一种基于众包技术的分类模型训练方法与流程
本发明涉及的是一种分类模型训练方法。
背景技术:
目前,在机器学习中监督学习的框架下,训练分类模型需要预先收集一组带有标注信息的数据样本。所收集训练数据的数量和质量直接决定了分类模型的泛化性能。在传统的训练数据收集过程中,需要具有专业领域知识的专家提供数据样本对应的唯一正确标注信息,用于保证训练所得的分类模型具有良好的泛化性能。
这一传统做法面临的挑战在于,现实任务中具有专业背景的人员较少,获取样本标注信息的花费较高、时间较长。因而,随着网络技术和数据存储技术的发展,利用众包技术为训练样本快速获取大量廉价标注信息,成为降低标注获取过程中的时间和经济代价的有效途径之一。
众包环境下,训练数据的标注获取任务并非由传统的专业人员来完成,而是以自由自愿的形式外包给非特定的大众网络来完成的,即非专业个人或开源个体以独立或协作的方式快速低价地完成标注任务。由于基于众包技术获取的标注信息来自多个在线的网络用户,因此难以保证所收集标注信息的质量,同时,由于缺少专业人士提供的正确标注信息作为“金标准”,也难以对这些用户的经验及其完成标注任务的准确度进行衡量。直接使用众包标注信息训练分类模型,会严重影响分类模型的泛化性能。
技术实现要素:
本发明的目的在于提供一种能够克服低质量标注信息对模型训练过程的影响,保证在众包环境下以最小标注代价学习一个高泛化能力的分类模型的基于众包技术的分类模型训练方法。
本发明的目的是这样实现的:
在所收集到的m个样本及由k个用户提供的众包标注信息为
步骤一,从所收集的样本及其众包标注数据中随机抽取n个样本及其对应的众包标注信息
步骤二,构建训练数据集
步骤三,在训练数据集
步骤四,第j个用户在类别c上提供的一组标注信息
其中,
步骤五,根据为样本xi提供标注信息的多个用户的标注水平,该样本用于训练的标注信息通过下式估计
步骤五,使用分类模型对剩余m-n个样本所属类别进行预测,并计算每个样本对应的分类模型期望误差,如下
其中,u表示剩余样本组成的集合,i(d,x)表示将样本加入训练集后分类模型的误差;
步骤六,选择p(y|x*;w)>0.5对应的类别,并将该类别上标注水平最高的用户为样本x*提供的标注信息y*加入训练数据集
步骤七,重复进行步骤三至步骤六,直至分类模型的泛化精度或者训练样本的数量达到既定标准为止。
本发明还可以包括:
1、第j个用户在类别c上的标注水平
在训练样本及其众包标注集合
其中
p(yi|xi;w)为分类模型对训练样本所属类别的概率估计值,根据所估计的
2、将样本加入训练集后分类模型的误差i(d,x)的计算方法为:
其中,u'表示将该样本从剩余样本集删除后的样本集合;同时,当样本x添加标注信息并加入训练集后,学习所得的分类模型对该样本的预测概率为
本发明提出了一种基于众包技术的分类模型训练方法。从单个用户提供的标注信息中估计该用户的标注水平,根据多个用户提供标注信息的质量来确定训练分类模型所使用的标注信息,降低低水平用户提供低质量标注信息对分类模型训练的负面影响。选择部分样本构建训练数据集,提高分类模型的泛化性能,保证了实际任务中分类模型的应用效果。
