一种基于文件系统的嵌入式存储方法和装置与流程
本发明属于存储系统技术领域,特别是涉及一种基于文件系统的嵌入式存储方法和装置。
背景技术:
众所周知,复杂的业务系统会依赖多种类型的数据,为了保证系统的解耦,系统之间往往通过服务的方式提供数据,实际上,应用本身可能有数据,但是某一些数据并不是应用本身的,需要从其他系统获取到。这种方式会给系统带来许多的强依赖,依赖过多之后,就会使应用变得不稳定,很容易被依赖的二方服务(公司内部提供出来的公共服务)所影响。
技术实现要素:
为解决上述问题,本发明提供了一种基于文件系统的嵌入式存储方法和装置,提高数据读取性能,去除对二方服务的强依赖,增强应用的稳定性。
本发明提供的一种基于文件系统的嵌入式存储方法,包括:
对每个待写入的数据进行解析,得到与所述数据相对应的key;
对所述key进行索引,得到与所述key相对应的目录;
以所述key作为文件名,在与所述key相对应的目录内生成文件,将所述数据写入所述文件中。
优选的,在上述基于文件系统的嵌入式存储方法中,将所述数据写入所述文件中之后,还包括:
接收待读取数据的key并进行解析,计算出与所述待读取数据的key相对应的目录;
拼接所述待读取数据的key和其对应的目录,得到文件的完整路径;
根据所述文件的完整路径,读取所述文件的内容得到所述待读取数据。
优选的,在上述基于文件系统的嵌入式存储方法中,所述对所述key进行索引为:
对所述key进行至少一次hash。
优选的,在上述基于文件系统的嵌入式存储方法中,所述对所述key进行至少一次hash为:
对所述key进行至三次hash。
本发明提供的一种基于文件系统的嵌入式存储装置,包括:
第一解析单元,用于对每个待写入的数据进行解析,得到与所述数据相对应的key;
索引单元,用于对所述key进行索引,得到与所述key相对应的目录;
写入单元,用于以所述key作为文件名,在与所述key相对应的目录内生成文件,将所述数据写入所述文件中。
优选的,在上述基于文件系统的嵌入式存储装置中,还包括:
第二解析单元,用于接收待读取数据的key并进行解析,计算出与所述待读取数据的key相对应的目录;
文件路径生成单元,用于拼接所述待读取数据的key和其对应的目录,得到文件的完整路径;
读取单元,用于根据所述文件的完整路径,读取所述文件的内容得到所述待读取数据。
优选的,在上述基于文件系统的嵌入式存储装置中,所述索引单元具体用于对所述key进行至少一次hash。
优选的,在上述基于文件系统的嵌入式存储装置中,所述索引单元具体用于对所述key进行至三次hash。
通过上述描述可知,本发明提供的上述基于文件系统的嵌入式存储方法和装置,由于该方法包括对每个待写入的数据进行解析,得到与所述数据相对应的key;对所述key进行索引,得到与所述key相对应的目录;以所述key作为文件名,在与所述key相对应的目录内生成文件,将所述数据写入所述文件中,因此提高数据读取性能,去除对二方服务的强依赖,增强应用的稳定性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本申请实施例提供的第一种基于文件系统的嵌入式存储方法的示意图;
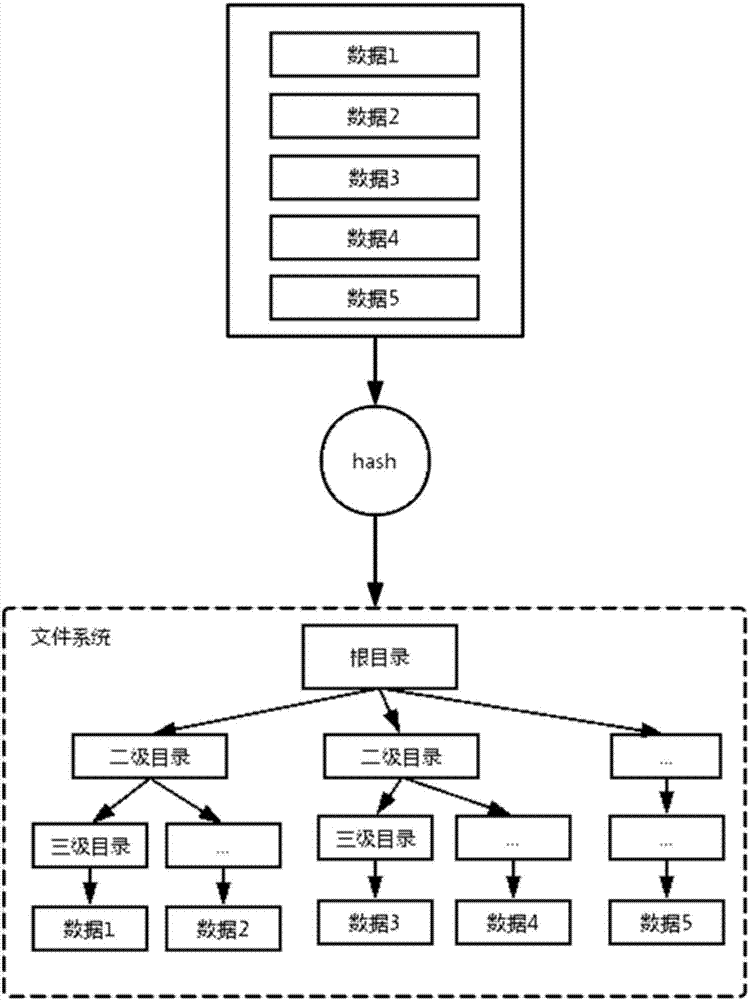
图2为数据写入过程的示意图;
图3为数据读取过程的示意图;
图4为本申请实施例提供的第一种基于文件系统的嵌入式存储装置的示意图。
具体实施方式
本发明的核心思想在于提供一种基于文件系统的嵌入式存储方法和装置,提高数据读取性能,去除对二方服务的强依赖,增强应用的稳定性。
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本申请实施例提供的第一种基于文件系统的嵌入式存储方法如图1所示,图1为本申请实施例提供的第一种基于文件系统的嵌入式存储方法的示意图,该方法包括如下步骤:
s1:对每个待写入的数据进行解析,得到与所述数据相对应的key;
