一种在多核DSP下的数据块多缓冲流水处理方法与流程
本发明属于多核并行计算领域,具体涉及一种在多核dsp下的数据块多缓冲流水处理方法。
背景技术:
目前在多核处理器的数据并行处理技术中,数据块的并行处理方法分为两种:基于共享内存模型的并行处理和基于分布式存储模型并行处理。
在共享内存模型中,并行数据块都存储在同一片内存,多核采用共享的方式进行数据交互和同步,多核间没有数据传输开销,但在并行处理数据块时存在总线竞争和多核cache一致性问题。目前一般采用的方式为设计较为复杂的硬件cache一致性方法,或使用多核软件优化方法提高系统的并行度。如,专利cn103048245a中设计了基于多核cpu的多缓冲数据调度方法,用于数据预取和与预输出,将输入、计算和输出并行,但该方法还是针对共享存储的多线程模型设计,未能彻底解决多核间的总线竞争问题。因此,在数据块访问频率较高的海量数据并行编程模式下,基于共享内存的数据块并行处理已经不能满足需求,并行编程模式都已转换为基于分布式存储模型的并行处理模式。
在分布式存储模型中,并行数据块通过传输部件传递至本地缓冲,多核在本地处理数据块,避免了总线竞争和多核cache一致性问题,极大地提高了数据块并行度,但数据块并行处理效率受限于多核处理器的传输带宽及并行传输能力。为了解决该问题,在嵌入式多核处理器上一般采用两种方式:
提高处理的传输带宽和并行传输能力,如cellbe采用双环四通路并行传输总线、每个加速核具有单独的dma传输控制器;dsp6678采用高速高带宽桥接互联总线,edma具有多通道设计。
计算单元采用双缓冲或多缓冲模型,如cellbe中采用了双缓冲模型来隐藏数据传输延迟,在同一时刻,输入和计算输出作用两个不同的缓冲上,从而实现输入与计算输出的重叠,从而提高并行计算的效率,这些设计虽然从一定程度上提高了并行计算效率,但又带来了以下问题:
由于加速核缓冲区大小有限,双缓冲或多缓冲的使用必然会减小数据块分割粒度,使得系统不能适用于粗粒度的海量数据并行计算,系统配置不够灵活。
多核dsp具有较高的并行传输能力,双缓冲未能充分发挥处理器的传输资源和并行能力,系统并行计算效率未能最大化。
技术实现要素:
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种在多核dsp下的数据块多缓冲流水处理方法,用于在海量数据并行计算的环境下不同粒度的并行计算,充分利用多核并行传输能力,提高海量数据并行计算性能。
本发明采用以下技术方案:
一种在多核dsp下的数据块多缓冲流水处理方法,包括主控核和加速核,所述主控核端和加速核端之间通过请求包队列传输请求,根据任务初始化的请求包,采用多缓冲内存管理方法实现加速核多缓冲内存管理,加速核内存分配,根据该分配原则,确定加速核多缓冲模式的设置,当加速核多缓冲模式设置完成后,开始从请求包队列上获取数据块处理请求包,加速核会根据多缓冲模式,根据多缓冲流水选择方法选择不同的流水线处理方式后,加速核开始执行数据块流水处理,根据数据块流水处理方法,输入流水线的数据块类型进行数据块的输入、计算和输出。
进一步的,所述多缓冲内存管理方法主要在加速核实现,具体步骤如下:
s101、初始化加速核缓冲区,包括任务上下文缓冲区、数据块参数缓冲区、输入数据缓冲区、输出数据缓冲区和重叠缓冲区;
s102、初始化三级流水线结构,包括流水线处理标示、流水线数据块、输入缓冲区、输出缓冲区、重叠缓冲区、输入edma通道和输出edma通道;
s103、根据任务上下文的大小,分配两个任务上下文缓冲区,用于任务上下文的传输和归约;
