一种面向服装图像检索的图像特征抽取方法与流程
本发明涉及图像检索技术领域,尤其涉及一种面向服装图像检索的图像特征抽取方法。
背景技术:
近年来,随着互联网特别是移动互联网的不断普及和发展,人们的生活发生日新月异的变化。过去人们获取的互联网信息主要以文本信息为主,而现在对图像、视频等多媒体信息也产生了巨大需求,如何从大量的图像数据中快速精准地找到人们所需的信息变得越来越重要。
当前有很多图像检索领域的研究,wan等人在[1]中通过实验验证了深度分类模型的高层特征对检索问题的有效性及其相对于传统特征的优越性。tolias等人在[2]中通过提取图像不同尺度的深度特征做融合使检索结果得到有效提升。huang等人在[3]中采用服装属性预测、特征排序和领域独立特征学习等方法提高了检索准确率。liu等人在[4]中通过提取人脸图像固定位置和大小的子区域特征来更好的刻画图像的局部信息。
然而这些方法依然没有很好的解决柔性物体(服装等)的局部信息刻画不足的问题,即检索结果虽然和检索图总体相似但细节却差别很大,比如t恤的检索结果虽然都是t恤但是图案却和检索图完全不同,使得检索结果的同款率低。为了解决局部信息刻画不足的问题,需要融合服装的关键区域特征,然而针对服装等柔性体,随着人的姿态变化同一款服装各个部位的相对位置变化极大,很难提取服装关键区域的特征,本文通过关键点检测并提取关键区域的方式解决了此问题。
参考文献:
[1]wanj,wangd,hoisch,etal.deeplearningforcontent-basedimageretrieval:acomprehensivestudy[j].2014(fullpaper):157-166.
[2]toliasg,sicrer,jégouh.particularobjectretrievalwithintegralmax-poolingofcnnactivations[j].computerscience,2015.
[3]huangj,ferisr,chenq,etal.cross-domainimageretrievalwithadualattribute-awarerankingnetwork[c]//ieeeinternationalconferenceoncomputervision.ieeecomputersociety,2015:1062-1070.
[4]liuj,dengy,bait,etal.targetingultimateaccuracy:facerecognitionviadeepembedding[j].2015.
技术实现要素:
本发明的目的是克服上述现有技术中局部信息刻画不足而导致服装检索的top1准确率低的问题,提出一种能够有效地抽取图像的局部特征来更好地刻画局部信息、使得服装检索的同款召回率得到提高的方法。
为了实现上述目的,本发明提出了一种面向服装图像检索的图像特征抽取方法,包括以下步骤:
一种面向服装图像检索的图像特征抽取方法,其特征在于包含以下步骤:
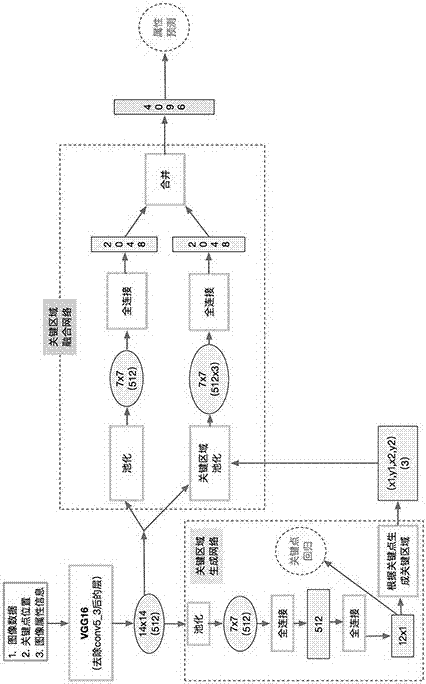
(1)设计如图1所示的深度学习模型。图中淡蓝色填充框表示数据,其中的数字表示数据的维度,绿色边框表示对数据的操作,箭头表示数据流向,红色部分表示损失函数。该网络的输入包含图像数据、图像关键点位置集合和图像属性信息集合,分别记为b、p、a。b表示图像的原始数据,可以看做三维矩阵,三维分别表示图像通道数、图像高度和图像宽度;p={p1,...,pi,...,pm}表示图像关键点坐标集合,其中m表示关键点个数,pi=(xi,yi)表示第i个关键点的位置,其中xi,yi分别表示关键点的横坐标和纵坐标;a表示图像对应的属性标签,包括颜色、类型、领型等,a={a1,...,ai,...,an},其中n表示属性个数,ai表示第i个属性的取值。图像数据b经过深度卷积网络vgg16处理后得到多个同宽高的特征图,记作fbase。然后将fbase输入关键区域生成网络,得到关键区域集合,记作r={r1,...,ri,...,rt},其中t表示关键区域的个数,ri=(xi1,yi1,xi2,yi2)表示第i个关键区域,xi1、yi1和xi2、yi2分别表示第i个关键区域左上角的横纵坐标和右下角的横纵坐标。再然后将上述的fbase和r一同输入关键区域融合网络,输出局部特征和全局特征的融合特征,记作fcomb。最后将fcomb连接到多个softmax属性分类器。
