一种电子产品激活量预测方法及一种服务器集群与流程
本发明涉及数据处理,尤其涉及一种电子产品激活量预测方法及一种服务器集群。
背景技术:
个人计算机(pc)、手机、平板电脑等电子产品为贵重的硬件产品,其库存积压,不论是整机库存还是部件库存,都会严重影响资金流动,甚至拖垮企业的资金链。降低库存最有效的方式就是:第一,准确把握市场的需求,使得生产量与销售量的差(即库存)最小;第二,提前把握市场的需求,通过在采购提前期前给出预测值,来指导科学合理的采购。那么如何度量市场的需求以降低库存呢?由于电子产品的智能性,能够将电子产品的激活数据直接上报,使得电子产品的激活量直接、准确的反映了市场需求量,所以对电子产品激活量准确的预测,尤为重要。
现有技术中,对电子产品激活量的预测,均是通过单一的回归模型或时间序列分析方法进行预测,但是,前者无法拟合数据的时间规律,即,无法拟合出电子产品激活量随时间变化的规律,后者无法学习相关因子随时间变化的影响力,即,无法学习影响电子产品激活量的相关因子(例如,促销活动、代言活动等)随时间变化的影响力,所以其效果均不稳定,且准确率非常低。
技术实现要素:
本发明提供一种电子产品激活量预测方法及一种服务器集群,能够准确的预测电子产品激活量。
本发明提供了一种电子产品激活量预测方法,包括:
获取第一激活量数据和影响第一激活量数据的至少一个第一因子数据;
对所述第一激活量数据和所述至少一个第一因子数据分别进行时间序列化;
对时间序列化后的数据进行时间规律拆解,得到第二激活量数据,所述第二激活量数据包括电子产品激活量未受所述至少一个第一因子数据影响情况下随时间的变化趋势数据;
判断所述变化趋势数据是否具有时间规律;
如果所述变化趋势数据具有时间规律,将所述变化趋势数据进行特征化处理生成第二因子数据,将所述至少一个第一因子数据与第二因子数据输入预设模型进行学习,以对预定时间的电子产品激活量进行预测。
作为优选,还包括,
如果所述变化趋势数据不具有时间规律,则将所述至少一个第一因子数据输入预设模型进行学习,以对预定时间的电子产品激活量进行预测。
作为优选,所述至少一个第一因子数据包括价格因子数据、市场活动因子数据、产品质量因子数据、舆论因子数据、竞争产品因子数据中的一个或多个。
作为优选,所述舆论因子数据包括情感指数因子数据,所述情感指数因子数据基于正面舆论评价信息数量以及负面舆论评价信息数量确认。
作为优选,对所述至少一个第一因子数据进行时间序列化包括对价格因子数据进行时间序列化,并且在对所述价格因子数据进行时间序列化前,对所述价格因子数据进行离散化。
作为优选,将所述变化趋势数据进行特征化处理包括,将所述变化趋势数据的依赖时长构造成一维特征或多维特征作为所述第二因子数据。
作为优选,所述第一因子数据与所述第二因子数据的权重相等。
本发明还公开了一种服务器集群,包括至少一个处理器、至少一个存储器,所述至少一个存储器能够存储被所述至少一个处理器处理的指令,所述至少一个处理器配置为执行所述指令以:
获取第一激活量数据和影响第一激活量数据的至少一个第一因子数据;
对所述第一激活量数据和所述至少一个第一因子数据分别进行时间序列化;
对时间序列化后的数据进行时间规律拆解,得到第二激活量数据,所述第二激活量数据包括电子产品激活量未受所述至少一个第一因子数据影响情况下随时间的变化趋势数据;