s104、判断加速核是否需要完成任务上下文初始化,若需要初始化跳转至s115;若不需要初始化跳转至s116;
s105、调用任务上下文初始化函数,设置任务上下文;
s106、根据数据块参数的大小,分配两个数据块参数缓冲区,用户多缓冲的流水处理;
s107、根据之前分配的缓冲区,计算当前剩余的缓冲区大小,即为数据块缓冲区大小;
s108、判断本次数据并行任务是否需要使用重叠缓冲区,若需要使用跳转至s119;若不需要使用跳转至s113;
s109、根据输入缓冲区大小,设置重叠缓冲区和输出缓冲区偏移量;
s110、判断当前的数据缓冲区大小是否大于两倍的输入、重叠、输出缓冲区大小之和,若大于跳转至s111;若小于跳转至s112;
s111、将数据缓冲区模式设置为重叠双缓冲并跳转至s122;
s112、将数据缓冲区模式设置为重叠单缓冲并跳转至s122;
s113、根据输入缓冲区大小,设置输出缓冲区偏移量;
s114、判断当前的数据缓冲区大小是否大于两倍的输入、输出缓冲区大小之和,若大于跳转至s115,若小于跳转至s116;
s115、将数据缓冲区模式设置为四缓冲并跳转至s122;
s116、判断当前数据缓冲区大小是否大于单倍的输入、输出缓冲区大小之和,若大于跳转至s117;若小于跳转至s118;
s117、将数据缓冲区模式设置为双缓冲并跳转至s122;
s118、判断是否大于输入缓冲区大小且输出缓冲区未设置,若大于且未设置跳转至s119;若小于或者已设置跳转至s120;
s119、将数据块缓冲区模式设置为输入单缓冲并跳转至s122;
s120、判断是否大于输出缓冲区大小且输入缓冲区未设置,若大于且未设置则调整至s121;否则跳转至s122;
s121、将数据块缓冲区模式设置为输出单缓冲;
s122、根据输入、输出和重叠缓冲区的大小,设置缓冲区的起始地址。
进一步的,为了适应不同粒度的海量数据并行编程,合理利用加速核缓冲区,需要根据用户对任务缓冲区的设置,动态分配所述加速核缓冲区,具体为:
根据主控核上设置的不同类型缓冲区大小,根据数据缓冲大小和主控核设置的输入、输出和重叠缓冲区大小,部署多缓冲,其中,所述计算得到任务数据缓冲大小为:
数据缓冲区大小=加速核缓冲区大小–应用函数可执行段大小–2*任务上下文大小–2*数据块参数大小。
进一步的,当计算任务完成一次计算只需一个输入或者一个输出时,系统只需要分配一个缓冲区,此时数据缓冲区为单缓冲,其大小限制为:
输入缓冲区大小<=数据缓冲区大小<2*输入缓冲区大小
输入缓冲区大小<=数据缓冲区大小<2*输入缓冲区大小;
当计算任务完成一次计算需要一个输入和一个输出,但输入和输出都较大时,系统只能分配两个缓冲区,此时数据缓冲区为双缓冲,其大小限制为:
输入缓冲区大小+输出缓冲区大小<=数据缓冲区大小<2*(输入缓冲区大小+输出缓冲区大小);
当计算任务完成一次计算需要一个输入和一个输出,但输入和输出都较小时,系统完成计算时可使用两个输入和输出,此时数据缓冲区为双缓冲,其大小限制为:
2*(输入缓冲区大小+输出缓冲区大小)<=数据缓冲区大小;
当计算任务完成一次计算需要一个输入和一个输出,但输入或输出较大,超过双缓冲限制时,此时数据缓冲区为单重叠缓冲,系统可分配一个重叠缓冲,用作输入或者输出,其大小限制为:
输入缓冲区大小+重叠缓冲区大小+输出缓冲区大小<=数据缓冲区大小<2*(输入缓冲区大小+重叠缓冲区大小+输出缓冲区大小);
当计算任务完成一次计算需要一个输入和一个输出,但输入或输出较大,超过四缓冲限制,未超过双缓冲限制时,此时数据缓冲区为双重叠缓冲,系统可分配两个重叠缓冲,用作输入或者输出,其大小限制为:
2*(输入缓冲区大小+重叠缓冲区大小+输出缓冲区大小)<=数据缓冲区大小。
进一步的,所述多缓冲流水选择方法的具体步骤为:
s201、从请求包队列中获取数据块处理请求;
s202、判断数据块处理请求包是否获取成功,若未成功跳转至任务空闲,等待主控核唤醒;若成功跳转至s203;
s203、判断多缓冲区的类型,若为四缓冲跳转至s204;若为双缓冲跳转至s205;若为单缓冲跳转至s206;若为重叠双缓冲跳转至s207;
s204、调用数据块流水线处理函数直接处理数据,并跳转至s208;
s205、调用数据块流水线处理函数,然后再插入一级空流水,并跳转至s208;
s206、调用数据块流水线处理函数,然后再插入两级空流水,并跳转至s208;
s207、判断当前流水线的处理阶段,若为第一阶段调用数据块流水线处理函数直接处理,并跳转至s208,若为第二阶段调用数据块流水线处理函数后再插入一级空流水,并跳转至s208;
s208、统计已完成处理的数据块个数,并跳转至s201。
进一步的,所述多缓冲流水线处理选择方法包括:
四缓冲模式下,输入、计算和输出可并行,当获取完数据块后直接进行流水处理;
双缓冲模式下,计算和输出使用了同一缓冲区,计算和输出不能并行,当数据块流水处理完成后,需要插入一级空流水;
输入单缓冲模式下,整个计算只涉及输入和计算,输入和计算不能并行,当数据块流水处理完成后,需要插入两级空流水;
输出单缓冲模式下,整个计算只涉及计算和输出,计算和输出不能并行,当数据块流水处理完成后,需要插入两级空流水;
重叠双缓冲模式下,重叠缓冲输入和输出重叠,输入和输出不能并行,当连续两个数据块流水处理完成后,需要插入一级空流水;
重叠单缓冲模式下,输入和输出重叠,整个计算的输入、输出无法并行,当数据块流水处理完成后,需要插入两级空流水。
进一步的,所述数据块流水处理方法通过利用edma多通道的并行传输能力,分别为输入和输出分配传输通道,使得数据输入和输出并行,同时再利用多缓冲模式,将数据传输和计算分开,达到三级流水并行,进行数据输入、计算和结果输出处理。
进一步的,所述数据块流水处理方法的具体步骤如下:
s301、根据当前流水线执行的次数,计算当前流水线三个阶段的索引;
s302、根据设定的缓冲区类型,计算输入缓冲区和输出缓冲区和索引号;
s303、判断当前处理的数据块是否为空,若为空跳转至s304,若不为空跳转至s305;
s304、设置一级流水线的处理标示为空,并跳转至s313;
s305、设置一级流水线的处理标示和数据块;
s306、根据之前分配的多缓冲区域和计算的缓冲区索引号,设置一级流水线的数输入缓冲区、输出缓冲区和数据块参数;
s307、根据数据块参数传输列表,将数据块参数拷贝至参数缓冲区中;
s308、判断一级流水线的数据块输入传输列表是否为空,不为空跳转至s309,为空跳转至s310;
s309、获取当前空闲的edma传输通道,根据输入传输列表和通道号,启动edma进行非等待传输,将数据传输至输入缓冲区;
s310、判断一级流水线的数据块重叠传输列表是否为空,不为空跳转至s311;为空跳转至s312;
s311、获取当前空闲的edma传输通道,根据重叠传输列表和通道号,启动edma进行非等待传输,将数据传输至重叠缓冲区;
s312、根据缓冲区类型,更新输入缓冲区的索引号,用于设置下一个数据块缓冲区的索引号;
s313、判断三级流水线处理标示是否为空,若不为空则跳转至s314;若为空则跳转至s318;
s314、判断三级流水线的数据块重叠传输列表是否为空,不为空跳转至s315;为空跳转至s316;
