一种基于分解聚合的电信诈骗电话的分类检测方法与流程
本发明属于数据挖掘,机器学习和商务智能等领域,具体是一种基于分解聚合的电信诈骗电话的分类检测方法。
背景技术:
近年来我国电信诈骗案件时有发生,严重威胁到人民的财产安全和社会的稳定。由于通话量巨大,监管部门难以对所有电话进行实时监管与拦截,因此如何利用数据挖掘中的分类、异常检测等方法实现自动化的疑似诈骗电话的检测,对监管部门来说是一个巨大的挑战。
诈骗电话分类检测的实际问题,首先是数据量较大,仅以国际通话端为例,每天的呼叫量在2000万次以上;同时,在原始的数据中,被拦截和标注的诈骗电话样本在全部通话记录中仅占较小的一部分,使得数据类别具有显著的不平衡特点。比如,少量被检出的诈骗电话被标注为正类样本,而其余大部分通话均被标注为负类样本,在目前的国际电话的记录中,正负比例达到了40:1。实际上,这种类别不平衡的现象存在于大量的实际应用场景中,如网络入侵检测,信用卡欺诈检测等有监督的异常检测问题中。
对于兼具大规模和不平衡类别特点的数据来说,难以通过统一的模型进行训练。一方面由于数据量过大,用单一模型需要消耗大量的时间和空间;另一方面由于数据本身的不平衡特点,采用单一模型会对正类样本的分类产生欠拟合(underfitting)的现象。
由于原始数据量较大,即使正负类比例失衡,对于正类比例仍然有大量可供训练的样本。在这种情形下,如何从大量原始数据中进行合理的采样成为在实际的稀有类别的检测中的一个重要问题。此外,目前大部分电信诈骗的检测方法仅侧重于单一指标,例如,仅追求检测的准确率,但是这类方法对于不同类型的诈骗电话缺乏普适性,导致召回率较低。
实际上,由于不同的正负类的训练样本会对检测模型的各种精度同时产生影响,因此需要一种自动确定最优正负类训练样本的方法来在各类指标,如准确率,召回率等之间要做出更加合理的权衡。
技术实现要素:
本发明有鉴于在不平衡类别下的大数据分类的难度和挑战,同时考虑到样本量较大,正类样本也较多的特点,构建了一种基于分解聚合的电信诈骗电话的分类检测方法。
具体步骤如下:
步骤一、收集电信网络中的cdr数据(calldetailrecord,呼叫详细数据),将被检出的少量诈骗电话记录标注为正类样本,其余的标注为负类样本。
步骤二、设定正负样本比例为x%,对cdr数据进行横向的连续采样划分,反复采样l次,得到l个正负类比例为x%的样本子集。
采用有放回的随机抽样方式,从cdr数据中抽取正负类样本比例为x%的数据记录。
步骤三、按照等步长的方式依次改变正负类比例,进行a次,共产生a*l个训练子集。
等步长是指任意两个相邻正负类样本比例值之间的差值固定;
步骤四、对cdr数据按照特征属性进行纵向分解,得到f种不同的类别属性子集;
具体而言,cdr数据共有m个特征,随机抽取y%的属性特征,共计m*y%个属性特征作为基础分类器的分类特征;通过有放回的随机抽样抽取采样f次,得到f种不同的类别属性子集。
步骤五、原始cdr数据被划分为了a*l*f个训练样本区,每个训练样区同时具有特定正负类比例及特征属性;
步骤六、针对每个训练样本区中的数据,利用决策树分类模型在子特征属性空间上构造一个分类器,共得到a*l*f个基础分类器;
步骤七、针对原始cdr数据中的某训练样本,在a*l*f个基础分类器上分别输出分类预测结果,构造成该训练样本的分类矩阵。
具体来说,矩阵中的每个元素对应了一种特定正负比例下,在特定的属性特征子集中的分类结果。
步骤八、针对该分类矩阵,对横向相同正负比例的分类结果进行聚合,并进行特征集合筛选。