本发明的目的是利用众包技术获取的多个低质量标注信息,以最小的标注代价学习一个高泛化能力的分类模型。本发明的有益效果:本发明利用了众包用户为训练样本提供的多个标注信息来估计单个用户在每个类别上提供标注的水平,将多个用户的标注水平作为先验知识,估计训练分类模型使用的样本标注信息,克服了低质量标注信息对模型训练过程的影响。根据分类模型对剩余样本的类别预测结果,选择使分类模型期望误差最小的样本加入训练样本集,同时,选择选择该类别上标注水平最高的用户提供的标注信息加入训练标注信息集,克服了低质量样本对分类模型训练的干扰。从而,保证了在众包环境下以最小标注代价学习一个高泛化能力的分类模型。
附图说明
图1为本发明的流程图;
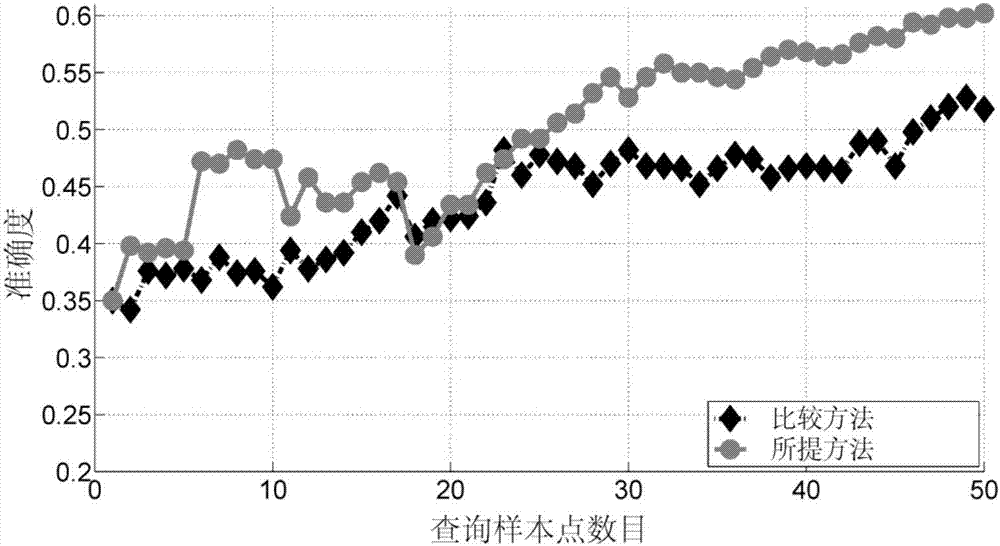
图2为本发明与使用正确标注训练分类模型的精度比较结果;
图3为本发明估计的用户标注水平与用户真实标注水平的比较结果。
具体实施方式
下面举例对本发明做更详细的描述。
根据本发明中基于众包技术的分类模型训练过程的流程图,具体步骤如下:
1)从所收集数据中随机抽取n(n<m)个样本及对应的众包标注信息
2)确定训练样本xi对应的标注信息yi,当
3)在使用训练样本及其标注信息学习一个参数为w的分类模型。
4)在训练样本及其众包标注集合
其中,
其中:
p(yi|xi;w)为分类模型对训练样本所属类别的概率估计值。根据所估计的
5)根据为样本xi提供标注信息的多个用户的标注水平,更新该样本用于训练的标注信息:
6)根据使用分类模型对剩余m-n个样本所属类别进行预测,并计算每个样本的对应的分类模型期望误差,如下:
其中:
u表示剩余样本组成的集合,u'表示将该样本从剩余样本集删除后的样本集合。同时,当样本x添加标注信息并加入训练集后,学习所得的分类模型对该样本的预测概率为
7)选择p(y|x*;w)>0.5对应的类别,并将该类别上标注水平最高的用户为样本x*提供的标注信息y*加入训练数据集
8)重复进行步骤三至步骤六,直至分类模型的泛化精度或者训练样本的数量达到既定标准为止。
由于在分类模型的训练过程中,所选取的样本的众包标注信息仅由该类别上标注水平最高的标注者提供,随后使用标注者的水平作为先验知识,校正了训练样本所使用的标注信息,保证了训练分类模型时所使用标注信息的质量,降低了低水平标注者所提供标注信息对分类模型训练过程的负面影响。其次,在分类模型训练过程中,针对分类模型来选取所用训练样本,保证了分类模型可以充分利用样本包含的信息。
在对本算法的仿真过程中,共使用了5个用户来模拟众包标注信息,训练数据集包含了40个训练样本,未标注数据集中包含了1000个未标注样本,测试数据集中包含了1000条样本。图2显示的是所提出众包标注条件下和正确标注条件下分别学习分类模型的roc精度比较结果。图3显示的是所提出的方法根据众包标注信息估计得到的用户水平和用户真实水平的比较结果。
虽然已经结合了具体实施方式对本发明的一种基于众包技术的分类模型训练方法进行了说明,但是本发明不限于此。在本发明的精神和原理下做出的各种变型均应包含在本发明的权利要求书限定的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!