s315、获取当前空闲的edma传输通道,根据重叠传输列表和通道号,启动edma进行非等待传输,将重叠缓冲区中的结果输出至主控核;
s316、判断三级流水线的数据块输出传输列表是否为空,不为空跳转至s317;为空跳转至s318;
s317、获取当前空闲的edma传输通道,根据输出传输列表和通道号,启动edma进行非等待传输,将输出缓冲区中的结果输出至主控核;
s318、判断二级流水的处理标示是否为空,若不为空跳转至s319;若为空跳转至s320;
s319、直接调用计算函数,将任务上下文、数据块参数、输入缓冲、输出缓冲和重叠缓冲传入函数中,开始计算;
s320、统计数据块流水线执行的次数,并结束处理。
进一步的,所述三级流水并行具体为:设定三级流水线,一级为数据输入,二级为计算,三级为结果输入;判断当前流水线是否有数据块,若有数据块分配输入通道,启动edma进行非等待传输;输入启动完成后,查看前两次的流水线中是否有计算结果,若有则分配输出通道,启动edma进行非等待传输;输出启动完成后,查看前一次的流水线中是否具有输入,若有数据则开始计算。
与现有技术相比,本发明至少具有以下有益效果:
本发明一种在多核dsp下的数据块多缓冲流水处理方法,在主控核端和加速核端之间通过请求包队列传输请求,根据任务初始化的请求包,采用多缓冲内存管理方法实现加速核多缓冲内存管理,加速核内存分配,根据该分配原则,确定加速核多缓冲模式的设置,当加速核多缓冲模式设置完成后,开始从请求包队列上获取数据块处理请求包,加速核会根据多缓冲模式,根据多缓冲流水选择方法选择不同的流水线处理方式后,加速核开始执行数据块流水处理,根据数据块流水处理方法,输入流水线的数据块类型进行数据块的输入、计算和输出,采用灵活的多缓冲内存配置节省了用户设置缓冲区模式的操作,用户只需简单配置缓冲区大小,系统可自动设置缓冲区模式,提高了并行开发的效率,数据块灵活设置可保证系统适用于不同粒度的数据并行计算,扩展了并行计算应用的范围,多缓冲的数据块的流水处理则充分利用了多通道并行传输能力,提升了海量数据并行的性能。
进一步的,多缓存内存管理方法在加速核实现可解放主控核的内存管理的负担,保证了主控核的调度效率,同时在加速核端实现减少了主控核和加速核的通信开销,提升了系统的计算效率。
进一步的,动态分配加速核缓冲区可充分利用加速核内存资源,在嵌入式环境提升了资源利用率,同时动态分配可适用于不同数据块粒度的并行算法,提升了并行计算的适用范围。
进一步的,多缓冲流水选择方法充分利用了多通道并行传输能力,提升了海量数据并行性能,而且多缓存流水还充分考虑了数据块粒度问题,在不同数据块调度粒度的基础上充分发挥多缓冲的并行传输能力,进一步提高了计算性能。
进一步的,数据块流水处理方法利用了输入传输、输出传输、缓冲区计算的不相关性,将三者并行,充分利用了硬件并行的能力,提升了加速核的计算性能,从而提升了系统整体的并行加速比。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
图1为四缓冲流水线处理示意图;
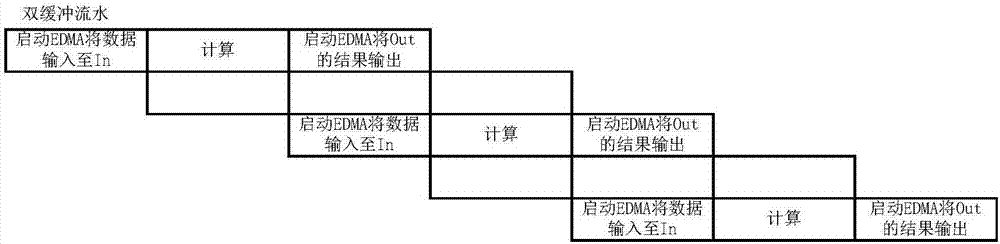
图2为双缓冲流水线处理示意图;
图3为输入单缓冲流水线处理示意图;
图4为输出单缓冲流水线处理示意图。
图5为重叠双缓冲流水线处理示意图;
图6为重叠单缓冲流水线处理示意图;
图7为海量数据并行框架整体结构示意图;
图8为加速核缓冲区分配图;
图9为加速核多缓冲内存管理流程图;
图10为流水线处理方式选择流程图;
图11为数据块三级流水线处理流程图。
具体实施方式
