸多问题,在深入研究pmf的基础上,提出了一种新颖的融合相似性和共同评分项数量的概率矩阵分解模型,该模型在pmf的基础上,通过相似性来约束因子矩阵的内积,同时对公共评分项数量建立合适的罚函数,并把罚函数和因子矩阵的内积关联在一块来共同约束因子矩阵,从而提高因子矩阵的质量。在三个真实数据集上的实验表明,该模型能进一步缓解数据稀松性问题,提高推荐精度。本发明提出的一种融合相似性和共同评分项数量的概率矩阵分解模型成功结合了相似性在发掘局部关系方面的优势和概率矩阵分解模型在挖掘全局关系方面的优势,同时该模型还考虑到了共同评分项数量对相似性可信赖度的影响。相比之间所做的研究,本发明在推荐精度方面具有显著的提高。
附图说明
图1为本发明的逻辑架构图,
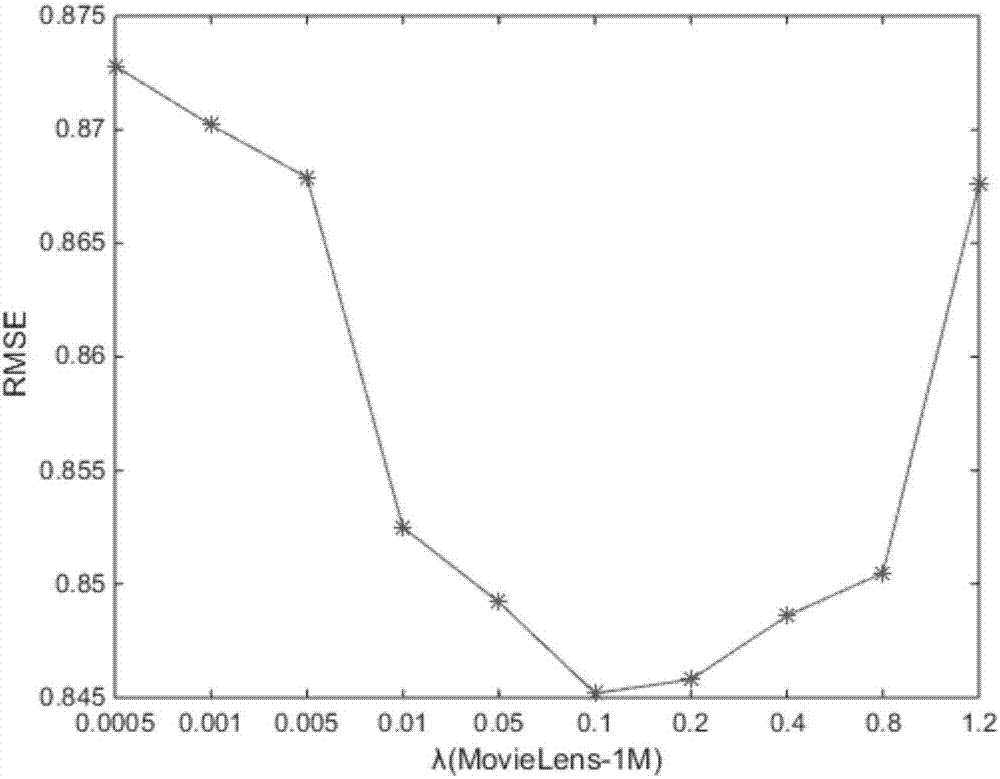
图2为模型参数λu和λv在movielens-1m上的影响,
图3为模型参数λu和λv在豆瓣图书数据集上的影响,
图4为模型参数λu和λv在豆瓣音乐数据集上的影响。
具体实施方式
下面结合附图及实施例对本发明作进一步的详细描述,但该实施例不应理解为对本发明的限制。
步骤1:建立用户-项目评分矩阵r,其中ri,j表示编号为i(i=1,2,..n)的用户对编号为j(j=1,2,3,..m)的项目的评分,n和m分别表示推荐系统中的用户数量和项目数量,如果用户i未对项目j进行评分,则ri,j=0。获取矩阵r之后,通过如下归一化函数对评分进行归一化处理:
ri,j=ri,j/k(1)
其中k为推荐系统规定的评分范围(如推荐系统采用5分制评分时,k=5)
步骤2:建立评分指示矩阵ir表示用户对项目评分情况,如果用户i对项目j进行过评分,则
步骤3:通过皮尔森相关系数计算用户相似度矩阵d,其中di,k表示用户i和用户k之间的相似性,即:
其中,j表示用户i和k共同评价过的项目集合,
步骤4:通过改进的余弦相似性计算项目相似度矩阵s,其中sj,p表示项目j与项目p之间的相似性,即:
其中i为同时评价过项目j和p的用户集。
步骤5:建立用户共同评分项数量矩阵cd,其中
步骤6:建立项目共同评分项数量矩阵cs,其中
步骤7:在用户、项目共同评分项矩阵的基础上,通过罚函数ω(c)建立用户相似性权重矩阵id和项目相似性权重矩阵is,即:id=ω(cd),is=ω(cs),罚函数如下:
其中,阈值α和β(α<β)分别表示最小评分项数量和最大评分项数量,罚函数表示当共同评分项数量小于α时,忽略其对应的相似性影响,当大于β,同等对待其对应的相似性影响。
步骤8:建立如下损失函数概率矩阵分解模型:
其中
步骤9:在上面的损失函数(式5)中,只有u和v为变量,通过随机梯度下降算法最小化损失函数求解用户因子矩阵u和项目因子矩阵v,其中u和v的偏导数如下:
步骤10:求解出u和v之后,即可通过公式6预测特定用户对特定项目的评分值
其中pi,j表示推荐系统预测的用户i对项目j的评分。
本实施例所述模型的推导过程包括:
和概率矩阵分解模型类似,融合相似性和共同评分项数量的概率矩阵分解模型在用户-项目评分集上的条件概率分布可以定义为:
其中,r为用户-项目评分集,n为用户数量,m为项目数量,u为用户因子矩阵,v为项目因子矩阵,n(x|μ,σ2)是均值为μ方差为σ2的高斯分布,g(x)=1/(1+exp(-x))为逻辑函数,
用户相似性矩阵d(d通过相似性计算得到)的先验条件概率分布定义为:
和用户相似性类似,项目之间的相似性矩阵s的先验条件概率分布定义为:
本发明也同样假定用户因子矩阵u和项目因子矩阵v都符合均值为0的高斯球形分布:
通过一个简单的贝叶斯推导,后验分布函数为:
对公式8取对数,得到如下公式:
其中c是一个常量,不依赖任何参数。针对变量u和v最大化后验分布的对数函数等价于最小化损失函数(式5)
将本实施例所述模型应用于java环境进行程序开发,jdk版本采用jdk1.7.0_79,运行环境为ubuntu14.04.4(64bit)。
以下通过具体数据对本发明实施例的效果进行描述:
为了丰富实验数据集,通过从豆瓣网站上爬取了图书和音乐数据,经过数据清理过程,获得了4705个用户对3876本书的1030701条评分数据,和7924个用户对4759首歌曲的1173540条评分数据。除此之外,我们还从movielens网站上下载了开放的movielens-1m数据集,其包含6040个用户对3952部电影的1000209条评分数据。对这三个数据集的描述如表2所示,三个数据集分别命名为book,music和movielens-1m。
在对iupmf与其它5种经典方法进行对比的实验中,我们把实验数据集分成两部分,90%的数据作为训练集,剩下10%的数据作为测试集。为了挑选最佳的参数设置,我们在训练集上采用了5-fold交叉验证的方法,并从集合{5,10,15,20,25,…,100}中选择最佳的邻居大小,pmf模型的参数λ从{0.0005,0.01,0.05,0.1,0.2,0.4,0.8,1.2}中选择,模型参数α的值从0到20之间选择,β的值从20到60之间选择,特征维度设置为10和20(即l=10和l=20)。我们选用随机梯度下降算法作为求最优解的方法,并把学习速率设置为0.001,最大迭代次数设置为1000。经过大量的实验,各算法的推荐精度如表1所示,获得的本模型最佳参数设置如表3所示。
在iupmf模型中,模型参数λu和λv在抗过拟合方面起着重要的作用。本发明设计了一组实验来专门探究模型参数的λu和λv的影响,在该实验中,我们让λu=λv=λ,然后λ的值从集合{0.0005,0.01,0.05,0.1,0.2,0.4,0.8,1.2}选择,除此之外,参数α、β以及l都设为最佳值。图2-4展示了模型参数λu和λv对iupmf模型的影响。
在推荐精度(rmse)方面,本发明与如下经典算法作了对比分析:
(1)item-knn:常规的基于项目的协同过滤推荐算法
(2)user-knn:常规的基于用户的协同过滤推荐算法
(3)pmf:经典的概率矩阵分解模型
(4)nhpmf:一种把基于近邻的方法与pmf相结合的推荐算法
(5)sbmf:一种新颖的融合相似性的矩阵分解模型
在三个真实数据集上的实验表明本发明显著提高了推荐精度,实验结果如下表所示:
表1本发明与现有的相关推荐算法的对比
表2进行实验的三个数据集
表3本发明的最佳参数设置
本发明提出了一种融合相似性和共同评分项数量的概率矩阵分解模型。该模型成功结合了相似性在发掘局部关系方面的优势和概率矩阵分解模型在挖掘全局关系方面的优势,同时该模型还考虑到了共同评分项数量对相似性可信赖度的影响。相比之间所做的研究,本发明在推荐精度方面具有显著的提高。接下来的工作就是将此模型运用于实际的推荐系统中,弥补传统推荐系统在推荐精度方面不足的问题。
以上显示和描述了本发明的基本原理、主要特征和优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!