判断所述变化趋势数据是否具有时间规律;
如果所述变化趋势数据具有时间规律,将所述变化趋势数据进行特征化处理生成第二因子数据,将所述至少一个第一因子数据与第二因子数据输入预设模型进行学习,以对预定时间的电子产品激活量进行预测。
作为优选,所述至少一个处理器配置为进一步执行所述指令以:
如果所述变化趋势数据不具有时间规律,则将所述至少一个第一因子数据输入预设模型进行学习,以对预定时间的电子产品激活量进行预测。
作为优选,所述至少一个第一因子数据包括价格因子数据、市场活动因子数据、产品质量因子数据、舆论因子数据、竞争产品因子数据中的一个或多个。
作为优选,所述舆论因子数据包括情感指数因子数据,所述情感指数因子数据基于正面舆论评价信息数量以及负面舆论评价信息数量确认。
作为优选,对所述至少一个第一因子数据进行时间序列化包括对价格因子数据进行时间序列化,并且在对所述价格因子数据进行时间序列化前,对所述价格因子数据进行离散化。
作为优选,将所述变化趋势数据进行特征化处理包括,将所述变化趋势数据的依赖时长构造成一维特征或多维特征作为所述第二因子数据。
作为优选,所述第一因子数据与所述第二因子数据的权重相等。
与现有技术相比,本发明的有益效果在于:通过利用时间序列法将第一激活量数据拆解为不受第一因子数据影响的第二激活量数据,并将第二激活量数据特征化处理后与第一因子数据输入集成学习模型进行学习,预测预定时间的电子产品激活量,预测的稳定性和准确率都有明显的提升,训练误差和测试误差都有明显的降低。
附图说明
图1是本发明一个实施例的电子产品激活量预测方法的流程图;
图2是本发明另一实施例的电子产品激活量预测方法的流程图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细描述,但不作为对本发明的限定。
此处参考附图描述本发明的各种方案以及特征。
应理解的是,可以对此处发明的实施例做出各种修改。因此,上述说明书不应该视为限制,而仅是作为实施例的范例。本领域的技术人员将想到在本发明的范围和精神内的其他修改。
包含在说明书中并构成说明书的一部分的附图示出了本发明的实施例,并且与上面给出的对本发明的大致描述以及下面给出的对实施例的详细描述一起用于解释本发明的原理。
通过下面参照附图对给定为非限制性实例的实施例的优选形式的描述,本发明的这些和其它特性将会变得显而易见。
还应当理解,尽管已经参照一些具体实例对本发明进行了描述,但本领域技术人员能够确定地实现本发明的很多其它等效形式,它们具有如权利要求所述的特征并因此都位于借此所限定的保护范围内。
当结合附图时,鉴于以下详细说明,本发明的上述和其他方面、特征和优势将变得更为显而易见。
此后参照附图描述本发明的具体实施例;然而,应当理解,所发明的实施例仅仅是本发明的实例,其可采用多种方式实施。熟知和/或重复的功能和结构并未详细描述以避免不必要或多余的细节使得本发明模糊不清。因此,本文所发明的具体的结构性和功能性细节并非意在限定,而是仅仅作为权利要求的基础和代表性基础用于教导本领域技术人员以实质上任意合适的详细结构多样地使用本发明。