具体步骤如下:
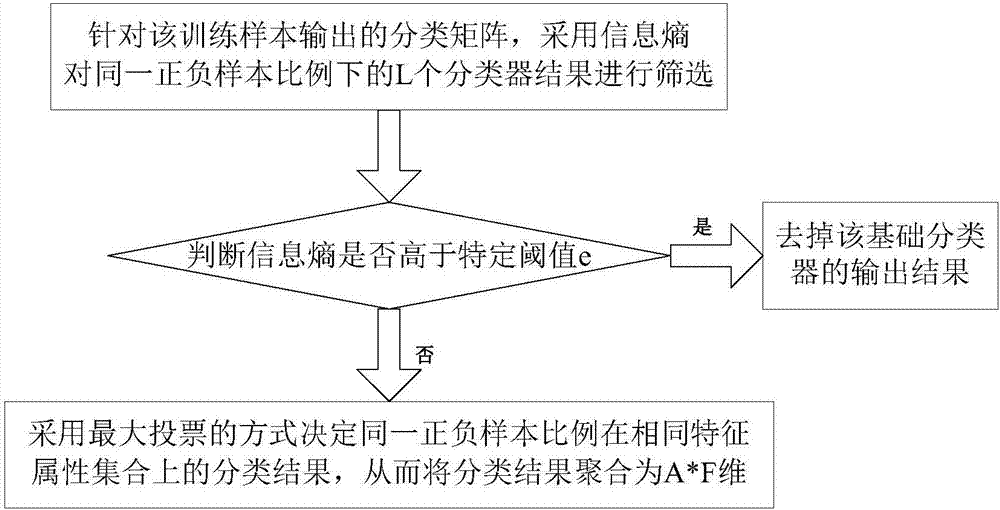
步骤801、针对该训练样本输出的分类矩阵,采用信息熵对同一分类比例下的l个分类器结果进行筛选;
步骤802、判断信息熵是否高于特定阈值e,如果是,去掉该基础分类器的输出结果;否则,进入步骤803;
信息熵高于特定阈值e,说明该组子特征集合下对于类别的区分度较差。
步骤803、采用最大投票的方式决定同一分类比例在相同特征属性集合上的分类结果,从而将分类结果聚合为a*f维。
步骤九、针对筛选后的a*f维特征集合中,采用最大投票的方式确定各行的分类输出结果,得到a种不同正负比例的分类结果。
a种不同正负比例下的分类结果视作该训练样本的一个a维特征表示。
步骤十、针对cdr数据的所有训练样本,采用决策树分类模型,运用每个训练样本的a维特征结果构造二级分类器;
步骤十一、对于一条新的测试样本,重复步骤七到步骤九,得到关于该测试数据在各种正负样本比例的a维特征,进一步利用二级分类器,得出该测试样本的最终的分类结果。
本发明的优势在于:
1)、一种基于分解与聚合的电信诈骗电话的分类检测的分类方法,适用于各种大数据场景下的不平衡分类,避免了不同正负类样本比例下模型精度的波动性。
2)、一种基于分解与聚合的电信诈骗电话的分类检测的分类方法,通过相同比例之间分类结果的校验以及构建与不同比例的特征上的二级分类器,使得分类结果具有较强的稳定性和鲁棒性。
3)、一种基于分解与聚合的电信诈骗电话的分类检测的分类方法,容易实现并行化计算,可以实现较高的分类和检测效率。
附图说明
图1是本发明一种基于分解与聚合的电信诈骗电话的分类检测的分类方法流程图;
图2是本发明进行特征集合筛选的方法流程图。
具体实施方式
下面结合附图对本发明的具体实施方法进行详细说明。
本发明鉴于在不平衡类别下的大数据分类的难度和挑战,考虑到样本量较大,正类样本也较多的特点,构建了一种基于“分解与聚合”的分类方法;涉及到大规模数据中的不平衡分类与异常检测,对原始大规模cdr数据进行不同正负类比例的横向划分与采样,同时在针对具体的训练样本时,随机抽取特定比例的特征属性用于基础分类器的构造。对于任一训练样本,根据基础分类器的输出结果构造分类矩阵,对各相同比例中的分类结果进行聚合,筛掉相同属性特征下的分类结果极端不一致的分类结果,并通过最大投票法确定各正负类别比例下的投票结果。同时,将各个比例分类器中的分类结果作为新的分类特征,并且构造二级分类器,从而确定各正负比例的基分类器对于测试结果的权重。
如图1所示,具体步骤如下:
步骤一、收集电信网络中的cdr数据,将被检出的少量诈骗电话记录标注为正类样本,其余的标注为负类样本。
收集电信网络中的cdr数据,将检出的少量诈骗电话样本标注为正类样本,其余的标注为负类样本,构造原始数据集。
步骤二、设定正负样本比例为x%,对cdr数据进行横向的连续采样划分,反复采样l次,得到l个正负类比例为x%的样本子集。
具体来说,对于特定的正负类比例x%,均通过有放回的随机抽样抽取固定数量n=10000的数据记录。按照此方式反复采样l=20次,得到20个正负类比例为x%的样本子集。
步骤三、按照等步长的方式依次改变正负类比例,进行a次,共产生a*l个训练子集。
等步长是指任意两个相邻正负类样本比例值之间的差值固定;
按照等步长的方式依次改变正负类比例从1%至50%,并且设1%为步长,因而共产生a=50种不同正负比例的样本;根据步骤二的划分方法,共产生20*50=1000个不同的训练样本子集。