s2:对所述key进行索引,得到与所述key相对应的目录;
s3:以所述key作为文件名,在与所述key相对应的目录内生成文件,将所述数据写入所述文件中。
参考图2,图2为数据写入过程的示意图,图中以hash来表示索引过程,但是此次并不构成限制,还可以采用其他方式进行索引,而且图中是以三级索引为例进行说明,实际上,可以根据实际情况增加或减少索引层级,保证数据被分散到足够多的目录中,避免单个目录的文件数过多。具体的,在数据写入时,会解析数据,将对应的数据key解析出来,并使用该key进行包括hash在内的索引,再以数据key为文件名,在之前的目录下生成这个文件,再将数据写入该文件,完成数据的写入过程。
需要说明的是,现有的单文件存储方案在数据全量时非常简单,但是其增量的实现非常困难,会导致整个文件重写一遍,具体而言,假设一个文件中存储了100条数据,增量的时候只修改了第10条数据,这时单文件存储的处理步骤如下:新建一个文件,将前9条数据写入新文件,写入新的第10条数据,再继续写入后面的90条数据,可见,这个过程相当于整个文件重新写了一次,效率非常低,且需要考虑到并发场景,引入锁得更加复杂的方案。而如果是本实施例提供的单文件方案就解决了上述问题,直接找到这条数据对应的文件,把这个文件的内容改掉就够了,且现有的方案中,对于数据的查询也非常消耗性能,极端情况下需要将整个数据文件扫描一遍,而本实施例解决了这个问题,它将每一个数据拆分成一个单独的文件,这样数据进行增量更新时,只需要简单的将一个数据文件修改掉就可以了。同时针对数据key进行索引,生成一个文件存储的完整路径,以这样的方式将文件打散到多个不同的目录下,每个目录下的文件数就得以减少,正是由于该方式是直接使用的文件的索引,所以文件查找非常迅速。
通过上述描述可知,本申请实施例提供的第一种基于文件系统的嵌入式存储方法,由于包括对每个待写入的数据进行解析,得到与所述数据相对应的key;对所述key进行索引,得到与所述key相对应的目录;以所述key作为文件名,在与所述key相对应的目录内生成文件,将所述数据写入所述文件中,因此提高数据读取性能,去除对二方服务的强依赖,增强应用的稳定性。
本申请实施例提供的第二种基于文件系统的嵌入式存储方法,是在上述第一种基于文件系统的嵌入式存储方法的基础上,还包括如下技术特征:
将所述数据写入所述文件中之后,还包括:
接收待读取数据的key并进行解析,计算出与所述待读取数据的key相对应的目录;
拼接所述待读取数据的key和其对应的目录,得到文件的完整路径;
根据所述文件的完整路径,读取所述文件的内容得到所述待读取数据。
参考图3,图3为数据读取过程的示意图,在这种情况下,数据解析过程更加简单,直接使用传入的待读取数据的key,使用数据写入时相对的算法,包括但不限于hash方式,计算出待读取数据的key对应的目录,拼接上待读取数据的key,即得到了文件的完整路径,然后直接读取该文件内容,即为该数据的完整内容。
本申请实施例提供的第三种基于文件系统的嵌入式存储方法,是在上述第一种至第二种基于文件系统的嵌入式存储方法中任一种的基础上,还包括如下技术特征:
所述对所述key进行索引为:
对所述key进行至少一次hash。
需要说明的是,当数据总量不大时,可以采用一次hash即可,而当数据比较大时,就需要增加hash的次数,以避免同一个目录中的数据超过承载能力,也就是说,可以根据实际的需要来决定hash的次数,此处并不做具体限制。
本申请实施例提供的第四种基于文件系统的嵌入式存储方法,是在上述第三种基于文件系统的嵌入式存储方法的基础上,还包括如下技术特征:
所述对所述key进行至少一次hash为:
对所述key进行至三次hash。