本说明书可使用词组“在一种实施例中”、“在另一个实施例中”、“在又一实施例中”或“在其他实施例中”,其均可指代根据本发明的相同或不同实施例中的一个或多个。
如图1所示,本发明公开的一个实施例中,电子产品激活量预测方法,包括:
s1,获取第一激活量数据和影响第一激活量数据的至少一个第一因子数据。
其中,第一激活量数据是统计的用户激活的电子产品的数据,其是用户实际购买电子产品的数量的一个反映,用户实际购买的电子产品的数量越多,第一激活量数据越大,可以根据第一激活量数据来判断用户实际购买电子产品的数量,也就是可以根据第一激活量数据来判断销售的电子产品的数量。
影响第一激活量数据的至少一个第一因子数据可以包括价格因子数据、市场活动因子数据、产品质量因子数据、舆论因子数据、竞争产品因子数据中的一个或多个。价格因子数据可以是厂家规定的电子产品的价格,也可以是售卖平台的售价,价格因子数据可以是变化的,例如,厂家为了多卖电子产品而对电子产品进行降价。市场活动因子数据可以是促销活动中花费的人力成本或物力成本,也可以是代言活动中名人的出场费用或代言场所的租赁费用或者代言场所的观众数量。产品质量因子数据可以包括返修率。舆论因子数据可以包括电子产品的讨论热度或者情感指数因子数据。另外,第一因子数据还可以包括竞品活动因子数据,竞品活动因子数据可以是作为竞争对手的厂家做促销活动或代言活动的数据。
s2,对第一激活量数据和至少一个第一因子数据分别进行时间序列化。
对第一激活量数据进行时间序列化可以是对第一激活量数据按照时间顺序进行排列,例如,电子产品的激活量按照日期的排列数据。
对第一因子数据进行时间序列化可以是对第一因子数据按照时间顺序进行排列。例如,对价格因子数据进行时间序列化可以是厂家规定的价格按照日期的排列数据,如果厂家在某段时间降低价格,可以在时间序列化后的价格因子数据中体现出来。
另外,对于代言活动中名人的出场费用的时间序列化可以是将出场费用平均到代言活动期间的每一天,再按照此段期间中的每一天对应平均化后的出场费用。租赁费用或观众数量的时间序列化类似于出场费用的时间序列化,在此不再赘述。对于竞品活动因子数据进行时间序列化也与之类似。
对于返修率的时间序列化可以是返修率按照日期的排列数据。而对于讨论热度的时间序列化可以是利用爬虫技术将人们在网上的讨论进行抓取,并计算关于电子产品的讨论的数量,最后对应日期进行排列。对于舆论因子数据中的情感指数因子数据,可以是基于正面舆论评价信息数量以及负面舆论评价信息数量确认。具体可以是,通过对正面和负面的舆论评价信息进行统计,并根据(n正-n负)*10/(n正+n负)计算得到情感指数,并对情感指数按照时间进行排列。其中,n正为统计的当天的正面舆论评价信息的数量,n负为统计的当天的负面舆论评价信息的数量。
s3,对时间序列化后的数据进行时间规律拆解,得到第二激活量数据,第二激活量数据包括电子产品激活量未受所述至少一个第一因子数据影响情况下随时间的变化趋势数据。