步骤四、对cdr数据按照特征属性进行纵向分解,得到f种不同的类别属性特征子集;
具体而言,对原始cdr数据进行特征提取,具体包括了主叫和被叫号码的特征及通话的特征,共提取30个特征;在30个特征中,随机抽取2%的属性特征,即6个属性特征作为各个基础分类器的分类特征,通过有放回的随机抽样抽取采样20次,共得到20种不同的类别属性子集。
步骤五、原始cdr数据被划分为了a*l*f个训练样本区,每个训练样区同时具有特定正负类比例及特征属性;
根据步骤二到四,将原始cdr数据集合划分了20*50*20=20000个具有特定正负类比例及特征属性空间上的子训练样本区。
步骤六、针对每个训练样本区中的数据,利用决策树分类模型在子特征属性空间上构造一个分类器,共得到a*l*f个基础分类器;
在每个训练样本区上,利用决策树分类模型对每个训练样本区中的数据在子特征属性空间上构造分类器,共得到20000个基础分类器。
步骤七、针对原始cdr数据中的某训练样本,在a*l*f个基础分类器上分别输出分类预测结果,构造成该训练样本的分类矩阵。
对于任一训练样本,在20000个基础分类器上分别输出20000个分类预测结果,构成了分类矩阵。具体来说,矩阵中的每个元素对应了一种特定正负比例下,在特定的属性特征子集中的分类结果。
步骤八、针对该分类矩阵,对横向相同正负比例的分类结果进行聚合,并进行特征集合筛选。
首先针对同一个正负样本比例x%,在20000个基础分类器上分别输出20000个分类预测结果,计算信息熵,去掉信息熵大于特定阈值e的特征子集所对应的分类结果,在剩余的结果中采用最大投票率选择正负样本比例为x%的分类结果,这样从l个分类结果确定一个分类结果,最终聚合成a*f个结果。
如图2所示,具体步骤如下:
步骤801、针对该训练样本输出的分类矩阵,采用信息熵对同一正负样本比例下的l个分类器结果进行筛选;
对于各样本输出的分类矩阵,首先采用信息熵对同一分类比例下的20个分类器结果进行筛选;
步骤802、判断信息熵是否高于特定阈值e,如果是,去掉该基础分类器的输出结果;否则,进入步骤803;
如果信息熵高于特定阈值e,说明该组子特征集合下对于类别的区分度较差,则去掉该基础分类器的输出结果。
步骤803、采用最大投票的方式决定同一正负样本比例在相同特征属性集合上的分类结果,从而将分类结果聚合为a*f维。
本实施例中分类结果聚合为1000维。
步骤九、针对筛选后的a*f维特征集合中,采用最大投票的方式确定各行的分类输出结果,得到a种不同正负比例的分类结果。
采用最大投票来决定不同正负比例下,各个子特征属性空间输出的分类结果;a种不同正负比例下的分类结果视作该训练样本的一个a维特征表示;
本实施例中对于任一训练样本,经过l=20次筛选后,得到a*f维特征共20*50=1000维,f=20是针对某种百分比的属性特征采样的次数。通过最大投票的方式,从f=20次采样中得到某百分比的分类结果,最终可以得到该训练样本在a=50种不同正负比例下的分类结果,而各分类结果可以视作该样本的一个50维的特征表示。
步骤十、针对cdr数据的所有训练样本,采用决策树分类模型,运用每个训练样本的a维特征结果构造二级分类器;
步骤十一、对于一条新的测试样本,重复步骤七到步骤九,得到关于该测试数据在各种正负样本比例的a维特征描述,进一步利用二级分类器,得出该测试样本的最终的分类结果。
- 还没有人留言评论。精彩留言会获得点赞!