一种双层网络聚类系数的计算方法与流程
本发明属于网络信息处理领域,特别适用于特定功能的网络数据处理,具体涉及双层网络节点聚类系数的计算方法。
背景计术
20世纪60年代,两位匈牙利数学家erdos和renyi建立了随机图理论,被公认为是在数学上开创了复杂网络理论的系统性研究。之后的40年里,人们一直讲随机图理论作为复杂网络研究的基本理论。1998年,watts及其导师strogatz在nature上的文章《collectivedynamicsofsmall-worldnetworks》揭示了复杂网络的小世界性质。实际多层复杂系统通常是由多个相互作用且相互依赖的复杂网络组成,kurant和thiran分析现实社会中存在的多层复杂系统,率先引入一个多层复杂网络模型。随后,越来越多关于复杂网络的性质被发掘出来,其中很重要的一项研究是2002年girvan和newman在pnas上的一篇文章《communitystructureinsocialandbiologicalnetworks》,指出复杂网络中普遍存在着聚类特性,每一个类称之为一个社团(community),并提出了一个发现这些社团的算法。从此研究者们对复杂网络中的社团发现问题进行了大量研究,产生了大量的算法。
现阶段复杂网络的节点聚类系数主要有如下几种计算方法:
(1)kernighan-lin算法
复杂网络的研究与图论有密不可分的关系,复杂网络的研究者们继承了图论的研究策略。计算网络的聚类系数需要我们把一个网络划分成多个社团,类似于图论中把一个图剖分成多个图,而图的剖分问题是图论中一个比较难的问题。文献“anefficientheuristicprocedureforpartitioninggraphs.”(kernighan&lin,bellsystemtechnicaljournal49:291–307,1970.)从比较简单的情况入手:图的二剖分,即把一个图分成两个(一般要求大小相等)的图。kernighan-lin算法的思想:不断交换两个子图中的点,使得两个子图之间的边尽可能地少。这种算法常常需要制定子图的个数,甚至每个子图的大小,不同类型的子图结果不同,算法较为复杂。
(2)newman算法
对于复杂网络的计算,除了图论思想以外,研究者还引入了凝聚法的思想,通过寻找社团“最中心”的边,不断地把最相似的两个点聚到一起,从点聚到小社团,再聚成大社团,其中最具代表性的就是newman算法。newman在文献“fastalgorithmfordetectingcommunitystructureinnetworks.”(newman.phy.rev.e,2004)中不断地选择是模块度增长最大的两个社团进行合并,不仅提高了计算速度,并且有效的简化了计算步骤。newman算法优点是简单,限制少,不需要预先指定社团个数,可以发现社团的层次关系。缺点是缺乏全局目标函数;两个点一旦合并,就永远在一个社团中了,无法撤消;另外,这种算法往往对单个的点比较敏感。
(3)gn算法