其中,对时间序列化后的数据进行时间规律拆解可以是利用时间序列分析方法对时间序列化后的数据进行时间规律拆解,具体的,可以是利用时间序列分析方法中的stl(seasonalandtrenddecompositionusingloess‘)分解方法,stl分解方法是以鲁棒局部加权回归作为平滑方法的时间序列分解方法,从而可以得到第二激活量数据,其中第二激活量数据包括电子产品激活量未受至少一个第一因子数据影响情况下随时间的变化趋势数据,也即是,第二激活量数据是从第一激活量数据中将第一因子数据的影响剥离后的随时间变化的电子产品的激活量的数据,随时间变化的趋势数据包括随时间变化的长期趋势数据和随时间变化的短期趋势数据。其中,随时间变化的长期趋势数据可以是电子产品激活量随时间变化的长期趋势数据,例如,在一年内随着时间变化的长期趋势数据。随时间变化的短期趋势数据可以是电子产品激活量随着时间变化的短期趋势数据,例如,在7天之内的变化。
s4,判断变化趋势数据是否具有时间规律。
判断变化趋势数据是否具有时间规律具体可以是判断随时间变化的长期趋势数据或随时间变化的短期趋势数据是否有时间规律,即,判断随时间变化的长期趋势数据是否逐渐降低或逐渐升高,或者随时间变化的短期趋势数据是否具有周期性或季节性。
s5,如果变化趋势数据具有时间规律,将变化趋势数据进行特征化处理生成第二因子数据,将至少一个第一因子数据与第二因子数据输入预设模型进行学习,以对预定时间的电子产品激活量进行预测。
如果判断为,随时间变化的长期趋势数据是逐渐升高的,例如在一年内随着时间而逐渐升高,随时间变化的短期趋势数据是例如以7天为周期逐渐变化的,那么,将变化趋势数据进行特征化处理生成第二因子数据。
其中,将变化趋势数据进行特征化可以包括将随时间变化的长期趋势数据和随时间变化的短期趋势数据的依赖时长构造成多维特征或者一维特征作为第二因子数据。例如,如果随时间变化的短期趋势数据是以7天为周期逐渐变化的,那么将以7天为周期输入例如lag(n)函数将其构造为七维特征。又例如,如果随时间变化的短期趋势数据是以1天为周期逐渐变化的,那么将以1天为周期输入例如lag(n)函数将其构造为一维特征。
将第二因子数据与至少一个第一因子数据输入预设模型进行学习,以对预定时间的电子产品激活量进行预测。预设模型可以是集成学习模型,例如是gbdt或xgboost算法。将第一因子数据与第二因子数据输入预设模型时,每一个第一因子数据与第二因子数据的权重均相等。
对电子产品的激活量进行预测,例如可以是将随时间变化逐渐上升的长期趋势特征化和将以7天为周期的短期趋势数据进行特征化后为第二因子数据,并将预定时间以及至少一个第一因子数据输入预设模型进行学习,此时的至少一个第一因子数据可以为预定时间对应的第一因子数据,从而得到在第二因子数据和至少一个第一因子数据作用下,预定时间的电子产品激活量。其中,预定时间可以是未来某一天的时间,也可以是未来某一段的时间。
通过利用时间序列法将第一激活量数据拆解为不受第一因子数据影响的第二激活量数据,并将第二激活量数据特征化处理后与第一因子数据输入集成学习模型进行学习,预测预定时间的电子产品激活量,预测的稳定性和准确率都有明显的提升,训练误差和测试误差都有明显的降低。
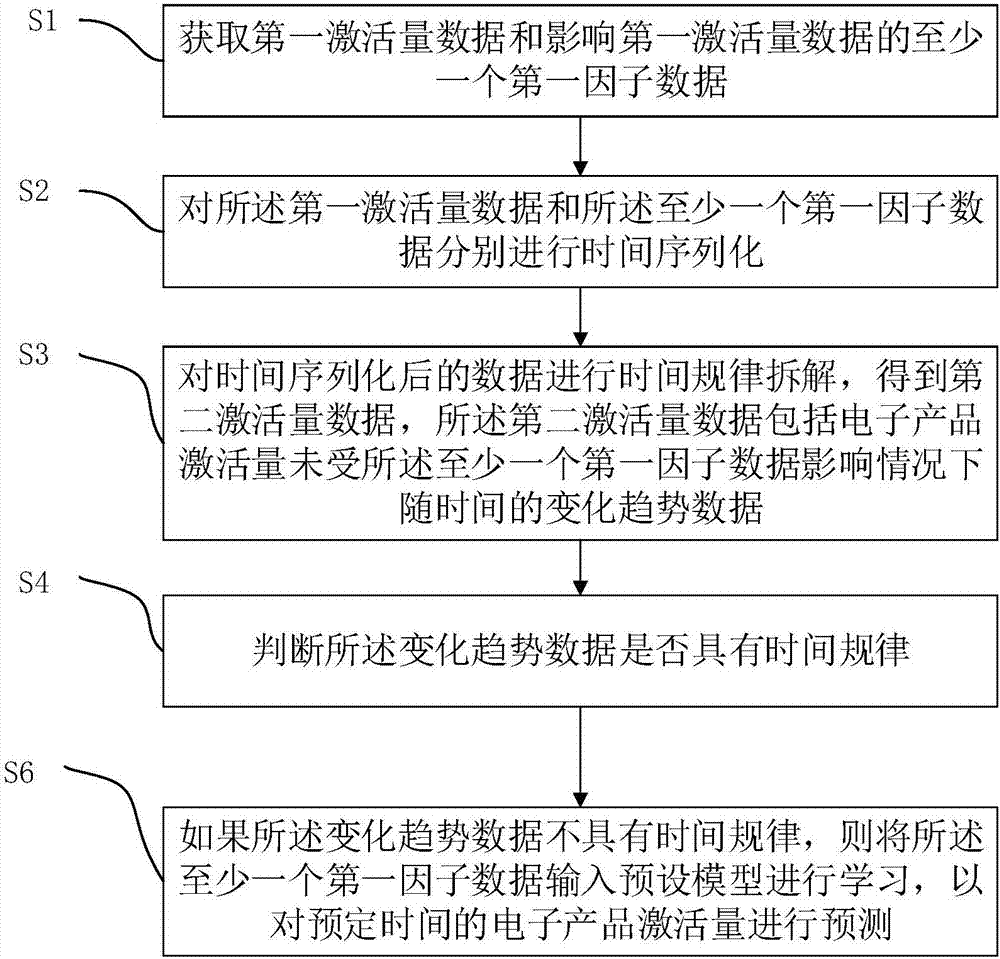
如图2所示,本发明公开的另一个实施例中,电子产品激活量预测方法包括:
s1,获取第一激活量数据和影响第一激活量数据的至少一个第一因子数据;
s2,对所述第一激活量数据和所述至少一个第一因子数据分别进行时间序列化;