需要说明的是,这里采用的hash过程的次数是完全可配置化的,需要hash的次数取决数据的多少,数据越多,hash的次数就可配置得越多,保证单个目录下文件不会太多。利用该实施例的三次hash的过程如下:对key进行第1次hash,做为一级目录名,再用一级目录名进行第二次hash,做为二级目录名,用二级目录名进行第三次hash,做为三级目录名,分别将三次hash的值拼接,就能够形成一个文件路径,将数据写入该文件中,就完成了数据的写入过程。
本申请实施例提供的第一种基于文件系统的嵌入式存储装置如图4所示,图4为本申请实施例提供的第一种基于文件系统的嵌入式存储装置的示意图,该装置包括:
第一解析单元201,用于对每个待写入的数据进行解析,得到与所述数据相对应的key;
索引单元202,用于对所述key进行索引,得到与所述key相对应的目录;
写入单元203,用于以所述key作为文件名,在与所述key相对应的目录内生成文件,将所述数据写入所述文件中。
需要说明的是,现有的单文件存储方案在数据全量时非常简单,但是其增量的实现非常困难,会导致整个文件重写一遍,具体而言,假设一个文件中存储了100条数据,增量的时候只修改了第10条数据,这时单文件存储的处理步骤如下:新建一个文件,将前9条数据写入新文件,写入新的第10条数据,再继续写入后面的90条数据,可见,这个过程相当于整个文件重新写了一次,效率非常低,且需要考虑到并发场景,引入锁得更加复杂的方案。而如果是本实施例提供的单文件方案就解决了上述问题,直接找到这条数据对应的文件,把这个文件的内容改掉就够了,且现有的方案中,对于数据的查询也非常消耗性能,极端情况下需要将整个数据文件扫描一遍,而本实施例解决了这个问题,它将每一个数据拆分成一个单独的文件,这样数据进行增量更新时,只需要简单的将一个数据文件修改掉就可以了。同时针对数据key进行索引,生成一个文件存储的完整路径,以这样的方式将文件打散到多个不同的目录下,每个目录下的文件数就得以减少,正是由于该方式是直接使用的文件的索引,所以文件查找非常迅速。
本申请实施例提供的第二种基于文件系统的嵌入式存储装置,是在上述第一种基于文件系统的嵌入式存储装置的基础上,还包括如下技术特征:
还包括:
第二解析单元,用于接收待读取数据的key并进行解析,计算出与所述待读取数据的key相对应的目录;
文件路径生成单元,用于拼接所述待读取数据的key和其对应的目录,得到文件的完整路径;
读取单元,用于根据所述文件的完整路径,读取所述文件的内容得到所述待读取数据。
在这种情况下,数据解析过程更加简单,直接使用传入的待读取数据的key,使用数据写入时相对的算法,包括但不限于hash方式,计算出待读取数据的key对应的目录,拼接上待读取数据的key,即得到了文件的完整路径,然后直接读取该文件内容,即为该数据的完整内容。
本申请实施例提供的第三种基于文件系统的嵌入式存储装置,是在上述第一种至第二种基于文件系统的嵌入式存储装置中任一种的基础上,还包括如下技术特征:
所述索引单元具体用于对所述key进行至少一次hash。
需要说明的是,当数据总量不大时,可以采用一次hash即可,而当数据比较大时,就需要增加hash的次数,以避免同一个目录中的数据超过承载能力,也就是说,可以根据实际的需要来决定hash的次数,此处并不做具体限制。
本申请实施例提供的第四种基于文件系统的嵌入式存储装置,是在上述第三种基于文件系统的嵌入式存储装置的基础上,还包括如下技术特征:
所述索引单元具体用于对所述key进行至三次hash。
需要说明的是,这里采用的hash过程的次数是完全可配置化的,需要hash的次数取决数据的多少,数据越多,hash的次数就可配置得越多,保证单个目录下文件不会太多。利用该实施例的三次hash的过程如下:对key进行第1次hash,做为一级目录名,再用一级目录名进行第二次hash,做为二级目录名,用二级目录名进行第三次hash,做为三级目录名,分别将三次hash的值拼接,就能够形成一个文件路径,将数据写入该文件中,就完成了数据的写入过程。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!