研究者针对网络的拓扑特点,提出了分裂法思想:通过找出最有可能位于社团之间的边,把这些边去掉,就自然产生了不同的社团,ng算法就应运而生。在文献“communitystructureinsocialandbiologicalnetworks”(girvan&newman,pnas,2002)中首先给出介数的定义,一个边的介数是指通过该边的最短路的条数。直观上,社团之间的边有较高的介数,而社团内部的边介数相对较小,这样,通过逐个去掉这些高介数的边,社团结构就会逐步显现出来。gn算法所采用的分裂思想,与凝聚法思想是对应的,一个自下而上,一个自上而下,一个不断把点连在一起,一个不断去边把点分开。这就导致了gn算法同样具有:缺乏全局目标函数、节点分配无法撤消以及对单个的点比较敏感的缺点。
(4)谱算法
首先给出一个概念——图的laplacian矩阵(l-矩阵)。设a为图的邻接矩阵;d为一个对角阵(对角元素为点i的度),则图的laplacian矩阵l=d-a。关于l-矩阵,有很多性质,如:(1)矩阵的每一行的元素之和为0,由此可以知道该矩阵至少一个0特征值,并且0特征值对应的特征向量为全1向量(1,1,...,1)。(2)0特征向量的个数与连通分支的个数相同;如果一个图是连通的,那么其laplacian矩阵只有一个0特征值,其余特征值都是正的。(3)不同特征值的特征向量正交的。所谓谱,就是指矩阵的特征值。谱算法就是利用邻接矩阵或者拉普拉斯矩阵的特征向量,将点投影到一个新的空间,在新的空间用传统的聚类方法来聚类。文献“acomparisonofspectralclusteringalgorithms.”(vermad,meilam,technicalreport,2003.uwcsetechnicalreport03-05-01)给出了谱算法的基础框架。
谱算法的计算瓶颈是计算矩阵的特征值,只需要少数的几个特征向量我们就可以得到很好的网路聚类情况,所以只需要计算最大的几个特征值即可。但是在具体实现过程中,不同的算法在数据集矩阵z的表示上存在着不同,如何选择可靠的数据集矩阵是一个值得研究的问题。
技术实现要素:
本发明以复杂网络中的双层网络为应用对象,根据现有的复杂网络聚类计算方法,提出一个新的双层网络聚类系数的计算方法。本方法将利用图论的相关思想,将双层网络拓扑结构以投影网络的方式进行分析简化,并通过投影将点投影到一个新的空间,在新的空间用传统的聚类方法来计算聚类。
为实现上述目的,本发明采用的技术方案为一种双层网络聚类系数的计算方法,包含以下步骤:
(1)基于molloy-reed配置模型方式产生双层网络g;
(2)确定投影网络;
(3)确定投影网络下节点聚类关系;
(4)给出聚类计算公式:
进一步,上述步骤1具体包括:假定原始网络有m条边,首先将该网络拆成m个子图,每个子图为两个节点{i,j}配对的形式,然后随机选取一个子图,并将子图中度值为ki的节点i视为起始节点,随机地在网络中挑选ki-1个子图,并且每个子图中至少含有一个度值为ki的节点,最后将这ki个节点重新组合成一个新的度为ki的节点,持续随机选取一个分支节点作为起始节点重复上述过程,直到将所有的子图都重新组合。
进一步,上述步骤2中投影方式具体为:根据双层网络的结构特点,将a层的投影作为投影参照面,a层的投影集合为xg,因为是参照面,集合仅仅包含a层网络内部节点连接情况
进一步,上述步骤3中在计算双层聚类系数时,不仅要考虑层内连接还要考虑耦合网络的层间连接,写关系将在投影网络中以以下关系式给出:
3.1:对于每个节点i,令n(i)为表示投影网络p中节点i的邻居节点集合,α∈{1,…,n};
3.2:令nα(i)=n(i),