本发明提供了一种在多核dsp下的数据块多缓冲流水处理方法,采用灵活的多缓冲内存管理方法,多缓冲流水选择方法和数据块流水处理方法,旨在提高多核dsp上的海量数据并行计算性能,利用多缓冲内存管理方法和多核dsp下多路并行传输能力,将双缓冲并行处理扩展为数据块多缓冲流水处理,利用软件流水的思想,将以前双缓冲模式下的两级并行扩展为输入、计算和输出三级流水并行,使得在多核dsp环境下,海量数据并行的应用范围更加广泛,计算效率成倍提升。
请参阅图7,整个海量数据流并行框架分为主控核并行中间件和加速核并行支撑系统,主控核并行中间件和加速核并行支撑系统之间通过请求包队列传输请求。
主控核负责创建海量数据并行调度环境、任务和数据块,完成任务和数据块的调度分配;
加速核负责处理具体的任务和数据块。
请参阅图8和图9,根据任务初始化的请求包,实现加速核多缓冲内存管理,加速核内存分配,根据该分配原则,确定加速核多缓冲模式的设置,多核dsp下的数据块多缓冲流水处理方法主要在加速核端实现,具体步骤如下:
(1)初始化加速核上五个缓冲区的大小,包括任务上下文缓冲区、数据块参数缓冲区、输入数据缓冲区、输出数据缓冲区和重叠缓冲区;
(2)初始化三级流水线结构,包括流水线处理标示、流水线数据块、输入缓冲区、输出缓冲区、重叠缓冲区、输入edma通道,输出edma通道;
(3)根据任务上下文的大小,分配两个任务上下文缓冲区,用于任务上下文的传输和归约
(4)判断加速核是否需要完成任务上下文初始化,若需要初始化跳转至(5);若不需要初始化跳转至(6);
(5)调用任务上下文初始化函数,设置任务上下文;
(6)根据数据块参数的大小,分配两个数据块参数缓冲区,用户多缓冲的流水处理;
(7)根据之前分配的缓冲区,计算当前剩余的缓冲区大小,即为数据块缓冲区大小;
(8)判断本次数据并行任务是否需要使用重叠缓冲区,若需要使用跳转至(9);若不需要使用跳转至(13);
(9)根据输入缓冲区大小,设置重叠缓冲区和输出缓冲区偏移量;
(10)判断当前的数据缓冲区大小是否大于两倍的输入、重叠、输出缓冲区大小之和,若大于跳转至(11);若小于跳转至(12);
(11)将数据缓冲区模式设置为重叠双缓冲并跳转至(22);
(12)将数据缓冲区模式设置为重叠单缓冲并跳转至(22);
(13)根据输入缓冲区大小,设置输出缓冲区偏移量;
(14)判断当前的数据缓冲区大小是否大于两倍的输入、输出缓冲区大小之和,若大于跳转至(15);若小于跳转至(16);
(15)将数据缓冲区模式设置为四缓冲并跳转至(22);
(16)判断当前数据缓冲区大小是否大于单倍的输入、输出缓冲区大小之和,若大于跳转至(17);若小于跳转至(18);
(17)将数据缓冲区模式设置为双缓冲并跳转至(22);
(18)判断是否大于输入缓冲区大小且输出缓冲区未设置,若大于且未设置跳转至(19);若小于或者已设置跳转至(20);
(19)将数据块缓冲区模式设置为输入单缓冲并跳转至(22);
(20)判断是否大于输出缓冲区大小且输入缓冲区未设置,若大于且未设置则调整至(21);否则跳转至(22);
(21)将数据块缓冲区模式设置为输出单缓冲;
(22)根据输入、输出和重叠缓冲区的大小,设置缓冲区的起始地址。
灵活的多缓冲内存管理方法主要根据数据块的分割粒度,配置加速核缓冲区,设置流水线的多缓冲模式。加速核缓冲区主要定义了任务计算时需要使用的存储资源,包括任务上下文缓冲区、数据块参数缓冲区、输入缓冲区、输出缓冲区和重叠缓冲区,应用函数所使用的输入、输出数据都位于该缓冲区中。