步骤(1)所述的关键区域生成网络的设计如下:该网络输入是步骤(1)中的fbase,输出是多个关键点的坐标预测值以及根据这些关键点得到的多个关键区域。输入和输出之间包含一个池化层和两个全连接层,第二个全连接层的输出为关键点的坐标预测值集合,记作pt=pt1,...,pti,...,ptm},其中m表示关键点个数,pti=(xti,yti)表示第i个关键点的横纵坐标预测值。将图像关键点的坐标预测值集合pt和步骤(1)的图像关键点坐标集合p一同输入关键点回归损失函数中,得到当前预测值的损失值。关键点回归损失函数lreg定义如下:
其中
步骤(1)所述的关键区域融合网络的设计如下:输入是步骤(1)的fbase和关键区域生成网络输出的多个关键区域,输出是局部特征和全局特征的融合特征。如图1所示,关键区域融合网络包含2个分支。第一个分支为服装全局特征的抽取,输入的fbase经过一个池化和一个全连接操作后,得到高维向量fglobal;第二个分支为服装的局部特征抽取,输入的fbase和步骤(1)的r经过关键区域池化和全连接操作后,得到高维向量flocal;最后将fglobal和flocal合并后得到的最终输出特征fcomb。关键区域池化具体过程为:
(1-1)设置输出集合为res,对步骤(1)的关键区域集合r的每个关键区域r,执行下面操作:
(1-1-1)按fbase和原图的宽高比例,将r的坐标从原图转换到fbase,得到新的关键区域坐标位置r′=(x′r1,y′r1,x′r2,y′r2),x′r1、y′r1和x′r2、y′r2分别表示关键区域r在fbase特征图上的左上角横纵坐标和右下角横纵坐标。
(1-1-2)将fbase的r′区域分成kxk个小块,并在每个小块里取最大值组成新的数据块,将此数据块加入输出集合res。
(1-2)将输出集合res的t个kxk的数据块依次拼接,得到关键区域池化的输出,记作fcritic,其中t表示步骤(1)中的关键区域个数。
步骤(1)所述的属性分类损失定义如下:
其中apl表示属性预测损失,s表示第s张图,
(2)准备步骤(1)所述深度学习模型的训练数据集、验证数据集和测试数据集。根据步骤(1)定义的图像数据b、图像关键点位置集合p和图像属性信息集合a准备模型训练的数据集x,x为三元组(b、p、a)的集合。将准备好的数据集按照6:2:2的比例分成训练数据集、验证数据集和测试数据集,分别记为xtrain、xval和xtest。
(3)训练关键区域生成网络。设置步骤(1)中深度学习模型的关键区域融合网络和属性预测任务的参数学习率系数(learningratemultiplier)为0,vgg16的参数学习率系数为较小值(0.1),关键区域生成网络的参数学习率系数为较大值(1.0)。采用imagenet训练得到的vgg16进行模型参数初始化,在步骤(2)所述的训练数据集xtrain上采用小批次随机梯度下降(msgd:mini-batchstochasticgradientdescent)优化算法进行参数训练学习,使得vgg16和关键区域生成网络的参数得到有效更新,从而提高关键点位置回归预测的准确率。训练过程中,初始基学习率(baselearningrate)为10e-2,当验证数据集xval的关键点回归损失函数值达到较低值且趋向平稳时依次选择基学习率为{10e-3,10e-4,10e-5}继续训练,直到在验证数据集xval上关键点回归损失函数值无法继续下降时停止训练。
(4)训练关键区域融合网络和属性预测任务。固定步骤(1)中深度学习模型的关键区域生成网络的参数学习率系数为0,设置vgg16、关键区域融合网络和属性预测任务的参数学习率系数分别为0.01、0.1、1.0。采用步骤(3)训练得到的关键区域生成网络的参数进行初始化,在步骤(2)的xtrain数据集上采用msgd优化算法进行属性预测任务训练。训练过程中通过观察在验证数据集xval上损失函数值的变化情况来调整基学习率和各层参数学习率系数,基学习率的选值过程依次为10e-2、10e-3、10e-4、10e-5,各层参数学习率系数根据所在层次的高低依次设定为0.01、0.1、1.0,即低层的参数在相似数据集上训练得到的值差别都不大,因此将低层的参数学习率系数设为0.01,而高层是任务紧密相关的参数,因此参数学习率系数设置为1.0。