本发明优点为:实现了双层网络拓扑结构的投影简化,改进了现有双层网络的聚类计算方法,计算复杂度低,容易实现。
附图说明
图1是将双层网络拓扑结构,投影到投影网络的示意图。
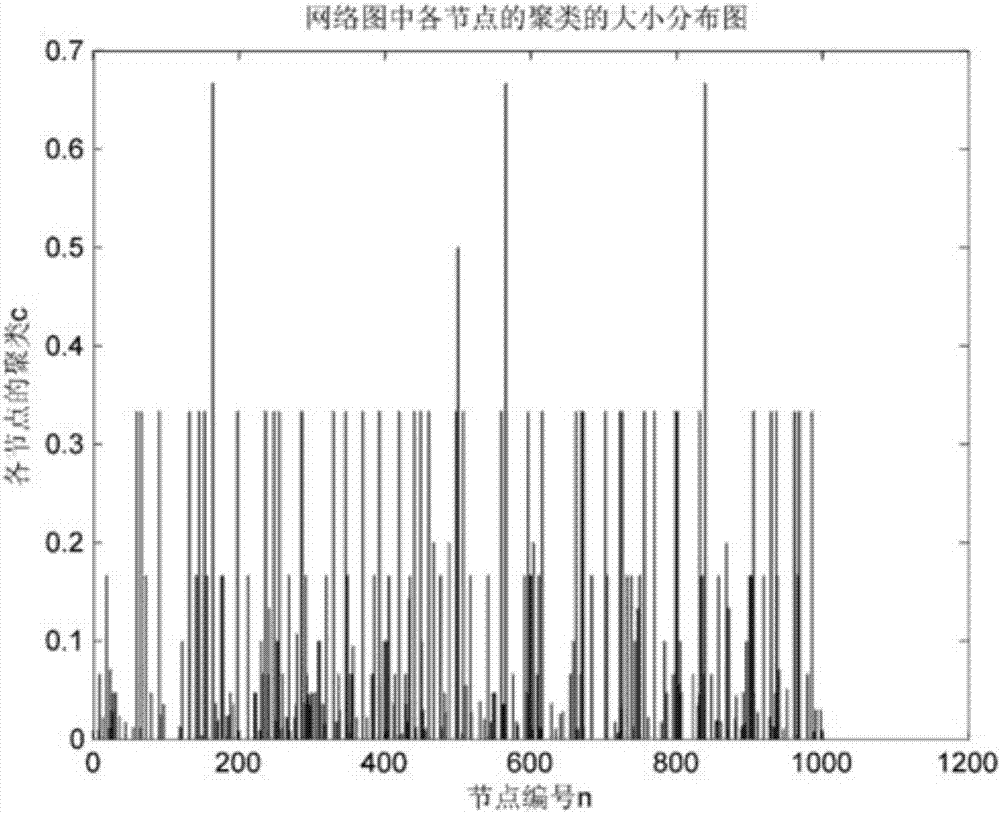
图2是传统k-means算法计算出的双层网络节点聚类分布图。
图3是本发明方法计算出的双层网络节点聚类分布图。
图4是在sir传播模型下,分别以k-means聚类大节点、k-means聚类小节点、发明方法聚类大节点、发明方法聚类小节点这四种不同情况作为初始节点,仿真出的传播节点随时间步数的变化结果图。
图5是在sir传播模型下,分别以k-means聚类大节点、k-means聚类小节点、发明方法聚类大节点、发明方法聚类小节点这四种不同情况作为初始节点,仿真出的传播节点变化速度随时间步数的变化结果图。
具体实施方式
现结合附图对本发明作进一步详细的说明。
本发明提出一种双层网络聚类系数的计算方法,以复杂网络中的双层网络为应用对象,根据现有的复杂网络聚类计算方法,提出一个新的双层网络聚类系数的计算方法。本方法将利用图论的相关思想,将双层网络拓扑结构以投影网络的方式进行分析简化,并通过投影将点投影到一个新的空间,在新的空间用传统的聚类方法来计算聚类。
(1)基于molloy-reed配置模型方式产生双层网络g。
假定原始网络有m条边,首先我们将该网络拆成m个子图,每个子图为两个节点{i,j}配对的形式。然后随机选取一个子图,并将子图中度值为ki的节点i视为起始节点。随机的在网络中挑选ki-1个子图,并且每个子图中至少含有一个度值为ki的节点,最后将这ki个节点重新组合成一个新的度为ki的节点。持续随机选取一个分支节点作为起始节点重复上述过程,直到将所有的子图都重新组合。
(2)确定投影网络
投影方式如下:根据双层网络的结构特点,我们将a层的投影作为投影参照面,a层的投影集合为xg,因为是参照面集合仅仅包含a层网络内部节点连接情况
其中:
(3)确定投影网络下节点聚类关系
我们在计算双层聚类系数时,不仅要考虑层内连接还要考虑耦合网络的层间连接,写关系将在投影网络中以以下关系式给出:1.对于每个节点i,令n(i)为表示投影网络p中节点i的邻居节点集合,α∈{1,…,n}。2.令nα(i)=n(i),
(4)给出聚类计算公式:
仿真实验
为了验证本发明一种网络节点聚类的计算方法的有效性,采用传统k-means聚类计算方式和本文计算方式进行了仿真实验。根据双层网络的拓扑结构特性,网络节点聚类系数越高,它与相邻节点联系越加紧密,病毒(或信息)的传播若以高聚类节点为初始节点的传播情况必然会与以低聚类节点为初始节点的传播情况有差异,根据差异的大小,我们即可直观感受到本发明方法与传统k-means算法的优劣。
实验内容如下:
step1构建双层网络g
step2分别通过传统k-means计算方法和本发明方法计算出双层网络中节点的聚类系数,将节点按照计算出的聚类系数排序。
step3采用sir病毒传播模型,分别以高聚类节点和低聚类节点为传播初始节点,进行病毒传播仿真实验。
实验结果如图4、图5示。实验结果显示本发明方法聚类大和聚类小两种情况,无论是从传播节点比例还是传播节点的变化速率来看,它们所导致的差异非常明显,与传统k-means方法有明显改进。实验结果表明,本方法对于双层网络的聚类系数计算更加合理可靠。
- 还没有人留言评论。精彩留言会获得点赞!