为了适应不同粒度的海量数据并行编程,合理利用加速核缓冲区,需要根据用户对任务缓冲区的设置,动态分配加速核缓冲区,具体步骤如下:
(1)根据主控核上设置的不同类型缓冲区大小,计算任务数据缓冲大小,其计算方式为:
数据缓冲区大小=加速核缓冲区大小–应用函数可执行段大小–2*任务上下文大小–2*数据块参数大小;
(2)根据数据缓冲大小和主控核设置的输入、输出和重叠缓冲区大小,部署多缓冲;
(3)当计算任务完成一次计算只需一个输入或者一个输出时,系统只需要分配一个缓冲区,此时数据缓冲区为单缓冲,其大小限制为:
输入缓冲区大小<=数据缓冲区大小<2*输入缓冲区大小
输入缓冲区大小<=数据缓冲区大小<2*输入缓冲区大小;
(4)当计算任务完成一次计算需要一个输入和一个输出,但输入和输出都较大时,系统只能分配两个缓冲区,此时数据缓冲区为双缓冲,其大小限制为:
输入缓冲区大小+输出缓冲区大小<=数据缓冲区大小<2*(输入缓冲区大小+输出缓冲区大小);
(5)当计算任务完成一次计算需要一个输入和一个输出,但输入和输出都较小时,系统完成计算时可使用两个输入和输出,此时数据缓冲区为双缓冲,其大小限制为:
2*(输入缓冲区大小+输出缓冲区大小)<=数据缓冲区大小;
(6)当计算任务完成一次计算需要一个输入和一个输出,但输入或输出较大,超过双缓冲限制时,此时数据缓冲区为单重叠缓冲,系统可分配一个重叠缓冲,用作输入或者输出,其大小限制为:
输入缓冲区大小+重叠缓冲区大小+输出缓冲区大小<=数据缓冲区大小<2*(输入缓冲区大小+重叠缓冲区大小+输出缓冲区大小);
(7)当计算任务完成一次计算需要一个输入和一个输出,但输入或输出较大,超过四缓冲限制,未超过双缓冲限制时,此时数据缓冲区为双重叠缓冲,系统可分配两个重叠缓冲,用作输入或者输出,其大小限制为:
2*(输入缓冲区大小+重叠缓冲区大小+输出缓冲区大小)<=数据缓冲区大小。
请参阅图10,当加速核多缓冲模式设置完成后,开始从请求包队列上获取数据块处理请求包,加速核会根据多缓冲模式,选择不同的流水线处理方式,具体步骤如下:
(1)从请求包队列中获取数据块处理请求。
(2)判断数据块处理请求包是否获取成功,若未成功跳转至任务空闲,等待主控核唤醒;若成功跳转至(3)。
(3)判断多缓冲区的类型,若为四缓冲跳转至(4);若为双缓冲跳转至(5);若为单缓冲跳转至(6);若为重叠双缓冲跳转至(7)。
(4)调用数据块流水线处理函数直接处理数据,并跳转至(8)。
(5)调用数据块流水线处理函数,然后再插入一级空流水,并跳转至(8)。
(6)调用数据块流水线处理函数,然后再插入两级空流水,并跳转至(8)。
(7)判断当前流水线的处理阶段,若为第一阶段调用数据块流水线处理函数直接处理,并跳转至(8);若为第二阶段调用数据块流水线处理函数后再插入一级空流水,并跳转至(8)。
(8)统计已完成处理的数据块个数,并跳转至(1)。
多缓冲流水线选择方法主要是根据不同的多缓冲模式,选择不同的流水线处理过程。通过分析不同多缓冲模式下的存储资源,确定输入、计算、输出之间的相关性,设置不同的流水线处理方式。多缓冲流水线处理选择方法原理如下:
(1)四缓冲模式下,输入、计算和输出可并行,当获取完数据块后直接进行流水处理,如图1所示。
(2)双缓冲模式下,计算和输出使用了同一缓冲区,计算和输出不能并行,当数据块流水处理完成后,需要插入一级空流水,如图2所示。
(3)输入单缓冲模式下,整个计算只涉及输入和计算,输入和计算不能并行,当数据块流水处理完成后,需要插入两级空流水,如图3所示。
(4)输出单缓冲模式下,整个计算只涉及计算和输出,计算和输出不能并行,当数据块流水处理完成后,需要插入两级空流水,如图4所示。