s3,对时间序列化后的数据进行时间规律拆解,得到第二激活量数据,第二激活量数据包括电子产品激活量未受至少一个第一因子数据影响情况下随时间的变化趋势数据;
s4,判断变化趋势数据是否具有时间规律;
s6,如果变化趋势数据不具有时间规律,则将至少一个第一因子数据输入预设模型进行学习,以对预定时间的电子产品激活量进行预测。
本实施例与上一个实施例的区别主要在于s6,s6中,由于变化趋势数据不具有时间规律,则仅将至少一个第一因子数据以及预定时间输入预设模型进行学习,从而得到在至少一个第一因子作用下,预定时间的电子产品激活量。预设模型可以是集成学习模型,例如是gbdt或xgboost算法。其中,预定时间可以是未来某一天的时间,也可以是未来某一段的时间。
在上述两个实施例中,对至少一个第一因子数据进行时间序列化包括对价格因子数据进行时间序列化,并且在对价格因子数据进行时间序列化前,对价格因子数据进行离散化,例如,可以对价格数据离散化为不同价格区间。
本发明还公开了一种服务器集群,包括至少一个处理器、至少一个存储器,至少一个存储器能够存储被至少一个处理器处理的指令,至少一个处理器配置为执行指令以:
获取第一激活量数据和影响第一激活量数据的至少一个第一因子数据;
对第一激活量数据和至少一个第一因子数据分别进行时间序列化;
对时间序列化后的数据进行时间规律拆解,得到第二激活量数据,第二激活量数据包括电子产品激活量未受所述至少一个第一因子数据影响情况下随时间的变化趋势数据;
判断变化趋势数据是否具有时间规律;
如果变化趋势数据具有时间规律,将变化趋势数据进行特征化处理生成第二因子数据,将至少一个第一因子数据与第二因子数据输入预设模型进行学习,以对预定时间的电子产品激活量进行预测。
进一步的,至少一个处理器配置为进一步执行指令以:
如果变化趋势数据不具有时间规律,则将至少一个第一因子数据输入预设模型进行学习,以对预定时间的电子产品激活量进行预测。
进一步的,至少一个第一因子数据包括价格因子数据、市场活动因子数据、产品质量因子数据、舆论因子数据、竞争产品因子数据中的一个或多个。
进一步的,舆论因子数据包括情感指数因子数据,情感指数因子数据基于正面舆论评价信息数量以及负面舆论评价信息数量确认。
进一步的,对至少一个第一因子数据进行时间序列化包括对价格因子数据进行时间序列化,并且在对价格因子数据进行时间序列化前,对价格因子数据进行离散化。
进一步的,将变化趋势数据进行特征化处理包括,将变化趋势数据的依赖时长构造成一维特征或多维特征作为第二因子数据。
进一步的,第一因子数据与第二因子数据的权重相等。
通过利用时间序列法将第一激活量数据拆解为不受第一因子数据影响的第二激活量数据,并将第二激活量数据特征化处理后与第一因子数据输入集成学习模型进行学习,预测预定时间的电子产品激活量,预测的稳定性和准确率都有明显的提升,训练误差和测试误差都有明显的降低。
以上实施例仅为本发明的示例性实施例,不用于限制本发明,本发明的保护范围由权利要求书限定。本领域技术人员可以在本发明的实质和保护范围内,对本发明做出各种修改或等同替换,这种修改或等同替换也应视为落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!