(5)关键区域生成网络第二次训练。由于在步骤(4)训练过程中改变了步骤(1)的深度学习模型中vgg16的参数,使得关键区域生成的效果下降,因此需要微调关键区域生成网络的参数。为了不影响关键区域融合网络和属性预测任务的效果,第二次训练关键区域生成模型的过程中不改变vgg16的参数,只调整关键区域生成网络的参数,即设置关键区域生成网络之外的所有层的参数学习率系数为0,其他的训练过程和步骤(3)一致。
(6)关键区域融合网络第二次训练。由于步骤(4)训练过程中关键区域生成网络的效果变差了,因此在步骤(5)之后需要再次训练关键区域融合网络和属性预测任务。此时,固定vgg16和关键区域生成网络的参数学习率系数为0,只调整关键区域融合网络和属性预测任务的参数,直到损失函数值在步骤(2)的验证数据集xval上趋于稳定时停止训练。除了参数学习率系数设置不同外,其他的训练过程和步骤(4)一致。
(7)图像特征抽取。将图像输入到步骤(6)训练完成的深度学习模型中,进行深度网络的前向传播,输出步骤(1)所述的fcomb,得到面向服装图像检索的图像特征表示。
本发明提出的基于关键区域融合的多任务深度学习服装图像检索方法,其优点是:
1、本发明方法通过回归预测关键点位置并生成关键区域,然后融合关键区域特征和全图特征,使得最终学习到的特征具有局部和全局信息刻画能力,有效地提高了检索结果的准确性。
2、本发明方法通过回归预测关键点位置,并基于这些关键点生成关键区域,对于服装这种柔性物体的关键区域选取有较高的精准性和稳定性。
3、本发明方法采用基于多属性预测的多任务深度学习方法进行特征学习,学习到的特征能够有效地刻画服装图像的高层语义信息(属性信息),能够有效地解决图像特征和图像语义之间的“语义鸿沟”问题。
附图说明
附图1是服装图像关键点定义和关键区域生成示意图。
附图2是基于关键区域融合的多任务深度学习服装检索方法的模型示意图。
具体实施方式
一种面向服装图像检索的图像特征抽取方法,其特征在于包含以下步骤:
(1)设计如图1所示的深度学习模型;图中淡蓝色填充框表示数据,其中的数字表示数据的维度,绿色边框表示对数据的操作,箭头表示数据流向,红色部分表示损失函数;该网络的输入包含图像数据、图像关键点位置集合和图像属性信息集合,分别记为b、p、a;b表示图像的原始数据,可以看做三维矩阵,三维分别表示图像通道数、图像高度和图像宽度;p={p1,...,pi,...,pm}表示图像关键点坐标集合,其中m表示关键点个数,pi=(xi,yi)表示第i个关键点的位置,其中xi,yi分别表示关键点的横坐标和纵坐标;a表示图像对应的属性标签,包括颜色、类型、领型等,a={a1,...,ai,...,an},其中n表示属性个数,ai表示第i个属性的取值。图像数据b经过深度卷积网络vgg16处理后得到多个同宽高的特征图,记作fbase。然后将fbase输入关键区域生成网络,得到关键区域集合,记作r={r1,...,ri,...,rt},其中t表示关键区域的个数,ri=(xi1,yi1,xi2,yi2)表示第i个关键区域,xi1、yi1和xi2、yi2分别表示第i个关键区域左上角的横纵坐标和右下角的横纵坐标。再然后将上述的fbase和r一同输入关键区域融合网络,输出局部特征和全局特征的融合特征,记作fcomb。最后将fcomb连接到多个softmax属性分类器。
步骤(1)所述的关键区域生成网络的设计如下:该网络输入是步骤(1)中的fbase,输出是多个关键点的坐标预测值以及根据这些关键点得到的多个关键区域。输入和输出之间包含一个池化层和两个全连接层,第二个全连接层的输出为关键点的坐标预测值集合,记作pt={pt1,...,pti,...,ptm},其中m表示关键点个数,pti=(xti,yti)表示第i个关键点的横纵坐标预测值。将图像关键点的坐标预测值集合pt和步骤(1)的图像关键点坐标集合p一同输入关键点回归损失函数中,得到当前预测值的损失值。关键点回归损失函数lreg定义如下:
其中
步骤(1)所述的关键区域融合网络的设计如下:输入是步骤(1)的fbase和关键区域生成网络输出的多个关键区域,输出是局部特征和全局特征的融合特征。如图1所示,关键区域融合网络包含2个分支。第一个分支为服装全局特征的抽取,输入的fbase经过一个池化和一个全连接操作后,得到高维向量fglobal;第二个分支为服装的局部特征抽取,输入的fbase和步骤(1)的r经过关键区域池化和全连接操作后,得到高维向量flocal;最后将fgloval和flocal合并后得到的最终输出特征fcomb。关键区域池化具体过程为:
(1-1)设置输出集合为res,对步骤(1)的关键区域集合r的每个关键区域r,执行下面操作:
(1-1-1)按fbase和原图的宽高比例,将r的坐标从原图转换到fbase,得到新的关键区域坐标位置r′=(x′r1,y′r1,x′r2,y′r2),x′r1、y′r1和x′r2、y′r2分别表示关键区域r在fbase特征图上的左上角横纵坐标和右下角横纵坐标。
(1-1-2)将fbase的r′区域分成kxk个小块,并在每个小块里取最大值组成新的数据块,将此数据块加入输出集合res。
(1-2)将输出集合res的t个kxk的数据块依次拼接,得到关键区域池化的输出,记作fcritic,其中t表示步骤(1)中的关键区域个数。
步骤(1)所述的属性分类损失定义如下:
其中apl表示属性预测损失,s表示第s张图,
(2)准备步骤(1)所述深度学习模型的训练数据集、验证数据集和测试数据集。根据步骤(1)定义的图像数据b、图像关键点位置集合p和图像属性信息集合a准备模型训练的数据集x,x为三元组(b、p、a)的集合。将准备好的数据集按照6:2:2的比例分成训练数据集、验证数据集和测试数据集,分别记为xtrain、xval和xtest。
(3)训练关键区域生成网络。设置步骤(1)中深度学习模型的关键区域融合网络和属性预测任务的参数学习率系数(learningratemultiplier)为0,vgg16的参数学习率系数为较小值(0.1),关键区域生成网络的参数学习率系数为较大值(1.0)。采用imagenet训练得到的vgg16进行模型参数初始化,在步骤(2)所述的训练数据集xtrain上采用小批次随机梯度下降(msgd:mini-batchstochasticgradientdescent)优化算法进行参数训练学习,使得vgg16和关键区域生成网络的参数得到有效更新,从而提高关键点位置回归预测的准确率。训练过程中,初始基学习率(baselearningrate)为10e-2,当验证数据集xval的关键点回归损失函数值达到较低值且趋向平稳时依次选择基学习率为{10e-3,10e-4,10e-5}继续训练,直到在验证数据集xval上关键点回归损失函数值无法继续下降时停止训练。
(4)训练关键区域融合网络和属性预测任务。固定步骤(1)中深度学习模型的关键区域生成网络的参数学习率系数为0,设置vgg16、关键区域融合网络和属性预测任务的参数学习率系数分别为0.01、0.1、1.0。采用步骤(3)训练得到的关键区域生成网络的参数进行初始化,在步骤(2)的xtrain数据集上采用msgd优化算法进行属性预测任务训练。训练过程中通过观察在验证数据集xval上损失函数值的变化情况来调整基学习率和各层参数学习率系数,基学习率的选值过程依次为10e-2、10e-3、10e-4、10e-5,各层参数学习率系数根据所在层次的高低依次设定为0.01、0.1、1.0,即低层的参数在相似数据集上训练得到的值差别都不大,因此将低层的参数学习率系数设为0.01,而高层是任务紧密相关的参数,因此参数学习率系数设置为1.0。
(5)关键区域生成网络第二次训练。由于在步骤(4)训练过程中改变了步骤(1)的深度学习模型中vgg16的参数,使得关键区域生成的效果下降,因此需要微调关键区域生成网络的参数。为了不影响关键区域融合网络和属性预测任务的效果,第二次训练关键区域生成模型的过程中不改变vgg16的参数,只调整关键区域生成网络的参数,即设置关键区域生成网络之外的所有层的参数学习率系数为0,其他的训练过程和步骤(3)一致。
(6)关键区域融合网络第二次训练。由于步骤(4)训练过程中关键区域生成网络的效果变差了,因此在步骤(5)之后需要再次训练关键区域融合网络和属性预测任务。此时,固定vgg16和关键区域生成网络的参数学习率系数为0,只调整关键区域融合网络和属性预测任务的参数,直到损失函数值在步骤(2)的验证数据集xval上趋于稳定时停止训练。除了参数学习率系数设置不同外,其他的训练过程和步骤(4)一致。
(7)图像特征抽取。将图像输入到步骤(6)训练完成的深度学习模型中,进行深度网络的前向传播,输出步骤(1)所述的fcomb,得到面向服装图像检索的图像特征表示。
- 还没有人留言评论。精彩留言会获得点赞!