(5)重叠双缓冲模式下,重叠缓冲输入和输出重叠,输入和输出不能并行,当连续两个数据块流水处理完成后,需要插入一级空流水,如图5所示。
(6)重叠单缓冲模式下,输入和输出重叠,整个计算的输入、输出无法并行,当数据块流水处理完成后,需要插入两级空流水,如图6所示。
请参阅图11,在选择完不同的流水处理方式后,加速核开始执行数据块流水处理,它根据输入流水线的数据块类型,进行数据块的输入、计算和输出,具体步骤如下:
(1)根据当前流水线执行的次数,计算当前流水线三个阶段的索引
(2)根据设定的缓冲区类型,计算输入缓冲区和输出缓冲区和索引号
(3)判断当前处理的数据块是否为空,若为空跳转至(4);若不为空跳转至(5)
(4)设置一级流水线的处理标示为空,并跳转至(13)
(5)设置一级流水线的处理标示和数据块
(6)根据之前分配的多缓冲区域和计算的缓冲区索引号,设置一级流水线的数输入缓冲区、输出缓冲区和数据块参数。
(7)根据数据块参数传输列表,将数据块参数拷贝至参数缓冲区中
(8)判断一级流水线的数据块输入传输列表是否为空,不为空跳转至(9);为空跳转至(10)
(9)获取当前空闲的edma传输通道,根据输入传输列表和通道号,启动edma进行非等待传输,将数据传输至输入缓冲区。
(10)判断一级流水线的数据块重叠传输列表是否为空,不为空跳转至(11);为空跳转至(12)
(11)获取当前空闲的edma传输通道,根据重叠传输列表和通道号,启动edma进行非等待传输,将数据传输至重叠缓冲区。
(12)根据缓冲区类型,更新输入缓冲区的索引号,用于设置下一个数据块缓冲区的索引号
(13)判断三级流水线处理标示是否为空,若不为空则跳转至(14);若为空则跳转至(18)
(14)判断三级流水线的数据块重叠传输列表是否为空,不为空跳转至(15);为空跳转至(16)
(15)获取当前空闲的edma传输通道,根据重叠传输列表和通道号,启动edma进行非等待传输,将重叠缓冲区中的结果输出至主控核。
(16)判断三级流水线的数据块输出传输列表是否为空,不为空跳转至(17);为空跳转至(18)
(17)获取当前空闲的edma传输通道,根据输出传输列表和通道号,启动edma进行非等待传输,将输出缓冲区中的结果输出至主控核。
(18)判断二级流水的处理标示是否为空,若不为空跳转至(19);若为空跳转至(20)
(19)直接调用计算函数,将任务上下文、数据块参数、输入缓冲、输出缓冲和重叠缓冲传入函数中,开始计算。
(20)统计数据块流水线执行的次数,并结束处理。
数据块流水处理方法主要根据当前流水线输入的数据块,进行数据输入、计算和结果输出处理。通过利用edma多通道的并行传输能力,分别为输入和输出分配传输通道,使得数据输入和输出并行,同时再利用多缓冲模式,将数据传输和计算分开,最终达到三级流水并行的效果,其步骤如下:
(1)设定三级流水线,一级为数据输入,二级为计算,三级为结果输入;
(2)判断当前流水线(一级流水)是否有数据块,若有数据块分配输入通道,启动edma进行非等待传输;
(3)输入启动完成后,查看前两次的流水线(三级流水)中是否有计算结果,若有则分配输出通道,启动edma进行非等待传输;
(4)输出启动完成后,查看前一次的流水线(二级流水)中是否具有输入,若有数据则开始计算。
以上内容仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明权利要求书的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!